【机器学习】神经网络实现异或(XOR)
注:在吴恩达老师讲的【机器学习】课程中,最开始介绍神经网络的应用时就介绍了含有一个隐藏层的神经网络可以解决异或问题,而这是单层神经网络(也叫感知机)做不到了,当时就觉得非常神奇,之后就一直打算自己实现一下,一直到一周前才开始动手实现。自己参考【机器学习】课程中数字识别的作业题写了代码,对于作业题中给的数字图片可以达到95%左右的识别准确度。但是改成训练异或的网络时,怎么也无法得到正确的结果。后来查了一些资料才发现是因为自己有一个参数设置的有问题,而且学习率过小,迭代的次数也不够。总之,异或逻辑的实现不仅对于人工神经网络这一算法是一大突破,对于我自己对误差反向传播算法(Error Back Propagation, BP)的理解也是非常重要的过程,因此记录于此。
什么是异或
在数字逻辑中,异或是对两个运算元的一种逻辑分析类型,符号为XOR或EOR或⊕。与一般的或(OR)不同,当两两数值相同时为否,而数值不同时为真。异或的真值表如下:
| Input | Output | |
|---|---|---|
| A | B | |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
- 0, false
- 1, true
据说在人工神经网络(artificial neural network, ANN)发展初期,由于无法实现对多层神经网络(包括异或逻辑)的训练而造成了一场ANN危机,到最后BP算法的出现,才让训练带有隐藏层的多层神经网络成为可能。因此异或的实现在ANN的发展史是也是具有里程碑意义的。异或之所以重要,是因为它相对于其他逻辑关系,例如与(AND), 或(OR)等,异或是线性不可分的。如下图:
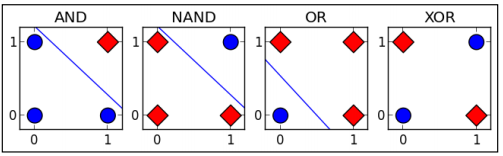
在实际应用中,异或门(Exclusive-OR gate, XOR gate)是数字逻辑中实现逻辑异或的逻辑门,这一函数能实现模为2的加法。因此,异或门可以实现计算机中的二进制加法。
异或的神经网络结构
在【机器学习】课程中,使用了AND(与),NOR(或非)和OR(或)的组合实现了XNOR(同或),与我们要实现的异或(XOR)正好相反。因此还是可以采用课程中的神经网络结构,如下图:
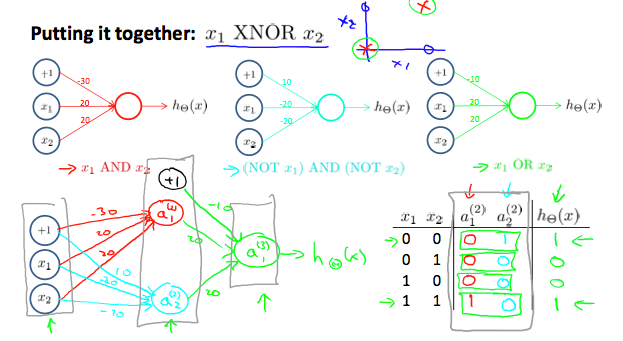
如果算上输入层我们的网络共有三层,如下图所示,其中第1层和第2层中的1分别是这两层的偏置单元。连线上是连接前后层的参数。
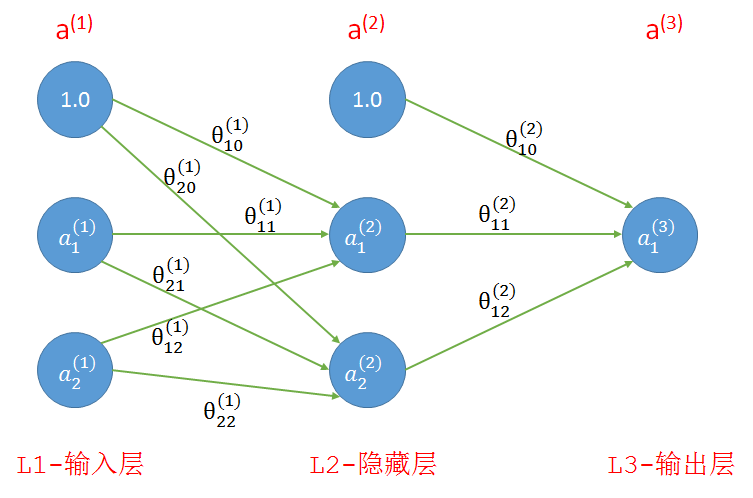
- 输入:我们一共有四个训练样本,每个样本有两个特征,分别是(0, 0), (1, 0), (0, 1), (1, 1);
- 理想输出:参考上面的真值表,样本中两个特征相同时为0,相异为1
- 参数:随机初始化,范围为(-1, 1)
- 关于神经网络的基础知识以及前向传播、反向传播的实现请参考下面两篇文章,写的非常精彩:
机器学习公开课笔记(4):神经网络(Neural Network)——表示
机器学习公开课笔记(5):神经网络(Neural Network)——学习
代码
- 原生态的代码:
下面的实现是完全根据自己的理解和对【机器学习】课程中作业题的模仿而写成的,虽然代码质量不是非常高,但是算法的所有细节都展示出来了。
在66, 69, 70行的注释是我之前没有得到正确结果的三个原因,其中epsilon确定的是随机初始化参数的范围,例如epsilon=1,参数范围就是(-1, 1)
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 4 10:47:51 2017 @author: xin
"""
# Neural Network for XOR
import numpy as np
import matplotlib.pyplot as plt HIDDEN_LAYER_SIZE = 2
INPUT_LAYER = 2 # input feature
NUM_LABELS = 1 # output class number
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]]) def rand_initialize_weights(L_in, L_out, epsilon):
"""
Randomly initialize the weights of a layer with L_in
incoming connections and L_out outgoing connections; Note that W should be set to a matrix of size(L_out, 1 + L_in) as
the first column of W handles the "bias" terms
"""
epsilon_init = epsilon
W = np.random.rand(L_out, 1 + L_in) * 2 * epsilon_init - epsilon_init
return W def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x)) def sigmoid_gradient(z):
g = np.multiply(sigmoid(z), (1 - sigmoid(z)))
return g def nn_cost_function(theta1, theta2, X, y):
m = X.shape[0] # m=4
# 计算所有参数的偏导数(梯度)
D_1 = np.zeros(theta1.shape) # Δ_1
D_2 = np.zeros(theta2.shape) # Δ_2
h_total = np.zeros((m, 1)) # 所有样本的预测值, m*1, probability
for t in range(m):
a_1 = np.vstack((np.array([[1]]), X[t:t + 1, :].T)) # 列向量, 3*1
z_2 = np.dot(theta1, a_1) # 2*1
a_2 = np.vstack((np.array([[1]]), sigmoid(z_2))) # 3*1
z_3 = np.dot(theta2, a_2) # 1*1
a_3 = sigmoid(z_3)
h = a_3 # 预测值h就等于a_3, 1*1
h_total[t,0] = h
delta_3 = h - y[t:t + 1, :].T # 最后一层每一个单元的误差, δ_3, 1*1
delta_2 = np.multiply(np.dot(theta2[:, 1:].T, delta_3), sigmoid_gradient(z_2)) # 第二层每一个单元的误差(不包括偏置单元), δ_2, 2*1
D_2 = D_2 + np.dot(delta_3, a_2.T) # 第二层所有参数的误差, 1*3
D_1 = D_1 + np.dot(delta_2, a_1.T) # 第一层所有参数的误差, 2*3
theta1_grad = (1.0 / m) * D_1 # 第一层参数的偏导数,取所有样本中参数的均值,没有加正则项
theta2_grad = (1.0 / m) * D_2
J = (1.0 / m) * np.sum(-y * np.log(h_total) - (np.array([[1]]) - y) * np.log(1 - h_total))
return {'theta1_grad': theta1_grad,
'theta2_grad': theta2_grad,
'J': J, 'h': h_total} theta1 = rand_initialize_weights(INPUT_LAYER, HIDDEN_LAYER_SIZE, epsilon=1) # 之前的问题之一,epsilon的值设置的太小
theta2 = rand_initialize_weights(HIDDEN_LAYER_SIZE, NUM_LABELS, epsilon=1) iter_times = 10000 # 之前的问题之二,迭代次数太少
alpha = 0.5 # 之前的问题之三,学习率太小
result = {'J': [], 'h': []}
theta_s = {}
for i in range(iter_times):
cost_fun_result = nn_cost_function(theta1=theta1, theta2=theta2, X=X, y=y)
theta1_g = cost_fun_result.get('theta1_grad')
theta2_g = cost_fun_result.get('theta2_grad')
J = cost_fun_result.get('J')
h_current = cost_fun_result.get('h')
theta1 -= alpha * theta1_g
theta2 -= alpha * theta2_g
result['J'].append(J)
result['h'].append(h_current)
# print(i, J, h_current)
if i==0 or i==(iter_times-1):
print('theta1', theta1)
print('theta2', theta2)
theta_s['theta1_'+str(i)] = theta1.copy()
theta_s['theta2_'+str(i)] = theta2.copy() plt.plot(result.get('J'))
plt.show()
print(theta_s)
print(result.get('h')[0], result.get('h')[-1])
下面是输出结果:
# 随机初始化得到的参数
('theta1', array([[ 0.18589823, -0.77059558, 0.62571502],
[-0.79844165, 0.56069914, 0.21090703]]))
('theta2', array([[ 0.1327994 , 0.59513332, 0.34334931]])) # 训练后得到的参数
('theta1', array([[-3.90903729, -7.44497437, 7.20130773],
[-3.76429211, 6.93482723, -7.21857912]]))
('theta2', array([[ -6.5739346 , 13.33011993, 13.3891608 ]])) # 同上,第一次迭代和最后一次迭代得到的参数
{'theta1_0': array([[ 0.18589823, -0.77059558, 0.62571502],
[-0.79844165, 0.56069914, 0.21090703]]), 'theta2_9999': array([[ -6.5739346 , 13.33011993, 13.3891608 ]]), 'theta1_9999': array([[-3.90903729, -7.44497437, 7.20130773],
[-3.76429211, 6.93482723, -7.21857912]]), 'theta2_0': array([[ 0.1327994 , 0.59513332, 0.34334931]])}
# 预测值h: 第1个array里是初始参数预测出来的值,第2个array中是最后一次得到的参数预测出来的值
(array([[ 0.66576877],
[ 0.69036552],
[ 0.64994307],
[ 0.67666546]]), array([[ 0.00245224],
[ 0.99812746],
[ 0.99812229],
[ 0.00215507]]))
下面是随着迭代次数的增加,代价函数值J(θ)的变化情况:
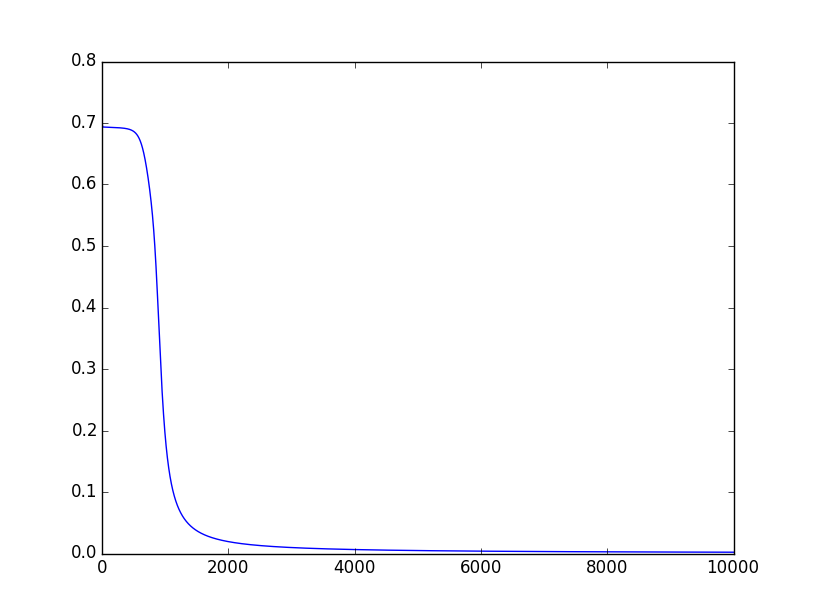
- 更加精炼的代码
下面这段代码是我在排除之前自己的代码中的问题时,在Stack Overflow上发现的,发帖的人也碰到了同样的问题,但原因不一样。他的代码里有一点小问题,已经修正。这段代码,相对于我自己的原生态代码,有了非常大的改进,没有限定层数和每层的单元数,代码本身也比较简洁。
说明:由于第44行,传的参数是该层的a值,而不是z值,所以第11行需要做出一点修改,其实直接传递a值是一种更方便的做法。
# -*- coding: utf-8 -*- import numpy as np
import matplotlib.pyplot as plt def sigmoid(x):
return 1/(1+np.exp(-x)) def s_prime(z):
return np.multiply(z, 1.0-z) # 修改的地方 def init_weights(layers, epsilon):
weights = []
for i in range(len(layers)-1):
w = np.random.rand(layers[i+1], layers[i]+1)
w = w * 2*epsilon - epsilon
weights.append(np.mat(w))
return weights def fit(X, Y, w):
# now each para has a grad equals to 0
w_grad = ([np.mat(np.zeros(np.shape(w[i])))
for i in range(len(w))]) # len(w) equals the layer number
m, n = X.shape
h_total = np.zeros((m, 1)) # 所有样本的预测值, m*1, probability
for i in range(m):
x = X[i]
y = Y[0,i]
# forward propagate
a = x
a_s = []
for j in range(len(w)):
a = np.mat(np.append(1, a)).T
a_s.append(a) # 这里保存了前L-1层的a值
z = w[j] * a
a = sigmoid(z)
h_total[i, 0] = a
# back propagate
delta = a - y.T
w_grad[-1] += delta * a_s[-1].T # L-1层的梯度
# 倒过来,从倒数第二层开始到第二层结束,不包括第一层和最后一层
for j in reversed(range(1, len(w))):
delta = np.multiply(w[j].T*delta, s_prime(a_s[j])) # 这里传递的参数是a,而不是z
w_grad[j-1] += (delta[1:] * a_s[j-1].T)
w_grad = [w_grad[i]/m for i in range(len(w))]
J = (1.0 / m) * np.sum(-Y * np.log(h_total) - (np.array([[1]]) - Y) * np.log(1 - h_total))
return {'w_grad': w_grad, 'J': J, 'h': h_total} X = np.mat([[0,0],
[0,1],
[1,0],
[1,1]])
Y = np.mat([0,1,1,0])
layers = [2,2,1]
epochs = 5000
alpha = 0.5
w = init_weights(layers, 1)
result = {'J': [], 'h': []}
w_s = {}
for i in range(epochs):
fit_result = fit(X, Y, w)
w_grad = fit_result.get('w_grad')
J = fit_result.get('J')
h_current = fit_result.get('h')
result['J'].append(J)
result['h'].append(h_current)
for j in range(len(w)):
w[j] -= alpha * w_grad[j]
if i == 0 or i == (epochs - 1):
# print('w_grad', w_grad)
w_s['w_' + str(i)] = w_grad[:] plt.plot(result.get('J'))
plt.show()
print(w_s)
print(result.get('h')[0], result.get('h')[-1])
下面是输出的结果:
# 第一次迭代和最后一次迭代得到的参数
{'w_4999': [matrix([[ 1.51654104e-04, -2.30291680e-04, 6.20083292e-04],
[ 9.15463982e-05, -1.51402782e-04, -6.12464354e-04]]), matrix([[ 0.0004279 , -0.00051928, -0.00042735]])],
'w_0': [matrix([[ 0.00172196, 0.0010952 , 0.00132499],
[-0.00489422, -0.00489643, -0.00571827]]), matrix([[-0.02787502, -0.01265985, -0.02327431]])]}
# 预测值h: 第1个array里是初始参数预测出来的值,第2个array中是最后一次得到的参数预测出来的值
(array([[ 0.45311095],
[ 0.45519066],
[ 0.4921871 ],
[ 0.48801121]]),
array([[ 0.00447994],
[ 0.49899856],
[ 0.99677373],
[ 0.50145936]]))
观察上面的结果,最后一次迭代得到的结果并不是我们期待的结果,也就是第1、4个值接近于0, 第2、3个值接近于1。下面是代价函数值J(θ)随着迭代次数增加的变化情况:
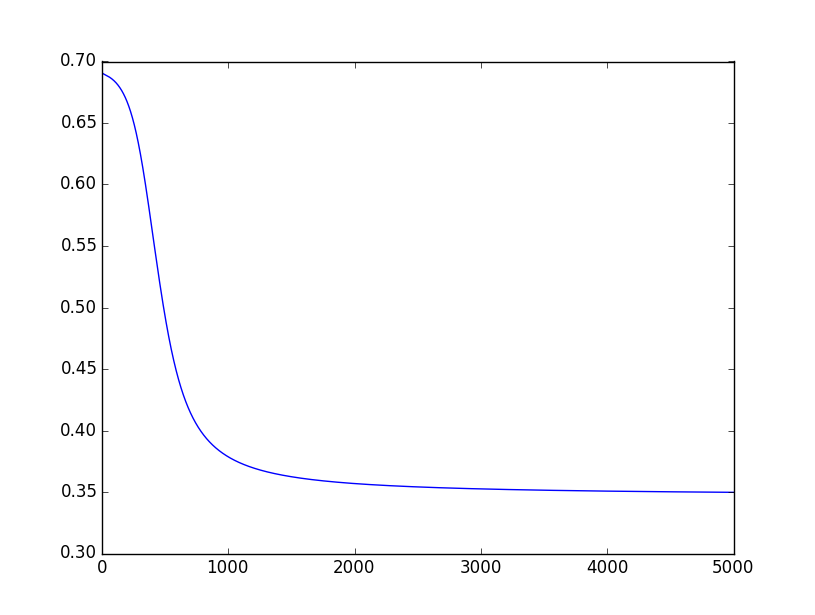
从上图可以看到,J(θ)的值从2000以后就一直停留在0.35左右,因此整个网络有可能收敛到了一个局部最优解,也有可能是迭代次数不够导致的。
将迭代次数改成10000后, 即epochs = 10000,基本上都是可以得到预期的结果的。其实在迭代次数少的情况下,也有可能得到预期的结果,这应该主要取决于初始的参数。
经验小结
通过阅读别人的代码确实是提高自己编程能力的一种重要方法。例如通过比较自己的原生态版代码和其他人写的代码,就可以找出自己的不足之处。其中最大的收获是:数据结构对于代码的结构和逻辑都非常重要。比如我自己写的时候,每一层是分开的,但后面的代码中将整个网络一起初始化并保存在一个list中,这就提高了代码的可扩展能力,也使得代码更加简洁!
此外,要准确的理解各种算法的细节,最好的方式就是自己实现一次。
<完>
参考文献
https://zh.wikipedia.org/wiki/%E9%80%BB%E8%BE%91%E5%BC%82%E6%88%96
https://zh.wikipedia.org/wiki/%E5%BC%82%E6%88%96%E9%97%A8
https://muxuezi.github.io/posts/10-from-the-perceptron-to-artificial-neural-networks.html
http://stackoverflow.com/q/36369335/2803344
Coursera, Andrew Ng 公开课第四周,第五周
【机器学习】神经网络实现异或(XOR)的更多相关文章
- ANN神经网络——实现异或XOR (Python实现)
一.Introduction Perceptron can represent AND,OR,NOT 用初中的线性规划问题理解 异或的里程碑意义 想学的通透,先学历史! 据说在人工神经网络(artif ...
- 简单多层神经网络实现异或XOR
最近在看<Neural Network Design_Hagan> 然后想自己实现一个XOR 的网络. 由于单层神经网络不能将异或的判定分为两类. 根据 a^b=(a&~b)|(~ ...
- 从 0 开始机器学习 - 神经网络反向 BP 算法!
最近一个月项目好忙,终于挤出时间把这篇 BP 算法基本思想写完了,公式的推导放到下一篇讲吧. 一.神经网络的代价函数 神经网络可以看做是复杂逻辑回归的组合,因此与其类似,我们训练神经网络也要定义代价函 ...
- 神经网络与机器学习 笔记—单神经元解决XOR问题
单神经元解决XOR问题 有两个输入的单个神经元的使用得到的决策边界是输入空间的一条直线.在这条直线的一边的所有的点,神经元输出1:而在这条直线的另一边的点,神经元输出0.在输入空间中,这条直线的位置和 ...
- BP神经网络求解异或问题(Python实现)
反向传播算法(Back Propagation)分二步进行,即正向传播和反向传播.这两个过程简述如下: 1.正向传播 输入的样本从输入层经过隐单元一层一层进行处理,传向输出层:在逐层处理的过程中.在输 ...
- python最全学习资料:python基础进阶+人工智能+机器学习+神经网络(包括黑马程序员2017年12月python视频(百度云链接))
首先用数据说话,看看资料大小,达到675G 承诺:真实资料.不加密,获取资料请加QQ:122317653 包含内容:1.python基础+进阶+应用项目实战 2.神经网络算法+python应用 3.人 ...
- python学习大全:python基础进阶+人工智能+机器学习+神经网络
首先用数据说话,看看资料大小,达到675G承诺:真实资料.不加密.(鉴于太多朋友加我QQ,我无法及时回复,) 方便的朋友给我点赞.评论下,谢谢!(内容较大,多次保存) [hide]链接:[url]ht ...
- 【xsy1147】 异或(xor) 可持久化trie
我的脑回路可能比较奇怪. 我们对这些询问离线,将所得序列${a}$的后缀和建$n$棵可持久化$trie$. 对于一组询问$(l,r,x)$,我们在主席树上询问第$l$棵树$-$第r$+1$棵树中与$s ...
- 图片异或(xor)getflag
题目地址:https://files.cnblogs.com/files/nul1/flag_enc.png.tar 这题是源于:网鼎杯minified 经过测试隧道红色最低通道异常.其余均正常.所以 ...
随机推荐
- css小技巧 :not 省时又省力
比如,要实现下面的效果(例如:一个列表的最后一项没有边框): See the Pen gmrGOV by 杨友存 (@Gavin-YYC) on CodePen. 一般的文档结构如下: <!-- ...
- 更改Debian Linux里面的EDT时区为CST时区
Debian按默认安装,设置的是EDT时区.这样跟我们的系统就都对不上,因此得 改回CST. 只需要两步即可: 使用vi编辑/etc/timezone,把timezone文件的内容更改为:Asia/S ...
- shell [ff: 未找到命令
在学习shell脚本时遇到一个问题: [ff: 未找到命令 相信很多初学者都会遇到,再次说明一下,希望对大家有所帮助: shell脚本代码如下: #!/bin/bash echo -n " ...
- 学习HTML5一周的收获4
/* [CSS常用文本属性] * 1.字体.字号: font-weight:字体的粗细,可选属性值:bold加粗 lighter细体 100~900数值(400正常,700 bold) fo ...
- 聊聊"jQuery is not defined"
KiwenLau同学在他的个人博客使用了Fundebug的JavaScript错误监控插件,然后偶尔会收到jQuery is not defined这样的错误报警: 他的博客使用了Staticfile ...
- wemall app商城源码Android之支付宝接口公用函数
wemall-mobile是基于WeMall的Android app商城,只需要在原商城目录下上传接口文件即可完成服务端的配置,客户端可定制修改.本文分享wemall app商城源码Android之 ...
- 1935: [Shoi2007]Tree 园丁的烦恼
1935: [Shoi2007]Tree 园丁的烦恼 Time Limit: 15 Sec Memory Limit: 357 MBSubmit: 648 Solved: 273[Submit][ ...
- 1675: [Usaco2005 Feb]Rigging the Bovine Election 竞选划区(题解第一弹)
1675: [Usaco2005 Feb]Rigging the Bovine Election 竞选划区 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: ...
- 1602: [Usaco2008 Oct]牧场行走
1602: [Usaco2008 Oct]牧场行走 Time Limit: 5 Sec Memory Limit: 64 MB Submit: 1211 Solved: 616 [Submit][ ...
- java深拷贝和浅拷贝
1.概念 java里的clone分为: A:浅复制(浅克隆): 浅复制仅仅复制所考虑的对象,而不复制它所引用的对象. b:深复制(深克隆):深复制把要复制的对象所引用的对象都复制了一遍. Java中对 ...