Video Target Tracking Based on Online Learning—深度学习在目标跟踪中的应用
- 摘要
近年来,深度学习方法在物体跟踪领域有不少成功应用,并逐渐在性能上超越传统方法。本文先对现有基于深度学习的目标跟踪算法进行了分类梳理,后续会分篇对各个算法进行详细描述。

看上方给出的3张图片,它们分别是同一个视频的第1,40,80帧。在第1帧给出一个跑步者的边框(bounding-box)之后,后续的第40帧,80帧,bounding-box依然准确圈出了同一个跑步者。以上展示的其实就是目标跟踪(visual object tracking)的过程。目标跟踪(特指单目标跟踪)是指:给出目标在跟踪视频第一帧中的初始状态(如位置,尺寸),自动估计目标物体在后续帧中的状态。
人眼可以比较轻松的在一段时间内跟住某个特定目标。但是对机器而言,这一任务并不简单,尤其是跟踪过程中会出现目标发生剧烈形变、被其他目标遮挡或出现相似物体干扰等等各种复杂的情况。过去几十年以来,目标跟踪的研究取得了长足的发展,尤其是各种机器学习算法被引入以来,目标跟踪算法呈现百花齐放的态势。2013年以来,深度学习方法开始在目标跟踪领域展露头脚,并逐渐在性能上超越传统方法,取得巨大的突破。本文首先简要介绍主流的传统目标跟踪方法,之后对基于深度学习的目标跟踪算法进行介绍,最后对深度学习在目标跟踪领域的应用进行总结和展望。
- 经典目标跟踪方法回顾
经典视频目标跟踪领域从以Mean Shift为代表的产生式模型(generative model)开始,在10年前逐渐引入各种机器学习方法过渡到判别式模型(discriminative model),到近年又发展到基于相关滤波(correlation filter)的跟踪方法,发展形势如火如荼,成果显著。这些方法的一个共同特点是均以tracking by detection/classification为框架,通过完善框架中的不同模型完成的。
产生式方法运用生成模型描述目标的表观特征,之后通过搜索候选目标来最小化重构误差。比较有代表性的算法有稀疏编码(sparse coding),在线密度估计(online density estimation)和主成分分析(PCA)等。产生式方法着眼于对目标本身的刻画,忽略背景信息,在目标自身变化剧烈或者被遮挡时容易产生漂移。
判别式方法通过训练分类器来区分目标和背景。这种方法也常被称为tracking-by-detection。近年来,各种机器学习算法被应用在判别式方法上,其中比较有代表性的有多示例学习方法(multiple instance learning), boosting和结构SVM(structured SVM)等。判别式方法因为显著区分背景和前景的信息,表现更为鲁棒,逐渐在目标跟踪领域占据主流地位。值得一提的是,目前大部分深度学习目标跟踪方法也归属于判别式框架。
基于相关滤波(correlation filter)的跟踪方法通过将输入特征回归为目标高斯分布来训练 filters。并在后续跟踪中寻找预测分布中的响应峰值来定位目标的位置。相关滤波器在运算中巧妙应用快速傅立叶变换获得了大幅度速度提升。目前基于相关滤波的拓展方法也有很多,包括核化相关滤波器(kernelized correlation filter, KCF), 加尺度估计的相关滤波器(DSST)等。
- 基于深度学习的目标跟踪方法综述
近年,随着Alphago在围棋界取得无往不胜的战绩。以深度学习为核心的人工智能技术得到极大发展。然而,不同于检测、识别等视觉领域深度学习一统天下的趋势,深度学习在目标跟踪领域的应用并非一帆风顺。其主要问题在于训练数据的缺失:深度模型的魔力之一来自于对大量标注训练数据的有效学习,而目标跟踪仅仅提供第一帧的bounding-box作为训练数据。这种情况下,在跟踪开始针对当前目标从头训练一个深度模型困难重重。
目前,基于深度学习的目标跟踪算法采用了几种思路来解决这个问题,本博文将展开介绍,并在最后介绍智能化目标跟踪的最新发展思路。
1)利用辅助图片数据预训练深度模型,在线跟踪时微调
在目标跟踪的训练数据非常有限的情况下,使用辅助的非跟踪训练数据进行预训练,获取对物体特征的通用表示(general representation ),在实际跟踪时,通过利用当前跟踪目标的有限样本信息对预训练模型微调(fine-tune), 使模型对当前跟踪目标有更强的分类性能,这种迁移学习的思路极大的减少了对跟踪目标训练样本的需求,也提高了跟踪算法的性能。这个方面代表性的作品有DLT和SO-DLT。
- DLT(NIPS2013) Learning a Deep Compact Image Representation for Visual Tracking

DLT是第一个把深度模型运用在单目标跟踪任务上的跟踪算法。它的主体思路如上图所示:
(1) 先使用栈式降噪自编码器(stacked denoising autoencoder,SDAE)在Tiny Images dataset这样的大规模自然图像数据集上进行无监督的离线预训练来获得通用的物体表征能力。预训练的网络结构如上图(b)所示,一共堆叠了4个降噪自编码器, 降噪自编码器对输入加入噪声,通过重构出无噪声的原图来获得更鲁棒的特征表达能力。SDAE1024-2560-1024-512-256这样的瓶颈式结构设计也使获得的特征更加compact。
(2) 之后的在线跟踪部分结构如上图(c)所示,取离线SDAE的encoding部分叠加sigmoid分类层组成了分类网络。此时的网络并没有获取对当前被跟踪物体的特定表达能力。此时利用第一帧获取正负样本,对分类网络进行fine-tune获得对当前跟踪目标和背景更有针对性的分类网络。在跟踪过程中,对当前帧采用粒子滤波(particle filter)的方式提取一批候选的patch(相当于detection中的proposal),这些patch输入分类网络中,置信度最高的成为最终的预测目标。
(3) 在目标跟踪非常重要的模型更新策略上,该论文采取限定阈值方式,即当所有粒子中最高的confidence低于阈值时,认为目标已经发生了比较大的表观变化,当前的分类网络已经无法适应,需要进行更新。
小结:DLT作为第一个将深度网络用于单目标跟踪的算法,首先提出了“离线预训练+在线微调”思路,很大程度解决了跟踪中训练样本不足问题,在CVPR2013提出的OTB50数据集上的29个跟踪器中排名第5。
但是DLT本身也存在一些不足:
(1) 离线预训练采用的数据集Tiny Images dataset只包含32*32大小的图片,分辨率明显低于主要的跟踪序列,因此SDAE很难学到足够强的特征表示。
(2) 离线阶段的训练目标为图片重构,这与在线跟踪需要区分目标和背景的目标相差甚大。
(3) SDAE全连接的网络结构使其对目标的特征刻画能力不够优秀,虽然使用了4层的深度模型,但效果仍低于一些使用人工特征的传统跟踪方法如Struck等。
- SO-DLT(arXiv2015) Transferring Rich Feature Hierarchies for Robust Visual Tracking
SO-DLT延续了DLT利用非跟踪数据预训练加在线微调的策略,来解决跟踪过程中训练数据不足的问题,同时也对DLT存在的问题做了很大的改进。

(1) 使用CNN作为获取特征和分类的网络模型。如上图所示,SO-DLT使用了的类似AlexNet的网络结构,但是有几大特点:一、针对跟踪候选区域的大小将输入缩小为100*100,而不是一般分类或检测任务中的224*224。 二、网络的输出为50*50大小,值在0-1之间的概率图(probability map),每个输出像素对应原图2*2的区域,输出值越高则该点在目标bounding-box中的概率也越高。这样的做法利用了图片本身的结构化信息,方便直接从概率图确定最终的bounding-box,避免向网络输入数以百计的proposal,这也是SO-DLT structured output得名的由来。三、在卷积层和全连接层中间采用SPP-NET中的空间金字塔采样(spatial pyramid pooling)来提高最终的定位准确度。
(2) 在离线训练中使用ImageNet 2014的detection数据集使CNN获得区分object和非object(背景)的能力。
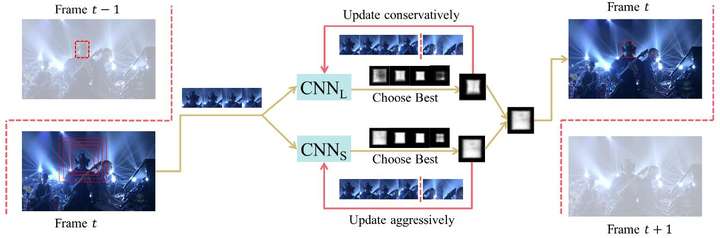
SO-DLT在线跟踪的pipeline如上图所示:
(1) 处理第t帧时,首先以第t-1帧的的预测位置为中心,从小到大以不同尺度crop区域放入CNN当中,当CNN输出的probability map的总和高于一定阈值时,停止crop, 以当前尺度作为最佳的搜索区域大小。
(2) 选定第t帧的最佳搜索区域后,在该区域输出的probability map上采取一系列策略确定最终的bounding-box中心位置和大小。
(3) 在模型更新方面,为了解决使用不准确结果fine-tune导致的drift问题,使用了long-term 和short-term两个CNN,即CNNs和CNNl。CNNs更新频繁,使其对目标的表观变化及时响应。CNNl更新较少,使其对错误结果更加鲁棒。二者结合,取最confident的结果作为输出。从而在adaptation和drift之间达到一个均衡。
小结:SO-DLT作为large-scale CNN网络在目标跟踪领域的一次成功应用,取得了非常优异的表现:在CVPR2013提出的OTB50数据集上OPE准确度绘图(precision plot)达到了0.819, OPE成功率绘图(success plot)达到了0.602。远超当时其它的state of the art。
SO-DLT有几点值得借鉴:
(1) 针对tracking问题设计了有针对性的网络结构。
(2) 应用CNNS和CNNL用ensemble的思路解决update 的敏感性,特定参数取多值做平滑,解决参数取值的敏感性。这些措施目前已成为跟踪算法提高评分的杀手锏。
但是SO-DLT离线预训练依然使用的是大量无关联图片,作者认为使用更贴合跟踪实质的时序关联数据是一个更好的选择。
2)利用现有大规模分类数据集预训练的CNN分类网络提取特征
2015年以来,在目标跟踪领域应用深度学习兴起了一股新的潮流。即直接使用ImageNet这样的大规模分类数据库上训练出的CNN网络如VGG-Net获得目标的特征表示,之后再用观测模型(observation model)进行分类获得跟踪结果。这种做法既避开了跟踪时直接训练large-scale CNN样本不足的困境,也充分利用了深度特征强大的表征能力。这样的工作在ICML15,ICCV15,CVPR16均有出现。下面介绍两篇发表于ICCV15的工作。
- FCNT(ICCV15) Visual Tracking with Fully Convolutional Networks
作为应用CNN特征于物体跟踪的代表作品,FCNT的亮点之一在于对ImageNet上预训练得到的CNN特征在目标跟踪任务上的性能做了深入的分析,并根据分析结果设计了后续的网络结构。
FCNT主要对VGG-16的Conv4-3和Conv5-3层输出的特征图谱(feature map)做了分析,并得出以下结论:
(1) CNN 的feature map可以用来做跟踪目标的定位。
(2) CNN 的许多feature map存在噪声或者和物体跟踪区分目标和背景的任务关联较小。
(3) CNN不同层的特征特点不一。高层(Conv5-3)特征擅长区分不同类别的物体,对目标的形变和遮挡非常鲁棒,但是对类内物体的区分能力非常差。低层(Conv4-3)特征更关注目标的局部细节,可以用来区分背景中相似的distractor,但是对目标的剧烈形变非常不鲁棒。
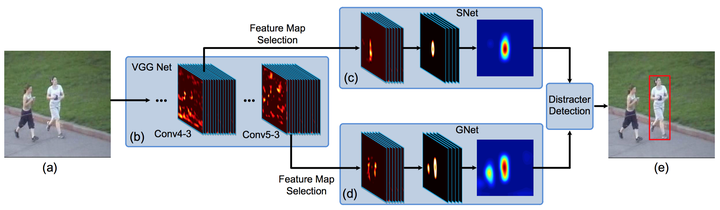
依据以上分析,FCNT最终形成了如上图所示的框架结构:
(1) 对于Conv4-3和Conv5-3特征分别构建特征选择网络sel-CNN(1层dropout加1层卷积),选出和当前跟踪目标最相关的feature map channel。
(2) 对筛选出的Conv5-3和Conv4-3特征分别构建捕捉类别信息的GNet和区分distractor(背景相似物体)的SNet(都是两层卷积结构)。
(3) 在第一帧中使用给出的bounding-box生成热度图(heat map)回归训练sel-CNN, GNet和SNet。
(4) 对于每一帧,以上一帧预测结果为中心crop出一块区域,之后分别输入GNet和SNet,得到两个预测的heatmap,并根据是否有distractor决定使用哪个heatmap 生成最终的跟踪结果。
小结:FCNT根据对CNN不同层特征的分析,构建特征筛选网络和两个互补的heat-map预测网络。达到有效抑制distractor防止跟踪器漂移,同时对目标本身的形变更加鲁棒的效果,也是ensemble思路的又一成功实现。在CVPR2013提出的OTB50数据集上OPE准确度绘图(precision plot)达到了0.856,OPE成功率绘图(success plot)达到了0.599,准确度绘图有较大提高。实际测试中FCNT的对遮挡的表现不是很鲁棒,现有的更新策略还有提高空间。
- Hierarchical Convolutional Features for Visual Tracking(ICCV15)
这篇是作者在2015年度看到的最简洁有效的利用深度特征做跟踪的论文。其主要思路是提取深度特征,之后利用相关滤波器确定最终的bounding-box。
这篇论文简要分析了VGG-19特征( Conv3_4, Conv4_4, Conv5_4 )在目标跟踪上的特性,得出的结论和FCNT有异曲同工之处,即:
(1) 高层特征主要反映目标的语义特性,对目标的表观变化比较鲁棒。
(2) 低层特征保存了更多细粒度的空间特性,对跟踪目标的精确定位更有效。
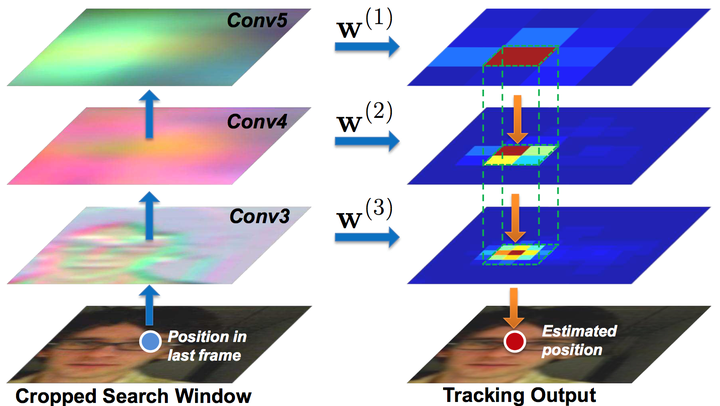
基于以上结论,作者给出了一个粗粒度到细粒度(coarse-to-fine)的跟踪算法即:
(1) 第一帧时,利用Conv3_4,Conv4_4,Conv5_4特征的插值分别训练得到3个相关滤波器。
(2) 之后的每帧,以上一帧的预测结果为中心crop出一块区域,获取三个卷积层的特征,做插值,并通过每层的相关滤波器预测二维的confidence score。
(3) 从Conv5_4开始算出confidence score上最大的响应点,作为预测的bounding-box的中心位置,之后以这个位置约束下一层的搜索范围,逐层向下做更细粒度的位置预测,以最低层的预测结果作为最后输出。具体公式如下:
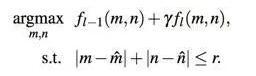
(4) 利用当前跟踪结果对每一层的相关滤波器做更新。
小结:这篇文章针对VGG-19各层特征的特点,由粗粒度到细粒度最终准确定位目标的中心点。在CVPR2013提出的OTB50数据集上OPE准确度绘图达到了0.891,OPE成功率绘图达到了0.605,相较于FCNT和SO-DLT都有提高,实际测试时性能也相当稳定,显示出深度特征结合相关滤波器的巨大优势。但是这篇文章中的相关滤波器并没有对尺度进行处理,在整个跟踪序列中都假定目标尺度不变。在一些尺度变化非常剧烈的测试序列上如CarScale上最终预测出的bounding-box尺寸大小和目标本身大小相差较大。
以上两篇文章均是应用预训练的CNN网络提取特征提高跟踪性能的成功案例,说明利用这种思路解决训练数据缺失和提高性能具有很高的可行性。但是分类任务预训练的CNN网络本身更关注区分类间物体,忽略类内差别。目标跟踪时只关注一个物体,重点区分该物体和背景信息,明显抑制背景中的同类物体,但是还需要对目标本身的变化鲁棒。分类任务以相似的一众物体为一类,跟踪任务以同一个物体的不同表观为一类,使得这两个任务存在很大差别,这也是两篇文章融合多层特征来做跟踪以达到较理想效果的动机所在。
3)利用跟踪序列预训练,在线跟踪时微调
1)和2)中介绍的解决训练数据不足的策略和目标跟踪的任务本身存在一定偏离。有没有更好的办法呢?VOT2015冠军MDNet给出了一个示范。该方法在OTB50上也取得了OPE准确度绘图0.942,OPE成功率绘图0.702的惊人得分。
- MDNet(CVPR2016) Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
意识到图像分类任务和跟踪之间存在巨大差别,MDNet提出直接用跟踪视频预训练CNN获得general的目标表示能力的方法。但是序列训练也存在问题,即不同跟踪序列跟踪目标完全不一样,某类物体在一个序列中是跟踪目标,在另外一个序列中可能只是背景。不同序列中目标本身的表观和运动模式、环境中光照、遮挡等情形相差甚大。这种情况下,想要用同一个CNN完成所有训练序列中前景和背景区分的任务,困难重重。
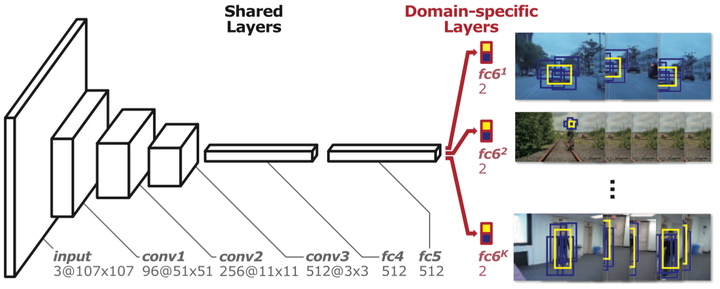
最终MDNet提出Multi-Domain的训练思路和如上图所示的Multi-Domain Network。该网络分为共享层和domain-specific层两部分。即:将每个训练序列当成一个单独的domain,每个domain都有一个针对它的二分类层(fc6),用于区分当前序列的前景和背景,而网络之前的所有层都是序列共享的。这样共享层达到了学习跟踪序列中目标general的特征表达的目的,而domain-specific层又解决了不同训练序列分类目标不一致的问题。
具体训练时,MDNet的每个mini-batch只由一个特定序列的训练数据构成,只更新共享层和针对当前序列的特定fc6层。这样共享层中获得了对序列共有特征的表达能力,如对光照、形变等的鲁棒性。MDNet的训练数据也非常有意思,即测试OTB100数据集时,利用VOT2013-2015的不重合的58个序列来做预训练。测试VOT2014数据集时,利用OTB100上不重合的89个序列做预训练。这种交替利用的思路也是第一次在跟踪论文中出现。
在线跟踪阶段针对每个跟踪序列,MDNet主要有以下几步:
(1) 随机初始化一个新的fc6层。
(2) 使用第一帧的数据来训练该序列的bounding box回归模型。
(3) 用第一帧提取正样本和负样本,更新fc4, fc5和fc6层的权重。
(4) 之后产生256个候选样本,并从中选择置信度最高的,之后做bounding-box regression得到最终结果。
(5) 当前帧最终结果置信度较高时,采样更新样本库,否则根据情况对模型做短期或者长期更新。
MDNet有两点值得借鉴之处:
(1) MDNet应用了更为贴合跟踪实质的视频数据来做训练,并提出了创新的Multi-domain训练方法和训练数据交叉运用的思路。
(2) 此外MDNet从检测任务中借鉴了不少行之有效的策略,如难例挖掘(hard negative mining),bounding box回归等。尤其是难例回归通过重点关注背景中的难点样本(如相似物体等)显著减轻了跟踪器漂移的问题。这些策略也帮助MDNet在TPAMI2015 OTB100数据集上OPE准确度绘图从一开始的0.825提升到0.908, OPE成功率绘图从一开始的0.589提升到0.673。
但是也可以发现MDNet的总体思路和RCNN比较类似,需要前向传递上百个proposal,虽然网络结构较小,速度仍较慢。且boundingbox回归也需要单独训练,因此MDNet还有进一步提升的空间。
4)运用递归神经网络进行目标跟踪的新思路
近年来RNN尤其是带有门结构的LSTM,GRU等在时序任务上显示出了突出性能。不少研究者开始探索如何应用RNN来做解决现有跟踪任务中存在的问题,以下简要介绍两篇在这方面比较有代表性的探索文章。
- RTT(CVPR16) Recurrently Target-Attending Tracking
这篇文章的出发点比较有意思,即利用多方向递归神经网络(multi-directional recurrent neural network)来建模和挖掘对整体跟踪有用的可靠目标部分(reliable part),实际上是二维平面上的RNN建模,最终解决预测误差累积和传播导致的跟踪漂移问题。其本身也是对part-based跟踪方法和相关滤波(correlation filter)方法的改进和探索。
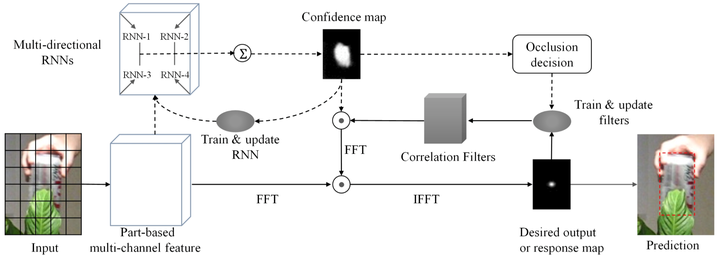
RTT的整体框架如上图所示:
(1) 首先对每一帧的候选区域进行网状分块,对每个分块提取HOG特征,最终相连获得基于块的特征
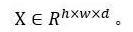
(2) 得到分块特征以后,RTT利用前5帧训练多方向RNN来学习分块之间大范围的空间关联。
通过在4个方向上的前向推进,RNN计算出每个分块的置信度,最终每个块的预测值组成了整个候选区域的置信图(confidence map)。受益于RNN的recurrent结构,每个分块的输出值都受到其他关联分块的影响,相比于仅仅考虑当前块的准确度更高,避免单个方向上遮挡等的影响,增加可靠目标部分在整体置信图中的影响。
(3) 由RNN得出置信图之后,RTT执行了另外一条pipeline。即训练相关滤波器来获得最终的跟踪结果。值得注意的是,在训练过程中RNN的置信图对不同块的filter做了加权,达到抑制背景中的相似物体,增强可靠部分的效果。
(4) RTT提出了一个判断当前跟踪物体是否被遮挡的策略,用其判断是否更新。即计算目标区域的置信度和,并与历史置信度和的移动平均数(moving average)做一个对比,低于一定比例,则认为受到遮挡,停止模型更新,防止引入噪声。
小结:RTT是第一个利用RNN来建模part-based跟踪任务中复杂的大范围关联关系的跟踪算法。在CVPR2013提出的OTB50数据集上OPE准确度绘图为0.827,OPE成功率绘图达到了0.588。相比于其他基于传统特征的相关滤波器算法有较大的提升,说明RNN对关联关系的挖掘和对滤波器的约束确实有效。RTT受制于参数数目的影响,只选用了参数较少的普通RNN结构(采用HOG特征其实也是降低参数的另外一种折中策略)。结合之前介绍的解决训练数据缺失的措施,RTT可以运用更好的特征和RNN结构,效果还有提升空间。
- DeepTracking: Seeing Beyond Seeing Using Recurrent Neural Networks(AAAI16)
这篇文章的应用场景是机器人视觉,目标是将传感器获得的有遮挡的环境信息还原为真实的无遮挡的环境信息。严格来说这篇文章仅输出还原后的图片,没有明确预测目标的位置和尺寸等状态信息,和之前介绍的所有文章的做法都不一样,不妨称为一种新的跟踪任务。
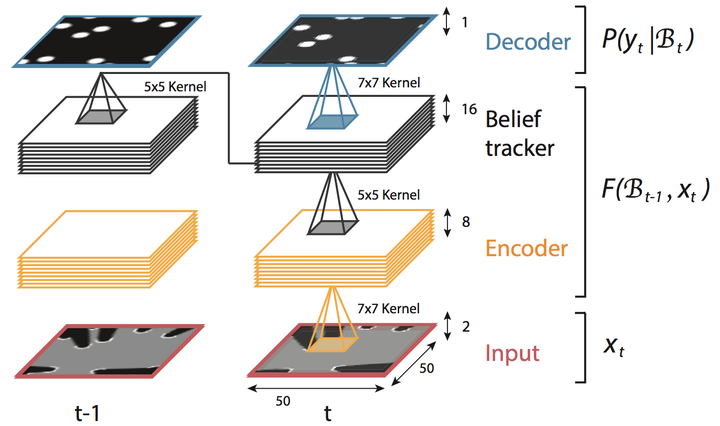
在模型方面,不同于RTT用RNN建模二维平面关联,DeepTracking利用RNN来做序列关联的建模,并最终实现了端到端的跟踪算法。
传统的贝叶斯跟踪方法一般采用高斯分布(卡尔曼滤波Kalman filter)或者离散的采样点权重(粒子滤波particle filter)来近似需要求解的后验概率 P(yt|x1:t) (yt 为需要预测的机器人周围的真实场景, xt 为传感器直接获得的场景信息),其表达能力有限。DeepTracking拓展了传统的贝叶斯跟踪框架,并利用RNN强大的表征能力来建模后验概率。
具体而言DeepTracking引入了一个具有马尔可夫性质的隐变量 ht ,认为其反映了真实环境的全部信息。最终需要预测的 yt 包含了 ht,包含了 ht 的部分信息,可由 ht 得到。假设 Bt 为关于 ht 的信念(belief),对应于后验概率:Bel(ht) = P(yt|ht) 。之后经典贝叶斯跟踪框架中由 P(yt-1|x1:t-1) 到 P(yt|x1:t) 到的时序更新在这里转化为:Bt = F(Bt-1,xt)和 P(ty|x1:t) = P(yt|Bt)。
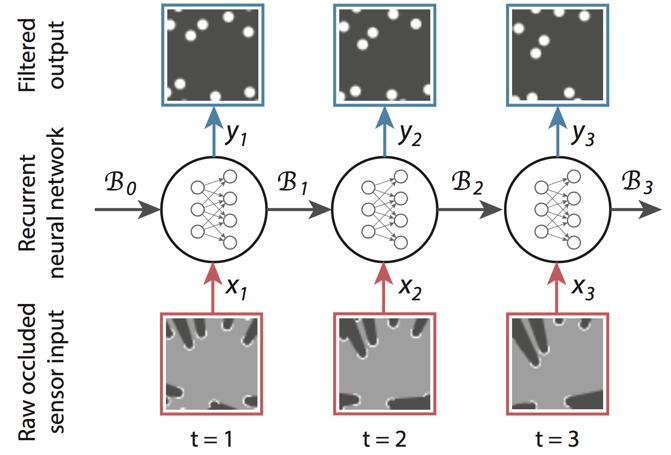
给出形式表达之后的关键是,如何将其对应到RNN的框架中去。DeepTracking的核心思路是用利用两个权重 WF 和 WP 来分别建模 F(Bt-1, xt)和P(yt|Bt ),将Bt 定义为RNN时序之间传递的memory 信息。此时,如上图所示RNN的各个状态和推进流程就和跟踪任务完美的对接上了。
小结:
DeepTracking作为用RNN建模跟踪时序任务的作品,其亮点主要在对RNN和贝叶斯框架融合的理论建模上。实验展示了该方法在模拟场景下的不错效果,但是模拟数据和真实场景差距很大,能否在实际应用中有比较好的表现还有待商榷。
- 基于深度学习的目标跟踪方法发展展望
1)tracking by detection/classification是唯一框架吗?
尽管深度学习已经应用与目标跟踪,但是研究框架仍然没有跳出传统的tracking by detection/classification。目前的问题是:这是解决tracking问题的一个本质方法么?在开始介绍这两篇文章之前不妨再回顾下Single Object Tracking(SOT)这个问题。
2)深度的另一种理解?
1)中提出跟踪的本质应该是verification,而不应该是目前主流的tracking by detection/classification,同时也指出feature是跟踪问题最核心的环节。
但是也有不同的看法。因为无论是detection还是verification,都是不够intuitive的。首先,我们考虑跟踪问题中很棘手的情况。例如遮挡、物体消失、周围相似物体、罕见形变。然而这些问题对于人而言,多数情况下其实都是容易的。个人认为,其中最重要的因素是“常识”,或者说是“运动规律”。遮挡和物体消失最为核心的依旧是feature,但罕见形变可能feature就会发生很大的变化,而且跟踪过程中的罕见形变可能是突然的,也就是说,只有很少几帧的图像可以用来在线训练,这显然是不够的,针对这个问题,个人考虑可以结合GAN来处理,详细细节这里暂时不说。
周围相似物体这是跟踪问题里很难的一个问题,而这个问题显然就不再是verification了,这里我们假设极端情况,比如说同一款车、双胞胎擦肩而过,这种时候,单从feature来解释显然是不可以的,但是,多数情况下,人是可以处理的,即使两个物体相似程度很高。这里就是前面提到的“常识”或“运动规律”。这种规律是物体具备的某种深层的语义信息,比如说,双胞胎擦肩而过,人预先能够通过运动规律判断,一个人往左边走,一个人往右边走,即使重叠了,人也是能够知道,一个人靠里被遮挡了,另一个靠外被直接看见了。这里就是“运动规律”的信息了,而无论是detection还是verification,都无法处理这类问题。你或许会质疑,这种情况发生的概率很小,应该更关注general的tracker啊,但我不这么认为。比如说道路上,车辆的相似度、街道上穿着一样的人。
这里引出“运动规律”这个概念,主要是考虑到目前跟踪算法主要关注精度和速度,而精度显然意味着更好的特征,一般认为CNN提取的特征更好(鉴于个人更看好“深度”这个方向,所以这里不提相关滤波)。但速度却是目前深度学习的最大难题。目前使用深度学习来做跟踪的方法速度慢,主要是因为在线finetune,finetune又涉及search region select、ROI confident score以及model update。
是否能够使用DNN或GAN去捕捉“运动规律”呢?offline学习到运动规律,简化NN在finetune时的计算,是不是能够同时起到提速和保持精度的可能呢?
关于”运动规律“,个人觉得可以先从经典的目标跟踪算法下手,比如说camshift、optical flow,这些方法其实都是很intuitive的,即使在今天,仍然是具有借鉴意义的。然后,可以考虑当前GAN的使用。据我了解,已经有使用GAN来预测视频后几帧的工作被提出了,预测过程中会不会含有某种”运动信息“的捕捉呢?
- 总结
本文介绍了深度学习在目标跟踪领域应用的几种不同思路。各方法解决训练数据缺失的思路各有千秋,效果较传统而言稍好。然而,基于深度学习的目标跟踪算法还有很大提升空间,目前已有的深度学习目标跟踪方法也还很难满足实时性的要求,如何设计网络和跟踪流程达到速度和效果的提升,还有很大的研究空间。
- 参考资料
[1]https://zhuanlan.zhihu.com/p/22334661
[2]http://www.cnblogs.com/liuyihai/p/8321299.html
- 博文预告
下一篇博文将详细讲述Learning Multi-Domain Convolutional Neural Networks for Visual Tracking(基于深度学习的MDNet的目标跟踪算法)-----欢迎阅读
Video Target Tracking Based on Online Learning—深度学习在目标跟踪中的应用的更多相关文章
- Video Target Tracking Based on Online Learning—TLD单目标跟踪算法详解
视频目标跟踪问题分析 视频跟踪技术的主要目的是从复杂多变的的背景环境中准确提取相关的目标特征,准确地识别出跟踪目标,并且对目标的位置和姿态等信息精确地定位,为后续目标物体行为分析提供足 ...
- Video Target Tracking Based on Online Learning—TLD多目标跟踪算法
TLD算法回顾 TLD(Tracking-Learning-Detection)是英国萨里大学的一个捷克籍博士生Zdenek Kalal在其攻读博士学位期间提出的一种新的单目标长时间(long ter ...
- 开源项目(9-0)综述--基于深度学习的目标跟踪sort与deep-sort
基于深度学习的目标跟踪sort与deep-sort https://github.com/Ewenwan/MVision/tree/master/3D_Object_Detection/Object_ ...
- #Deep Learning回顾#之基于深度学习的目标检测(阅读小结)
原文链接:https://www.52ml.net/20287.html 这篇博文主要讲了深度学习在目标检测中的发展. 博文首先介绍了传统的目标检测算法过程: 传统的目标检测一般使用滑动窗口的框架,主 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(下)
转载:http://www.jianshu.com/p/b73b6953e849 该资源的github地址:Qix <Statistical foundations of machine lea ...
- Deep Learning 深度学习 学习教程网站集锦
http://blog.sciencenet.cn/blog-517721-852551.html 学习笔记:深度学习是机器学习的突破 2006-2007年,加拿大多伦多大学教授.机器学习领域的泰斗G ...
- Deep Learning 深度学习 学习教程网站集锦(转)
http://blog.sciencenet.cn/blog-517721-852551.html 学习笔记:深度学习是机器学习的突破 2006-2007年,加拿大多伦多大学教授.机器学习领域的泰斗G ...
随机推荐
- bzoj 3597: [Scoi2014]方伯伯运椰子
Description Input 第一行包含二个整数N,M 接下来M行代表M条边,表示这个交通网络 每行六个整数,表示Ui,Vi,Ai,Bi,Ci,Di 接下来一行包含一条边,表示连接起点的边 Ou ...
- TreeMap源码
一.TreeMap简介 TreeMap是基于红黑树的java版实现,作者Josh Bloch and Doug Lea(这二人在java发展的早期做了重大贡献,比如集合框架JDK1.2.并发包JDK1 ...
- ab返回结果参数分析
Server Software 返回的第一次成功的服务器响应的HTTP头.Server Hostname 命令行中给出的域名或IP地址Server Port 命令行中给出端口.如果没 ...
- jquery提供的插件无法删除cookie的解决办法
之前使用jquery的cookie插件提供的 $.cookie("key",null)方法删除cookie,结果发现代码中的cookie一直无法删除,导致后面的种种问题. 经过各种 ...
- Solr 管理界面删除所有数据
https://my.oschina.net/lcdmusic/blog/326698
- K:java中序列化的两种方式—Serializable或Externalizable
在java中,对一个对象进行序列化操作,其有如下两种方式: 第一种: 通过实现java.io.Serializable接口,该接口是一个标志接口,其没有任何抽象方法需要进行重写,实现了Serializ ...
- thinkinginjava学习笔记05_访问权限
Java中访问权限等级从大到小依次为:public.protected.包访问权限(没有关键词).private: 以包访问权限为界限,public.protected分别可以被任意对象和继承的对象访 ...
- qt中建立图片资源文件
qt中如果你要添加图片资源文件我们需要执行以下步骤: (1)先找好一张图片,这里就不多说了,网上资源很多. (2)把我们找好的文件统一放到一个文件夹,然后拉到工程文件所在的文件夹下 (3)在qt中新建 ...
- AVFoundation 框架初探究(一)
夜深时动笔 前面一篇文章写了视频播放的几种基本的方式,算是给这个系列开了一个头,这里面最想说和探究的就是AVFoundation框架,很想把这个框架不敢说是完全理解,但至少想把它弄明白它里面到底有什么 ...
- css布局--水平垂直居中
1. 使用text-align 和 vertical-align 和 inline-block实现水平垂直居中 html <div class="parent"> &l ...