ML笔记:Gradient Descent
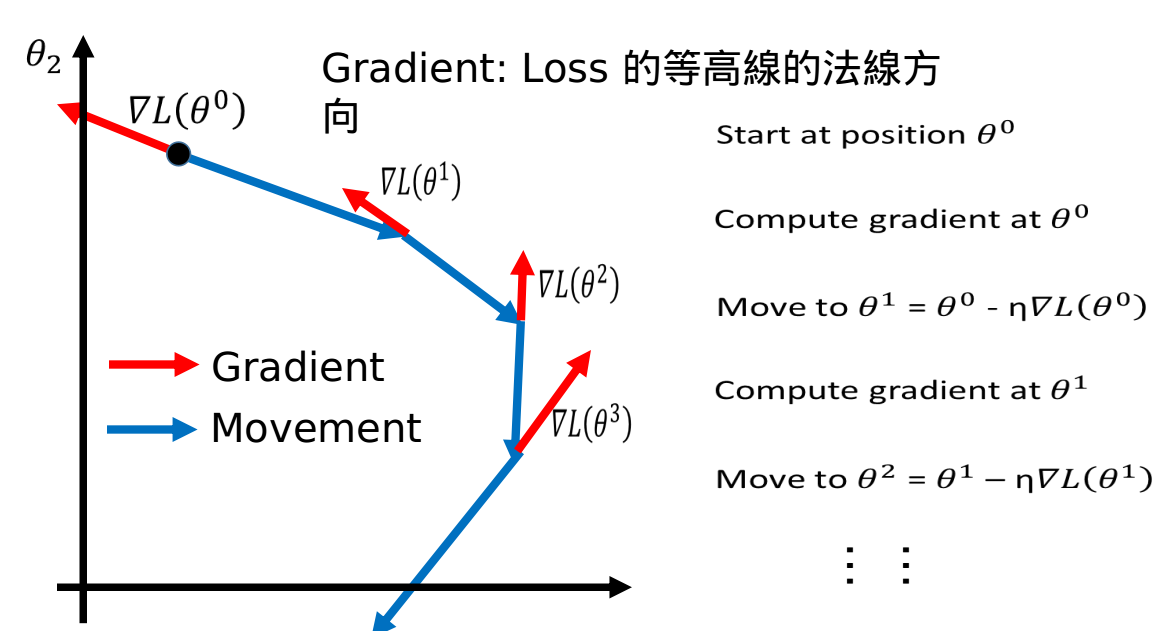
Review: Gradient Descent

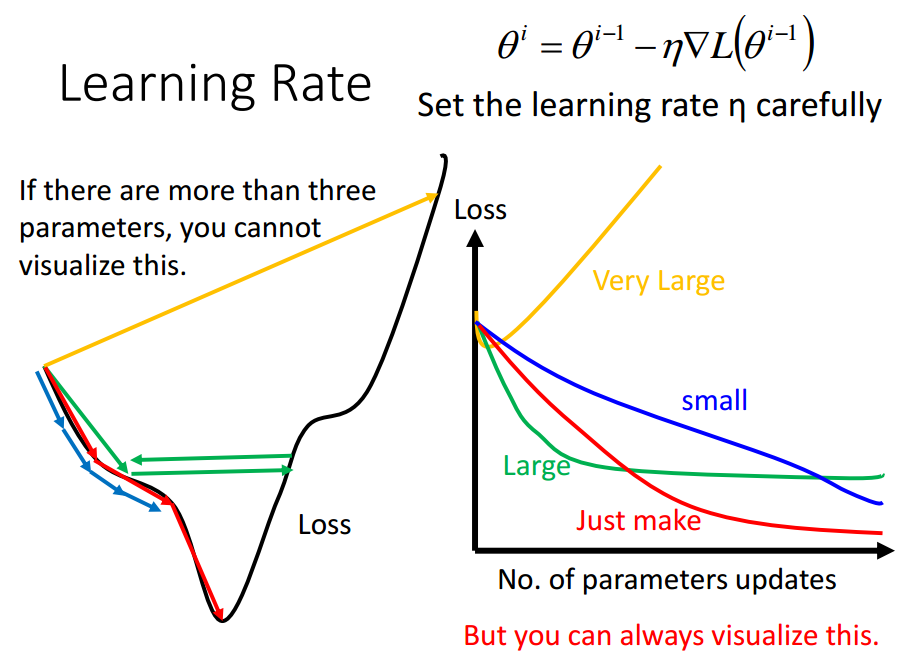
Tip 1: Tuning your learning rates
eta恰好,可以走到局部最小值点;
eta太小,走得太慢,也可以走到局部最小值点;
eta太大,很可能走不到局部最小值点,卡在某处上;
eta太太大,很可能走出去.
可以自动调节eta,
大原则是eta随更新次数的增长而减小,---time dependent
同时也要针对不同的参数设置不同的eta.---parameter dependent

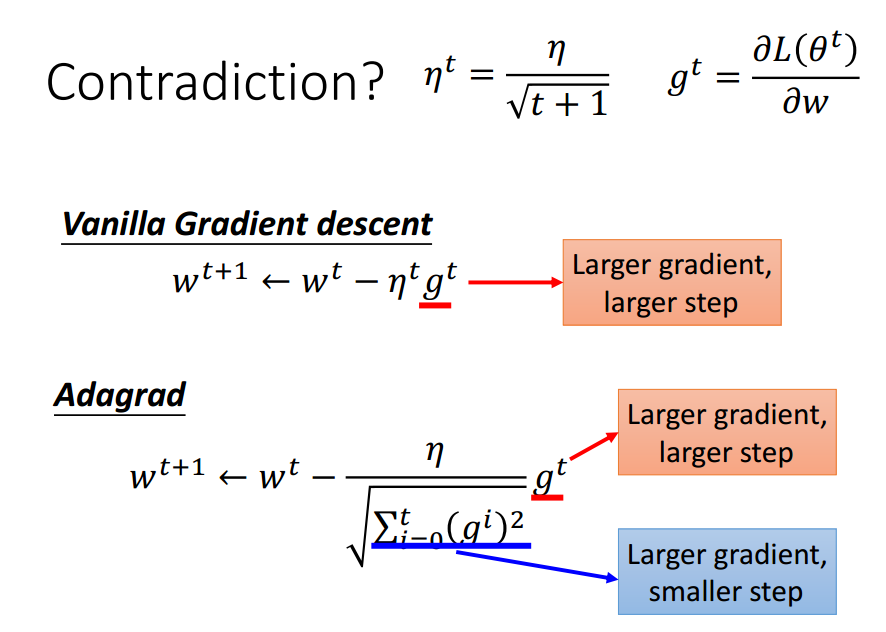
有很多这样的自动调节eta的梯度下降方法,名称常以Ada开头,
其中较为简单的Adagrad:

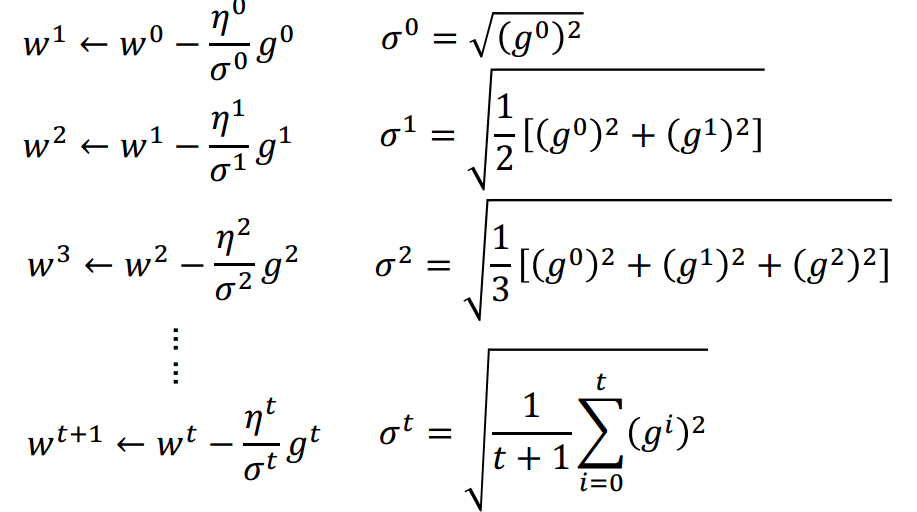
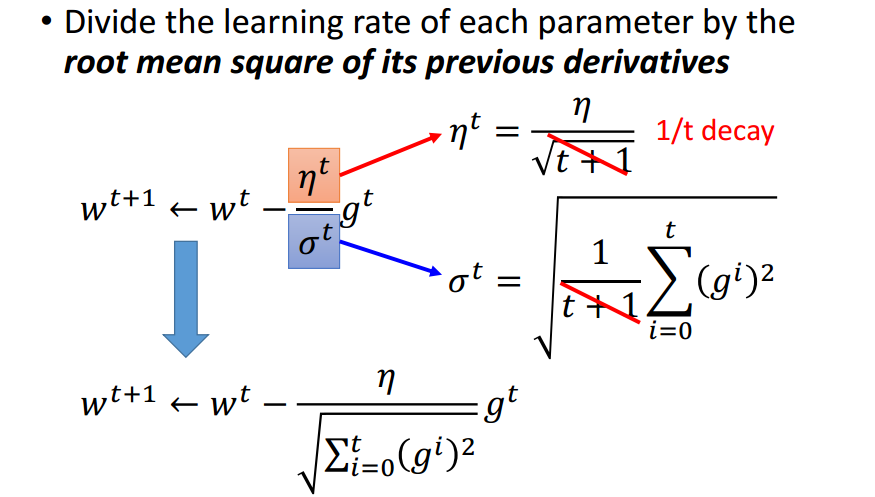
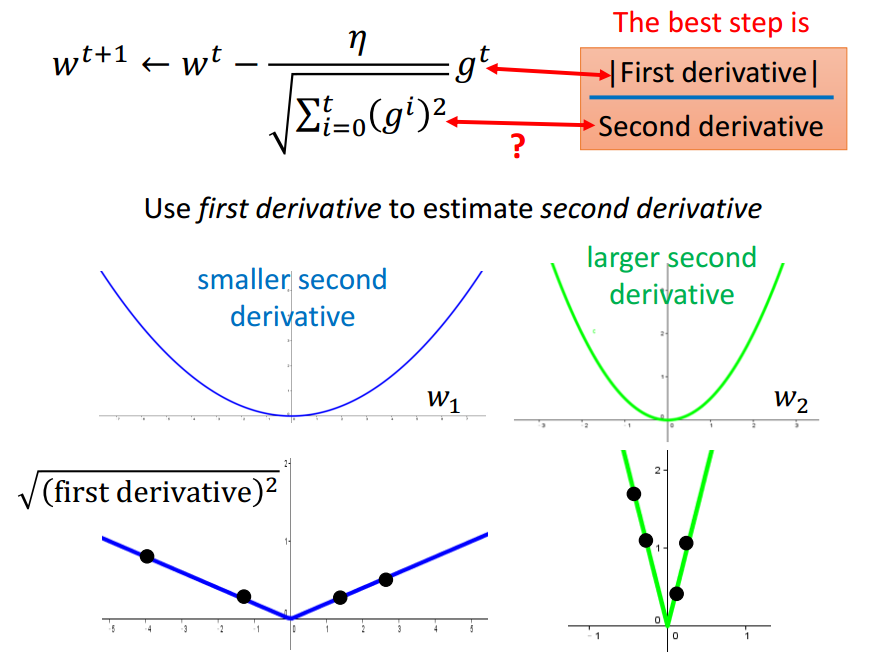
Adagrad强化反差.

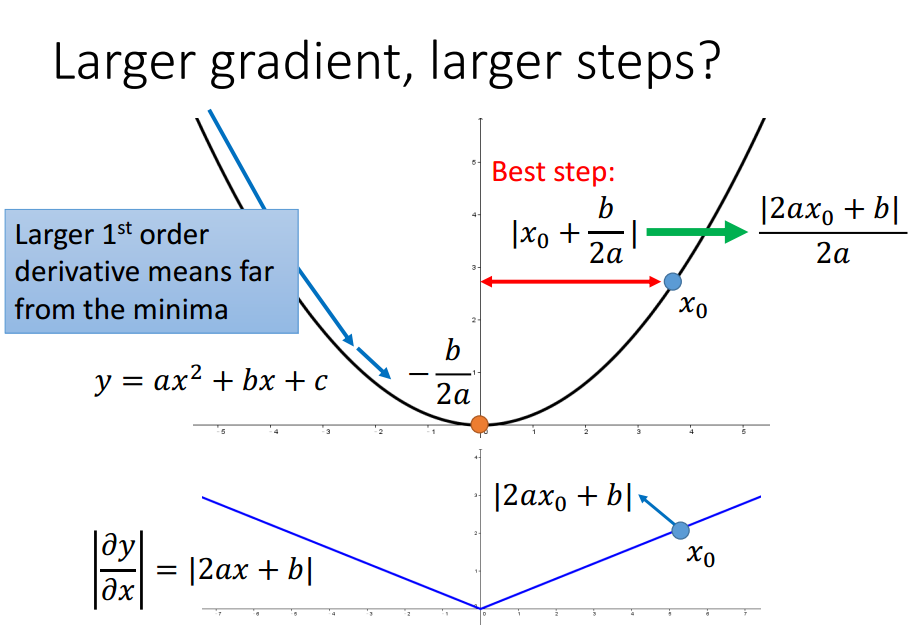
只考虑一个参数时,当前点与局部最优值点的距离与导数成正比,
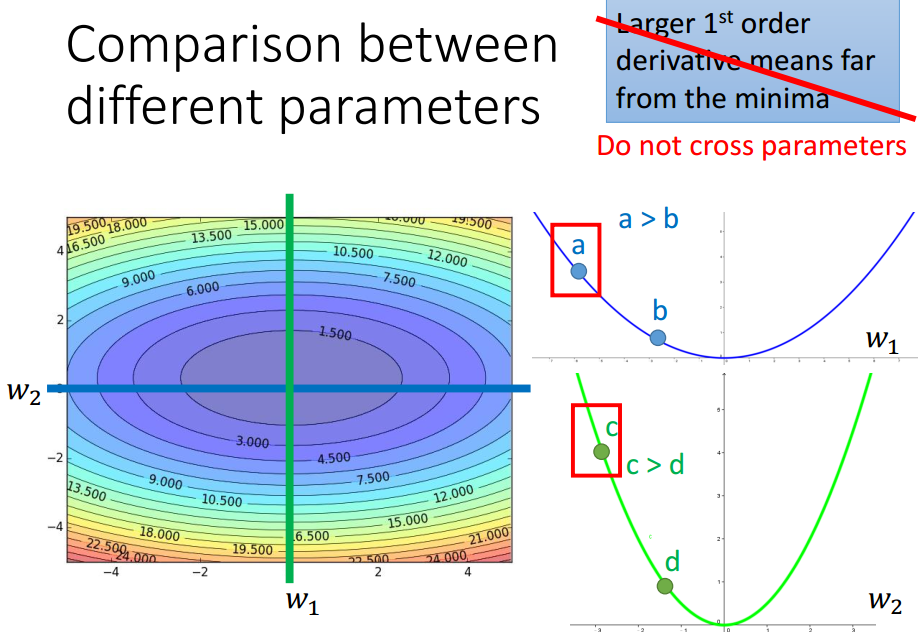
考虑多个参数时,该结论不一定成立.
还需要考虑2阶导数来反映当前位置与局部最小值点的距离.
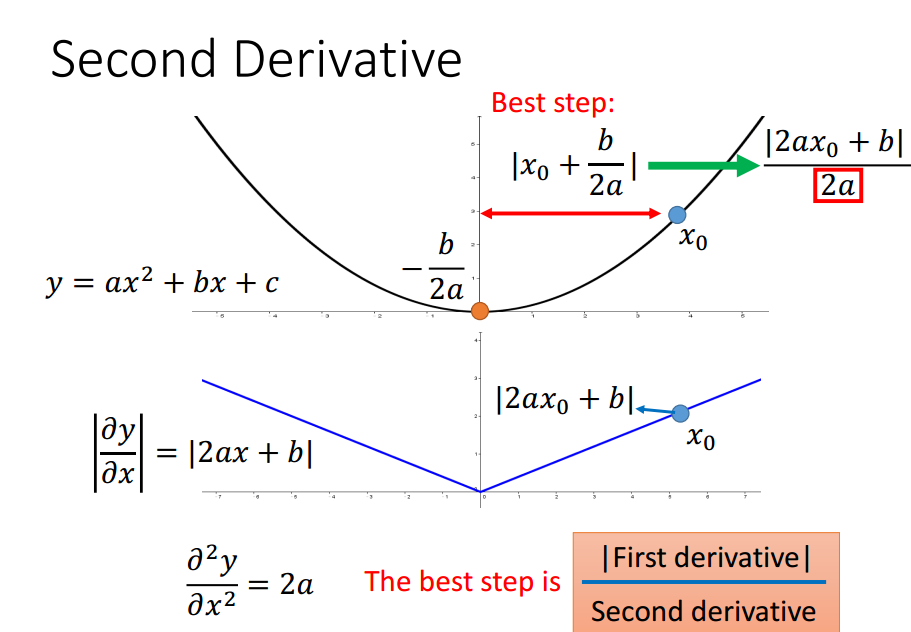

Adagrad的分母计算近似了2阶导数的计算.
没有增加额外的花费来估计2阶导数.
Tip 2: Stochastic Gradient Descent
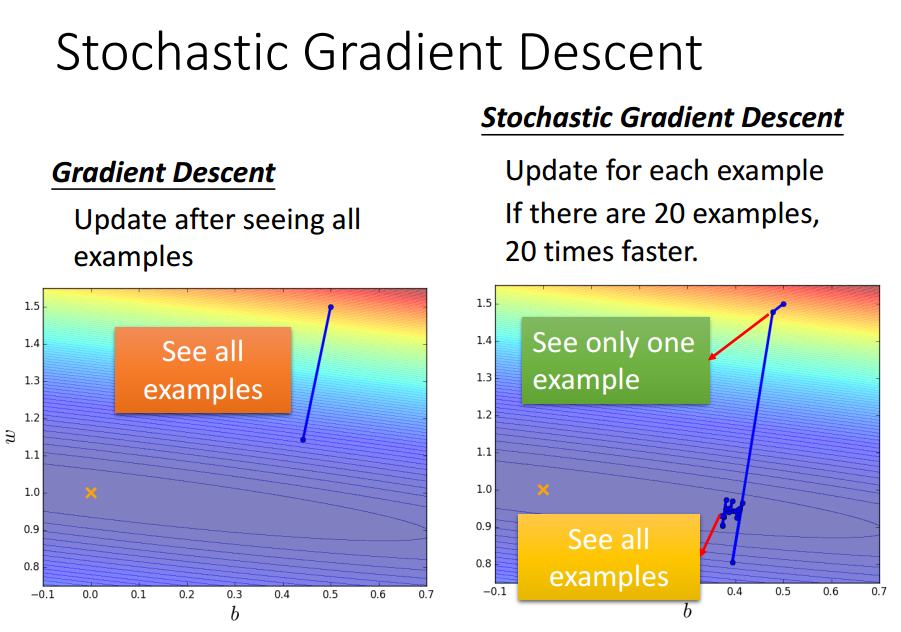
梯度下降一次使用所有训练数据,
随机梯度下降一次使用单个训练数据.

SGD可能步伐小和散乱,但走得更快.
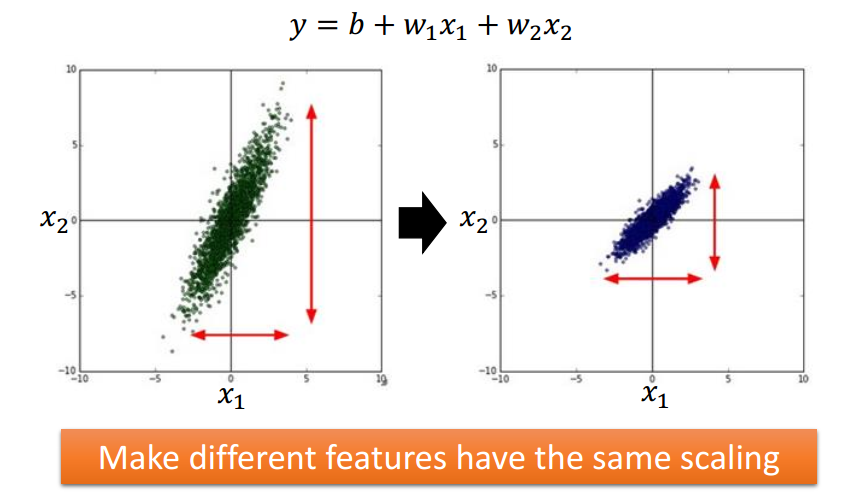
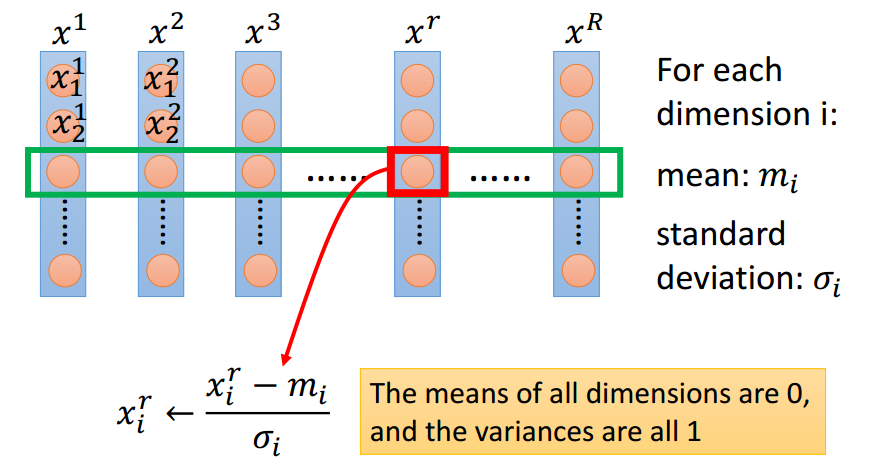
Tip 3: Feature Scaling
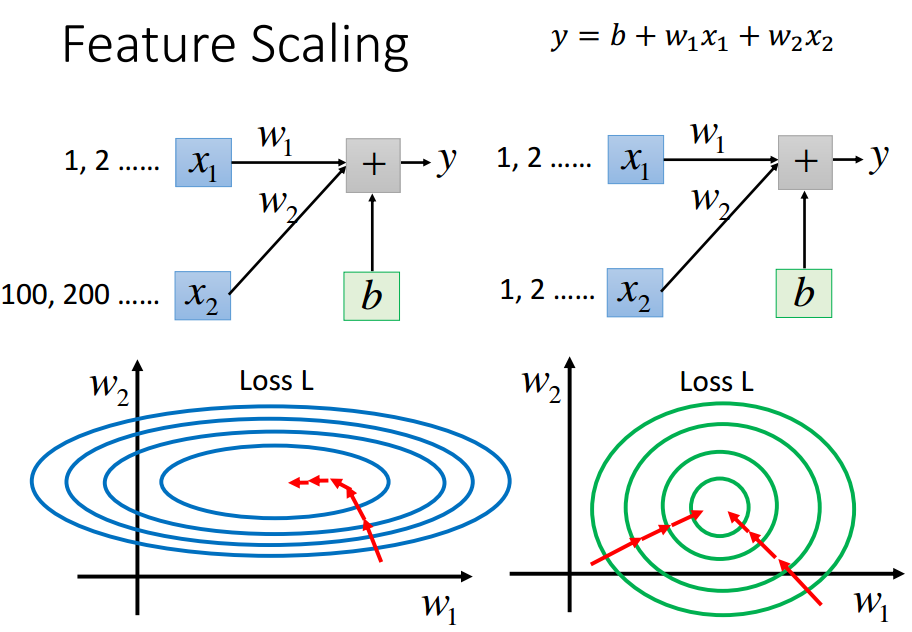
w1变化,y变化小;---w1对loss影响小
w2变化,y变化大.---w2对loss影响大
一般来说,椭圆形中不同方向的eta需求不一样,需要Ada梯度下降;
圆形中更新次数较少,因为无论椭圆形还是圆形,更新时都是沿着等高线的法线方向,
而圆形直接向着圆心走.
通过将特征归一化(均值0,方差1)实现特征缩放.
Theory
问题:

答案当然是不正确.
正式推导梯度下降能到达局部最小值点.
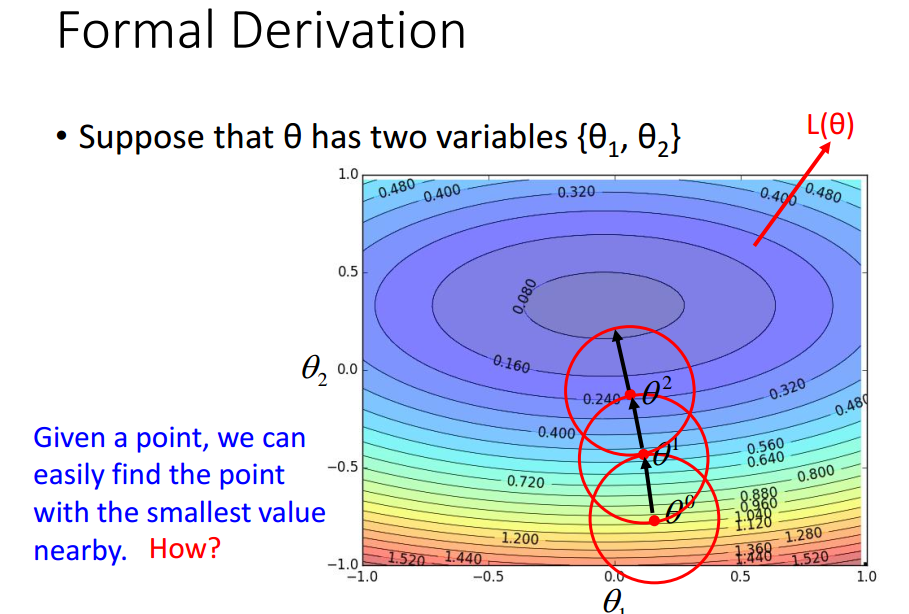


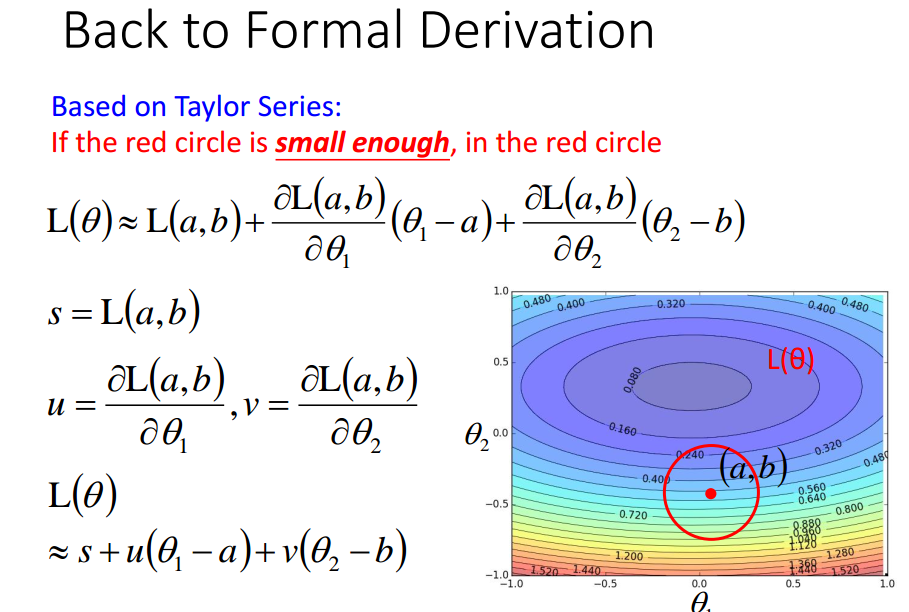
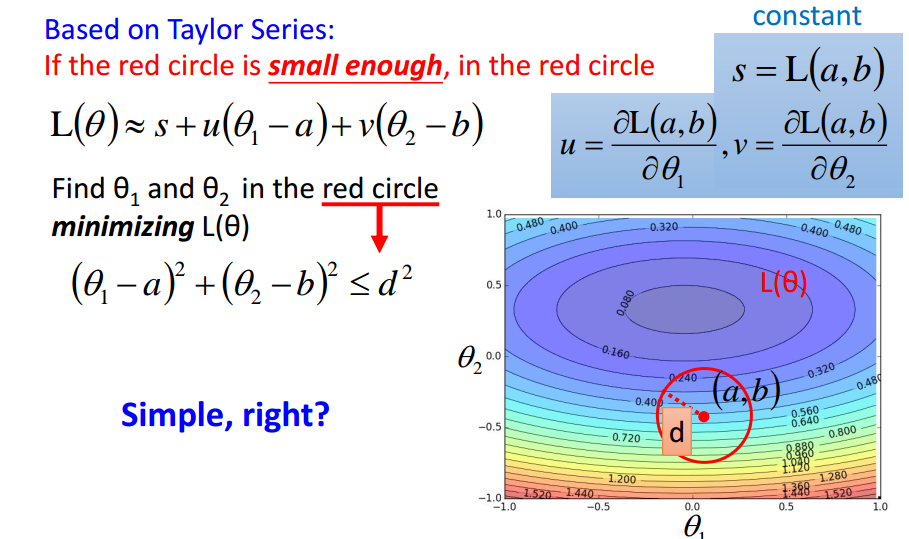

注意:
eta与红色半径成正比,
理论上,eta要充分小才能保证能到达局部最优值点,
实际上,eta只要小就行.
考虑泰勒二阶式的话,理论上eta值可以设得大点.---这种方式在deep learning中不见得那么普及
因为考虑二阶式会多出很多运算,deep learning中认为这样不划算.

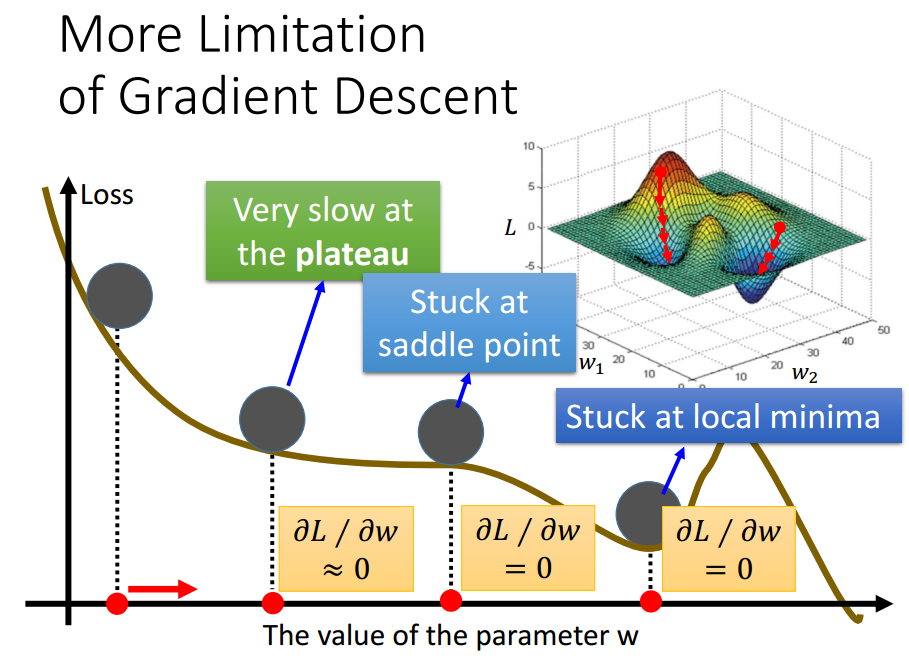
Limitation
实际操作中,很少情况下导数会exactly为0.
所以,真正问题是,该点实际在高原处,但导数小于阈值,
停下,但此时离局部最优值点还很远.
ML笔记:Gradient Descent的更多相关文章
- 李宏毅机器学习笔记2:Gradient Descent(附带详细的原理推导过程)
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- [机器学习] ML重要概念:梯度(Gradient)与梯度下降法(Gradient Descent)
引言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等,主要学习资料来自网上的免费课程和一些经典书籍,免费课 ...
- 机器学习笔记:Gradient Descent
机器学习笔记:Gradient Descent http://www.cnblogs.com/uchihaitachi/archive/2012/08/16/2642720.html
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 深度学习课程笔记(四)Gradient Descent 梯度下降算法
深度学习课程笔记(四)Gradient Descent 梯度下降算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- ML:梯度下降(Gradient Descent)
现在我们有了假设函数和评价假设准确性的方法,现在我们需要确定假设函数中的参数了,这就是梯度下降(gradient descent)的用武之地. 梯度下降算法 不断重复以下步骤,直到收敛(repeat ...
- # ML学习小笔记—Gradien Descent
关于本课程的相关资料http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17.html 根据前面所为,当我们得到Loss方程的时候,我们希望求得最优的Loss方 ...
- 【笔记】机器学习 - 李宏毅 - 4 - Gradient Descent
梯度下降 Gradient Descent 梯度下降是一种迭代法(与最小二乘法不同),目标是解决最优化问题:\({\theta}^* = arg min_{\theta} L({\theta})\), ...
随机推荐
- Keras学习环境配置-GPU加速版(Ubuntu 16.04 + CUDA8.0 + cuDNN6.0 + Tensorflow)
本文是个人对Keras深度学习框架配置的总结,不周之处请指出,谢谢! 1. 首先,我们需要安装Ubuntu操作系统(Windows下也行),这里使用Ubuntu16.04版本: 2. 安装好Ubunt ...
- C++运算符重载(10)
编译器在默认情况下为每个类生成一个默认的赋值操作,用于同类的两个对象之间相互赋值.默认的含义是逐个为成员赋值,即将一个对象的成员的值赋给另一个对象相应的成员,这种赋值方式对于有些类可能是不正确的. 运 ...
- Linux系列教程(七)——Linux帮助和用户管理命令
上篇博客我们介绍了Linux文件搜索命令,其中find是用的最多的也是功能最强大的文件或目录搜索命令,和另一个搜索命令locate的区别是,find命令是全盘搜索,刚创建的文件也能搜索的到,而loca ...
- (function($){...})(jQuery)和$(document).ready(function(){}) 的区别
(function($){...})(jQuery) 实际上是执行()(para)匿名函数,只不过是传递了jQuery对象. 立即执行函数:相当于先申明一个函数,声明完后直接调用: 用于存放开发 ...
- 用C写的计算运行时间
#include <stdio.h> #include <stdlib.h> #include <time.h> int main( void ) { long i ...
- 版本控制之一:SVN服务器搭建与安装(转)
Subversion是优秀的版本控制工具,其具体的的优点和详细介绍,这里就不再多说. 首先来下载和搭建SVN服务器. 现在Subversion已经迁移到apache网站上了,下载地址: http:// ...
- Winsock网络编程笔记(2)----基于TCP的server和client
今天抽空看了一些简单的东西,主要是对服务器server和客户端client的简单实现. 面向连接的server和client,其工作流程如下图所示: 服务器和客户端将按照这个流程就行开发..(个人觉得 ...
- HDU 4325 Flowers(树状数组)
Flowers Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Sub ...
- awk详解 数组
第1章 awk命令基础 1.1 awk命令执行过程 1.如果BEGIN 区块存在,awk执行它指定的动作. 2.awk从输入文件中读取一行,称为一条输入记录.如果输入文件省略,将从标准输入读取 3.a ...
- zookeeper详解
ZooKeeper 1.Zookeeper(***必须掌握***) 官方网址:http://zookeeper.apache.org/ Ø 什么是Zookeeper? l Zookeeper 是 G ...