mysql 证明为什么用limit时,offset很大会影响性能
本文同时发表在https://github.com/zhangyachen/zhangyachen.github.io/issues/117
首先说明一下MySQL的版本:
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.17 |
+-----------+
1 row in set (0.00 sec)
表结构:
mysql> desc test;
+--------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------------+------+-----+---------+----------------+
| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment |
| val | int(10) unsigned | NO | MUL | 0 | |
| source | int(10) unsigned | NO | | 0 | |
+--------+---------------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
id为自增主键,val为非唯一索引。
灌入大量数据,共500万:
mysql> select count(*) from test;
+----------+
| count(*) |
+----------+
| 5242882 |
+----------+
1 row in set (4.25 sec)
我们知道,当limit offset rows中的offset很大时,会出现效率问题:
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (15.98 sec)
为了达到相同的目的,我们一般会改写成如下语句:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.38 sec)
时间相差很明显。
为什么会出现上面的结果?我们看一下select * from test where val=4 limit 300000,5;的查询过程:
- 查询到索引叶子节点数据。
- 根据叶子节点上的主键值去聚簇索引上查询需要的全部字段值。
类似于下面这张图:
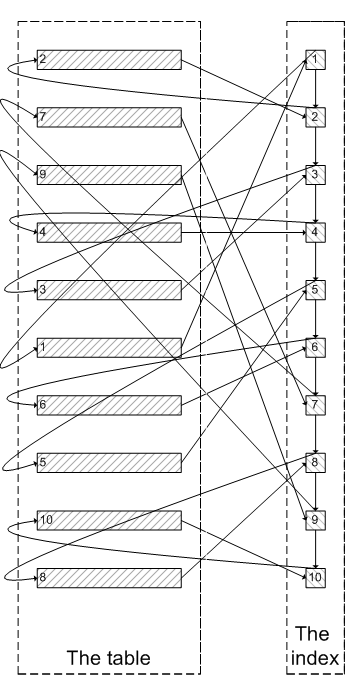
像上面这样,需要查询300005次索引节点,查询300005次聚簇索引的数据,最后再将结果过滤掉前300000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有300000次随机I/O查询到的数据是不会出现在结果集当中的。
肯定会有人问:既然一开始是利用索引的,为什么不先沿着索引叶子节点查询到最后需要的5个节点,然后再去聚簇索引中查询实际数据。这样只需要5次随机I/O,类似于下面图片的过程:
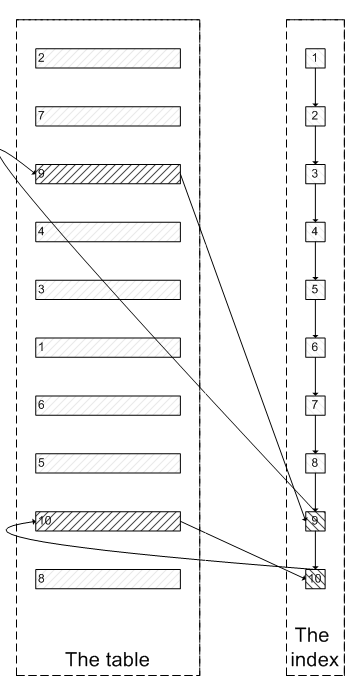
其实我也想问这个问题。
证实
下面我们实际操作一下来证实上述的推论:
为了证实select * from test where val=4 limit 300000,5是扫描300005个索引节点和300005个聚簇索引上的数据节点,我们需要知道MySQL有没有办法统计在一个sql中通过索引节点查询数据节点的次数。我先试了Handler_read_*系列,很遗憾没有一个变量能满足条件。
我只能通过间接的方式来证实:
InnoDB中有buffer pool。里面存有最近访问过的数据页,包括数据页和索引页。所以我们需要运行两个sql,来比较buffer pool中的数据页的数量。预测结果是运行select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;之后,buffer pool中的数据页的数量远远少于select * from test where val=4 limit 300000,5;对应的数量,因为前一个sql只访问5次数据页,而后一个sql访问300005次数据页。
select * from test where val=4 limit 300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.04 sec)
可以看出,目前buffer pool中没有关于test表的数据页。
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (26.19 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 4098 |
| val | 208 |
+------------+----------+
2 rows in set (0.04 sec)
可以看出,此时buffer pool中关于test表有4098个数据页,208个索引页。
select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id
为了防止上次试验的影响,我们需要清空buffer pool,重启mysql。
mysqladmin shutdown
/usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.03 sec)
运行sql:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.09 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 5 |
| val | 390 |
+------------+----------+
2 rows in set (0.03 sec)
我们可以看明显的看出两者的差别:第一个sql加载了4098个数据页到buffer pool,而第二个sql只加载了5个数据页到buffer pool。符合我们的预测。也证实了为什么第一个sql会慢:读取大量的无用数据行(300000),最后却抛弃掉。
而且这会造成一个问题:加载了很多热点不是很高的数据页到buffer pool,会造成buffer pool的污染,占用buffer pool的空间。
遇到的问题
- 为了在每次重启时确保清空buffer pool,我们需要关闭
innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,这两个选项能够控制数据库关闭时dump出buffer pool中的数据和在数据库开启时载入在磁盘上备份buffer pool的数据。
参考资料:
mysql 证明为什么用limit时,offset很大会影响性能的更多相关文章
- mysql用limit时offset越大时间越长
首先说明一下MySQL的版本:mysql> select version();+-----------+| version() |+-----------+| 5.7.17 |+----- ...
- mysql limit和offset用法
limit和offset用法 mysql里分页一般用limit来实现 1. select* from article LIMIT 1,3 2.select * from article LIMIT 3 ...
- mysql中limit 和 limit 与 offset 的用法(效果相同,用法不通过)
例1,假设数据库表student存在13条数据. 代码示例: 语句1:select * from student limit 9,4 语句2:slect * from student limit 4 ...
- MySQL 用 limit 为什么会影响性能?
一,前言 首先说明一下MySQL的版本: mysql> select version();+-----------+| version() |+-----------+| 5.7.17 |+-- ...
- LIMIT和OFFSET分页性能差!今天来介绍如何高性能分页
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. GreatSQL是MySQL的国产分支版本,使用上与MySQL一致. 前言 之前的大多数人分页采用的都是这样: SELEC ...
- MySQL在大数据Limit使用
它已被用于Oracle一世.但今天,很惊讶,MySQL在对数量级的性能,甚至差距如此之大不同的顺序相同的功能. 看看表ibmng(id,title,info) 只要 id key 指数title ...
- 第二百八十八节,MySQL数据库-索引、limit分页、执行计划、慢日志查询
MySQL数据库-索引.limit分页.执行计划.慢日志查询 索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构.类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获 ...
- MySQL里创建外键时错误的解决
--MySQL里创建外键时错误的解决 --------------------------------2014/04/30 在MySQL里创建外键时(Alter table xxx add const ...
- 【转】MySQL 当记录不存在时insert,当记录存在时update
MySQL当记录不存在时insert,当记录存在时更新:网上基本有三种解决方法 第一种: 示例一:insert多条记录 假设有一个主键为 client_id 的 clients 表,可以使用下面的语句 ...
随机推荐
- 关于回调(callback)
如果要理解回调,需要在分同步通信.异步通信的基础上了解 举个通俗的例子: 你打电话问书店老板有没有<JS>这本书,如果是同步通信机制,书店老板会说,你稍等,"我查一下" ...
- 《java.util.concurrent 包源码阅读》19 PriorityBlockingQueue
前面讲ScheduledThreadPoolExecutor曾经重点讲到了DelayedWorkQueue,这里说的PriorityBlockingQueue其实是DelayedWorkQueue的简 ...
- params SqlParameter[] commandParameters(转)
C#代码 ExecuteReader(string connectionString, CommandType commandType, string commandText, params Sql ...
- JSONP原理解析
前言 我工作以来接触的第一个项目就是前后端分离的,前端静态文件有自己独立域名,通过接口来获取数据进行渲染等操作. 跨域的方法不需要多言,随便一搜,就有很多,但最常用不外乎jsonp和CORS.json ...
- margin、padding单位百分比
年前做了一个测试题 https://www.wenjuan.com/s/VjaEva/,里面有一道题目涉及到了margin和padding单位为百分比的情况.写出来记录一下以防止自己忘记. <! ...
- sklearn 中 make_blobs模块使用
sklearn.datasets.make_blobs(n_samples=100, n_features=2, centers=3, cluster_std=1.0, center_box=(-10 ...
- MySQL服务找不到了,navicat打不开数据库连接
今天打开Navicat看看连接名,突然发现连接不上了,打开服务发现MySQL服务不见了,所以手动安装了遍MySQL服务. 详细步骤如下: 1.管理员身份打开cmd,切换到MySQL安装目录下的bin目 ...
- 推荐一个非常牛逼的并发httpful的库(php)
MultiHttp :结合了libcurl多线程.httpful方式的PHP库 This is high performance curl wrapper written in pure PHP. I ...
- haproxy,tomcat.apache记录用户真实IP
Haproxy配置: default加入: option httpclose option forwardfor Tomcat配置: server.xml中添加 prefix="localh ...
- Activit各个网关使用简单介绍
一.排他网关 Exclusive Gateway 排他网关又叫互斥网关,条件计算为true的顺序流会被选择继续流程,有且只有一条出口,如果出现多个条件为true,则会默认选择第一条true来执行,如果 ...