Linux下的I/O模型以及各自的优缺点
其实关于这方面的知识,我阅读的是《UNIX网络编程:卷一》,书里是以UNIX为中心展开描述的,根据这部分知识,在网上参考了部分资料。以Linux为中心整理了这篇博客。
Linux的I/O模型
和Unix的I/O模型基本一致,Linux下一共有5种I/O模型[1]
- 阻塞式I/O模型;
- 非阻塞式I/O模型;
- I/O复用式模型;
- 信号驱动动式I/O模型
- 异步I/O模型
上面这个列表,算是绝大部分关于Linux I/O模型博客中都会贴出来的。
在上述5种I/O模型中,前4种,其实都可以划分为同步I/O方式,只有最有一种异步I/O模型才使用异步I/O方式。
为什么这么划分呢,就得仔细看看这5种I/O模型到底是什么。
行文须知
下文中对各个模型的描述,都是使用数据报(UDP)套接字作为例子进行说明的。
因为UDP相对与TCP来说比较简单——要么整个数据报已经收到,要么还没有——而对于TCP来说,套接字低水位标记等额外变量开始起作用,导致整个概念变得复杂。(加粗字体的内容在写这篇博客时,并没有搞清楚是什么,可能后续会陆续搞懂)
一、阻塞式I/O
通常我们使用的I/O都是阻塞式I/O,在编程时使用的大多数也是阻塞式I/O。在默认情况下,所有的套接字(socket)都是阻塞的。下图解释了阻塞式I/O模型的流程
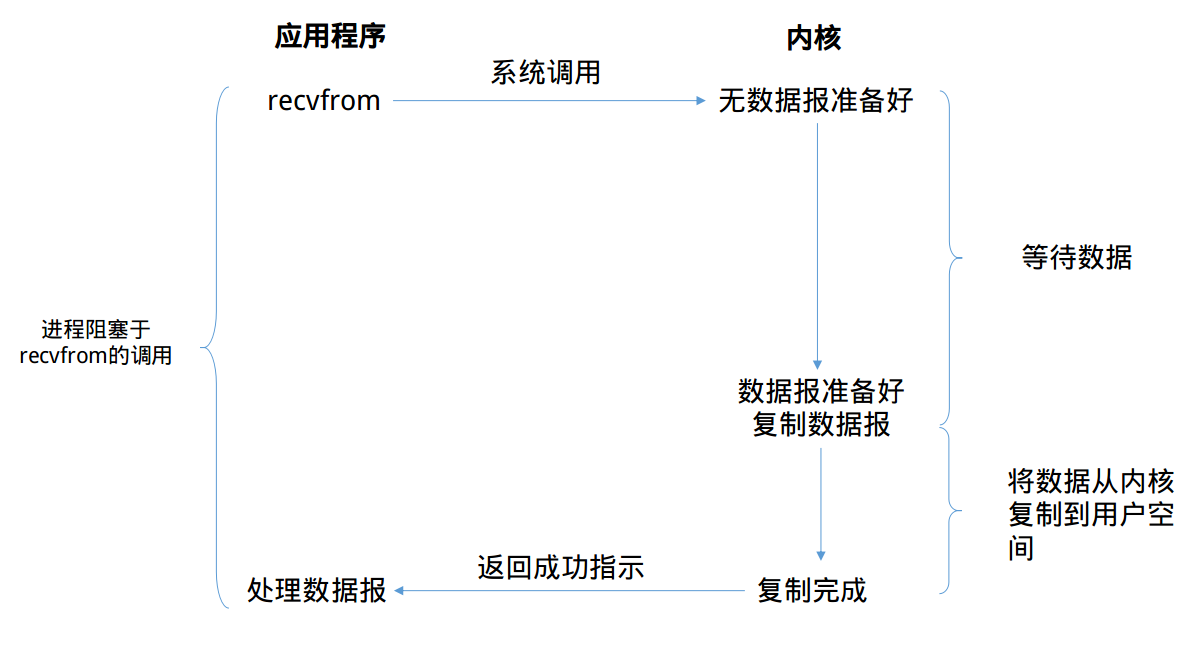
上图中,我们说从调用recvfrom开始到它返回的整段时间内是被阻塞的,recvfrom成功返回后,引用程序才开始处理数据报。
阻塞式I/O的优缺点
优点:
阻塞式I/O很容易上手,一般程序按照read-process的顺序进行处理就好。通常来说我们编写的第一个TCP的C/S程序就是阻塞式I/O模型的。并且该模型定位错误,在阻塞时整个进程将被挂起,基本不会占用CPU资源。
缺点:
该模型的缺点也十分明显。作为服务器,需要处理同时多个的套接字,使用该模型对具有多个的客户端并发的场景时就显得力不从心。
当然也有补救方法,我们使用多线程技术来弥补这个缺陷。但是多线程在具有大量连接时,多线程技术带来的资源消耗也不容小看:
如果我们现在有1000个连接时,就需要开启1000个线程来处理这些连接,于是就会出现下面的情况
- 线程有内存开销,假设每个线程需要512K的存放栈,那么1000个连接就需要月512M的内存。当并发量高的时候,这样的内存开销是无法接受的。
- 线程切换有CPU开销,这个CPU开销体现在上下文切换上,如果线程数越多,那么大多数CPU时间都用于上下文切换,这样每个线程的时间槽会非常短,CPU真正处理数据的时间就会少了非常多。
二、非阻塞式I/O
有阻塞I/O,那么也会有非阻塞I/O,在上文说过默认情况下,所有的套接字都是阻塞的,那么通过设置套接字的NONBLOCK(一般在open(),socket()等调用中设置)标志或者设置recv、send等输入输出函数的MSG_DONTWAIT标志就可以实现非阻塞操作。
那我们来看看非阻塞I/O模型的运行流程吧
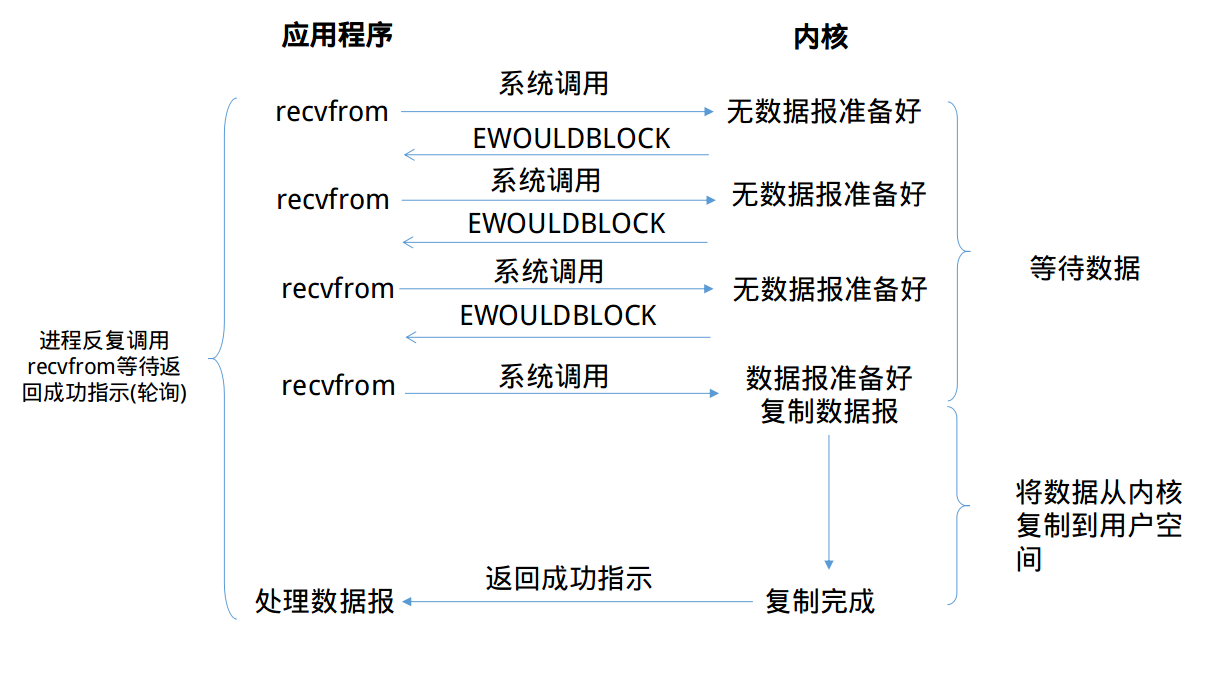
可以看到,前三次recvfrom时没有数据可以返回,此时内核不阻塞进程,转而立即返回一个EWOULDBLOCK错误。第四次调用recvfrom时已经有一个数据报准备好了,此时它将被复制到应用进程的缓冲区,于是recvfrom调用成功返回。
当一个应用进程像这样对一个非阻塞描述符循环调用recvfrom时,我们称之为轮询(polling)
非阻塞式I/O的优缺点
优点:
这种I/O方式也有明显的优势,即不会阻塞在内核的等待数据过程,每次发起的I/O请求可以立即返回,不用阻塞等待。在数据量收发不均,等待时间随机性极强的情况下比较常用。
缺点
轮询这一个特征就已近暴露了这个I/O模型的缺点。轮询将会不断地询问内核,这将占用大量的CPU时间,系统资源利用率较低。同时,该模型也不便于使用,需要编写复杂的代码。
三、I/O复用模型
上文中说到,在出现大量的链接时,使用多线程+阻塞I/O的编程模型会占用大量的内存。那么I/O复用技术在内存占用方面,就有着很好的控制。
当前的高性能反向代理服务器Nginx使用的就是I/O复用模型(epoll),它以高性能和低资源消耗著称,在大规模并发上也有着很好的表现。
那么,我们就来看一看I/O复用模型的面目吧
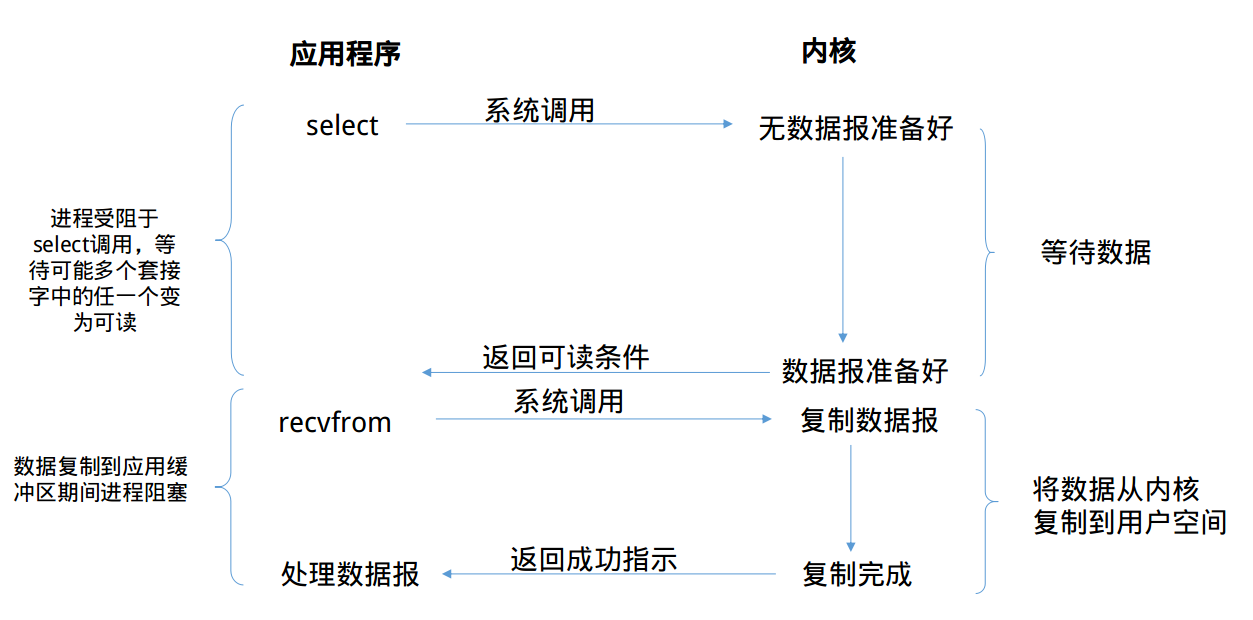
那到底什么是I/O复用(I/O multiplexing)。根据我的理解,复用指的是复用线程,从阻塞式I/O来看,基本一个套接字就霸占了整个线程。例如当对一个套接字调用recvfrom调用时,整个线程将被阻塞挂起,直到数据报准备完毕。
多路复用就是复用一个线程的I/O模型,Linux中拥有几个调用来实现I/O复用的系统调用——select,poll,epoll(Linux 2.6+)
线程将阻塞在上面的三个系统调用中的某一个之上,而不是阻塞在真正的I/O系统调用上。I/O复用允许对多个套接字进行监听,当有某个套接字准备就绪(可读/可写/异常)时,系统调用将会返回。
然后我们可能将重新启用一个线程并调用recvfrom来将特定套接字中的数据报从内核缓冲区复制到进程缓冲区。
I/O复用模型的优缺点
优点
I/O复用技术的优势在于,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,所以它也是很大程度上减少了资源占用。
另外I/O复用技术还可以同时监听不同协议的套接字
缺点
在只处理连接数较小的场合,使用select的服务器不一定比多线程+阻塞I/O模型效率高,可能延迟更大,因为单个连接处理需要2次系统调用,占用时间会有增加。
四、信号驱动式I/O模型
当然你可能会想到使用信号这一机制来避免I/O时线程陷入阻塞状态。那么内核开发者怎么可能会想不到。那么我们来看看信号驱动式I/O模型的具体流程

从上图可以看到,我们首先开启套接字的信号驱动式I/O功能,并通过sigaction系统调用来安装一个信号处理函数,我们进程不会被阻塞。
当数据报准备好读取时,内核就为该进程产生一个SIGIO信号,此时我们可以在信号处理函数中调用recvfrom读取数据报,并通知数据已经准备好,正在等待处理。
信号驱动式I/O模型的优缺点
优点
很明显,我们的线程并没有在等待数据时被阻塞,可以提高资源的利用率
缺点
其实在Unix中,信号是一个被过度设计的机制(这句话来自知乎大神,有待考究)
信号I/O在大量IO操作时可能会因为信号队列溢出导致没法通知——这个是一个非常严重的问题。
稍微歇息一下,还记得我们前面说过这4种I/O模型都可以划分为同步I/O方式,那我们来看看为什么。
了解了4种I/O模型的调用过程后,我们可以注意到,在数据从内核缓冲区复制到用户缓冲区时,都需要进程显示调用recvfrom,并且这个复制过程是阻塞的。
也就是说真正I/O过程(这里的I/O有点狭义,指的是内核缓冲区到用户缓冲区)是同步阻塞的,不同的是各个I/O模型在数据报准备好之前的动作不一样。
下面所说的异步I/O模型将会有所不同
五、异步I/O模型
异步I/O,是由POSIX规范定义的。这个规范定义了一些函数,这些函数的工作机制是:告知内核启动某个操作,并让内核在整个操作完成后再通知我们。(包括将数据从内核复制到我们进程的缓冲区)
照样,先看模型的流程
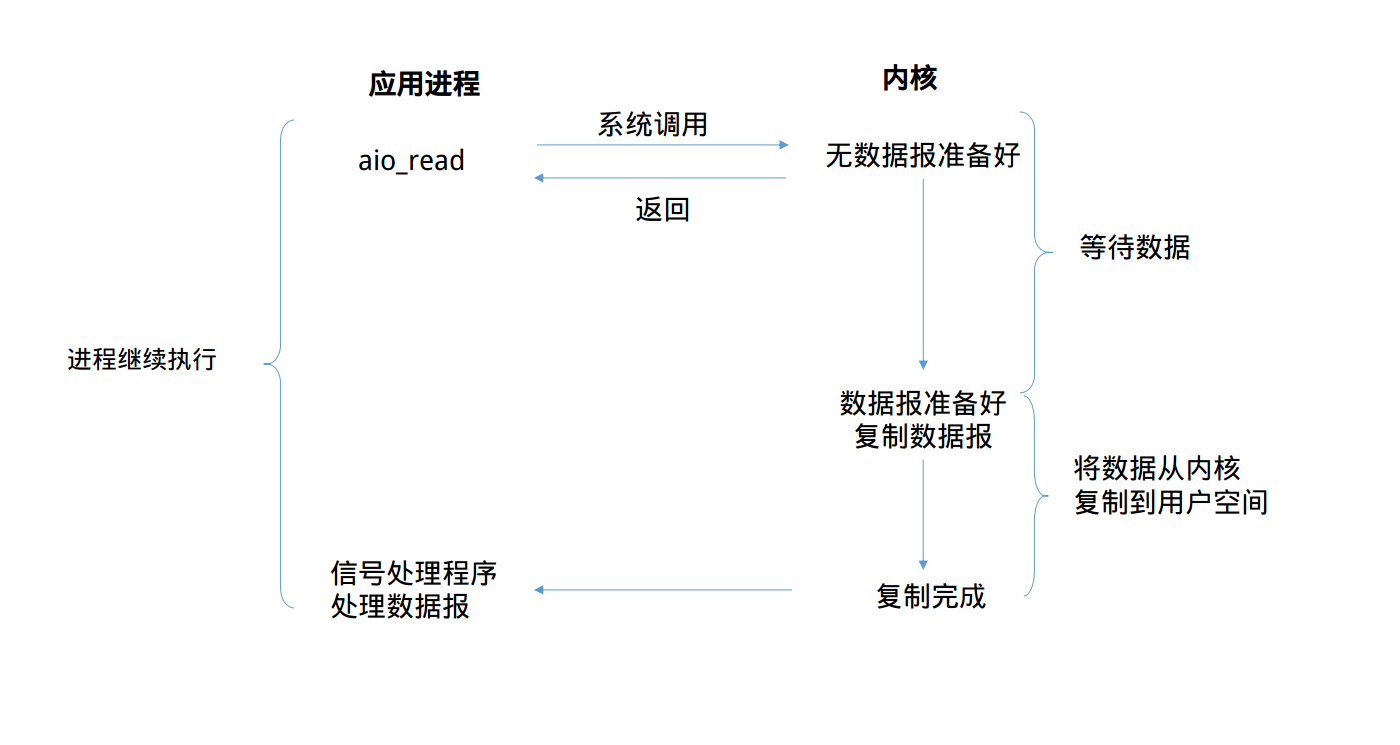
全程没有阻塞,真正做到了异步
异步的优点还用说明吗?
but

异步I/O在Linux2.6才引入,而且到现在仍然未成熟。
虽然有知名的异步I/O库 glibc,但是听说glibc采用多线程模拟,但存在一些bug和设计上的不合理。wtf?多线程模拟,那还有杀卵用。
引入异步I/O可能会代码难以理解的问题,这个站在软件工程的角度也是需要细细衡量的。
总结
关于对Linux 的I/O模型的学习就写到这里,每个模型都有自己使用的范围
Talk is cheap, show me the code
实践出真知。
关于I/O模型的实验代码会在2017年10月前放到我的github仓库中。
参考文献
- 《Unix网络编程卷1:套接字联网API》(第3版)人民邮电出版社
Linux下的I/O模型以及各自的优缺点的更多相关文章
- Linux下5种IO模型的小结
概述 接触网络编程,我们时常会与各种与IO相关的概念打交道:同步(Synchronous).异步(ASynchronous).阻塞(blocking)和非阻塞(non-blocking).关于概念的区 ...
- netty学习(一)--linux下的网络io模型简单介绍
linux的内核将全部的外部设备都看作一个文件来操作,对一个文件的读写操作会调用内核提供的系统命令 ,返回一个file descriptor(fd.文件描写叙述符).而对一个socket的读写也会有对 ...
- 从操作系统层面理解Linux下的网络IO模型
I/O( INPUT OUTPUT),包括文件I/O.网络I/O. 计算机世界里的速度鄙视: 内存读数据:纳秒级别. 千兆网卡读数据:微妙级别.1微秒=1000纳秒,网卡比内存慢了千倍. 磁盘读数据: ...
- Linux下常见的IO模型
前言 阻塞IO(blocking IO) 非阻塞IO(nonblocking IO) IO复用(IO multiplexing) 异步IO(asynchronous IO (the POSIX aio ...
- Linux下常用I/O模型
Linux异步I/O是Linux内核中提供的一个相当新的增强.它是2.6版本内核的一个标准特性,异步非阻塞I/O背后的基本思想是允许进程发起很多I/O操作,而不用阻塞或等待任何操作完成.稍后或在接收到 ...
- DPM检测模型 VoC-release 5 linux 下编译运行
(转载请注明作者和出处 楼燚(yì)航的blog :http://www.cnblogs.com/louyihang-loves-baiyan/ 未经允许请勿用于商业用途) DPM目前使非神经网络方法 ...
- linux下多路复用模型之Select模型
Linux关于并发网络分为Apache模型(Process per Connection (进程连接) ) 和TPC , 还有select模型,以及poll模型(一般是Epoll模型) Select模 ...
- Linux 下的五种 IO 模型
概念说明 用户空间与内核空间 现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方).操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的 ...
- Linux下套接字具体解释(三)----几种套接字I/O模型
參考: 网络编程–IO模型演示样例 几种server端IO模型的简介及实现 背景知识 堵塞和非堵塞 对于一个套接字的 I/O通信,它会涉及到两个系统对象.一个是调用这个IO的进程或者线程,还有一个就是 ...
随机推荐
- Sangmado 公共基础类库
Sangmado 涵盖了支撑 .NET/C# 项目开发的最基础的公共类库,为团队在不断的系统开发和演进过程中发现和积累的最公共的代码可复用单元. Sangmado 公共类库设计原则: 独立性:不与任何 ...
- Jenkins+ANT+Jmeter 接口测试的实践(转载)
转载地址:https://testerhome.com/topics/5262 1.前言 最近感觉大家都在讲Jenkins+jmeter+ant或maven的使用,但没有说到具体怎么投入到项目使用,只 ...
- 蓝桥杯算法训练_2的次幂表示+前缀表达式+Anagrams问题+出现次数最多的整数
今天做了4个简单的题,题目虽然是简单,但是对于我这样的小白,还是有很多东西需要学习的. 2的次幂表示 上面就是题目,题目说的也很清晰了,接下来就是递归的实现: #include<iostream ...
- ArrayList 和 LinkedList的执行效率比较
一.概念: 一般我们都知道ArrayList* 由一个数组后推得到的 List.作为一个常规用途的对象容器使用,用于替换原先的 Vector.允许我们快速访问元素,但在从列表中部插入和删除元素时,速度 ...
- Redis-入门笔记-15min带你一览redis
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! 少年入门笔记,整理出来一起入坑!入门的视屏 ...
- MySQL binlog相关分析
1.redolog.binlog的简单分析 图解:redolog和binlog机制 2.开启binlog及关注点 3.关注binlog的相关参数 4.binlog模式分析 5.关于binlog的使用 ...
- javascript-数组的常用方法
不知大家是否有过跟我类似的经历,就是切图仔刚开始做切图页面的时候,经常调用一些别人写的jquery插件,例如音乐播放器这种需要切换多首音乐的插件.调用的时候就必须有一个音乐队列,而这个队列就是一个数组 ...
- Spring Boot 出现 in a frame because it set 'X-Frame-Options' to 'DENY'
在spring boot项目中出现不能加载iframe 页面报一个"Refused to display 'http://......' in a frame because it set ...
- MVC项目中使用百度地图
已经很久没更新博客了,因为最近一直在学习前端的知识,没那么多时间,写博客或者写文章不但没有钱,写得好还好说,如果写得不好,一些吃瓜群众,不仅要喷你,搞不好还要人身攻击就不好了.所以写博客的人,脸皮得厚 ...
- c#获取数组中指定元素的索引
//获取元素的索引 ArrayList arrList = new ArrayList(); ; i < array.Length; i++) { ) { arrList.Add(i); } } ...