Hibernate 学习笔记 - 2
五、映射一对多关联关系
1. 单向多对一 即 单向 n-1
1)单向 n-1 关联只需从 n 的一端可以访问 1 的一端
① 域模型: 从 Order 到 Customer 的多对一单向关联需要在Order 类中定义一个 Customer 属性, 而在 Customer 类中无需定义存放 Order 对象的集合属性
② 关系数据模型:ORDERS 表中的 CUSTOMER_ID 参照 CUSTOMER 表的主键 (多的那一端的数据表需要加上 s,否则建表不成功)
2)使用 many-to-one 映射

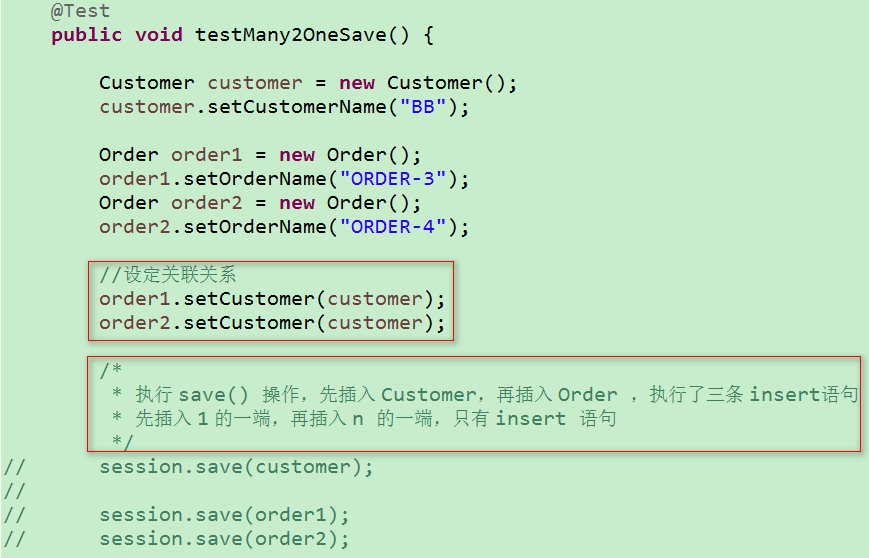
3)测试多对一 映射
① save() 保存

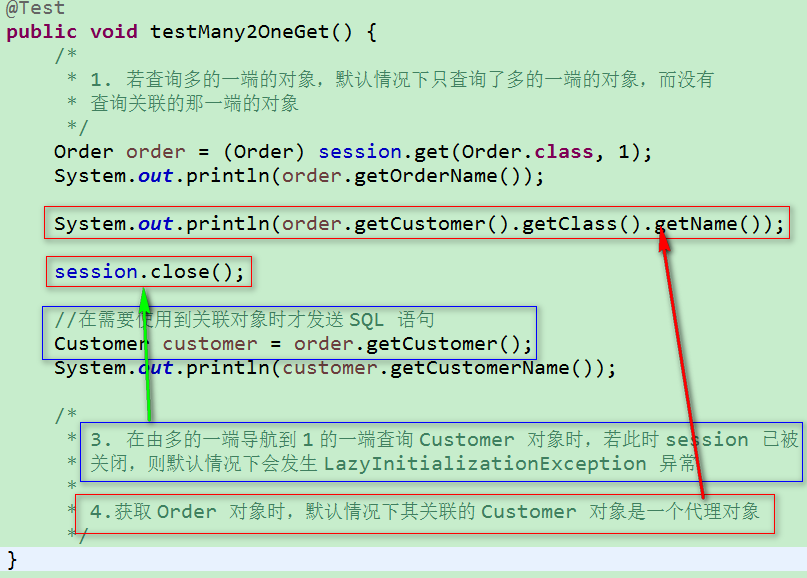
② get() 查询
③ update() 修改 和 删除

2、双向一对多 即 双向1-n
1)双向 1-n 与 双向 n-1 是完全相同的两种情形
2)域模型:从 Order 到 Customer 的多对一双向关联需要在Order 类中定义一个 Customer 属性, 而在 Customer 类中需定义存放 Order 对象的集合属性
3)需要在 1 的一端即 Customer 中添加 n 的一端(Order)的集合关系,并注意

4)测试双向多对一映射
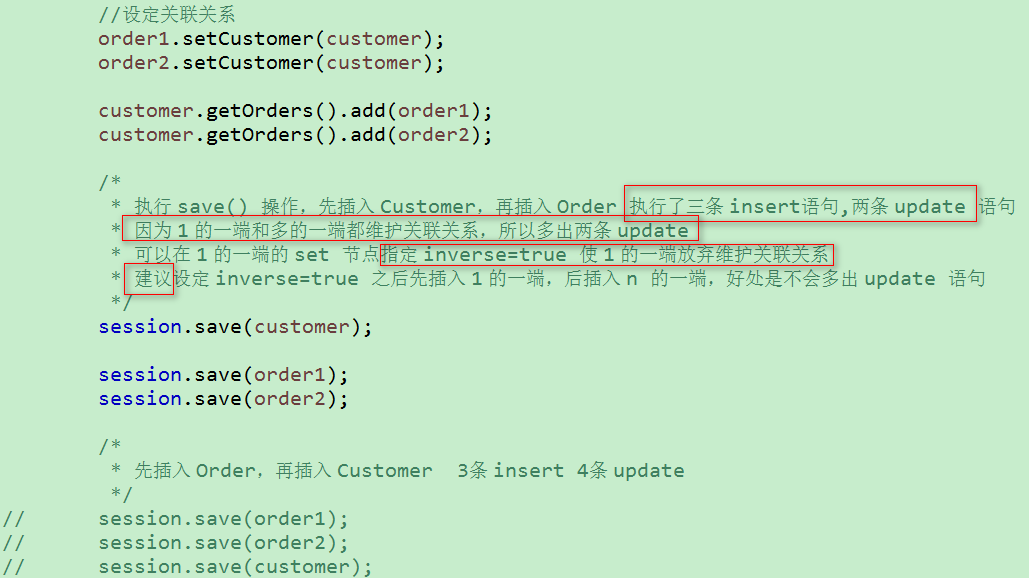
① save() 保存操作
> 映射:n(Order)这一端需要进行常规的多对一映射;在 1(Customer)这 一端使用 set 节点映射:
其中:inverse 属性:
inverse = false 的为主动方,inverse = true 的为被动方, 由主动方负责维护关联关系,在没有设置 inverse=true 的情况下,父子两边都维护父子关系
> 测试:
② get() 获取操作
> 测试

③ update() 操作 常规操作

六、映射一对一关联关系
1. 一对一关联关系
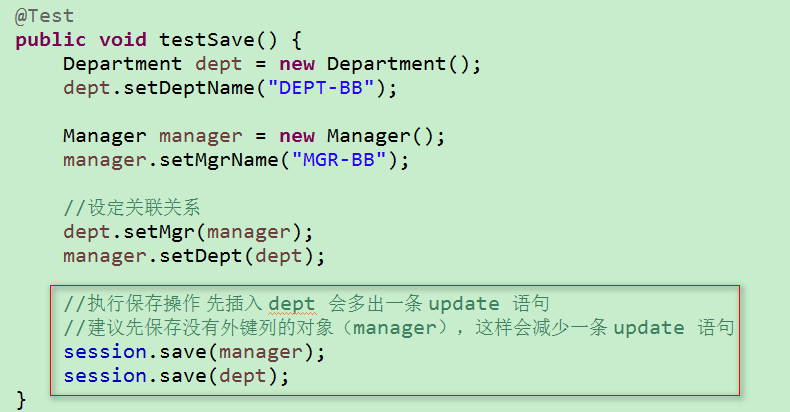
1)理解:一个部门只有一个部门经理,一个部门经理管理一个部门
2)域模型:Department 中有 Manager 的引用,Manager 中也有 Department 的引用
3) ① 基于外键映射的 1 - 1
> 对于基于外键的1-1关联,其外键可以存放在任意一边,在需要存放外键一端,增加many-to-one元素。为many-to-one元素增加 unique=“true” 属性来表示为1-1关联, 如下:

> 另一端需要使用one-to-one元素,该元素使用 property-ref 属性指定使用被关联实体主键以外的字段作为关联字段

> 测试:
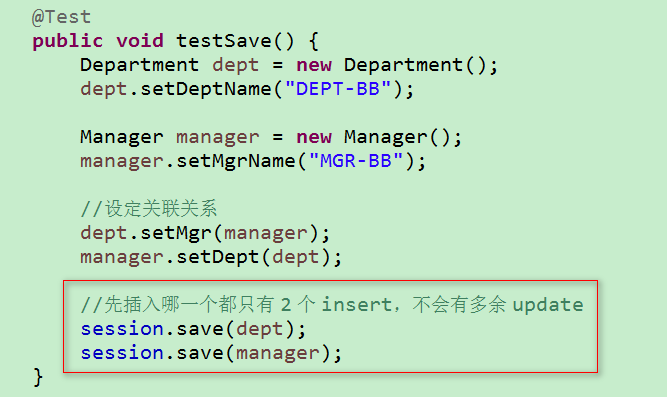
save() 保存:
get() 获取:
② 基于主键映射的 1 -1
> 指一端的主键生成器使用 foreign 策略,表明根据”对方”的主键来生成自己的主键,自己并不能独立生成主键. <param> 子元素指定使用当前持久化类的哪个属性作为 “对方”

> 采用foreign主键生成器策略的一端增加 one-to-one 元素映射关联属性,其one-to-one属性还应增加 constrained=“true” 属性;另一端增加one-to-one元素映射关联属性
注:constrained(约束):指定为当前持久化类对应的数据库表的主键添加一个外键约束,引用被关联的对象(“对方”)所对应的数据库表主键


> 测试:
save() :
get() 获取:

七、映射多对多的关联关系
1.单向多对多:
1) 域模型:Category (类别) 和 Item (商品) 之间的关系模型,只在 Category 类中定义 Set<Item>,即单向 n-n 关联只需一端使用集合属性
2) n-n 的关联必须使用连接表 CATEGORIES_ITEMS
3)与 1-n 映射类似,必须为 set 集合元素添加 key 子元素,指定CATEGORIES_ITEMS 表中参照 CATEGORIES 表的外键为 C_ID. 与 1-n 关联映射不同的是,建立 n-n 关联时, 集合中的元素使用 many-to-many. many-to-many 子元素的 class 属性指定 items 集合中存放的是 Item 对象, column 属性指定 CATEGORIES_ITEMS 表中参照 ITEMS 表的外键为 I_ID

4) 单向多对多的测试,get() 方法会连接中间表查询
2.双向多对多
1) 域模型:Category (类别) 和 Item (商品) 之间的关系模型,在 Category 类中定义 Set<Item>,在 Item 类中定义 Set<Category>,即
双向 n-n 关联需要两端都使用集合属性
2)双向n-n关联必须使用连接表
3)在双向 n-n 关联的两边都需指定连接表的表名及外键列的列名. 两个集合元素 set 的 table 元素的值必须指定,而且必须相同。set元素的两个子元素:key 和 many-to-many 都必须指定 column 属性,其中,key 和 many-to-many 分别指定本持久化类和关联类在连接表中的外键列名,因此两边的 key 与 many-to-many 的column属性交叉相同
> Category.hbm.xml 中的 Set 节点的配置:

> Item.hbm.xml 中的 Set 节点的配置:

注:对于双向 n-n 关联, 必须把其中一端的 inverse 设置为 true, 否则两端都维护关联关系可能会造成主键冲突.即:

八、映射继承关系(了解,开发中使用很少)
1.使用 subclass 进行映射:
1)采用 subclass 的继承映射可以实现对于继承关系中父类和子类使用同一张表
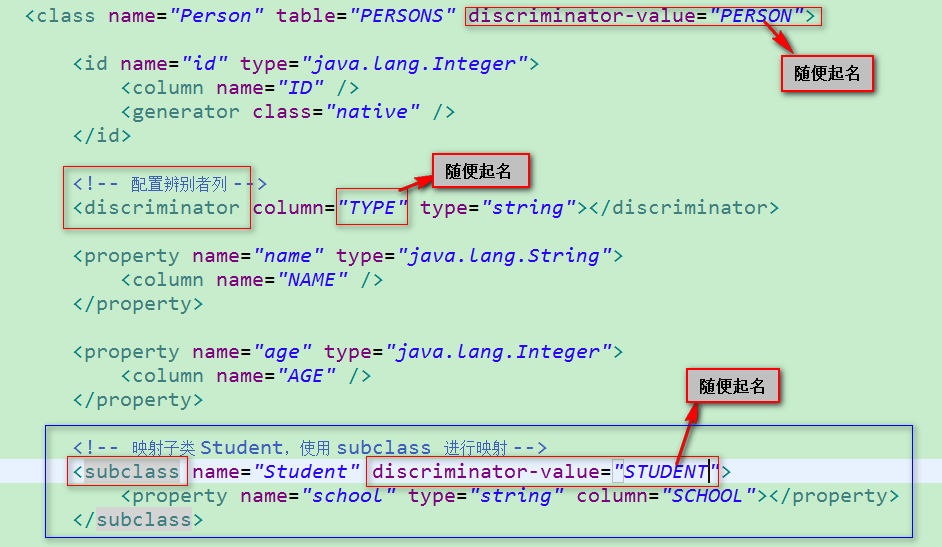
2)因为父类和子类的实例全部保存在同一个表中,因此需要在该表内增加一列,使用该列来区分每行记录到低是哪个类的实例----这个列被称为辨别者列(discriminator).
3)在这种映射策略下,使用 subclass 来映射子类,使用 class 和 subclass 的 discriminator-value 属性指定辨别者列的值
4)所有子类定义的字段都不能有非空约束。如果为那些字段添加非空约束,那么父类的实例在那些列其实并没有值,这将引起数据库完整性冲突,导致父类的实例无法保存到数据库中
5)具体配置:只生成 父类的 .hbm.xml 文件即可,在此配置文件中对子类进行映射
6)测试:
save():

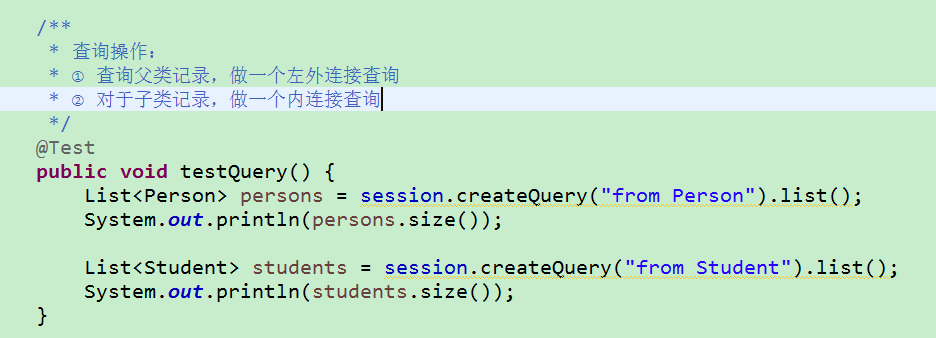
查询操作:

7)使用 subclass 进行映射的缺点:
> 使用了 辨别者列
> 子类独有的字段不能添加非空约束
> 若继承层次较深,则数据表的字段也会较多
2.使用 joined-subclass 进行映射
1)采用 joined-subclass 元素的继承映射可以实现每个子类一张表
2)采用这种映射策略时,父类实例保存在父类表中,子类实例由父类表和子类表共同存储。因为子类实例也是一个特殊的父类实例,因此必然也包含了父类实例的属性。于是将子类和父类共有的属性保存在父类表中,子类增加的属性,则保存在子类表中。
3)在这种映射策略下,无须使用鉴别者列,但需要为每个子类使用 key 元素映射共有主键。
4)子类增加的属性可以添加非空约束。因为子类的属性和父类的属性没有保存在同一个表中
5)具体映射:只生成 父类的 .hbm.xml 文件即可,在此配置文件中对子类进行映射

6)测试
save() 操作:

query() 查询操作:
7)优点:
> 不需要使用辨别者列
>子类独有的字段能添加非空约束
>没有冗余的字段
3.使用 union-subclass 进行映射
1)采用 union-subclass 元素可以实现将每一个实体对象映射到一个独立的表中。
2)子类增加的属性可以有非空约束 --- 即父类实例的数据保存在父表中,而子类实例的数据保存在子类表中。
3)子类实例的数据仅保存在子类表中, 而在父类表中没有任何记录
4)在这种映射策略下,子类表的字段会比父类表的映射字段要多,因为子类表的字段等于父类表的字段、加子类增加属性的总和
5)在这种映射策略下,既不需要使用鉴别者列,也无须使用 key 元素来映射共有主键.
6)使用 union-subclass 映射策略是不可使用 identity 的主键生成策略
7)具体映射:只生成 父类的 .hbm.xml 文件即可,在此配置文件中对子类进行映射,如下:

8)测试:
save() : 插入效率还可以,对于子类对象,只需把记录插入到自己的一张表中
query():查询父类记录,需把父表和子表记录汇总到一起再做查询,性能稍差
9)优点:
> 不需要使用辨别者列
>子类独有的字段能添加非空约束
缺点:
> 存在冗余的字段
>若更新父表的字段,则更新的效率较低
九、Hibernate 的检索策略
1.类级别的检索策略,仅适用于 session 的 load() 方法
1)分为 立即检索(立即加载检索方法指定的对象) 和 延迟检索(延迟加载检索方法指定的对象,在使用具体的非 id 属性时再进行加载)
2)类级别的检索策略可以通过 <class> 元素的 lazy 属性进行设置
3)如果程序加载一个对象的目的是为了访问它的属性, 可以采取立即检索.
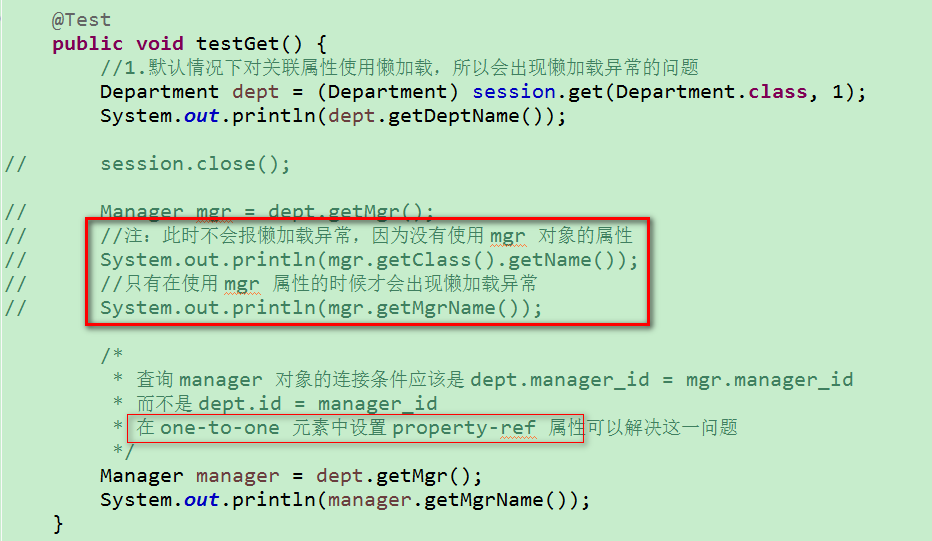
4)如果程序加载一个持久化对象的目的是仅仅为了获得它的引用, 可以采用延迟检索。注意出现懒加载异常!
5)注:①无论 <class> 元素的 lazy 属性是 true 还是 false, Session 的 get() 方法及 Query 的 list() 方法在类级别总是使用立即检索策略
②若 <class> 元素的 lazy 属性为 true 或取默认值(true), Session 的 load() 方法不会执行查询数据表的 SELECT 语句, 仅返回代理类对象的实例, 该代理类实例有如下特征:
–由 Hibernate 在运行时采用 CGLIB 工具动态生成
–Hibernate 创建代理类实例时, 仅初始化其 OID 属性
–在应用程序第一次访问代理类实例的非 OID 属性时, Hibernate 会初始化代理类实例
6)测试:

2.一对多和多对多的检索策略
1)Set 节点的 lazy 属性

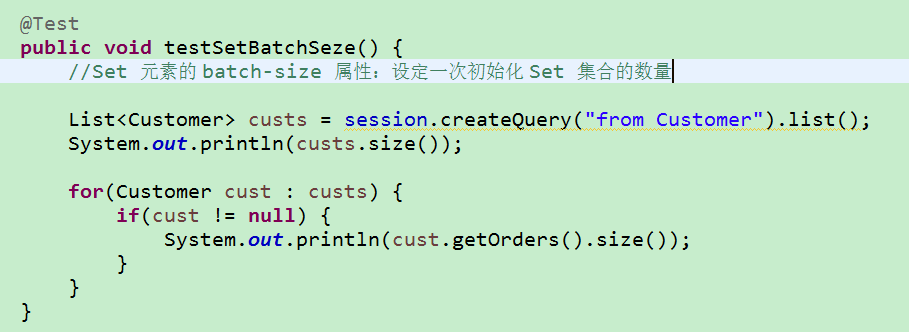
2)Set 节点的 batch-size 属性
3)Set 节点的 fetch 属性

3.多对一 和 一对一 关联检索策略
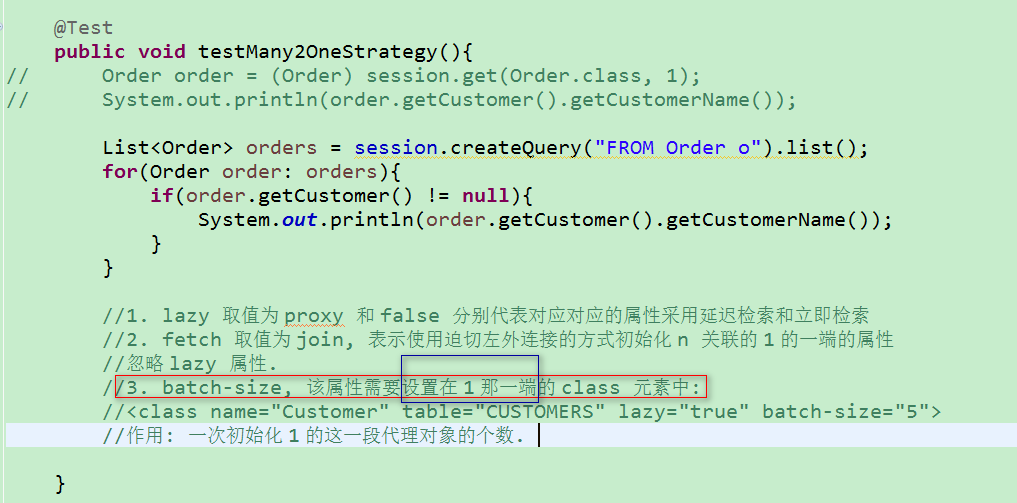
1)many-to-one 节点的 lazy 属性,设置是否延迟检索,默认为 proxy,为延迟检索,可取值: proxy false
2)lazy fetch batch-size 属性的使用如下:
十、Hibernate 的检索方式(使用 Oracle 数据库,在数据库中建立了my_department 和 my_employee 两张数据表,并导入了数据)
重点学习:
1. HQL(Hibernate Query Language) 检索方式:使用面向对象的 HQL 查询语言
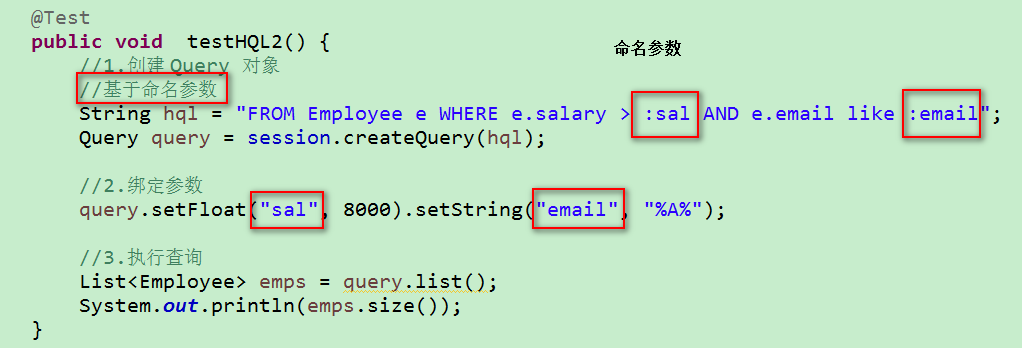
2.HQL查询的 HelloWorld:

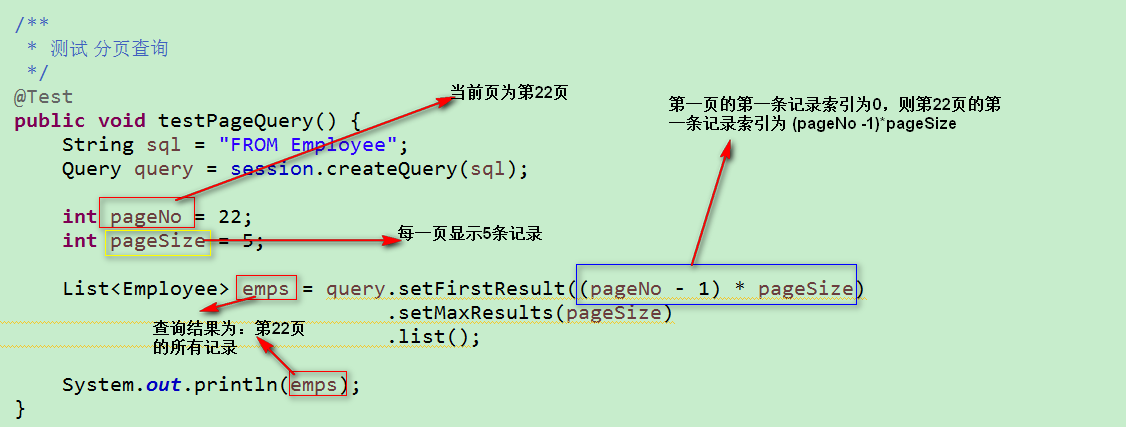
3.HQL 的分页查询
两个方法:
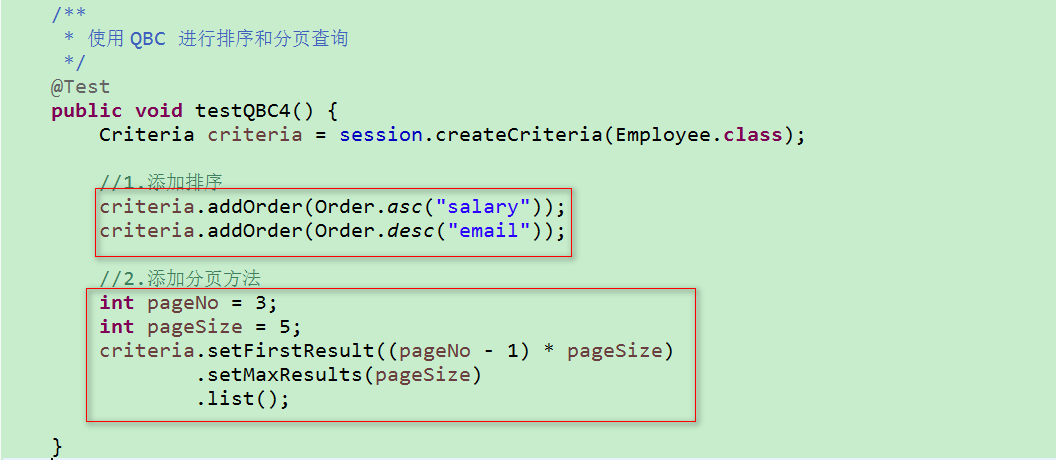
1)setFirstResult(int firstResult) :设置开始检索的位置,参数 firstResult 表示这个对象在查询结果中的索引位置
2)setMaxResults(int maxResults):设置一次检索多少个,即一页显示多少条记录
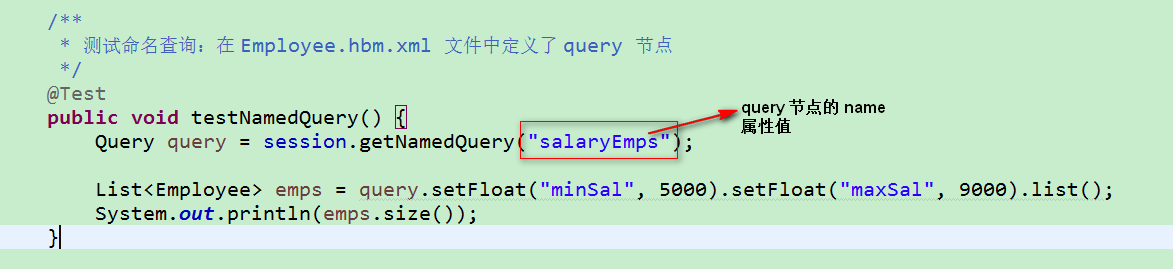
4.HQL 的命名查询:特点是可以把 hql 语句配置在 .hbm.xml 文件中
1)在 Employee.hbm.xml 文件中定义<query> 节点,用于定义一个 HQL 查询语句, 它和 <class> 元素并列

5.HQL 的投影查询:查询结果仅包含实体的部分属性. 通过 SELECT 关键字实现.
1)注:Query 的 list() 方法返回的集合中包含的是数组类型的元素, 每个对象数组代表查询结果的一条记录

2)上面的方式不方便使用,使用下面的方式可以返回一个对象的集合,方便使用

注:在 hql 语句中使用了 Employee 的构造器,所以在 Employee 类中必须定义一个同样的构造器
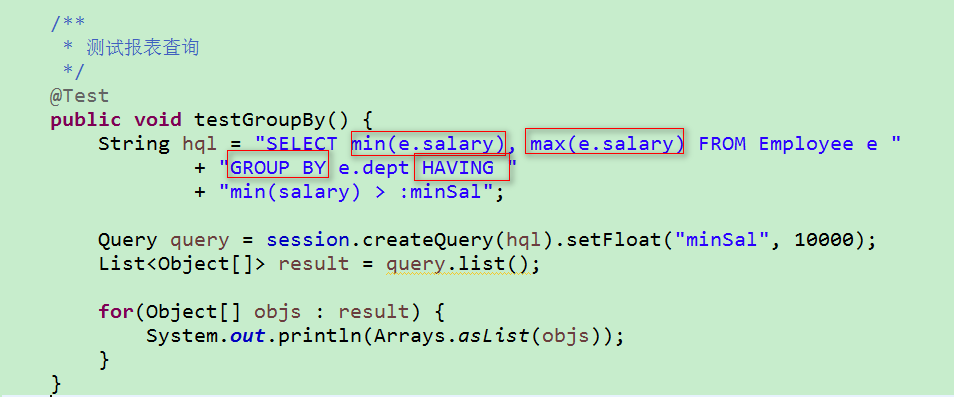
6.HQL 的报表查询:即在 HQL 语句中可以使用 GROUP BY 或 HAVING 或 min() 或 max() 或 sum() 或 count() 等聚集函数
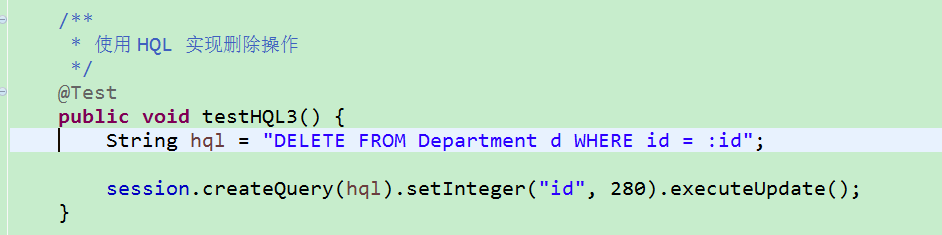
补:使用 HQL 可以实现删除操作:
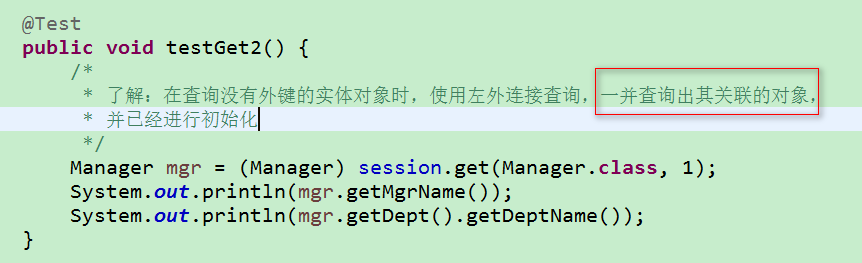
7.HQL 的左外连接 和 迫切左外连接
1)迫切左外连接(尽量使用迫切左外连接)
①LEFT JOIN FETCH 关键字表示迫切左外连接检索策略
②list() 方法返回的集合中存放实体对象的引用, 每个 Department 对象关联的 Employee 集合都被初始化, 存放所有关联的 Employee 的实体对象.
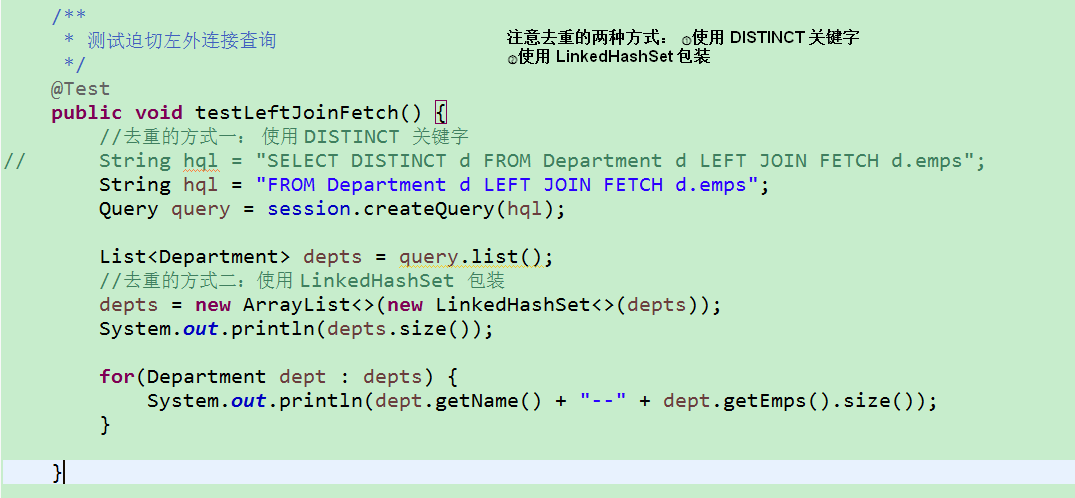
2)左外连接
①LEFT JOIN 关键字表示左外连接查询
②list 方法返回的集合中存放的是对象数组类型,如果希望 list 集合中仅包含 Department 对象,可以在 HQL 查询语句中使用 SELECT 关键字

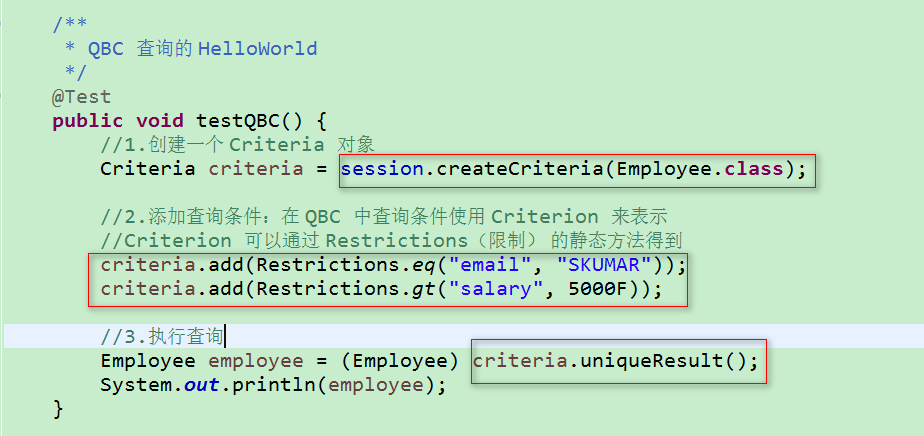
8.QBC(Query By Criteria)查询和本地 SQL查询 Criteria:标准 条件
1)QBC 查询的 HelloWorld:
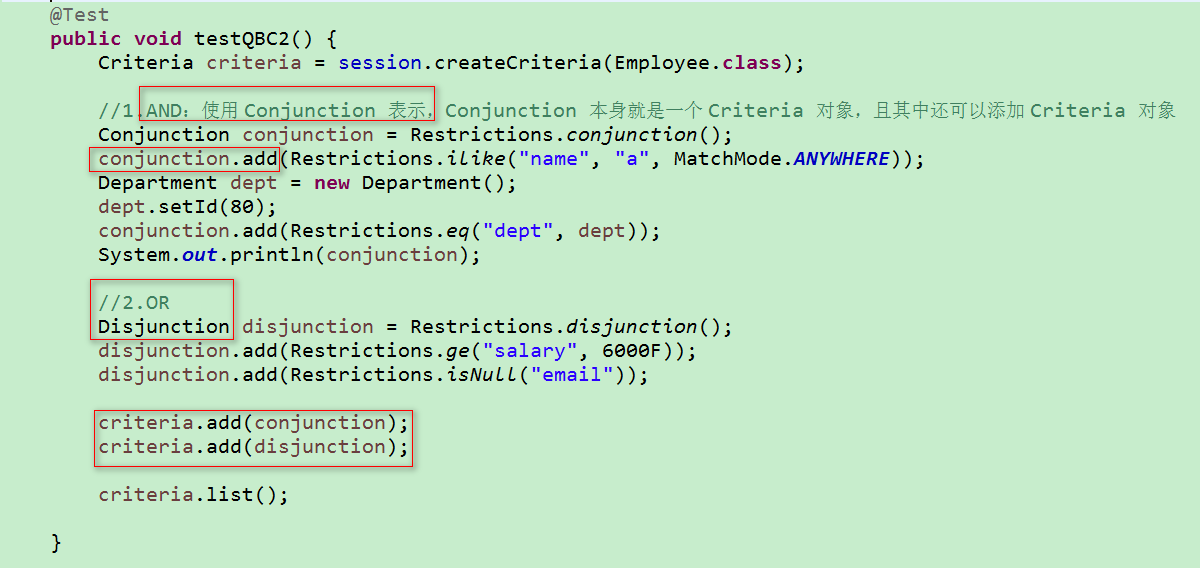
2)带有 AND 和 OR 关键字的 QBC 查询
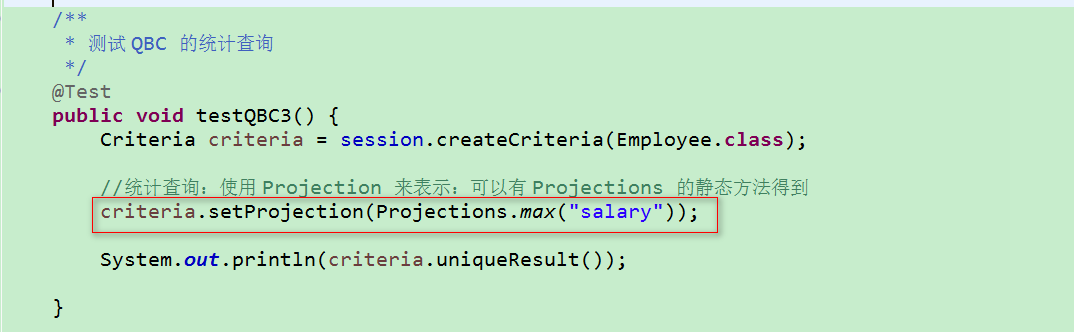
3)QBC 的统计查询
4)使用 QBC 进行排序和分页
注:关于 QBC 查询的更多实例可查看 Hibernate 的示例文档:
hibernate-release-4.3.11.Final\documentation\manual\en-US\html_single\index.html#querycriteria
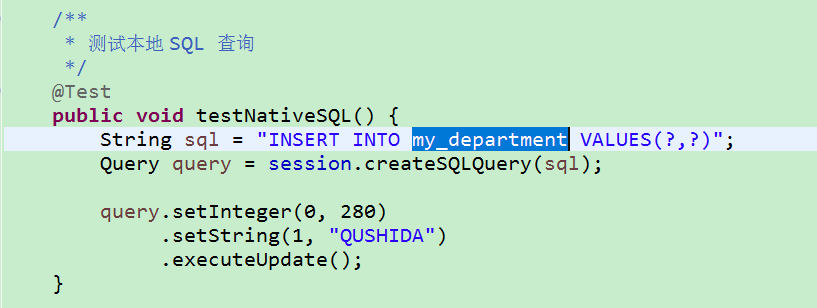
5)本地 SQL 查询
十一、Hibernate 的二级缓存
SessionFactory 级别的缓存
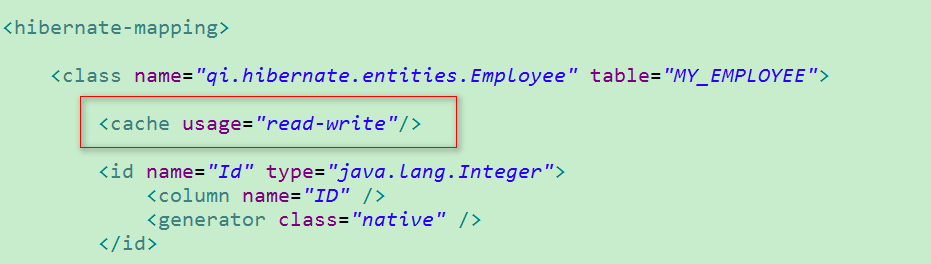
1. 配置 Hibernate类级别的二级缓存:
> 加入 EHCache 的三个 jar 包 hibernate-release-4.2.4.Final\lib\optional\ehcache 目录下
> 加入 EHCache 的配置文件 hibernate-release-4.2.4.Final\project\etc 目录下,放到 src 目录下
> 在 Hibernate.cfg.xml 中 启用二级缓存 配置使用二级缓存的产品 设置对哪一个类使用二级缓存

> 注:还可以在 对应类的 .hbm.xml 文件中使用 cache 节点配置使用缓存的策略,而省略在 Hibernate.cfg.xml 中设置对哪一个类使用二级缓存
2.配置 Hibernate 集合级别的二级缓存:
> 配置对集合使用二级缓存:注:还需要对集合中元素对应的持久化类也使用二级缓存,否则会多出 n 条 SQL 语句

注:也可以在 .hbm.xml 中配置,注意集合的二级缓存在 Set 节点中配置

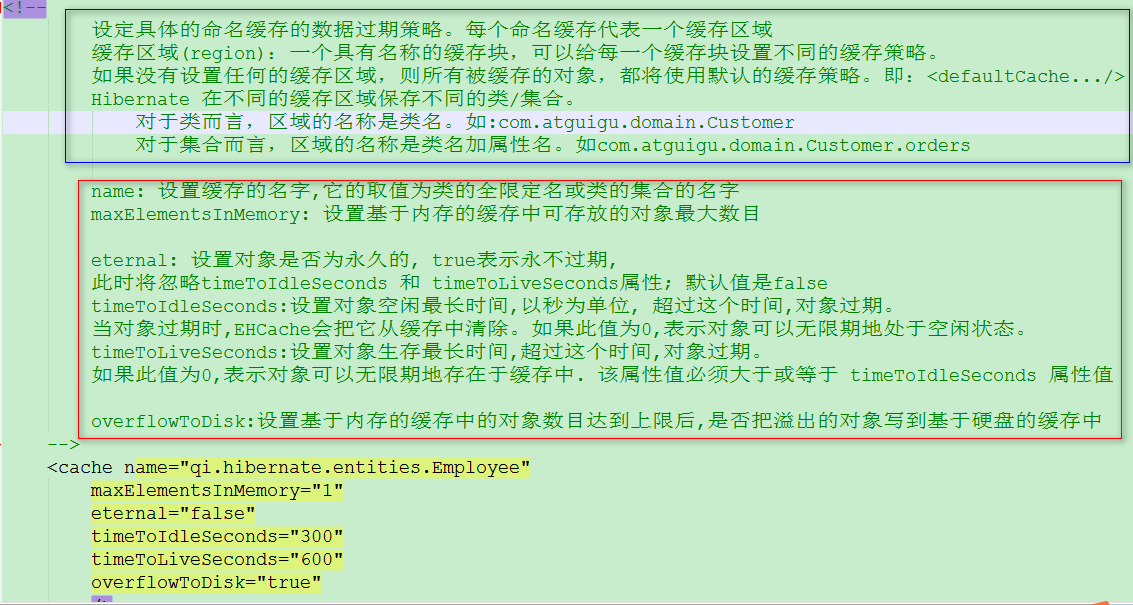
3.详解 ehcache.xml 配置文件:

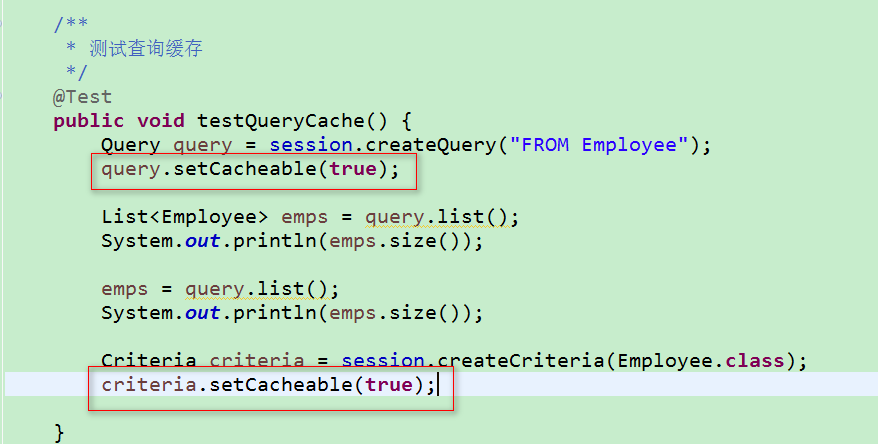
4.查询缓存:默认情况下, 设置的缓存对 HQL 及 QBC 查询时无效的, 但可以通过以下方式使其是有效的
注:查询缓存依赖于二级缓存
> 在 hibernate 配置文件中声明开启查询缓存

> 调用 Query 或 Criteria 的 setCacheable(true) 方法
5.管理 Session ,使 Session 的生命周期和本地线程绑定
步骤(用于测试):
1)在 Hibernate.cfg.xml 文件中配置管理 Session 的方式

2)构建一个 HibernateUtils 类,用于获取与当前线程绑定的 Session
- public class HibernateUtils {
- //单例
- private HibernateUtils() {}
- private static HibernateUtils instance = new HibernateUtils();
- public static HibernateUtils getInstance() {
- return instance;
- }
- private SessionFactory sessionFactory;
- //获取 Session 对象的方法
- public Session getSession() {
- return getSessionFactory().getCurrentSession();
- }
- //获取 SessionFactory 对象的方法
- public SessionFactory getSessionFactory() {
- if(sessionFactory == null) {
- Configuration configuration = new Configuration().configure();
- ServiceRegistry serviceRegistry = new ServiceRegistryBuilder().applySettings(configuration.getProperties()).buildServiceRegistry();
- sessionFactory = configuration.buildSessionFactory(serviceRegistry);
- }
- return sessionFactory;
- }
- }
3)构建一个 DepartmentDao 类
- public class DepartmentDao {
- public void save(Department dept) {
- /**
- * 内部获取 Session 对象,获取和当前线程绑定的 Session 对象
- * 优点: 1.不需要从外部传入 Session对象
- * 2. 多个 DAO 方法可以使用一个事务
- */
- Session session = HibernateUtils.getInstance().getSession();
- System.out.println(session.hashCode());
- session.save(dept);
- }
- /**
- * 若需要传入一个 Session 对象, 则意味着上一层(Service)需要获取到 Session 对象.
- * 这说明上一层需要和 Hibernate 的 API 紧密耦合. 所以不推荐使用此种方式.
- */
- public void save(Session session, Department dept) {
- session.save(dept);
- }
- }
4)测试:

6、建议使用原生的 JDBC 的API 进行批量操作

Hibernate 学习笔记 - 2的更多相关文章
- Hibernate学习笔记(二)
2016/4/22 23:19:44 Hibernate学习笔记(二) 1.1 Hibernate的持久化类状态 1.1.1 Hibernate的持久化类状态 持久化:就是一个实体类与数据库表建立了映 ...
- Hibernate学习笔记(一)
2016/4/18 19:58:58 Hibernate学习笔记(一) 1.Hibernate框架的概述: 就是一个持久层的ORM框架. ORM:对象关系映射.将Java中实体对象与关系型数据库中表建 ...
- Hibernate 学习笔记一
Hibernate 学习笔记一 今天学习了hibernate的一点入门知识,主要是配置domain对象和表的关系映射,hibernate的一些常用的配置,以及对应的一个向数据库插入数据的小例子.期间碰 ...
- Hibernate学习笔记-Hibernate HQL查询
Session是持久层操作的基础,相当于JDBC中的Connection,通过Session会话来保存.更新.查找数据.session是Hibernate运作的中心,对象的生命周期.事务的管理.数据库 ...
- Hibernate学习笔记
一.Hibernate基础 1.Hibernate简介 Hibernate是一种对象关系映射(ORM)框架,是实现持久化存储的一种解决方案.Java包括Java类到数据库表的映射和数据查询及获取的方法 ...
- Hibernate学习笔记(四)
我是从b站视频上学习的hibernate框架,其中有很多和当前版本不符合之处,我在笔记中进行了修改以下是b站视频地址:https://www.bilibili.com/video/av14626440 ...
- Hibernate学习笔记(三)
我是从b站视频上学习的hibernate框架,其中有很多和当前版本不符合之处,我在笔记中进行了修改以下是b站视频地址:https://www.bilibili.com/video/av14626440 ...
- HIbernate学习笔记(一) 了解hibernate并搭建环境建立第一个hello world程序
Hibernate是一个开放源代码的ORM(对象关系映射)框架,它对JDBC进行了轻量级的封装,Java程序员可以使用面向对象的编程思维来操纵数据库,它通过对象属性和数据库表字段之间的映射关系,将对象 ...
- Hibernate学习笔记-Hibernate关系映射
1. 初识Hibernate——关系映射 http://blog.csdn.net/laner0515/article/details/12905711 2. Hibernate 笔记8 关系映射1( ...
- Hibernate学习笔记(1)Hibernate构造
一 准备工作 首先,我们将创建一个简单的基于控制台(console-based)Hibernate应用. 我们所做的第一件事就是创建我们的开发文件夹.并把所有需要用到的Java件放进去.解压缩从Hib ...
随机推荐
- 团队作业2——需求分析&原型设计
Deadline: 2017-4-14 22:00PM,以博客发表日期为准 评分基准: 按时交 - 有分,检查的项目包括后文的三个方面 需求分析 原型设计 编码规范 晚交 - 0分 迟交两周以上 - ...
- 第1周-java作业总结与建议
1. 本周作业简评与建议 存在的问题: 这周的作业普遍存在一个格式混乱的问题.请认真学习Markdown,我们后面的作业都要使用Markdown.Markdown学习请参考http://group.c ...
- 201521123098 《Java程序设计》 第5周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关多态与接口的知识点. 1.2 可选:使用常规方法总结其他上课内容. 1. 对接口这一定义有了初步的了解: 2. 学习了如何定义实现类和如何实现一些接 ...
- Java中的基本数据类型和基本数据类型之间的转换
在Java中有8中基本数据类型,分别为: 整型: byte.short.int.long 浮点型:float.double 布尔型:boolean 字符型:char. byte: 8位, 封装 ...
- PTA中提交Java程序的一些套路
201708新版改版说明 PTA与2017年8月已升级成新版,域名改为https://pintia.cn/,官方建议使用Firefox与Chrome浏览器. 旧版 PTA 用户首次在新版系统登录时,请 ...
- 201521123018 《Java程序设计》第13周学习总结
1. 本章学习总结 2. 书面作业 一.1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu.edu.cn,分析返回结果有何不同?为什么会有这样的不同? 返回时间 ...
- 201521123109 《java程序设计》第13周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图.OneNote或其他)归纳总结多网络相关内容. 2. 书面作业 1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu ...
- hadoop运行wordcount实例,hdfs简单操作
1.查看hadoop版本 [hadoop@ltt1 sbin]$ hadoop version Hadoop -cdh5.12.0 Subversion http://github.com/cloud ...
- 商城项目整理(四)JDBC+富文本编辑器实现商品增加,样式设置,和修改
UEditor富文本编辑器:http://ueditor.baidu.com/website/ 相应页面展示: 商品添加: 商品修改: 前台商品展示: 商品表建表语句: create table TE ...
- readfile & file_get_contents异同
记录一下:应用memcache时,准备把整个文件缓存到内存中,遇到了比较奇怪的事情,因为最初使用readfile来读取文件,结果这个函数返回一个字节数,而不是一个字符串,于是文件没办法再输出,最后使用 ...