deeplearning.ai 卷积神经网络 Week 4 特殊应用:人脸识别和神经风格转换 听课笔记
本周课程的主题是两大应用:人脸检测和风格迁移。
1. Face verification vs. face recognition
Verification: 一对一的问题。
1) 输入:image, name/ID.
2) 输出:image是否对应这个name/ID。
Recognition: 一对多的问题。
1) 数据库存了K个人。
2)输入:图片。
3)输出:如果图片中的人属于数据库,则输出ID;否则显示“not recognized”。
Verification是基础组建,正确率足够高之后,则可以用于recognition。
2. One-shot learning
人脸检测比较难的地方在于只能通过一个样本来进行学习。对于常规的卷积神经网络(CONV -> softmax),表现很差,因为单个样本不足以训练鲁棒的神经网络;另一方面,如果加入新人,softmax的输出就得多一个元素,这意味着要重新训练网络。
解决的办法是学习“similarity”函数:d(img1, img2) = degree of difference between images. 如果d(img1, img2)小于某个阈值(这是一个超参数),则判断同一个人;否则判断是不同的人。
3. Siamese network(Taigman et. al., 2014. DeepFace closing the gap to human level performance.)
常规的卷积神经网络在卷积层、池化层、全连接层等之后会得到n*1的向量,然后把这个向量送入softmax函数,得到具体分类。Siamese network舍弃了最后的softmax层,把n*1(比如128*1)的向量 f(x(k)) 作为输入图片 x(k) 的编码,两张图片的相似性就用这个编码的差的范数 d(img i, img j)=||f(x(i))-f(x(j))||2 来表征。神经网络不同的权重参数,可以计算出不同的编码。我们训练网络的目的就是训练出一组编码,使得对于相同得人的图片d(img i, img j)足够高,对于不同的人的图片d(img i, img j)足够低。
4. Triplet loss(Schroff et al., FaceNet: A unified embedding for face reconition and clustering.)
叫triplet的原因是会同时看三张图片,一张是参照图片Anchor,一张是正例(Positive),一张是反例(Negative)。我们希望 d(A, P)+α≤d(A, N),其中d(A, P)=||f(A)-f(P)||2,d(A, N)=||f(A)-f(N)||2,α是margin。
单个样本的 Loss function: L(A, P, N) = max( ||f(A)-f(P)||2 - ||f(A)-f(N)||2 + α, 0),这里加上max的意思是只要小于等于0就可以了,不在乎让loss function更小。
整个网络的 Cost function:J = ∑L(A(i), P(i), N(i))。训练集可能是1000个人的10k张图片,把这10k张图片组合成(A, P, N)的三元组来训练网络。注意,这里需要同一个人的一对图片A和P,如果训练集里每个人只有一张图片,这个算法是训练不了的。训练好网络之后,可以每个人只有一张照片。
如何组合(A, P, N)三元组?如果随机选择,那么d(A, P)+α≤d(A, N)太容易训练了。所以我们要找难训练的,即d(A, P) ≈ d(A, N)的情况,神经网络会努力让左边的变小,右边的变大。
5. 二分类的算法(Taigman et. al., 2014. DeepFace closing the gap to human level performance.)
不同于triplet loss的算法,也可以把人脸检测定义为二分类问题,用同一个神经网络把任意两张图片分别转成编码,然后用sigmoid处理编码,如果是同一个人则输出1,否则输出0。
预测的分类 y_hat = σ( ∑wk|f(x(i))k - f(x(j))k| +b),这里σ()是sigmoid函数,f(x(i))k表示图片x(i)的编码f(x(i))的第k个元素,如果编码一共128个元素,则求和符号就是做128次加法。也可以选择其他的预测函数,比如 y_hat = σ( ∑wk (f(x(i))k - f(x(j))k)2 / (f(x(i))k + f(x(j))k)+b),这是χ2相似度(Kai平方)。
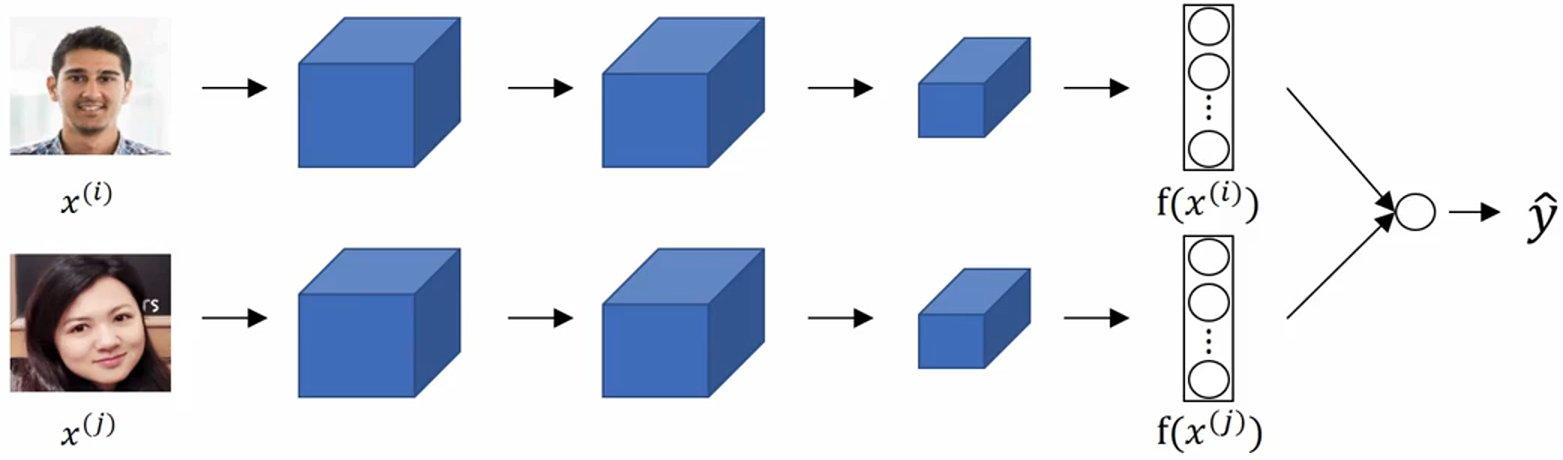
实际部署的时候,x(i)是要检测的新图片,x(j)是数据库里的图片,数据库里的图片可以不用每次都计算,可以直接预先计算(precompute)好编码f(x(j)),这样只需要每次计算x(i)的编码就行了。
6. 风格迁移(Gatys et. al., 2015. A neural algorithm of artistic style.)
一张内容(Content)图片C,一张风格(Style)图片S,生成(Generate)一张新的图片G。
Cost function: J(G) = αJcontent(C, G)+βJstyle(S, G)。前者评估C和G的相似度,后者评估S和G的相似度,α和β是权重(NG说这边一个超参数就够了,但原文作者使用了两个)。具体算法是:1)用随机数初始化G,得到一张白噪声的图片;2)梯度下降最小化J(G)。
Content cost function:用一个预训练过得卷积神经网络(比如VGG),选其中不要太浅(会非常具体地要求两张图片尽量相同)也不要太深(会非常抽象地检测图片中是否有狗)的隐藏层l。假设a[l](C)和a[l](C)分别表示内容图片C和生成图片G在第l层的激活函数值,如果这两个激活值相似,则两张图片内容相似。Jcontent(C, G) = 1/2*||a[l](c) - a[l](G)||2,对应元素的差的平方和。
Style cost function:图片的风格是用图片不同通道间的相关性来表征的。计算出两张图片在每一个隐藏层的style matrix的差,然后把所有层的都加起来。
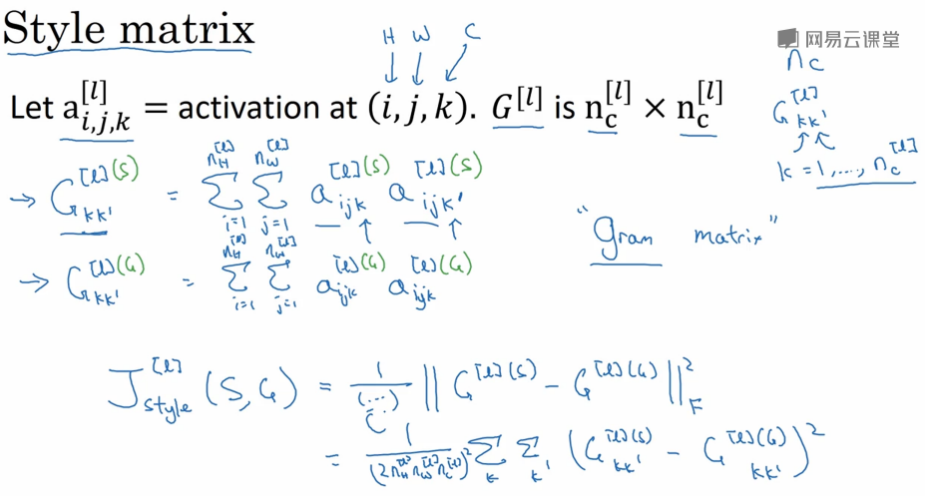

7. 卷积神经网络主要针对2D的图像,但也可以推广到1D和3D的情况
1D的例子:心电图诊断,1*14的信号和1*5的filter做卷积(和图像一样,这里其实也是相关,因为信号没有flip),在信号中找filter类似的特征。如果信号有不同的通道,则filter对应的也有那么多通道。
3D的例子:CT诊断,14*14*14*1的数据和5*5*5*1的filter做卷积,最后一个数字1是指通道数量。另一个应用是视频中检测物体、人物行为等。
deeplearning.ai 卷积神经网络 Week 4 特殊应用:人脸识别和神经风格转换 听课笔记的更多相关文章
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week4 特殊应用:人力脸识别和神经风格转换
一.什么是人脸识别 老实说这一节中的人脸识别技术的演示的确很牛bi,但是演技好尴尬,233333 啥是人脸识别就不用介绍了,下面笔记会介绍如何实现人脸识别. 二.One-shot(一次)学习 假设我们 ...
- deeplearning.ai 卷积神经网络 Week 3 目标检测 听课笔记
本周的主题是对象检测(object detection):不但需要检测出物体(image classification),还要能定位出在图片的具体位置(classification with loca ...
- deeplearning.ai 卷积神经网络 Week 1 卷积神经网络 听课笔记
1. 传统的边缘检测(比如Sobel)手工设计了3*3的filter(或者叫kernel)的9个权重,在深度学习中,这9个权重都是学习出来的参数,会比手工设计的filter更好,不但可以提取90度.0 ...
- deeplearning.ai 卷积神经网络 Week 3 目标检测
本周的主题是对象检测(object detection):不但需要检测出物体(image classification),还要能定位出在图片的具体位置(classification with loca ...
- deeplearning.ai 卷积神经网络 Week 1 卷积神经网络
1. 传统的边缘检测(比如Sobel)手工设计了3*3的filter(或者叫kernel)的9个权重,在深度学习中,这9个权重都是学习出来的参数,会比手工设计的filter更好,不但可以提取90度.0 ...
- deeplearning.ai 卷积神经网络 Week 2 深度卷积网络:实例研究 听课笔记
1. Case study:学习经典网络的原因是它们可以被迁移到其他任务中. 1.1)几种经典的网络: a)LeNet-5(LeCun et al., 1998. Gradient-based lea ...
- deeplearning.ai 卷积神经网络 Week 2 卷积神经网络经典架构
1. Case study:学习经典网络的原因是它们可以被迁移到其他任务中. 1.1)几种经典的网络: a)LeNet-5(LeCun et al., 1998. Gradient-based lea ...
- 深度学习项目——基于卷积神经网络(CNN)的人脸在线识别系统
基于卷积神经网络(CNN)的人脸在线识别系统 本设计研究人脸识别技术,基于卷积神经网络构建了一套人脸在线检测识别系统,系统将由以下几个部分构成: 制作人脸数据集.CNN神经网络模型训练.人脸检测.人脸 ...
- 吴恩达deepLearning.ai循环神经网络RNN学习笔记_看图就懂了!!!(理论篇)
前言 目录: RNN提出的背景 - 一个问题 - 为什么不用标准神经网络 - RNN模型怎么解决这个问题 - RNN模型适用的数据特征 - RNN几种类型 RNN模型结构 - RNN block - ...
随机推荐
- .NET 绝对路径的配置
有时候因为用IIS配置网站,会导致一些全局引用有路径问题无法引用到.今天就说一下,关于全局引用的绝对路径的配置,譬如,由于IIS配置的虚拟路径,一些CSS,JS的引用找不到,又或者自定义的一些跳转出现 ...
- 【java】泛型的作用是在编译阶段防止错误输入,绕过编译就绕过泛型,可用反射验证
package com.tn.collect; import java.lang.reflect.Method; import java.util.ArrayList; public class Fa ...
- iOS 工程默认只允许竖屏,在单独界面进行横竖转换,屏幕旋转
只含有 .关于横竖屏的代码 #import "InspectionReportViewController.h" #define SCREEN_WIDTH ([UIScreen m ...
- TCP/IP协议族各层的作用
从协议分层模型方面来讲,TCP/IP由四个层次组成:数据链路层.网络层.传输层.应用层一.数据链路层 数据链路层是负责接收IP数据报并通过网络发送之,或者从网络上接收物理帧,抽出IP数据报,交给IP层 ...
- 使用JavaScript将图片保存至本地
在最近的开发当中,我们需要为img标签以及canvas动态绘制的图像提供下载功能,下面是经过探索后我们得出的结果. 一.Canvas 版本 // 下载Canvas元素的图片 function down ...
- Golang中的坑二
Golang中的坑二 for ...range 最近两周用Golang做项目,编写web服务,两周时间写了大概五千行代码(业务代码加单元测试用例代码).用Go的感觉很爽,编码效率高,运行效率也不错,用 ...
- js间隔几秒弹出一次联系框
运行效果截图如下: 在线演示地址如下: http://demo.jb51.net/js/2015/js-3-sec-alert-dlg-codes/ 具体代码如下: <html> < ...
- ADO.NET查询和操作数据库
stringbuilder 类 stringbuilder类:用来定义可变字符串 stringbulider Append(string value) 在结尾追加 stringbuilder in ...
- shell的含义
shell:壳,是操作linux最直接的方式,通过shell中输入命令和linux系统进行交互. shell是一个小盒子,每一个有独立的命名空间,登录后的操作就是一个shell(有可能是bash,zs ...
- Netty对Protocol Buffer多协议的支持(八)
Netty对Protocol Buffer多协议的支持(八) 一.背景 在上篇博文中笔者已经用代码演示了如何在netty中使用Protocol Buffer,然而细心的用户可能会发现一个明显的不足之处 ...