Java NIO (二) 缓冲区(Buffer)
缓冲区(Buffer):一个用于特定基本数据类型的容器,由 java.nio 包定义的,所有缓冲区都是 Buffer 抽象类的子类。
Java NIO 中的Buffer 主要用于和NIO中的通道(Channel)进行交互, 数据从通道(Channel)读入缓冲区(Buffer)或者从缓冲区(Buffer)写入通道(Channel)。如下,我画的一个简图,Chanenl直接和数据源或者目的位置接触,Buffer作为中介这,从一个Channel中读取数据,然后将数据写入另一个Channel中。

Buffer 就像一个数组,可以保存多个相同类型的数据。根据数据类型不同(boolean 除外) ,有以下 Buffer 常用子类:
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
上述 Buffer 类 他们都采用相似的方法进行管理数据,只是各自管理的数据类型不同而已。都是通过如下方法获取一个 Buffer对象:
static XxxBuffer allocate(int capacity) : 创建一个容量为capacity 的 XxxBuffer 对象 ,如下创建了一个容量为1024的ByteBuffer 。
ByteBuffer buffer = ByteBuffer.allocate(1024);
前面说Buffer就像一个数据,实质Buffer的内部存放数据的就是一个对应类型的数组,如下看源码:
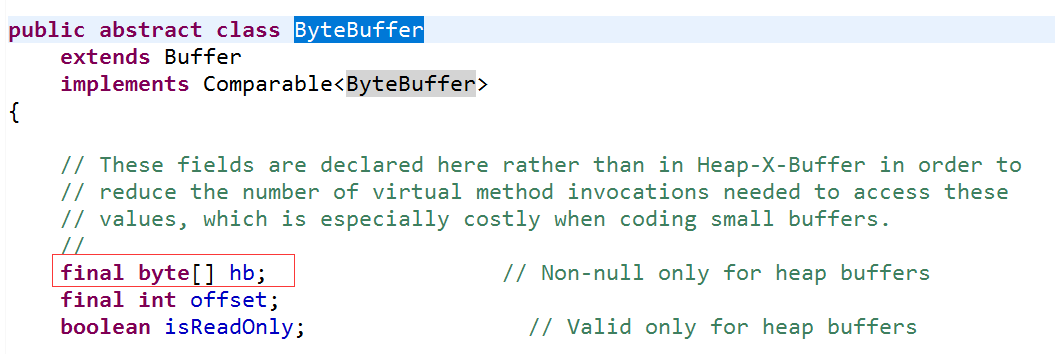
其他类型的Buffer类似。
Buffer的几个主要属性:
position : 下一个要读取或者写入数据的索引,其值不能为负不能大于limit。
limit : 第一个不应该读取或者写入数据的索引,即位于limit的数据不可读写,其值不能为负不能大于总容量。
capacity : 创建Buffer的最大容量,不能为负值,创建后不能修改。
如下图超类变量的定义:

1. 如下创建一个容量为 10 的Buffer (下标为 0-9 ,下标为10的不在Buffer容量中):

position : 0
capacity :10
limit :10
2. 向上图中的Buffer写入五个元素后:

position : 5
capacity :10
limit :10
3. 使用 buffer.flip()函数转换为读模式后:

position : 5
capacity :10
limit :10
mark 为标记一个操作过了的位置。
所以有: mark <= position <= limit <= capacity
Buffer的几个常用函数:
Buffer clear() :清空缓冲区并返回对缓冲区的引用
Buffer flip():将缓冲区的界限设置为当前位置,并将当前位置充值为 0
int capacity():返回 Buffer 的 capacity 大小
boolean hasRemaining():判断缓冲区中是否还有元素
int limit():返回 Buffer 的界限(limit) 的位置
Buffer limit(int n):将设置缓冲区界限为 n, 并返回一个具有新 limit 的缓冲区对象
Buffer mark():对缓冲区设置标记
int position():返回缓冲区的当前位置 position
Buffer position(int n):将设置缓冲区的当前位置为 n , 并返回修改后的 Buffer 对象
int remaining():返回 position 和 limit 之间的元素个数
Buffer reset() :将位置 position 转到以前设置的mark 所在的位置
Buffer rewind():将位置设为为 0, 取消设置的 mark
下面用一段代码来看各个方法调用后,position,capacity,limit的变化:
public class BufferTest {
@Test
public void test(){
String str = "abcde";
//1. 分配一个指定大小的缓冲区
ByteBuffer buf = ByteBuffer.allocate(1024);
System.out.println("-----------------allocate()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//2. 利用 put() 存入数据到缓冲区中
buf.put(str.getBytes());
System.out.println("-----------------put()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//3. 切换读取数据模式
buf.flip();
System.out.println("-----------------flip()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//4. 利用 get() 读取缓冲区中的数据
byte[] dst = new byte[buf.limit()];
buf.get(dst);
System.out.println(new String(dst, 0, dst.length));
System.out.println("-----------------get()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//5. rewind() : 可重复读
buf.rewind();
System.out.println("-----------------rewind()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//6. clear() : 清空缓冲区. 但是缓冲区中的数据依然存在,但是处于“被遗忘”状态
buf.clear();
System.out.println("-----------------clear()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
System.out.println((char)buf.get());
}
}
运行结果:
-----------------allocate()----------------
0
1024
1024
-----------------put()----------------
5
1024
1024
-----------------flip()----------------
0
5
1024
abcde
-----------------get()----------------
5
5
1024
-----------------rewind()----------------
0
5
1024
-----------------clear()----------------
0
1024
1024
a
Buffer的存取方法:
获取 Buffer 中的数据
get() :读取单个字节
get(byte[] dst):批量读取多个字节到 dst 中
get(int index):读取指定索引位置的字节(不会移动 position)
放入数据到 Buffer 中
put(byte b):将给定单个字节写入缓冲区的当前位置
put(byte[] src):将 src 中的字节写入缓冲区的当前位置
put(int index, byte b):将指定字节写入缓冲区的索引位置(不会移动 position)
非直接缓冲和直接缓冲区(对于字节缓冲区而言)
1. 非直接缓冲区
ByteBuffer buf = ByteBuffer.allocate(1024);
2. 直接缓冲区
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
① 字节缓冲区要么是直接的,要么是非直接的。如果为直接字节缓冲区,则 Java 虚拟机会尽最大努力直接在此缓冲区上执行本机 I/O 操作。也就是说,在每次调用基础操作系统的一个本机 I/O 操作之前(或之后),虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容)。
② 直接字节缓冲区可以通过调用此类的 allocateDirect() 工厂方法来创建。此方法返回的缓冲区进行分配和取消分配所需成本通常高于非直接缓冲区。直接缓冲区的内容可以驻留在常规的垃圾回收堆之外,因此,它们对应用程序的内存需求量造成的影响可能并不明显。所以,建议将直接缓冲区主要分配给那些易受基础系统的本机 I/O 操作影响的大型、持久的缓冲区。一般情况下,最好仅在直接缓冲区能在程序性能方面带来明显好处时分配它们。
③ 直接字节缓冲区还可以通过FileChannel 的 map() 方法 将文件区域直接映射到内存中来创建。该方法返回MappedByteBuffer 。Java 平台的实现有助于通过 JNI 从本机代码创建直接字节缓冲区。如果以上这些缓冲区中的某个缓冲区实例指的是不可访问的内存区域,则试图访问该区域不会更改该缓冲区的内容,并且将会在访问期间或稍后的某个时间导致抛出不确定的异常。
④字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用其 isDirect() 方法来确定。提供此方法是为了能够在性能关键型代码中执行显式缓冲区管理。
参考资料:李贺飞 老师的视频教程
Java NIO (二) 缓冲区(Buffer)的更多相关文章
- Java NIO之缓冲区Buffer
Java NIO的核心部件: Buffer Channel Selector Buffer 是一个数组,但具有内部状态.如下4个索引: capacity:总容量 position:下一个要读取/写入的 ...
- Java NIO流 -- 缓冲区(Buffer,ByteBuffer)
用来定义缓冲区的所有类都以Buffer类为基类,Buffer定义了缓冲区的基本特征. 直接子类: ByteBuffer 用来存储byte类型的缓冲区,可以在这种缓冲区中存储任意其他基本类型的二进制值( ...
- Java NIO中的Buffer 详解
Java NIO中的Buffer用于和NIO通道进行交互.如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的.缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存.这块内存被包装成NIO ...
- NIO之缓冲区(Buffer)的数据存取
缓冲区(Buffer) 一个用于特定基本数据类行的容器.有java.nio包定义的,所有缓冲区都是抽象类Buffer的子类. Java NIO中的Buffer主要用于与NIO通道进行交互,数据是从通道 ...
- Java NIO Channel和Buffer
Java NIO Channel和Buffer @author ixenos Channel和Buffer的关系 1.NIO速度的提高来自于所使用的结构更接近于OS执行I/O的方式:通道和缓冲器: 2 ...
- Java NIO——2 缓冲区
一.缓冲区基础 1.缓冲区并不是多线程安全的. 2.属性(容量.上界.位置.标记) capacity limit 第一个不能被读或写的元素 position 下一个要被读或写的元素索引 mark ...
- Java NIO4:缓冲区Buffer(续)
一.什么是缓冲区 一个缓冲区对象是固定数量的数据的容器,其作用是一个存储器,或者分段运输区,在这里数据可被存储并在之后用于检索.缓冲区像前篇文章讨论的那样被写满和释放,对于每个非布尔原始数据 ...
- java NIO中的buffer和channel
缓冲区(Buffer):一,在 Java NIO 中负责数据的存取.缓冲区就是数组.用于存储不同数据类型的数据 根据数据类型不同(boolean 除外),提供了相应类型的缓冲区:ByteBufferC ...
- Java NIO 之缓冲区
缓冲区基础 所有的缓冲区都具有四个属性来 供关于其所包含的数据元素的信息. capacity(容量):缓冲区能够容纳数据的最大值,创建缓冲区后不能改变. limit(上界):缓冲区的第一个不能被读或写 ...
- Java NIO3:缓冲区Buffer
在上一篇中,我们介绍了NIO中的两个核心对象:缓冲区和通道,在谈到缓冲区时,我们说缓冲区对象本质上是一个数组,但它其实是一个特殊的数组,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况,如 ...
随机推荐
- js中一些注意点 ps不断更新中....
nextSibling 和 nextElementSibling 的区别 (previousSibling 和 previousElementSibling ) nextSibling 在IE8及以下 ...
- 360提供的php防注入代码
<?php //Code By Safe3 function customError($errno, $errstr, $errfile, $errline) { echo "< ...
- linux上安装php7 memcache扩展 和 安装服务端memcached
linux上安装memcached不算太困难.唯一让本人感到困难的是 php7的memcache扩展安装.真的蛋疼! 先说安装服务端 memcached 1. 首先安装Libevent事件触发管理器. ...
- Java分布式锁之数据库实现
之前的文章<Java分布式锁实现>中列举了分布式锁的3种实现方式,分别是基于数据库实现,基于缓存实现和基于zookeeper实现.三种实现方式各有可取之处,本篇文章就详细讲解一下Java分 ...
- mybatis实现延迟加载多对一
1.数据库表 CREATE TABLE `country` ( `cid` ) NOT NULL AUTO_INCREMENT COMMENT '国家id', `cname` ) COLLATE ut ...
- Python--Pycharm backup_ver1.py 控制台一直Backup FAILED
1.windows不自带zip,需自行安装,http://gnuwin32.sourceforge.net/packages/zip.htm 2.安装后,要配置环境变量:PATH 3.简明Python ...
- 学校的c++程序课程设计(简单的写法 并无太多c++的特色)
好久没更新博客了,最近一直在忙,花了一天时间做出这个简陋版的课程设计, 为了储存,也为了更新,所以于今天更新我的博客. 我选的课程设计题目如下: 某某公司的设备管理系统 功能及要求描述: (1)公司主 ...
- ubuntu14.04 升级mysql到5.7版本
Ubuntu14.04默认安装的是mysql5.5,由于开发需要支持utf8mb4,因此需要升级到mysql5.7 默认情况下,apt是无法直接升级到mysql5.7的,因此需要额外设置 首先,备份数 ...
- lucene6+HanLP中文分词
1.前言 前一阵把博客换了个模版,模版提供了一个搜索按钮,这让我想起一直以来都想折腾的全文搜索技术,于是就用lucene6.2.1加上HanLP的分词插件做了这么一个模块CSearch.效果看这里:h ...
- 如何通过PowerShell获取Office 365 TenantID
作者:陈希章 发表于2017年5月31日 安装Azure Powershell 模块 Installing the Azure PowerShell Service Management module ...