Hive(笔记)
(2015.07.22Hive笔记)
一、Hive的安装
1.1Hive的安装过程
下载hive源文件(apache-hive-0.14.0-bin.tar.gz )
解压hive文件
进入$HIVE_HOME/conf/修改文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template(模板文档,提供了hive很多参数) hive-site.xml


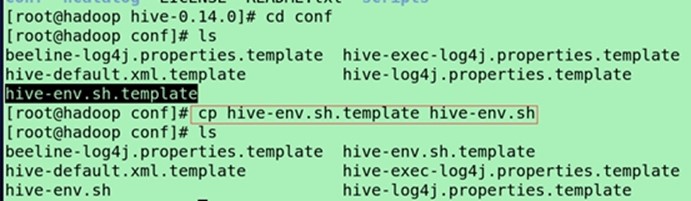
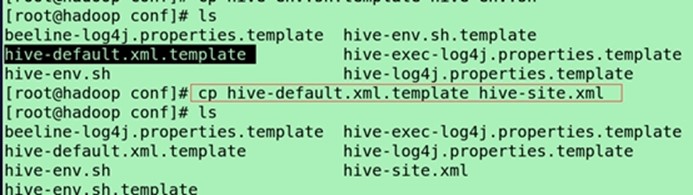
修改$HIVE_HOME/conf的hive-env.sh,增加以下三行
export JAVA_HOME=/usr/local/jdk1.7.0_45
export HIVE_HOME=/usr/local/hive-0.14.0
export HADOOP_HOME=/usr/local/hadoop-2.6.0

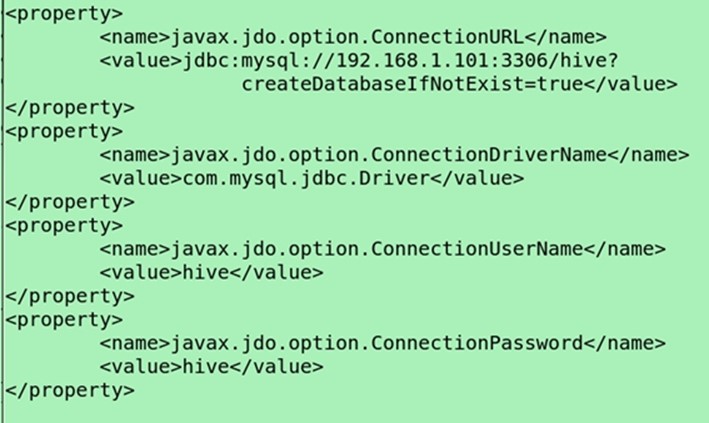
配置MySQL的metastore
修改$HIVE_HOME/conf/hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.101:3306/hive?
createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>(lib目录下默认没有驱动,需要自己下载mysql-connector-java-5.1.10.jar,因为自带了derby-10.10.1.1.jar,能启动derby数据库)
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/local/hive-0.14.0/tmp</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hive-0.14.0/tmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/hive-0.14.0/tmp</value>
</property>
连接本地Mysql解决办法(感谢为我提供帮助的国柱、其国、世昌师兄们和老师)
1.首先登陆到mysql
mysql -uroot -pmysql
2.创建远程登陆用户并授权
grant all PRIVILEGES on test_db.* to root@'192.168.1.101' identified by 'root';
3.执行了上面的语句后,再执行下面的语句,方可立即生效。
flush privileges;
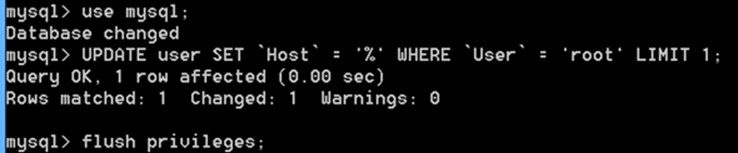
如果不行
先use mysql;
然后UPDATE user SET `Host` = '%' WHERE `User` = 'root' LIMIT 1;
flush privileges;
我还是有一些疑问1:现在不能用root用户登录,只能用其他用户登录对吗?其他用户的权限少了些什么?2配置文件连接的是192.168.1.101,在qlyog127.0.0.1新建一个hive数据库才能用(hive新建的表的元数据都保存在那里,而不是192.168.1.101)
新创建一个用户,不要用root,估计root串了。
use mysql;
grant all privileges on *.* to <用户名>@'%' identified by '密码';
flush privilege;
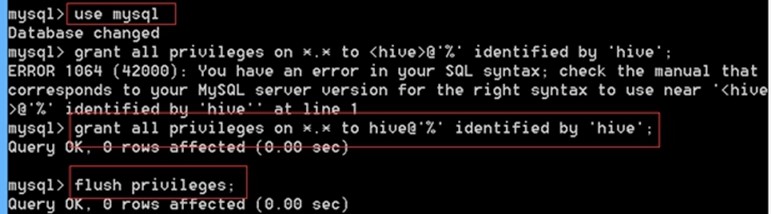
SELECT `Host`,`User` FROM user;
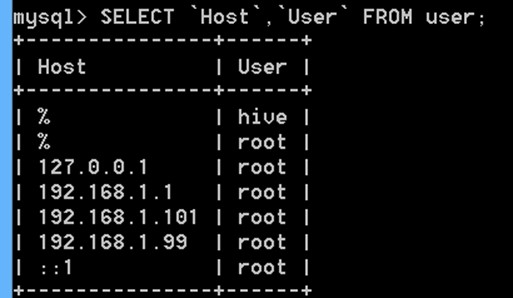
alter database hive character set latin1;

成功连接mysql启动hive



因为$HIVE_HOME/lib目录下有derby的jar包所以使用derby作为默认的metastore。
Hive1.2版本中的jline-2.12.jar包与hadoop2.6.0(jline-0.9.94.jar版本)不兼容,解决办法,将这个jar包复制到hadoop的lib目录下。
1.2hive web界面模式
web界面安装:
下载apache-hive-0.14.0-src.tar.gz(版本需要对应)
制作war包放在HIVE_HOME/lib/ : (apache-hive-0.14.0-src.tar\apache-hive-0.14.0-src\hwi将web解压出来,里面的jsp文件就是hwi的显示界面 )hwi/web/*里面所有的文件打成war包(压缩文件,并重命名为hive-hwi-0.14.0.war)
复制tool.jar(jdk的lib包下面的tool.jar包)到HIVE_HOME/lib下
修改hive-site.xml(HIVE_HOME/conf)
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-0.14.0.war</value>
</property>
hive web界面的 (端口号9999) 启动方式
#hive --service hwi &(&表示后台显示)
用于通过浏览器来访问hive
可以查看hive的系统信息,hadoop日志路径信息等

1.3set命令使用
hive控制台set命令:
set hive.cli.print.current.db=true;
set hive.cli.print.header=true;
set hive.metastore.warehouse.dir=/hive;
hive参数初始化配置set命令:
~/.hiverc(存放在每个用户的主目录下面,可以创建一个.hiverc,将set命令的参数复制进去,重新启动执行hive,就可以将set命令执行起来)
补充:
hive历史操作命令集(more .hivehistory查看一下)
~/.hivehistory
直接查看(执行set),查看hadoop定义的全部变量,hive底层依赖的hadoop环境变量配置信息(set -v)
设置name变量并初始化(set hivevar:name=crxy;)显示(set hivevar:name;),传值(create table t2(name string,${hivevar:name} string);)
- 基本数据类型

String和int在创建表,时间戳(hive与Hbase结合时,底层的映射结构,是自动完成,如果没有,hive与Hbase结合有困难)
2.1复合数据类型
创建学生表
hive>CREATE TABLE student(
id INT,
name STRING,
favors ARRAY<STRING>,
scores MAP<STRING, FLOAT>
);
2.2hive记录中默认分隔符
分隔符 描述 语句
\n 分隔行 LINES TERMINATED BY '\t'
^A 分隔字段(列),显示编码使用\001 FIELDS TERMINATED BY '\001'
^B 分隔复合类型中的元素,显示编码使用\002 COLLECTION ITEMS TERMINATED BY '\002'
^C 分隔map元素的key和value,显示编码使用\003 MAP KEYS TERMINATED BY '\003'
Hdfs存储表时用的是分隔符
原始数据组织方式(导入hive表前的数据)
1001\001zhangsan\001AA\002\BB\001key\003value 1002\001lisi
在hdfs数组存放方式
1001^Azhangsan^AAA^BBB^Akey^Cvalue\n1002^Alisi
2.3复合类型—Struct使用
structs内部的数据可以通过DOT(.)来存取,例如,表中一列c的类型为STRUCT{a INT; b INT},我们可以通过c.a来访问域a
hive> create table student_test(id INT, info struct<name:STRING, age:INT>) ROW FORMAT DELIMITED(限定) FIELDS TERMINATED(终止) BY ',' COLLECTION(集合) ITEMS TERMINATED BY ':'; (第一个是字段id与struct结构体的分隔符逗号或者tab(\t)都可以,第二个是struct分割)


vi student_test
1001,zhangsan:24
1002,lisi:28
1003,wangwu:25

(local inpath,应该就是为什么可以将/root/student_test传进去)

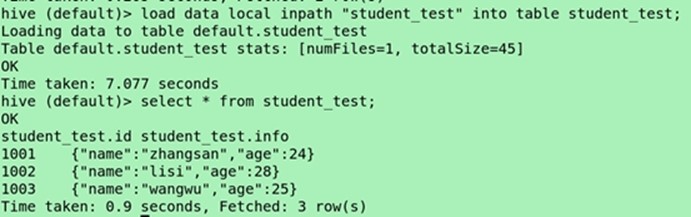
(导入数据)load data local inpath"student_test" into table student_test;
Select * from student_test;
(查询id)select id from student_test;
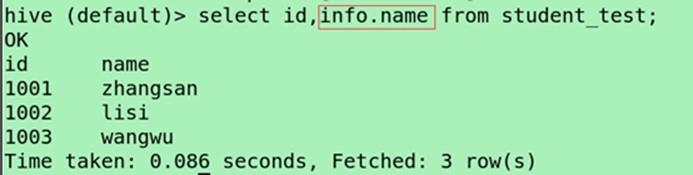
(查询structs内部数据,通过点的方式)
select id,info.name from student_test;
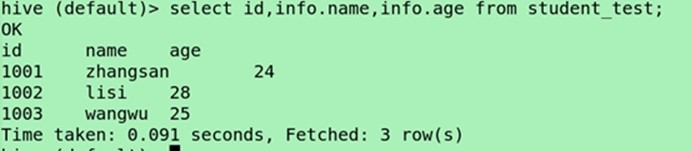
Select id,info.name,info.age from student_test;
可以直接在MySQL(储存的是元数据)查看创建的表
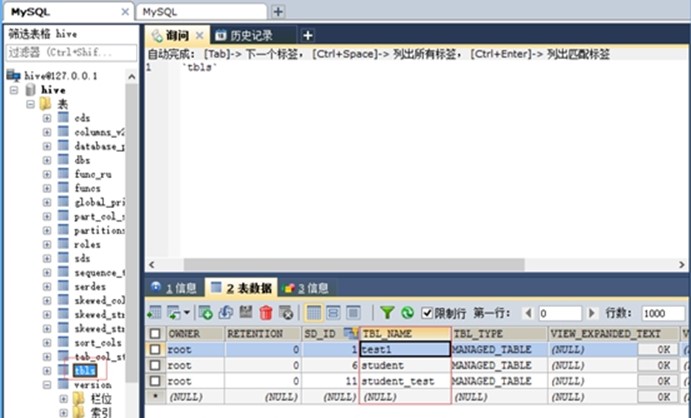
也可以在hdfs(储存的是表的实际信息)上查看
dfs -cat /usr/hive/warehouse/student_test/student_test;

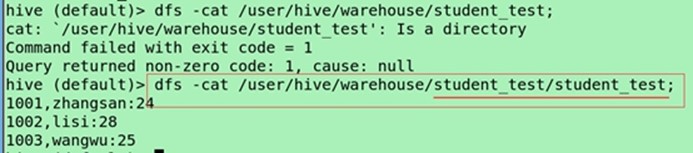
第一个是表名没有内容,第二个才是表的内容,除了默认格式不一样,指定格式显示就会一样的。
2.4复合类型—Array使用
array中的数据为相同类型,例如,假如array A中元素['a','b','c'],则A[1]的值为'b'
create table class_test(name string, student_id_list array<INT>) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY ':';
vi class_test
zhangsan,10:25:27:37
lisim,09:31:42:46
wangwu,06:12:18
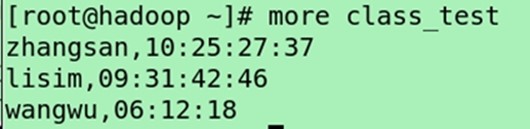
(导入表)load data local inpath "class_test" into table class_test;
select * from class_test;
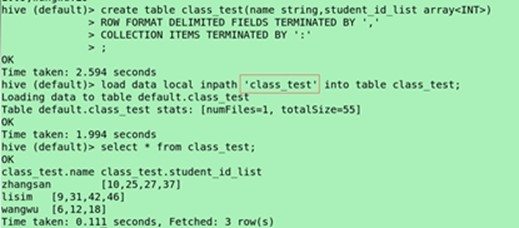
(查询名字)select name from class_test;

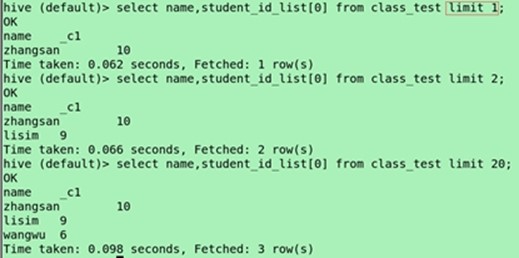
(集合类型的角标查询)select name,student_id_list[0] from class_test;

select name,lstudent_id_list[0] from class_test where name='zhangsan';

角标超出范围会显示NULL
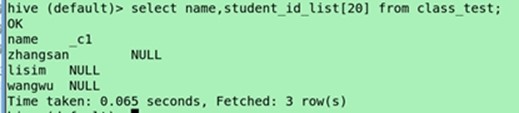
按照列解析的
2.5复合类型—Map使用
访问指定域可以通过["指定域名称"]进行,例如,一个Map M包含了一个group-》gid的kv对,gid的值可以通过M['group']来获取
create table employee(id string, perf map<string, int>) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY ':';
(字段之间使用的是\t(Tab键),集合(多个map就会是集合)之间的用,号,map之间用:分割)

vi employee(在~目录下面)
1001 job:80,team:60,person:70
1002 job:60,team:80,person:80
1003 job:90,team:70,person:100
Load data local inpath "employee" into table employee;(备注;使用双引号和单引号也是可以的。)

(查询)Select *from employee;
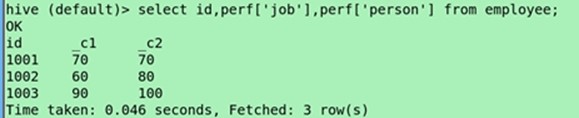
Select id,perf['job'] from employee;

Select id,perf['job'],perf['person'] from employee;
(设置别名,显示表头)select id,perf['job'] as job,perf['team'] as team,perf['person'] as person from employee;

三、数据定义
3.1数据库定义
默认数据库"default"
使用#hive命令后,不使用hive>use <数据库名>,系统默认的数据库。可以显式使用hive> use default;
创建一个新库
hive>CREATE DATABASE
[IF NOT EXISTS] mydb
[LOCATION] '/.......'
[COMMENT] '....';
hive>SHOW DATABASES;
hive>DESCRIBE DATABASE [extended] mydb;
hive>DROP DATABASE [IF EXISTS] mydb [CASCADE];
Create database mydb;
在hdfs创建mydb.db目录会存放mydb数据里面的内容
消除不必要的提示(干扰我们的判断)

Create database if not exists mydb;

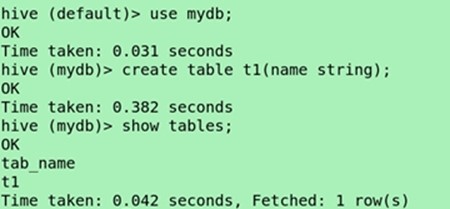
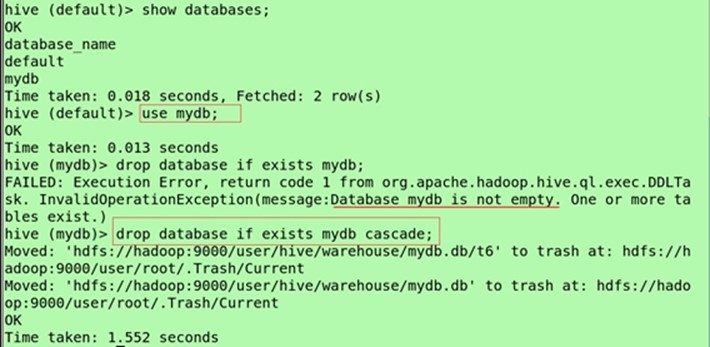
Use mydb;
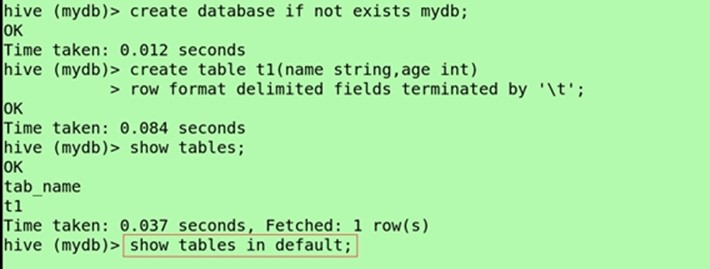
Create table t1(name string);
Show tables;

Create database bd;
Show databases;
Drop database if exists db;
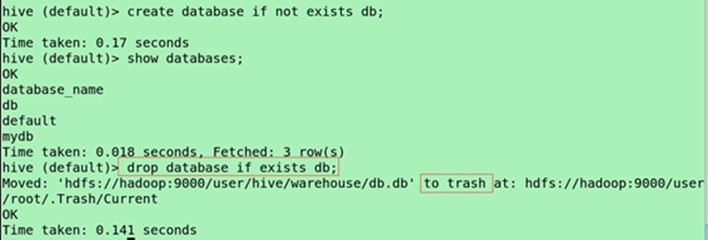
(级联删除)
drop database if exists mydb cascade;
3.2 表定义
hive>CREATE TABLE IF NOT EXISTS t1(...)
[COMMENT '....']
[LOCATION '...']
(当前数据库显示其他数据库的表)hive>SHOW TABLES in mydb;
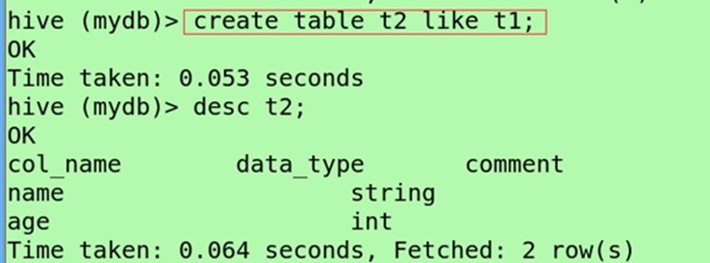
hive>CREATE TABLE t2 LIKE t1;
hive>DESCRIBE t2;
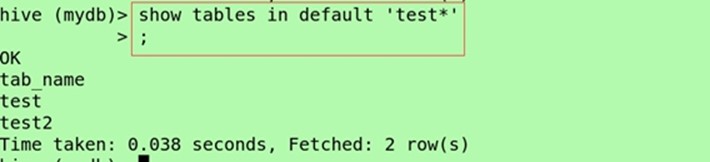
(寻找某个关键字的表)show tables in default 'class*';
(显示表的结构)desc t1;
(显示表的结构,原来的)describe t1;

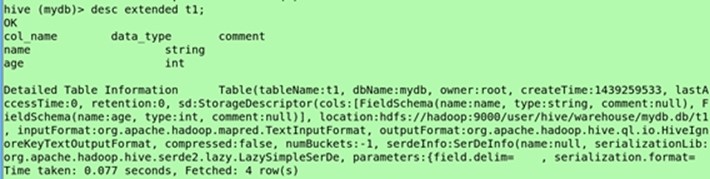
(显示拓展信息)desc extended t1;
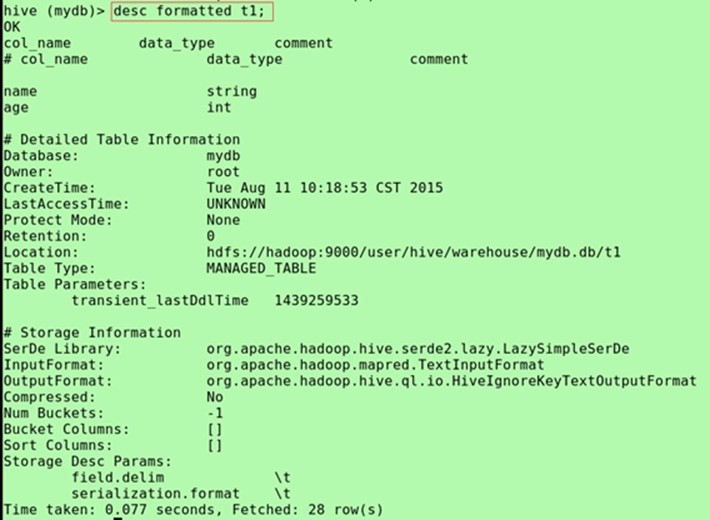
(显示拓展信息更加有结构,查看分隔符)desc formatted t1;
(创建另一个表进行测试,防止操作不当对原表造成伤害)create table t2 like t1;
(复制其他数据库的表的结构)Create table t3 like default.employee;

Hive(笔记)的更多相关文章
- Hive笔记--sql语法详解及JavaAPI
Hive SQL 语法详解:http://blog.csdn.net/hguisu/article/details/7256833Hive SQL 学习笔记(常用):http://blog.sina. ...
- Hive 笔记
DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees ...
- hive笔记(自学整理的)
第一部分:用户管理 创建用户:CREATE DATABASE XXX 查看用户:SHOW DATABASES; 关键查看用户:show databases like 'de.*' 讲解:创建一个用 ...
- Hive笔记--配置以及遇到的问题
ubuntu安装mysql http://www.2cto.com/database/201401/273423.html Hive安装: http://www.aboutyun.com/forum ...
- Hive笔记——技术点汇总
目录 · 概况 · 手工安装 · 引言 · 创建HDFS目录 · 创建元数据库 · 配置文件 · 测试 · 原理 · 架构 · 与关系型数据库对比 · API · WordCount · 命令 · 数 ...
- hive笔记:复杂数据类型-map结构
map 结构 1. 语法:map(k1,v1,k2,v2,…) 操作类型:map ,map类型的数据可以通过'列名['key']的方式访问 案例: select deductions['Feder ...
- hive笔记
cast cast(number as string), 可以将整数转成字符串 lpad rpad lpad(target, 10, '0') 表示在target字符串前面补0,构成一个长度为 ...
- hive笔记:时间格式的统一
一.string类型,年月日部分包含的时间统一格式: 原数据格式(时间字段为string类型) 取数时间和格式的语法 2018-11-01 00:12:49.0 substr(regexp_repl ...
- hive笔记:转义字符的使用
hive中的转义符 Hadoop和Hive都是用UTF-8编码的,所以, 所有中文必须是UTF-8编码, 才能正常使用 备注:中文数据load到表里面, 如果字符集不同,很有可能全是乱码需要做转码的, ...
- hive笔记:复杂数据类型-array结构
array 结构 (1)语法:array(val1,val2,val3,…) 操作类型:array array类型的数据可以通过'数组名[index]'的方式访问,index从0开始: (2)建表: ...
随机推荐
- MongoDB基础之五:游标
1.cursor(游标)是什么 ? 通俗的说,游标不是查询结果,而是查询的返回资源,或者接口. 通过这个接口,你可以逐条读取. 就像php中的fopen打开文件,得到一个资源一样, 通过资源,可以一行 ...
- matlab中运用项目思维分析问题并解决问题
我们将沿着以下几步思考:1.State the problem关于这个例子陈述问题很简单.我们想写一个判定二元一次方程的程序:是否有两个实根,重复实根,或者两个复数根2.Define the inpu ...
- React 国际化
前言 React 做国际化,我推荐使用 React-intl , 这个库提供了 React 组件和Api两种方式来格式化日期,数字和字符串等.知道这个库了,那让我们开始使用它 组件用法 为了和Reac ...
- Javascript面对对象. 第四篇
原型模式创建对象也有自己的缺点,它省略看构造函数传参初始化这一过程,带来的缺点就是初始化的值都是一致的. 而原型最大的缺点就是它优点,那就是共享. 原型中所有属性是被很多实例共享的,共享对于函数非常合 ...
- node-webkit制作桌面应用
心血来潮突然想用js尝试写桌面应用,突然发现我大js真的无所不能.在网上搜到了这么一个东东:node-webkit.用Node.js来进行系统资源的访问,用HTML+CSS完成页面的搭建.哇,一切突然 ...
- 继续学习ant
今天由于打电话,打了两个小时的电话,结果一下子错过了学习的时间段,表示很惭愧,不过查了一些资料,感觉还不错,明天继续学习吧! ant入门到精通Ant 的最完整build.xml解释ant实用实例Ant ...
- 读书笔记 effective c++ Item 18 使接口容易被正确使用,不容易被误用
1. 什么样的接口才是好的接口 C++中充斥着接口:函数接口,类接口,模板接口.每个接口都是客户同你的代码进行交互的一种方法.假设你正在面对的是一些“讲道理”的人员,这些客户尝试把工作做好,他们希望能 ...
- 3D Touch开发
一.3d Touch 官方文档介绍 1.A user can now press your Home screen icon to immediately access functionality p ...
- BZOJ 1095: [ZJOI2007]Hide 捉迷藏(线段树维护括号序列)
这个嘛= =链剖貌似可行,不过好像代码长度很长,懒得打(其实是自己太弱了QAQ)百度了一下才知道有一种高大上的叫括号序列的东西= = 岛娘真是太厉害了,先丢链接:http://www.shuizilo ...
- BZOJ USACO 银组 水题集锦
最近刷银组刷得好欢快,好像都是水题,在这里吧他们都记录一下吧(都是水题大家一定是道道都虐的把= =)几道比较神奇的题到时再列出来单独讲一下吧= =(其实我会说是BZOJ蹦了无聊再来写的么 = =) [ ...