【 js 模块加载 】深入学习模块化加载(node.js 模块源码)
文章提纲:
第一部分:介绍模块规范及之间区别
第二部分:以 node.js 实现模块化规范 源码,深入学习。
一、模块规范
define(id?, dependencies?, factory);
//id :可选参数,它指的是模块的名字。
//dependencies:可选参数,定义中模块所依赖模块的数组。
//factory:模块初始化要执行的函数或对象
define("alpha", ["require", "exports", "beta"], function (require, exports, beta) {
exports.verb = function() {
return beta.verb();
//Or:
//return require("beta").verb();
}
});
1.2、require() 函数
require([module], callback);
//module:一个数组,里面的成员就是要加载的模块.
//callback:模块加载成功之后的回调函数。
需要注意的是 ,module 有多少个元素,callback 就有多少个传参,位置一一对应。
使用的栗子:
require(["a","b","c"],function(a,b,c){
//code here
});
define(factory);
//factory:模块初始化要执行的函数或对象,为函数时,表示是模块的构造方法。
//执行该构造方法,可以得到模块向外提供的接口。
//factory 方法在执行时,默认会传入三个参数:require、exports 和 module。
//其中require用来获取其他模块提供的接口,exports用来向外提供模块接口,module是一个对象,上面存储了与当前模块相关联的一些属性和方法。
使用的栗子:
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
// 此处略去 100 行
var b = require('./b') // 依赖可以就近书写
b.doSomething()
// …
// 对外提供 doSomething 方法
exports.doSomething = function() {};
});
而调用CMD编写的模块的方法是:
seajs.use("a")//调用a模块
//这里就设计到SeaJS的使用了:
//- 引入sea.js的库
//- 如何变成模块?
// - define
//- 如何调用模块?
// -sea.js.use
//- 如何依赖模块?
// -require
//定义模块 math.js
var random=Math.random()*10;
function printRandom(){
console.log(random)
} function printIntRandom(){
console.log(Math.floor(random))
}
//模块输出
module.exports={
printRandom:printRandom,
printIntRandom:printIntRandom
}
//加载模块 math.js
var math=require('math')
//调用模块提供的方法
math.printIntRandom()
math.printRandom()
4、模块规范之间的区别
A、首先说一下 CommonJS与其它两种的区别:CommonJS采用的就是同步加载方式,而其它两种都是异步的。
举个栗子:
commonJS中:
var math = require('math');
math.add(2, 3);
第二行 math.add(2, 3),在第一行 require('math') 之后运行,因此必须等 math.js 加载完成。也就是说,如果加载时间很长,整个应用就会停在那里等。
AMD中:
require(['math'], function (math) {
math.add(2, 3);
});
console.log("222");
这个是不会阻遏后面语句的执行的,等到什么时候 math 模块加载出来进行回调函数就可以了。
PS:由于 Node.js 主要用于服务器编程,模块文件一般都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,所以 CommonJS 规范比较适用。但是,如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用 AMD 规范。
通常我们在使用一个模块的时候在 js 中都是这样引用的:
var math = require('math');
math.add(2, 3);
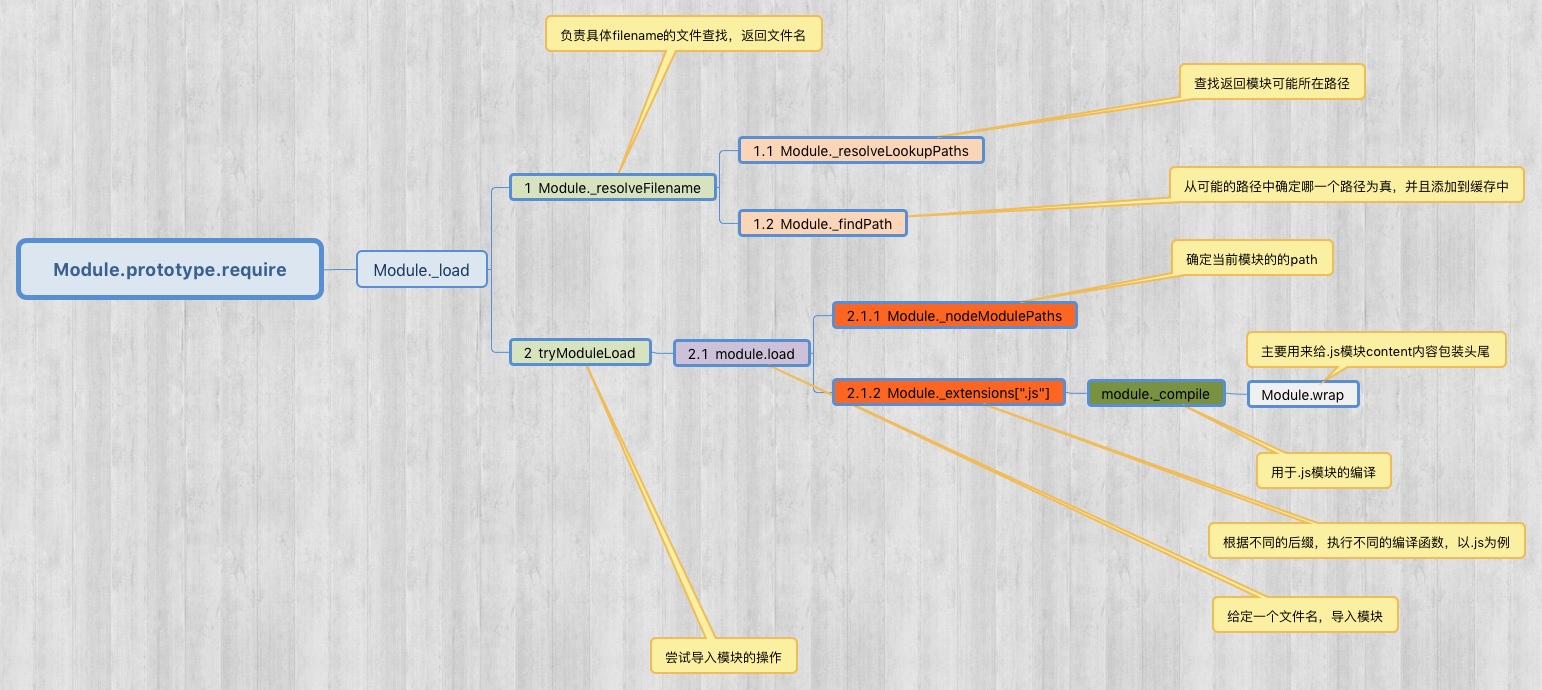
从 require 方法本身是如何实现的入手,一步一步看:(代码全部来自 node.js [https://github.com/nodejs/node] 源码)
require 方法封装在 node 源码中的 lib 文件夹里的 module.js 中
// Loads a module at the given file path. Returns that module's
// `exports` property.
// 给定一个模块目录,返回该模块的 exports 属性
Module.prototype.require = function(path) {
// assert() 头部引入,主要用于断言,如果表达式不符合预期,就抛出一个错误。
// assert方法接受两个参数,当第一个参数对应的布尔值为true时,不会有任何提示,返回undefined。
// 当第一个参数对应的布尔值为false时,会抛出一个错误,该错误的提示信息就是第二个参数设定的字符串。
assert(path, 'missing path'); //断言是否有path
assert(typeof path === 'string', 'path must be a string'); //断言 path是否是个字符串 return Module._load(path, this, /* isMain */ false); //require方法主要是为了引出_load方法。
//_load函数三个参数: path 当前加载的模块名称,parent 父亲模块,其实是谁导入了该模块,
// /* isMain */ false 是不是主入口文件
};
// Check the cache for the requested file.
// 1. If a module already exists in the cache: return its exports object.
// 2. If the module is native: call `NativeModule.require()` with the
// filename and return the result.
// 3. Otherwise, create a new module for the file and save it to the cache.
// Then have it load the file contents before returning its exports
// object.
// 从缓存中查找所要加载的模块
// 1. 如果一个模块已经存在于缓存中:直接返回它的exports对象
// 2. 如果模块是一个本地模块,调用'NativeModule.require()'方法,filename作为参数,并返回结果
// 3. 否则,使用这个文件创建一个新模块并把它加入缓存中。在加载它只会返回exports对象。
// _load函数三个参数: path 当前加载的模块名称,parent 父亲模块,/* isMain */ false 是不是主入口文件
Module._load = function(request, parent, isMain) {
if (parent) {
//头部引入了 Module._debug = util.debuglog('module');const debug = Module._debug;
// 这个方法用来打印出调试信息,具体可以看 https://chyingp.gitbooks.io/nodejs/%E6%A8%A1%E5%9D%97/util.html
debug('Module._load REQUEST %s parent: %s', request, parent.id); } // 找到当前的需要解析的文件名
var filename = Module._resolveFilename(request, parent, isMain); //如果已经有的缓存,直接返回缓存的exports
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
} //如果模块是一个内部模块,调用内部方法'NativeModule.require()'方法,filename作为参数,并返回结果
if (NativeModule.nonInternalExists(filename)) {
debug('load native module %s', request);
return NativeModule.require(filename);
} //创建一个新模块
var module = new Module(filename, parent); //是否为主模块,
if (isMain) {
//主模块的话,需要将当前的module赋值给process.mainModule
process.mainModule = module;
//主模块的id特殊的赋值为"."
module.id = '.';
} //并把新模块加入缓存中
Module._cache[filename] = module; //尝试导入模块的操作
tryModuleLoad(module, filename); // 返回新创建模块中的exports,也就是暴露在外面的方法属性等。
return module.exports;
};
Module._load 中调用了 Module._resolveFilename() 方法
// 负责具体filename的文件查找
// 参数 request 当前加载的模块名称,parent 父亲模块,/* isMain */ false 是不是主入口文件
Module._resolveFilename = function(request, parent, isMain) { //NativeModule用于管理js模块,头部引入的。
//NativeModule.nonInternalExists()用来判断是否是原生模块且不是内部模块,
//所谓内部模块就是指 lib/internal 文件目录下的模块,像fs等。
//满足 是原生模块且不是内部模块,则直接返回 当前加载的模块名称request。
if (NativeModule.nonInternalExists(request)) {
return request;
} // Module._resolveLookupPaths()函数返回一个数组[id , paths],
// paths是一个 可能 包含这个模块的文件夹路径(绝对路径)数组
var paths = Module._resolveLookupPaths(request, parent, true); // look up the filename first, since that's the cache key.
// 确定哪一个路径为真,并且添加到缓存中
var filename = Module._findPath(request, paths, isMain); // 如果没有找到模块,报错
if (!filename) {
var err = new Error(`Cannot find module '${request}'`);
err.code = 'MODULE_NOT_FOUND';
throw err;
} // 找到模块则直接返回
return filename;
};
Module._resolveFilename 调用了 Module._resolveLookupPaths() 方法 和 Module._findPath() 方法。
这两个方法主要是对模块路径的查找,这里要说一下 node 模块路径解析,方便对下面两个函数的理解,大家可以对照着理解。
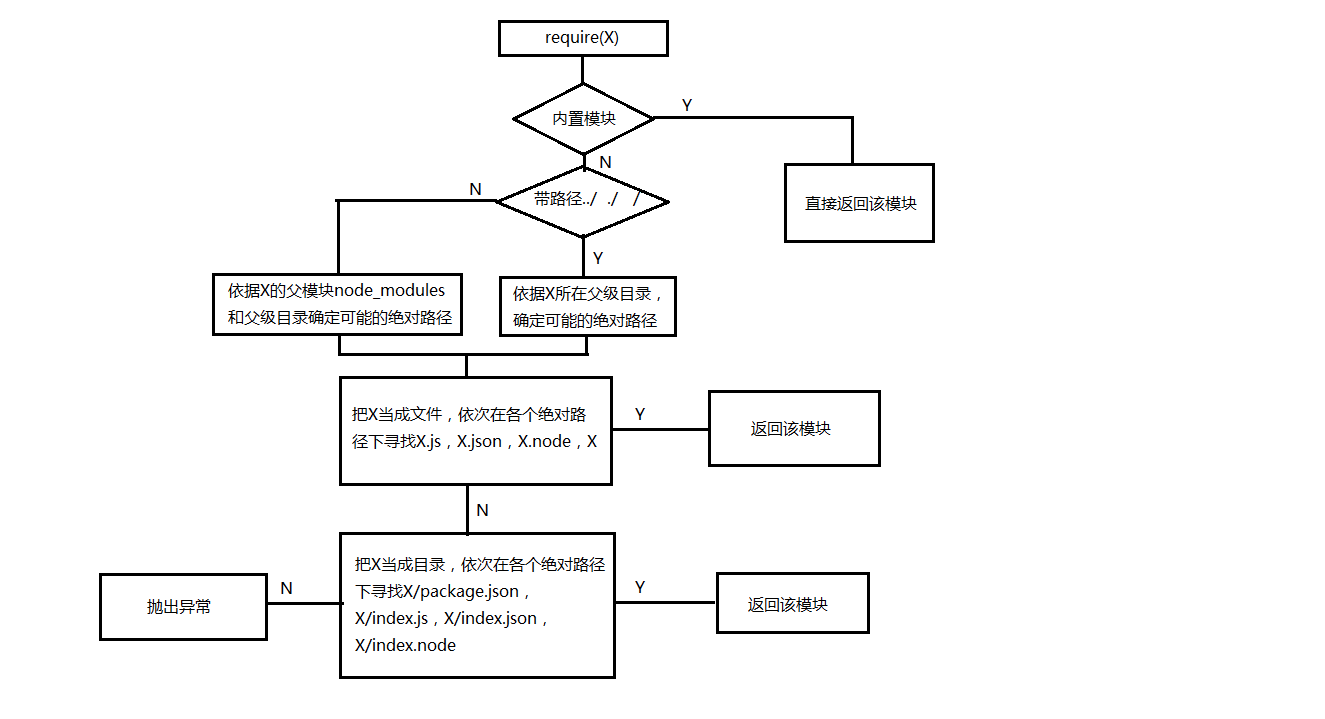
根据require函数的参数形式的不同,比如说直接引一个文件名 require("moduleA"),或者是路径require("./moduleA")等,查找方式会有一些变化:
从 Y 路径的模块 require(X)
1. 如果 X 是一个核心模块,
a. 返回核心模块 //核心模块是指node.js下lib的内容
b. 结束
2. 如果 X 是以 './' 或 '/' 或 '../' 开头
a. 加载文件(Y + X)
b. 加载目录(Y + X)
3. 加载Node模块(X, dirname(Y)) // 导入一个NODE_MODULE,返回
4. 抛出 "未找到" // 上述都没找到,直接排出没找到的异常。
加载文件(X)
1. 如果 X 是一个文件,加载 X 作为 JavaScript 文本。结束
2. 如果 X.js 是一个文件,加载 X.js 作为 JavaScript 文本。结束
3. 如果 X.json 是一个文件,解析 X.json 成一个 JavaScript 对象。结束
4. 如果 X.node 是一个文件,加载 X.node 作为二进制插件。结束 加载目录(X)
1. 如果 X/package.json 是一个文件,
a. 解析 X/package.json,查找 "main" 字段
b. let M = X + (json main 字段)
c. 加载文件(M)
2. 如果 X/index.js 是一个文件,加载 X/index.js 作为 JavaScript 文本。结束
3. 如果 X/index.json 是一个文件,解析 X/index.json 成一个 JavaScript 对象。结束
4. 如果 X/index.node 是一个文件,加载 X/index.node 作为二进制插件。结束 加载Node模块(X, START)
1. let DIRS=NODE_MODULES_PATHS(START) //得到 node_module 文件目录
2. for each DIR in DIRS: // 遍历所有的路径 直到找到 x ,x 可能是 文件或者是目录
a. 加载文件(DIR/X)
b. 加载目录(DIR/X) NODE_MODULES_PATHS(START) //具体NODE_MODULES文件目录算法
1. let PARTS = path split(START)
2. let I = count of PARTS - 1
3. let DIRS = []
4. while I >= 0,
a. if PARTS[I] = "node_modules" CONTINUE
b. DIR = path join(PARTS[0 .. I] + "node_modules")
c. DIRS = DIRS + DIR
d. let I = I - 1 5. return DIRS
1、Module._resolveLookupPaths() 方法
// 'index.' character codes
var indexChars = [ 105, 110, 100, 101, 120, 46 ];
var indexLen = indexChars.length;
//_resolveLookupPaths() 方法用来查找模块,返回一个数组,数组第一项为模块名称即request,数组第二项返回一个可能包含这个模块的文件夹路径数组
//
//处理了如下几种情况:
// 1、是原生模块且不是内部模块
// 2、如果路径不以"./" 或者'..'开头或者只有一个字符串,即是引用模块名的方式,即require('moduleA');
// 2.1以 '/' 为前缀的模块是文件的绝对路径。 例如,require('/home/marco/foo.js') 会加载 /home/marco/foo.js 文件。
// 2.2以 './' 为前缀的模块是相对于调用 require() 的文件的。 也就是说,circle.js 必须和 foo.js 在同一目录下以便于 require('./circle') 找到它。
// 2.3当没有以 '/'、'./' 或 '../' 开头来表示文件时,这个模块必须是一个核心模块或加载自 node_modules 目录。
Module._resolveLookupPaths = function(request, parent, newReturn) { //request 当前加载的模块名称,parent 父亲模块 //NativeModule用于管理js模块,头部引入的。
//NativeModule.nonInternalExists()用来判断是否是原生模块且不是内部模块,所谓内部模块就是指 lib/internal 文件目录下的模块,像fs等。
if (NativeModule.nonInternalExists(request)) {
debug('looking for %j in []', request); //满足 是原生模块且不是内部模块,也就是说是node.js下lib文件夹下的模块,
//但不包含lib/internal 文件目录下的模块,并且newReturn 为true,则返回null ,
//如果newReturn 为false 则返回[request, []]。
return (newReturn ? null : [request, []]);
} // Check for relative path
// 检查相关路径
// 如果路径不以"./"或者'..'开头或者只有一个字符串,即是引用模块名的方式,即require('moduleA');
if (request.length < 2 ||
request.charCodeAt(0) !== 46/*.*/ ||
(request.charCodeAt(1) !== 46/*.*/ &&
request.charCodeAt(1) !== 47/*/*/)) {
//全局变量,在Module._initPaths 函数中赋值的变量,modulePaths记录了全局加载依赖的根目录
var paths = modulePaths; // 设置一下父亲的路径,其实就是谁导入了当前模块
if (parent) {
if (!parent.paths)
paths = parent.paths = [];
else
paths = parent.paths.concat(paths);
} // Maintain backwards compat with certain broken uses of require('.')
// by putting the module's directory in front of the lookup paths.
// 如果只有一个字符串,且是 .
if (request === '.') {
if (parent && parent.filename) {
paths.unshift(path.dirname(parent.filename));
} else {
paths.unshift(path.resolve(request));
}
} debug('looking for %j in %j', request, paths); //直接返回
return (newReturn ? (paths.length > 0 ? paths : null) : [request, paths]);
} // with --eval, parent.id is not set and parent.filename is null
// 处理父亲模块为空的情况
if (!parent || !parent.id || !parent.filename) {
// make require('./path/to/foo') work - normally the path is taken
// from realpath(__filename) but with eval there is no filename
// 生成新的目录, 在系统目录 modulePaths,当前目录 和 "node_modules" 作为候选的路径
var mainPaths = ['.'].concat(Module._nodeModulePaths('.'), modulePaths); debug('looking for %j in %j', request, mainPaths);
//直接返回
return (newReturn ? mainPaths : [request, mainPaths]);
} // Is the parent an index module?
// We can assume the parent has a valid extension,
// as it already has been accepted as a module.
// 处理父亲模块是否为index模块,即 path/index.js 或者 X/index.json等 带有index字样的module
const base = path.basename(parent.filename); // path.basename()返回路径中的最后一部分
var parentIdPath;
if (base.length > indexLen) {
var i = 0; //检查 引入的模块名中是否有 "index." 字段,如果有, i === indexLen。
for (; i < indexLen; ++i) {
if (indexChars[i] !== base.charCodeAt(i))
break;
} // 匹配 "index." 成功,查看是否有多余字段以及剩余部分的匹配情况
if (i === indexLen) {
// We matched 'index.', let's validate the rest
for (; i < base.length; ++i) {
const code = base.charCodeAt(i); // 如果模块名中有 除了 _, 0-9,A-Z,a-z 的字符 则跳出,继续下一次循环
if (code !== 95/*_*/ &&
(code < 48/**/ || code > 57/**/) &&
(code < 65/*A*/ || code > 90/*Z*/) &&
(code < 97/*a*/ || code > 122/*z*/))
break;
} if (i === base.length) {
// Is an index module
parentIdPath = parent.id;
} else {
// Not an index module
parentIdPath = path.dirname(parent.id); //path.dirname() 返回路径中代表文件夹的部分
}
} else {
// Not an index module
parentIdPath = path.dirname(parent.id);
}
} else {
// Not an index module
parentIdPath = path.dirname(parent.id);
} //拼出绝对路径
//path.resolve([from ...], to) 将 to 参数解析为绝对路径。
//eg:path.resolve('/foo/bar', './baz') 输出'/foo/bar/baz'
var id = path.resolve(parentIdPath, request); // make sure require('./path') and require('path') get distinct ids, even
// when called from the toplevel js file
// 确保require('./path')和require('path')两种形式的,获得不同的 ids
if (parentIdPath === '.' && id.indexOf('/') === -1) {
id = './' + id;
} debug('RELATIVE: requested: %s set ID to: %s from %s', request, id,
parent.id);
//path.dirname() 返回路径中代表文件夹的部分
var parentDir = [path.dirname(parent.filename)]; debug('looking for %j in %j', id, parentDir); // 当我们以"./" 等方式require时,都是以当前引用他的模块,也就是父亲模块为对象路径的
return (newReturn ? parentDir : [id, parentDir]);
};
2、Module._findPath() 方法
var warned = false;
//_findPath用于从可能的路径中确定哪一个路径为真,并且添加到缓存中
//参数request 当前加载的模块名称,
//paths ,Module._resolveLookupPaths()函数返回一个数组[id , paths],即模块可能在的所有路径,
// /* isMain */ false 是不是主入口文件
Module._findPath = function(request, paths, isMain) { //path.isAbsolute()判断参数 path 是否是绝对路径。
if (path.isAbsolute(request)) {
paths = [''];
} else if (!paths || paths.length === 0) {
return false;
} var cacheKey = request + '\x00' +
(paths.length === 1 ? paths[0] : paths.join('\x00'));
var entry = Module._pathCache[cacheKey]; //判断是否在缓存中,如果有则直接返回
if (entry)
return entry; //如果不在缓存中,则开始查找
var exts;
// 当前加载的模块名称大于0位并且最后一位是 / ,即是否有后缀的目录斜杠
var trailingSlash = request.length > 0 &&
request.charCodeAt(request.length - 1) === 47/*/*/; // For each path
// 循环每一个可能的路径paths
for (var i = 0; i < paths.length; i++) { // Don't search further if path doesn't exist
// 如果路径存在就继续执行,不存在就继续检验下一个路径 stat 获取路径状态
const curPath = paths[i];
if (curPath && stat(curPath) < 1) continue;
var basePath = path.resolve(curPath, request); //生成绝对路径
var filename; //stat 头部定义的函数,用来获取路径状态,判断路径类型,是文件还是文件夹
var rc = stat(basePath);
//如果没有后缀的目录斜杠,那么就有可能是文件或者是文件夹名
if (!trailingSlash) {
// 若是文件
if (rc === 0) { // File. // 如果是使用模块的符号路径而不是真实路径,并且不是主入口文件
if (preserveSymlinks && !isMain) {
filename = path.resolve(basePath);
} else {
filename = toRealPath(basePath); //获取当前执行文件的真实路径
} // 若是目录
} else if (rc === 1) { // Directory.
if (exts === undefined)
//目录中是否存在 package.json
//通过package.json文件,返回相应路径
exts = Object.keys(Module._extensions);
filename = tryPackage(basePath, exts, isMain);
} // 如果尝试了上面都没有得到filename 匹配所有扩展名进行尝试,是否存在
if (!filename) {
// try it with each of the extensions
if (exts === undefined)
exts = Object.keys(Module._extensions);
// 该模块文件加上后缀名js .json .node进行尝试,是否存在
filename = tryExtensions(basePath, exts, isMain);
}
} // 如果仍然没有得到filename,并且路径类型是文件夹
if (!filename && rc === 1) { // Directory.
if (exts === undefined)
// 目录中是否存在 package.json
// 通过package.json文件,返回相应路径
exts = Object.keys(Module._extensions);
filename = tryPackage(basePath, exts, isMain);
} // 如果仍然没有得到filename,并且路径类型是文件夹
if (!filename && rc === 1) { // Directory.
// try it with each of the extensions at "index"
// 是否存在目录名 + index + 后缀名
// 尝试 index.js index.json index.node
if (exts === undefined)
exts = Object.keys(Module._extensions); //tryExtensions()头部定义方法,用来检查文件加上js node json后缀是否存在
filename = tryExtensions(path.resolve(basePath, 'index'), exts, isMain);
} if (filename) {
// Warn once if '.' resolved outside the module dir
if (request === '.' && i > 0) {
if (!warned) {
warned = true;
process.emitWarning(
'warning: require(\'.\') resolved outside the package ' +
'directory. This functionality is deprecated and will be removed ' +
'soon.',
'DeprecationWarning', 'DEP0019');
}
} // 将找到的文件路径存入返回缓存,然后返回
Module._pathCache[cacheKey] = filename;
return filename;
}
} // 所以从这里可以看出,对于具体的文件的优先级:
// 1. 具体文件。
// 2. 加上后缀。
// 3. package.json
// 4 index加上后缀
// 可能的路径以当前文件夹,nodejs系统文件夹和node_module中的文件夹为候选,以上述顺序找到任意一个,
// 就直接返回 // 没有找到文件,返回false
return false;
};
Module._load 中还调用了 tryModuleLoad() 方法
function tryModuleLoad(module, filename) {
var threw = true;
//try catch一下,如果装载失败,就会从cache中将这个模块删除。
try {
//做真正的导入模块的操作
module.load(filename);
threw = false;
} finally {
if (threw) {
delete Module._cache[filename];
}
}
}
tryModuleLoad() 中调用了 Module.prototype.load() 方法
// Given a file name, pass it to the proper extension handler.
// 指定一个文件名,导入模块,调用适当扩展处理函数,当前主要是js,json,和node
Module.prototype.load = function(filename) {
debug('load %j for module %j', filename, this.id); assert(!this.loaded); //断言 确保当前模块没有被载入
this.filename = filename; // 赋值当前模块的文件名 // Module._nodeModulePaths主要决定paths参数的值的方法。获取node_modules文件夹所在路径。
// path.dirname() 方法返回一个 path 的目录名 path.dirname('/foo/bar/baz/asdf/quux')
// 返回: '/foo/bar/baz/asdf'
this.paths = Module._nodeModulePaths(path.dirname(filename)); //当前文件的后缀
var extension = path.extname(filename) || '.js'; //如果没有后缀,默认为 .js
if (!Module._extensions[extension]) extension = '.js'; //根据不同的后缀,执行不同的函数
Module._extensions[extension](this, filename);
this.loaded = true;
};
Module.prototype.load() 中调用了 Module._nodeModulePaths() 和 Module._extensions 方法
1、Module._nodeModulePaths() 根据操作系统的不同,返回不同的函数
//path 模块的默认操作会根据 Node.js 应用程序运行的操作系统的不同而变化。
//比如,当运行在 Windows 操作系统上时,path 模块会认为使用的是 Windows 风格的路径。
//例如,对 Windows 文件路径 C:\temp\myfile.html 使用 path.basename() 函数,
//运行在 POSIX 上与运行在 Windows 上会产生不同的结果:
//在 POSIX 上:
//path.basename('C:\\temp\\myfile.html');
// 返回: 'C:\\temp\\myfile.html'
//
// 在 Windows 上:
//path.basename('C:\\temp\\myfile.html');
// 返回: 'myfile.html'
//
// 以下就是根据不同的操作系统返回不同的路径格式 ,具体可以了解http://nodejs.cn/api/path.html
//
//
// Module._nodeModulePaths主要决定paths参数的值的方法。获取node_modules文件夹所在路径。
// 'node_modules' character codes reversed
var nmChars = [ 115, 101, 108, 117, 100, 111, 109, 95, 101, 100, 111, 110 ];
var nmLen = nmChars.length;
if (process.platform === 'win32') {
// 'from' is the __dirname of the module.
Module._nodeModulePaths = function(from) {
// guarantee that 'from' is absolute.
from = path.resolve(from); // note: this approach *only* works when the path is guaranteed
// to be absolute. Doing a fully-edge-case-correct path.split
// that works on both Windows and Posix is non-trivial. // return root node_modules when path is 'D:\\'.
// path.resolve will make sure from.length >=3 in Windows.
if (from.charCodeAt(from.length - 1) === 92/*\*/ &&
from.charCodeAt(from.length - 2) === 58/*:*/)
return [from + 'node_modules']; const paths = [];
var p = 0;
var last = from.length;
for (var i = from.length - 1; i >= 0; --i) {
const code = from.charCodeAt(i);
// The path segment separator check ('\' and '/') was used to get
// node_modules path for every path segment.
// Use colon as an extra condition since we can get node_modules
// path for dirver root like 'C:\node_modules' and don't need to
// parse driver name.
if (code === 92/*\*/ || code === 47/*/*/ || code === 58/*:*/) {
if (p !== nmLen)
paths.push(from.slice(0, last) + '\\node_modules');
last = i;
p = 0;
} else if (p !== -1) {
if (nmChars[p] === code) {
++p;
} else {
p = -1;
}
}
} return paths;
};
} else { // posix
// 'from' is the __dirname of the module.
Module._nodeModulePaths = function(from) {
// guarantee that 'from' is absolute.
from = path.resolve(from);
// Return early not only to avoid unnecessary work, but to *avoid* returning
// an array of two items for a root: [ '//node_modules', '/node_modules' ]
if (from === '/')
return ['/node_modules']; // note: this approach *only* works when the path is guaranteed
// to be absolute. Doing a fully-edge-case-correct path.split
// that works on both Windows and Posix is non-trivial.
const paths = [];
var p = 0;
var last = from.length;
for (var i = from.length - 1; i >= 0; --i) {
const code = from.charCodeAt(i);
if (code === 47/*/*/) {
if (p !== nmLen)
paths.push(from.slice(0, last) + '/node_modules');
last = i;
p = 0;
} else if (p !== -1) {
if (nmChars[p] === code) {
++p;
} else {
p = -1;
}
}
} // Append /node_modules to handle root paths.
paths.push('/node_modules'); return paths;
};
}
2、Module._extensions 方法
// 根据不同的文件类型,三种后缀,Node.js会进行不同的处理和执行
// 对于.js的文件会,先同步读取文件,然后通过module._compile解释执行。
// 对于.json文件的处理,先同步的读入文件的内容,无异常的话直接将模块的exports赋值为json文件的内容
// 对于.node文件的打开处理,通常为C/C++文件。
// Native extension for .js
Module._extensions['.js'] = function(module, filename) {
// 同步读取文件
var content = fs.readFileSync(filename, 'utf8'); // internalModule.stripBOM()剥离 utf8 编码特有的BOM文件头,
// 然后通过module._compile解释执行
module._compile(internalModule.stripBOM(content), filename);
}; // Native extension for .json
Module._extensions['.json'] = function(module, filename) {
// 同步的读入文件的内容
var content = fs.readFileSync(filename, 'utf8');
try {
// internalModule.stripBOM()剥离 utf8 编码特有的BOM文件头,
// 然后将模块的exports赋值为json文件的内容
module.exports = JSON.parse(internalModule.stripBOM(content));
} catch (err) {
// 异常处理
err.message = filename + ': ' + err.message;
throw err;
}
}; //Native extension for .node
Module._extensions['.node'] = function(module, filename) {
// 对于.node文件的打开处理,通常为C/C++文件。
return process.dlopen(module, path._makeLong(filename));
};
针对 .js 后缀的,在 Module._extensions 还调用了 module._compile() 方法
// Resolved path to process.argv[1] will be lazily placed here
// (needed for setting breakpoint when called with --debug-brk)
var resolvedArgv;
// Run the file contents in the correct scope or sandbox. Expose
// the correct helper variables (require, module, exports) to
// the file.
// Returns exception, if any.
// 此方法用于模块的编译。
// 参数content 主要是模块js文件的主要内容,filename 是js文件的文件名
Module.prototype._compile = function(content, filename) {
// Remove shebang
// Shebang(也称为 Hashbang )是一个由井号和叹号构成的字符序列 #!
var contLen = content.length;
if (contLen >= 2) {
// 如果content 开头有Shebang
if (content.charCodeAt(0) === 35/*#*/ &&
content.charCodeAt(1) === 33/*!*/) {
if (contLen === 2) {
// Exact match
content = '';
} else {
// Find end of shebang line and slice it off
// 找到以shebang开头的句子的结尾,并将其分开,留下剩余部分 赋值给content
var i = 2;
for (; i < contLen; ++i) {
var code = content.charCodeAt(i);
if (code === 10/*\n*/ || code === 13/*\r*/)
break;
}
if (i === contLen)
content = '';
else {
// Note that this actually includes the newline character(s) in the
// new output. This duplicates the behavior of the regular expression
// that was previously used to replace the shebang line
content = content.slice(i);
}
}
}
} // create wrapper function
// Module.wrap头部引入,主要用来给content内容包装头尾,类似于
// (function (exports, require, module, __filename, __dirname) {
// -----模块源码 content-----
// });
var wrapper = Module.wrap(content); // 包装好的文本就可以送到vm中执行了,这部分就应该是v8引擎的事情,
// runInThisContext将被包装后的源字符串转成可执行函数,runInThisContext的作用,类似eval
var compiledWrapper = vm.runInThisContext(wrapper, {
filename: filename,
lineOffset: 0,
displayErrors: true
}); var inspectorWrapper = null;
// 处理debug模式,
if (process._debugWaitConnect && process._eval == null) {
if (!resolvedArgv) {
// we enter the repl if we're not given a filename argument.
if (process.argv[1]) {
resolvedArgv = Module._resolveFilename(process.argv[1], null, false);
} else {
resolvedArgv = 'repl';
}
} // Set breakpoint on module start
if (filename === resolvedArgv) {
delete process._debugWaitConnect;
inspectorWrapper = getInspectorCallWrapper();
if (!inspectorWrapper) {
const Debug = vm.runInDebugContext('Debug');
Debug.setBreakPoint(compiledWrapper, 0, 0);
}
}
} // 获取当前的文件的路径
var dirname = path.dirname(filename); //生成require方法
var require = internalModule.makeRequireFunction(this); //依赖模块
var depth = internalModule.requireDepth;
if (depth === 0) stat.cache = new Map();
var result; //直接调用content经过包装后的wrapper函数,将module模块中的exports,生成的require,
//this也就是新创建的module,filename, dirname作为参数传递给模块
//类似于
//(function (exports, require, module, __filename, __dirname) {
// -----模块源码 content-----
// })( this.exports, require, this, filename, dirname);
// 这就是为什么我们可以直接在module文件中,直接访问exports, module, require函数的原因
if (inspectorWrapper) {
result = inspectorWrapper(compiledWrapper, this.exports, this.exports,
require, this, filename, dirname);
} else {
result = compiledWrapper.call(this.exports, this.exports, require, this,
filename, dirname);
}
if (depth === 0) stat.cache = null;
return result;
};
Module.prototype._compile 中调用了 Module.wrap 这个方法就是用了给 content 包装的主要函数, 它来自头部的引用:
//Module.wrapper和Module.wrap的方法写在下面,
//给传入进去的script也就是咱们的content --js文件内容套了一个壳,使其最后变成类似于如下的样子:
//
//(function (exports, require, module, __filename, __dirname) {
// -----模块源码-----
// });
//
// NativeModule.wrap = function(script) {
// return NativeModule.wrapper[0] + script + NativeModule.wrapper[1];
// }; // NativeModule.wrapper = [
// '(function (exports, require, module, __filename, __dirname) { ',
// '\n});'
// ];
Module.wrapper = NativeModule.wrapper;
Module.wrap = NativeModule.wrap;
(图一)
现在咱们再看这个图,梳理一下刚才的代码,就清晰多了。
(图二)
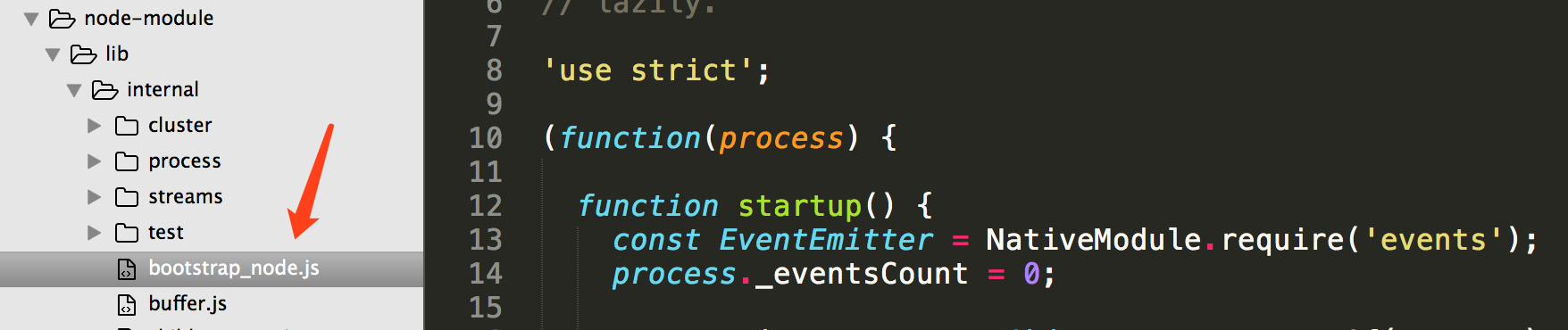
在 bootstrap_node.js 中定义了一个 NativeModule 对象,用于加载核心模块,如 module.js、http.js 等即 lib 文件夹下的 排除 lib/internal 目录下的 js 模块。

在这个 NativeModule 对象中也定义了 require 方法,compile 方法、wrap 方法(用于包装头尾)等 都和上面的 module.js 中的相应的方法意思是一样的,可以下载源码了解一下。

【 js 模块加载 】深入学习模块化加载(node.js 模块源码)的更多相关文章
- node.js在windows下的学习笔记(5)---用NODE.JS创建服务器和客户端
//引入http模块 var http = require('http'); //调用http的createServer的方法,这个方法有一个回调函数,这个回调数 //的作用是当有请求发送给服务器的时 ...
- node.js在windows下的学习笔记(1)---安装node.js
1.首先打开http://www.nodejs.org/ 2.选择DOWNLOADS,跳转到下面的画面,我的系统是windows7的32位.所以选择.msi的32bit版本. 3.下载后,得到一个5. ...
- 【 js 模块加载 】【源码学习】深入学习模块化加载(node.js 模块源码)
文章提纲: 第一部分:介绍模块规范及之间区别 第二部分:以 node.js 实现模块化规范 源码,深入学习. 一.模块规范 说到模块化加载,就不得先说一说模块规范.模块规范是用来约束每个模块,让其必须 ...
- 鸿蒙内核源码分析(进程镜像篇)|ELF是如何被加载运行的? | 百篇博客分析OpenHarmony源码 | v56.01
百篇博客系列篇.本篇为: v56.xx 鸿蒙内核源码分析(进程映像篇) | ELF是如何被加载运行的? | 51.c.h.o 加载运行相关篇为: v51.xx 鸿蒙内核源码分析(ELF格式篇) | 应 ...
- 《唐三学node.js系列》—魂士篇&&三哥初始node.js
前言 如果你有一定的前端基础,比如 HTML.CSS.JavaScript.jQuery.那么Node.js 能让你以最低的成本快速过渡成为一个全栈工程师(我称这个全栈为伪全栈,我认为的全栈也要精通数 ...
- Java并发包源码学习系列:JDK1.8的ConcurrentHashMap源码解析
目录 为什么要使用ConcurrentHashMap? ConcurrentHashMap的结构特点 Java8之前 Java8之后 基本常量 重要成员变量 构造方法 tableSizeFor put ...
- 并发编程学习笔记(9)----AQS的共享模式源码分析及CountDownLatch使用及原理
1. AQS共享模式 前面已经说过了AQS的原理及独享模式的源码分析,今天就来学习共享模式下的AQS的几个接口的源码. 首先还是从顶级接口acquireShared()方法入手: public fin ...
- 并发编程学习笔记(8)----ThreadLocal的使用及源码分析
1. ThreadLocal的理解 ThreadLocal,顾名思义,就是线程的本地变量,ThreadLocal会为每个线程创建一个本地变量副本,使得使用ThreadLocal管理的变量在多线程的环境 ...
- node.js在windows下的学习笔记(9)---文件I/O模块
开发中我们经常会有文件I/O的需求,node.js中提供一个名为fs的模块来支持I/O操作,fs模块的文件I/O是对标准POSIX函数的简单封装. 1.将"hello world" ...
随机推荐
- WinSCP 中普通用户以 root 身份登录 Linux
版本说明: Windows 10 CentOS 7 WinSCP 5.7.7 (Build 6257) 问题背景 使用 WinSCP 登录 CentOS 上传文件,使用的是普通用户,且已加入 sudo ...
- JNI只C性能测试
深入学习JNI之前,介绍一个比较好的学习文档:jni详细教程.我这里只是一个Demo测试性能,至于入门教程请看我前一篇博文. Demo展示 这个Demo用于从小到大的冒泡排序,App.java代码: ...
- 第二章 mac上运行第一个appium实例
一.打开appium客户端工具 1 检查环境是否正常运行: 点击左边第三个图标 这是测试你环境是否都配置成功了 2 执行的过程中,遇到Could not detect Mac OS ...
- oracle目录操作
1.创建目录 create directory dir_name as 'dir_path' (dir_path必须事先手动创建) 2.授权 grant read,write on director ...
- JavaScript 图片轮播入门
轮播要求:一个在页面居中的矩形框,图片依次从矩形框中经过 当图片完整占满矩形框时 停留一小段时间再向左边移动经过矩形框的图片自动跑到右边最后一个图的后面.核心原理:在一个for循环中利用offsetl ...
- Java面试04|Spring框架
1.动态代理的几种方式 Java主要有两种代理,JDK和Cglib动态代理.先看JDK代理实例如下: JDK创建代理有一个限制,即它只能为接口创建代理实例.举个例子如下: public interfa ...
- node c++多线程插件构想
最近想写一个node的c++插件实现线程.提供的api使用回调并进行二次包装使其返回一个promise,并且要求需要在工作线程里执行的函数为async函数.如果是node7.0以下的版本,函数必须返回 ...
- 1084: [SCOI2005]最大子矩阵
1084: [SCOI2005]最大子矩阵 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1325 Solved: 670[Submit][Stat ...
- CoreAnimation 核心动画
- (void)createBaseAnimation{ //基础动画 CABasicAnimation *animation = [CABasicAnimation animation]; anim ...
- 统计solr multivalued 字段中数目
问题是这样的:已有若干multivalued 字段, 需要统计出 multivalued 字段中数目. 比如 *DOC1* <doc> <arr name="multi&q ...