由String的构造方法引申出来的java字符编码
在String类的constructors中,有一个constructor是将int数组类型转化为字符串:
int[] num = {48,49,50,51,52};
String numStr = new String(num,0,4);
System.out.println(numStr);
输出结果是:
0123
这个constructor的作用是将int数组中每一位上的数字转化为在Unicode编码中对应的字符。现在来看看它是怎么转化的。
源代码:
public String(int[] codePoints, int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
// Note: offset or count might be near -1>>>1.
if (offset > codePoints.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
final int end = offset + count;
// Pass 1: Compute precise size of char[]
int n = count;
for (int i = offset; i < end; i++) {
int c = codePoints[i];
if (Character.isBmpCodePoint(c))
continue;
else if (Character.isValidCodePoint(c))
n++;
else throw new IllegalArgumentException(Integer.toString(c));
}
// Pass 2: Allocate and fill in char[]
final char[] v = new char[n];
for (int i = offset, j = 0; i < end; i++, j++) {
int c = codePoints[i];
if (Character.isBmpCodePoint(c))
v[j] = (char) c;
else
Character.toSurrogates(c, v, j++);
}
this.value = v;
this.count = n;
this.offset = 0;
}
代码很简单,但是用到了Character类的三个方法:
Character.isBmpCodePoint(c)
Character.isValidCodePoint(c)
Character.toSurrogates(c, v, j++)
先来看看第一个方法isBmpCodePoint():
public static boolean isBmpCodePoint(int codePoint) {
return codePoint >>> 16 == 0;
// Optimized form of:
// codePoint >= MIN_VALUE && codePoint <= MAX_VALUE
// We consistently use logical shift (>>>) to facilitate
// additional runtime optimizations.
}
>>>是移位运算符,codePoint >>> 16 的意思是将codePoint变量无符号右移16位,然后判断是否等于0,这个是在判断什么呢?根据字面意思理解is bmp code point,是否是bmp代码点,也是不明白,然后就去search了一下,于是就引申出了两个概念----代码点与代码单元。
说到代码点与代码单元,就得先说说Unicode编码的基本概念了。
1、Unicode的基本概念
1)编码字符集
编码字符集是一个字符集,它为每一个字符分配一个唯一数字。Unicode 标准的核心是一个编码字符集,字母“A”的编码为0041和字符“€”的编码为20AC。Unicode标准始终使用十六进制数字,而且在书写时在前面加上前缀“U+”,所以“A”的编码书写为“U+0041”。说白了,就是在编码字符集中,每一个字符都有一个自己的一个唯一的ID。
2)代码点与代码单元
| Unicode 代码点 | U+0041 | U+00DF | U+6771 | U+10400 | ||||||||||
| 表示字形 | ||||||||||||||
| UTF-32 代码单元 |
|
|
|
|
||||||||||
| UTF-16 代码单元 |
|
|
|
|
||||||||||
| UTF-8 代码单元 |
|
|
|
|
网摘:“代码点(Code Point)就是指Unicode中为字符分配的编号,一个字符只占一个代码点,例如我们说到字符“汉”,它的代码点是U+6C49.代码单元(Code Unit)则是针对编码方法而言,它指的是编码方法中对一个字符编码以后所占的最小存储单元。例如UTF-8中,代码单元是一个字节,因为一个字符可以被编码为1个,2个或者3个4个字节;在UTF-16中,代码单元变成了两个字节(就是一个char),因为一个字符可以被编码为1个或2个char(你找不到比一个char还小的UTF-16编码的字符,嘿嘿)。说得再罗嗦一点,一个字符,仅仅对应一个代码点,但却可能有多个代码单元(即可能被编码为2个char)。”
说白了,代码点:就是字符所对应的那个“ID”。代码单元:指的是在各种不同的编码方式中(UTF-8,UTF-16),对一个字符编码以后所占的最小存储单元。
3)增补字符
16 位编码的所有 65536 个字符并不能完全表示全世界所有正在使用或曾经使用的字符。于是,Unicode 标准已扩展到包含多达 1112064 个字符。那些超出原来的16 位限制的字符被称作增补字符。
Java的char类型是固定16bits(两个字节)的。代码点在U+0000 — U+FFFF之内到是可以用一个char完整的表示出一个字符。但代码点在U+FFFF之外的,一个char无论如何无法表示一个完整字符。这样用char类型来获取字符串中的那些代码点在U+FFFF之外的字符就会出现问题。
于是,有了增补字符。增补字符是代码点在 U+10000 至 U+10FFFF 范围之间的字符,也就是那些使用原始的 Unicode 的 16 位设计无法表示的字符。从 U+0000 至 U+FFFF 之间的字符集有时候被称为基本多语言面 (BMP UBasic Multilingual Plane )。Unicode的代码点可以分成17个代码级别。第一个代码级别称为基本的多语言级别,代码点从U+0000到U+FFFF,其中包括了经典的Unicode代码,其余的16个附加级别,代码点从U+10000到U+10FFFF,其中包括了一些增补字符。因此,每一个 Unicode 字符要么属于 BMP,要么属于增补字符。
2、基于Unicode的具体编码格式
网摘:
UTF-32 即将每一个 Unicode 代码点表示为相同值的32位整数。很明显,它是内部处理最方便的表达方式,但是,如果作为一般字符串表达方式,则要消耗更多的内存。
UTF-16 使用一个或两个未分配的16位代码单元的序列对 Unicode 代码点进行编码。假设U是一个代码点,也就是Unicode编码表中一个字符所对应的Unicode值:
(1) 如果在BMP级别中,那么16bits(一个代码单元)就足够表示出字符的Unicode值。
(2)如果U+10FFFF>U>=U+10000,也就是处于增补字符级别中。UTF-16用2个16位来表示出了,并且正好将每个16位都控制在替代区域U+D800-U+DFFF(其中\uD800-\uDBFF为高代理项 范围,\uDC00- \uDFFF为低代理项 范围) 中。
也就是说,在UTF-16中,增补字符的表示方式是由两个代码单元来表示的,原因就是一个代码单元放不下它。那么在java中是如何处理这些增补字符的呢?
java的处理方式是这样的:对于增补字符U(U+10FFFF>U>=U+10000)。首先,分别初始化2个16位无符号的整数 —— W1和W2。其中W1=110110xxxxxxxxxx(0xD800-0xDBFF),W2 = 110111xxxxxxxxxx(0xDC00-OxDFFF)。然后,将Unicode的高10位分配给W1的低10位,将Unicode 的低10位分配给W2的低10位。这样就可以将20bits的代码点U拆成两个16bits的代码单元。而且这两个代码点正好落在替代区域U+D800-U+DFFF中。
UTF-16表示的增补字符怎样才能被正确的识别为增补字符,而不是两个普通的字符呢?答案是通过看它的第一个char是不是在高代理范围内,第二个char是不是在低代理范围内来决定,这也意味着,高代理和低代理所占的共2048个码位(从0xD800到0xDFFF)是不能分配给其他字符的。
Unicode的编号中,U+D800到U+DFFF是否有字符分配?答案是也没有!这么做的目的是希望基本多语言面中的字符和一个char型的UTF-16编码的字符能够一一对应。(这里就不写代码验证了)
java具体的是怎么来拆分增补字符的呢?看一个例子:通过两个代码点U+11001,U+1D56B(使用4个字节表示的代码点)以U+1D56B来说
0x1D56B= 0001 1101 01-01 0110 1011
将0x1D56B的高10位0001 1101 01分配给W1的低10位组合成110110 0001 1101 01=0xD875
将0x1D56B的低10位01 0110 1011分配给W2的低10位组合成110111 01 0110 1011=0xDD6B
这样代码点U+1D56B采用UTF-16编码方式,用2个连续的代码单元U+D875和U+DD6B表示出了
int[] codePoints = {0x11001,0x1d56b}; //增补字符
String s = new String(codePoints,0,2);
System.out.println("s: " + s);
System.out.println("s.length: " + s.length()); //4,说明length()是按代码单元计算的
System.out.println("s.charAt(0): " + Integer.toHexString((int)s.charAt(0)));//输出结果表明增补字符并非简单地把两个代码单元拆开
System.out.println("s.charAt(1): " + Integer.toHexString((int)s.charAt(1)));
System.out.println("s.charAt(2): " + Integer.toHexString((int)s.charAt(2)));
System.out.println("s.charAt(3): " + Integer.toHexString((int)s.charAt(3)));
System.out.println("s.codePointAt(0):" + Integer.toHexString(s.codePointAt(0)));
输出结果是:
s: ??
s.length: 4
s.charAt(0): d804
s.charAt(1): dc01
s.charAt(2): d835
s.charAt(3): dd6b
s.codePointAt(0):11001
可以看到
字符串的长度为4,说明length()是按代码单元计算的,然后我们看看U+1D56B的拆分结果:
s.charAt(2): d835
s.charAt(3): dd6b
与我们计算的 U+D875 U+DD6B 有出入,该代理代码点不一样,带着这个疑问,我们去看看java代码是如何转化的:
[java.lang.String]
for (int i = offset, j = 0; i < end; i++, j++) {
int c = codePoints[i];
if (Character.isBmpCodePoint(c)) //判断是不是BMP级别
v[j] = (char) c;
else
Character.toSurrogates(c, v, j++);//给出高低代理项
}
[java.lang.Character]
static void toSurrogates(int codePoint, char[] dst, int index) {
// We write elements "backwards" to guarantee all-or-nothing
dst[index+1] = lowSurrogate(codePoint);//给出低代理项
dst[index] = highSurrogate(codePoint);//给出高代理项
}
[java.lang.Character]
public static final char MIN_LOW_SURROGATE = '\uDC00';//低代理项最小值
public static char lowSurrogate(int codePoint) {
return (char) ((codePoint & 0x3ff) + MIN_LOW_SURROGATE);
}
[java.lang.Character]
public static final char MIN_HIGH_SURROGATE = '\uD800';//高代理项最小值
public static final int MIN_SUPPLEMENTARY_CODE_POINT = 0x010000;//增补字符最小代码点
public static char highSurrogate(int codePoint) {
return (char) ((codePoint >>> 10)
+ (MIN_HIGH_SURROGATE - (MIN_SUPPLEMENTARY_CODE_POINT >>> 10)));
}
可以看出低代理项与计算方式一样,所以计算出的结果一致,但是高代理项在移位10bit,加上最小高代理项后,又减去了增值字符最小代码点的移位10bit后的值,其实这就相当于,对于增补字符U+1D56B,其操作是对 U+0D56B进行的操作。这里还没有确定为什么会减去这个位,有待考证!
UTF-8:
网摘:
使用一至四个字节的序列对编码 Unicode 代码点进行编码。U+0000 至 U+007F 使用一个字节编码,U+0080 至 U+07FF 使用两个字节,U+0800 至 U+FFFF 使用三个字节,而 U+10000 至 U+10FFFF 使用四个字节。UTF-8 设计原理为:字节值 0x00 至 0x7F 始终表示代码点 U+0000 至 U+007F(Basic Latin 字符子集,它对应 ASCII 字符集)。这些字节值永远不会表示其他代码点,这一特性使 UTF-8 可以很方便地在软件中将特殊的含义赋予某些 ASCII 字符。
以下是Unicode和UTF-8之间的转换关系表:
| U-00000000 - U-0000007F: | 0xxxxxxx | |||||
| U-00000080 - U-000007FF: | 110xxxxx | 10xxxxxx | ||||
| U-00000800 - U-0000FFFF: | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| U-00010000 - U-001FFFFF: | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| U-00200000 - U-03FFFFFF: | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| U-04000000 - U-7FFFFFFF: | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
可以看到:
(1)如果一个字节以10开头,一定不是首字节,需要向前查找。
(2)在一个首字节中,如果以0开头,表示是一个ASCII字符,而开头的连续的1的个数也表示了这个字符的字节数。如1110xxxx表示这个字符由三个字节组成。
下面来看一个使用各种编码对字符进行编码的例子,如下:
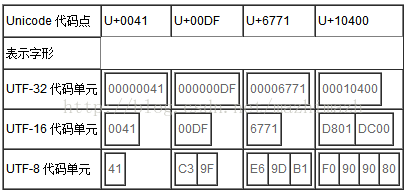
分析到这里,结合源码,可以看出: Java 以 UTF-16 作为内存的字符存储格式。
参考:
http://blog.csdn.net/u010411264/article/details/45258629
http://blog.csdn.net/cumtwyc/article/details/45080679
http://blog.csdn.net/mazhimazh/article/details/17708001
由String的构造方法引申出来的java字符编码的更多相关文章
- Java 字符编码归纳总结
String newStr = new String(oldStr.getBytes(), "UTF-8"); java中的String类是按照unicode进行编码的 ...
- 【字符编码】Java字符编码详细解答及问题探讨
一.前言 继上一篇写完字节编码内容后,现在分析在Java中各字符编码的问题,并且由这个问题,也引出了一个更有意思的问题,笔者也还没有找到这个问题的答案.也希望各位园友指点指点. 二.Java字符编码 ...
- 【JAVA编码专题】 JAVA字符编码系列三:Java应用中的编码问题
这两天抽时间又总结/整理了一下各种编码的实际编码方式,和在Java应用中的使用情况,在这里记录下来以便日后参考. 为了构成一个完整的对文字编码的认识和深入把握,以便处理在Java开发过程中遇到的各种问 ...
- 【JAVA编码】 JAVA字符编码系列二:Unicode,ISO-8859,GBK,UTF-8编码及相互转换
http://blog.csdn.net/qinysong/article/details/1179489 这两天抽时间又总结/整理了一下各种编码的实际编码方式,和在Java应用中的使用情况,在这里记 ...
- Java 字符编码(二)Java 中的编解码
Java 字符编码(二)Java 中的编解码 java.nio.charset 包中提供了一套处理字符编码的工具类,主要有 Charset.CharsetDecoder.CharsetEncoder. ...
- Java 字符编码(三)Reader 中的编解码
Java 字符编码(三)Reader 中的编解码 我们知道 BufferedReader 可以将字节流转化为字符流,那它是如何编解码的呢? try (BufferedReader reader = n ...
- java字符编码详解
引用自:http://blog.csdn.net/jerry_bj/article/details/5714745 GBK.GB2312.iso-8859-1之间的区别 GB2312,由中华人民共和国 ...
- JAVA字符编码三:Java应用中的编码问题
第三篇:JAVA字符编码系列三:Java应用中的编码问题 这部分采用重用机制,引用一篇文章来完整本部分目标. 来源: Eceel东西在线 问题研究--字符集编码 地址:http://china.e ...
- JAVA字符编码二:Unicode,ISO-8859,GBK,UTF-8编码及相互转换
第二篇:JAVA字符编码系列二:Unicode,ISO-8859-1,GBK,UTF-8编码及相互转换 1.函数介绍 在Java中,字符串用统一的Unicode编码,每个字符占用两个字节,与编码有 ...
随机推荐
- Java单元测试之覆盖率统计eclemma
安装 有两种安装方法 下载安装(推荐) 地址: http://sourceforge.net/projects/eclemma/ 将解压后的features和plugins目录下的文件分别拷贝到Ecl ...
- KKlist团队目录
KKlist团队目录 一.Daily Scrum Meeting[Alpha] 4.22 day one 4.23 day two 4.24 day three 4.25 day four 4.26 ...
- 201521123037 《Java程序设计》第6周学习总结
1. 本周学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图,对面向对象思想进行一个总结. 1.2 可选:使用常规方法总结其他上课内容. 接口与抽象类 ...
- 201521123066 《Java程序设计》 第二周学习总结
1.本周学习总结,记录本周学习中的重点 关于String类:String类的对象创建之后不能再进行修改:当大量拼接字符串是,使用StringBuilder而 不使用String:检测字符串是否相等时, ...
- 201521123010 《Java程序设计》第14周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多数据库相关内容. 2. 书面作业 1. MySQL数据库基本操作 建立数据库,将自己的姓名.学号作为一条记录插入.(截图,需出现自 ...
- 201521123064 《Java程序设计》第12周学习总结
本次作业参考文件 正则表达式参考资料 1. 本章学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容. ① 标准输入输出流(字节流):标准输入流 System.in,标准输出流 ...
- 201521123056 《Java程序设计》第9周学习总结
1. 本周学习总结 1.1 思维导图如下: 2. 书面作业 本次PTA作业题集异常 1. 常用异常 题目5-1 1.1 截图你的提交结果(出现学号) 1.2 自己以前编写的代码中经常出现什么异常.需要 ...
- PHP连接数据_insert_id介绍
对于自增长的主键列不好取值的情况,php提供了一个变量来取值,insert_id $db = new MySQLi("localhost","root",&qu ...
- 数据库系统概论——Chap. 1 Introduction
数据库系统概论--Introduction 一.数据库的4个基本概念 数据(data):数据是数据库中存储的基本单位.我们把描述事物的符号记录称为数据.数据和关于数据的解释是不可分的,数据的含义称为数 ...
- Project Euler 92:Square digit chains C++
A number chain is created by continuously adding the square of the digits in a number to form a new ...