Spark实战--搭建我们的Spark分布式架构
Spark的分布式架构
如我们所知,spark之所以强大,除了强大的数据处理功能,另一个优势就在于良好的分布式架构。举一个例子在Spark实战--寻找5亿次访问中,访问次数最多的人中,我用四个spark节点去尝试寻找5亿次访问中,次数最频繁的ID。这一个过程耗时竟然超过40分钟,对一个程序来说,40分钟出结果这简直就是难以忍耐。但是在大数据处理中,这又是理所当然的。当然实际中不可能允许自己的程序在简单的仅处理五亿次访问中耗费如此之大的时间,因此考虑了分布式架构。(PS:当然处理5亿次请求的示例中,我们实际采用的其实是四个节点,三台机子的伪分布式架构)
分布式架构的优势
还是以上面Spark实战--寻找5亿次访问中,访问次数最多的人作为例子,如果我们四个节点(实际上三台机子)处理了四十分钟,如果我们用一千个相同配置的节点上,理论上这个时间会缩短到2.4分钟。如果我们再增加节点的性能,比如内存、CPU性能、核数等这个理论值会缩短到更小的值。但是,实际上这个理论值永远达不到,这一点显而易见,因为spark调度、分配、网络等时间消耗,因此这个值会比2.4分钟大一些。但是相较于47分钟,这个值已经非常令人满意了。为了达到spark的性能,我们常常会对其进行调优,这是后话了。
从零开始搭建我们的Spark平台
1、准备centeros环境
为了搭建一个真正的的集群环境,并且要做到高可用的架构,我们至少准备三个虚拟机来作为集群节点。因此我购买了三台阿里云的服务器,来作为我们的集群节点。
| Hostname | IP | 内存 | CPU |
|---|---|---|---|
| master | 172.19.101.111 | 4G | 1核 |
| slave1 | 172.19.77.91 | 4G | 1核 |
| slave2 | 172.19.131.1 | 4G | 1核 |
注意到,master是主节点,而slave顾名思义就是奴隶,自然就是为主节点工作的节点。实际上,在我们这个集群中,master和slave并没有那么明确的区分,因为事实上他们都在“努力地工作”。当然在搭建集群的时候,我们依然要明确这个概念。
2、下载jdk
- 1、下载jdk1.8 tar.gz包
wget https://download.oracle.com/otn-pub/java/jdk/8u201-b09/42970487e3af4f5aa5bca3f542482c60/jdk-8u201-linux-x64.tar.gz
- 2、解压
tar -zxvf jdk-8u201-linux-x64.tar.gz
解压之后得到
- 3、配置环境变量
修改profile
vi /etc/profile
添加如下
export JAVA_HOME=/usr/local/java1.8/jdk1.8.0_201
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source使其生效
source /etc/profile
查看是否生效
java -version
看到如图内容表示已经成功。
以上操作三台虚拟机一模一样!
以上操作三台虚拟机一模一样!
以上操作三台虚拟机一模一样!
3、安装zookeeper
- 下载zookeeper包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
- 解压
tar -zxvf zookeeper-3.4.13.tar.gz
- 进入zookeeper配置目录
cd zookeeper-3.4.13/conf
- 拷贝配置文件模板
cp zoo_sample.cfg zoo.cfg
- 拷贝后修改zoo.cfg内容
dataDir=/home/hadoop/data/zkdata
dataLogDir=/home/hadoop/log/zklog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
- 配置环境变量
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.13
export PATH=$PATH:$ZOOKEEPER_HOME/bin
- 使环境变量生效
source /etc/profile
- 注意到前面配置文件中这句话,配置了数据目录
dataDir=/home/hadoop/data/zkdata
- 我们手动创建该目录,并且进入到其中
cd /home/hadoop/data/zkdata/
echo 3 > myid
- 这里需要特别注意这个
echo 1 > myid
- 这是对于这个配置,因此在master中我们echo 1,而对于slave1则是 echo 2,对于slave2则是 echo 3
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
- 配置完启动测试
zkServer.sh start
- 启动后查看是否启动成功
zkServer.sh status
以上操作三台虚拟机都要进行!只有echo 不一样
以上操作三台虚拟机都要进行!只有echo 不一样
以上操作三台虚拟机都要进行!只有echo 不一样
- 在master中启动后查看状态
- 在salve1中启动后查看状态
这里面的Mode是不一样的,这是zookeeper的选举机制,至于该机制如何运行,这里按下不表。后续会有专门说明。 至此,zookeeper集群已经搭建完成
4、安装hadoop
- 1、通过wget下载hadoop-2.7.7.tar.gz
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
- 2、下载后解压
解压出一个hadoop-2.7.7目录
tar -zxvf hadoop-2.7.7
- 3、配置hadoop环境变量
修改profile
vi /etc/profile
- 增加hadoop环境变量
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
- 使环境变量生效
source /etc/profile
- 配置完之后,查看是否生效
hadoop version
进入hadoop-2.7.7/etc/hadoop中
编辑core-site.xml
vi core-site.xml
- 增加configuration
<configuration>
<!-- 指定hdfs的nameservice为myha01 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myha01/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata/</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
<description>ms</description>
</property>
</configuration>
- 拷贝mapred-site.xml.template
cp mapred-site.xml.template mapred-site.xml
- 编辑mapred-site.xml
vi mapred-site.xml
- 增加如下内容
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定mapreduce jobhistory地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 任务历史服务器的web地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
- 编辑hdfs-site.xml
vi hdfs-site.xml
- 增加如下内容
<configuration>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 配置namenode和datanode的工作目录-数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoopdata/dfs/data</value>
</property>
<!-- 启用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定hdfs的nameservice为myha01,需要和core-site.xml中的保持一致
dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。
配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
例如,如果使用"myha01"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符
-->
<property>
<name>dfs.nameservices</name>
<value>myha01</value>
</property>
<!-- myha01下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.myha01</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn1</name>
<value>master:9000</value>
</property>
- 编辑yarn-site.xml
vi yarn-site.xml
- 增加如下内容
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave2</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
- 最后编辑salves
master
slave1
slave2
以上操作三台虚拟机一模一样!
以上操作三台虚拟机一模一样!
以上操作三台虚拟机一模一样!
接着就可以启动hadoop
首先在三个节点上启动journalnode,切记三个节点都要操作
hadoop-daemon.sh start journalnode
- 操作完成后用jps命令查看,可以看到
其中QuorumPeerMain是zookeeper,JournalNode则是我启动的内容
接着对主节点的namenode进行格式化
hadoop namenode -format
注意标红色方框的地方
完成格式化后查看/home/hadoop/data/hadoopdata目录下的内容
- 目录中的内容拷贝到slave1上,slave1是我们的备用节点,我们需要他来支撑高可用模式,当master宕机的时候,slave1马上能够顶替其继续工作。
cd..
scp -r hadoopdata/ root@slave1:hadoopdata/
- 这样就确保了主备节点都保持一样的格式化内容
接着就可以启动hadoop
- 首先在master节点启动HDFS
start-dfs.sh
- 接着启动start-yarn.sh ,注意start-yarn.sh需要在slave2中启动
start-yarn.sh
- 分别用jps查看三个主机
master
slave1
slave2
- 这里注意到master和slave1都有namenode,实际上只有一个是active状态的,另一个则是standby状态。如何证实呢,我们 在浏览器中输入master:50700,可以访问
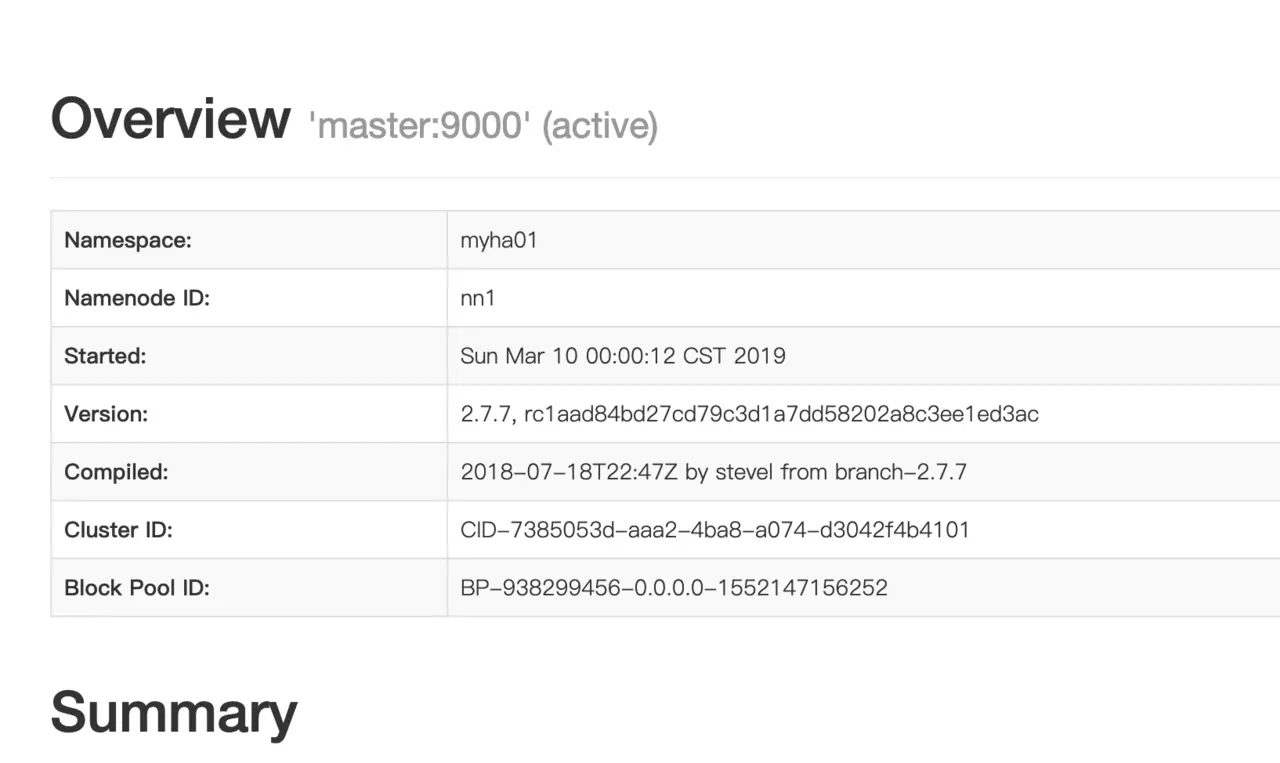
- 在浏览器中输入slave1:50700,可以访问
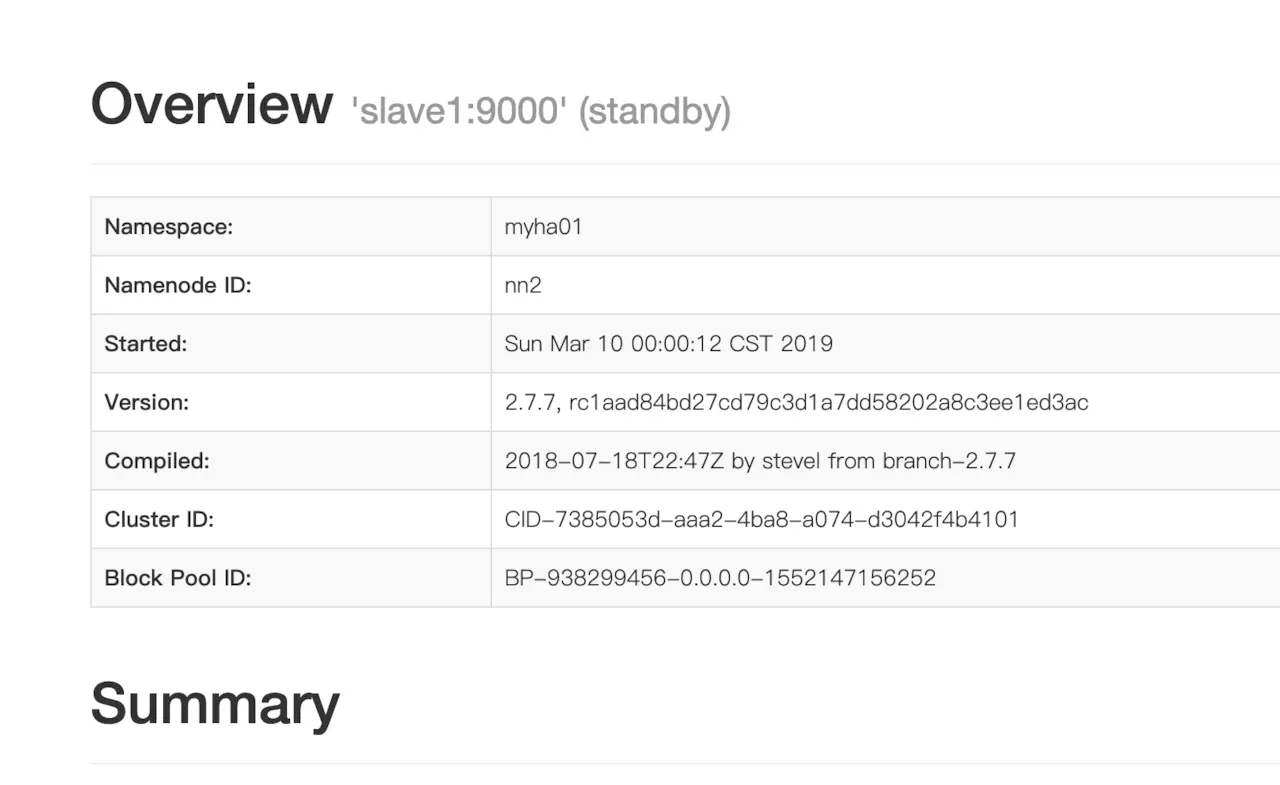
- 另一种方式,是查看我们配置的两个节点
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
5、spark安装
- 下载spark
wget http://mirrors.shu.edu.cn/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
- 解压
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
- 进入spark的配置目录
cd spark-2.4.0-bin-hadoop2.7/conf
- 拷贝配置文件spark-env.sh.template
cp spark-env.sh.template spark-env.sh
编辑spark-env.sh
vi spark-env.sh
- 增加内容
export JAVA_HOME=/usr/local/java1.8/jdk1.8.0_201
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.7.7/etc/hadoop
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/spark"
export SPARK_WORKER_MEMORY=300m
export SPARK_WORKER_CORES=1
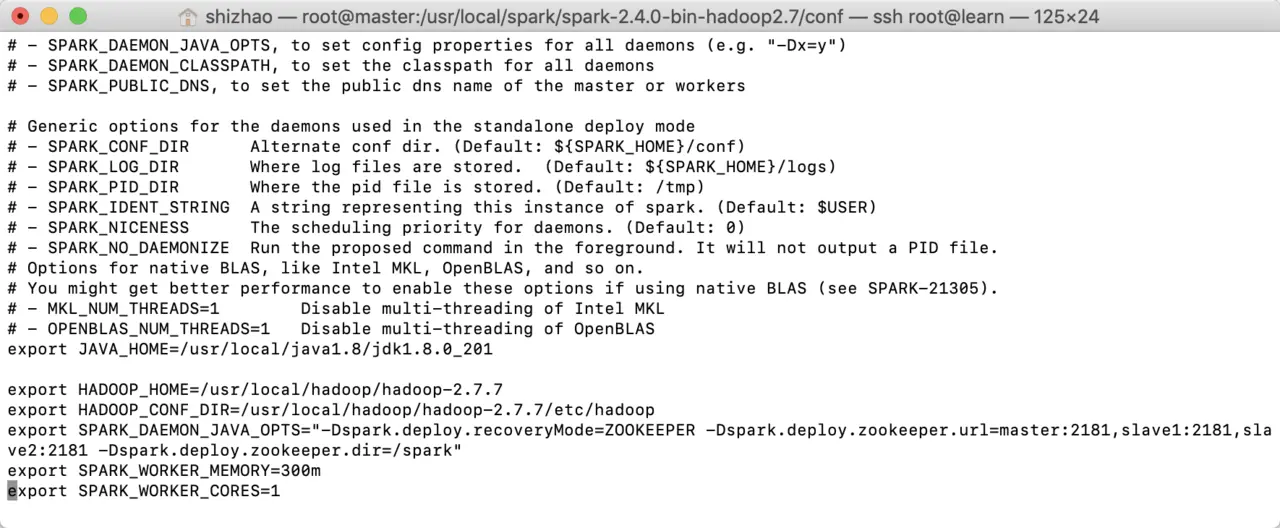
其中java的环境变量、hadoop环境变量请从系统环境变量中拷贝,后面SPARK_WORKER_MEMORY是spark运行的内存,SPARK_WORKER_CORES是spark使用的CPU核数
以上操作三台虚拟机一模一样!
以上操作三台虚拟机一模一样!
以上操作三台虚拟机一模一样!
- 配置系统环境变量
vi /etc/profile
- 增加内容
export SPARK_HOME=/usr/local/spark/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
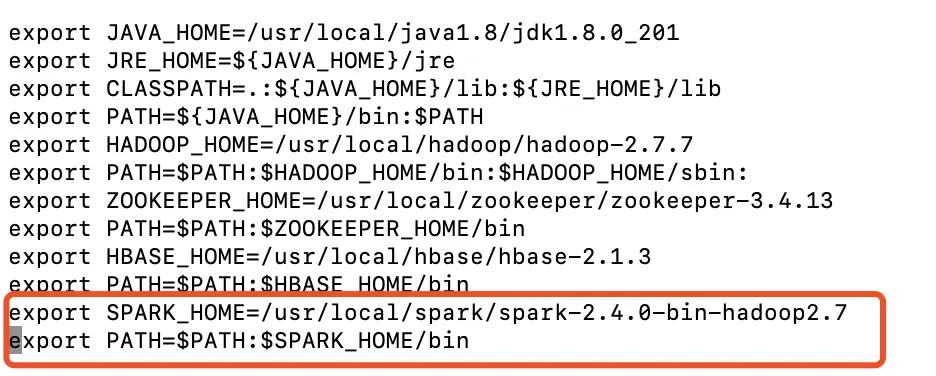
- 拷贝slaves.template 文件
cp slaves.template slaves
- 使环境变量生效
source /etc/profile
- 编辑slaves
vi slaves
- 增加内容
master
slave1
slave2

最后我们启动spark,注意即便配置了spark的环境变量,由于start-all.sh和hadoop的start-all.sh冲突,因此我们必须进入到spark的启动目录下,才能执行启动所有的操作。
进入启动目录
cd spark-2.4.0-bin-hadoop2.7/sbin
- 执行启动
./start-all.sh

执行完成后,用jps查看三个节点下的状态
master:
- slave1:
- slave2:
注意到三个节点都有了spark的worker进程,只有master当中有Master进程。
访问master:8080
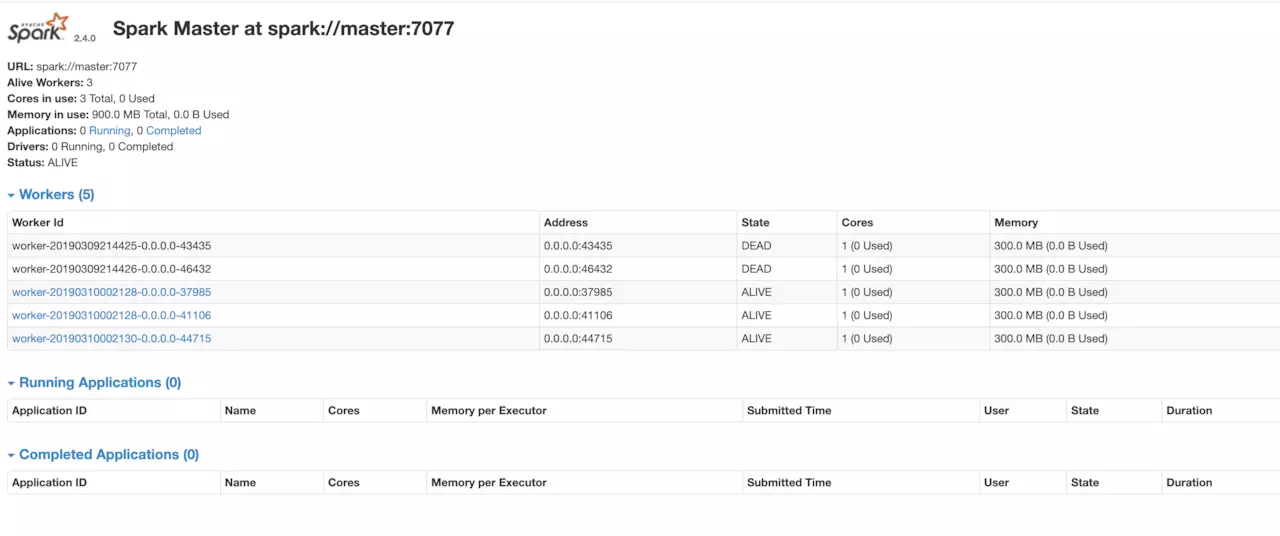
至此我们就拥有了正式的spark环境。
6、尝试使用
由于我们已经配置了环境变量,故可以输入spark-shell直接开始。
spark-shell
这里我们就进入了spark-shell.
然后进行编码
val lise = List(1,2,3,4,5)
val data = sc.parallelize(lise)
data.foreach(println)
`
或者我们进入spark-python
pyspark
查看sparkContext
Spark实战--搭建我们的Spark分布式架构的更多相关文章
- [原创].NET 分布式架构开发实战之一 故事起源
原文:[原创].NET 分布式架构开发实战之一 故事起源 .NET 分布式架构开发实战之一 故事起源 前言:本系列文章主要讲述一个实实在在的项目开发的过程,主要包含:提出问题,解决问题,架构设计和各个 ...
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- Spark(二)CentOS7.5搭建Spark2.3.1分布式集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
- Java 18套JAVA企业级大型项目实战分布式架构高并发高可用微服务电商项目实战架构
Java 开发环境:idea https://www.jianshu.com/p/7a824fea1ce7 从无到有构建大型电商微服务架构三个阶段SpringBoot+SpringCloud+Solr ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- Spark入门(1-2)Spark的特点、生态系统和技术架构
一.Spark的特点 Spark特性 Spark通过在数据处理过程中成本更低的洗牌(Shuffle)方式,将MapReduce提升到一个更高的层次.利用内存数据存储和接近实时的处理能力,Spark比其 ...
- Spark实战1
1. RDD-(Resilient Distributed Dataset)弹性分布式数据集 Spark以RDD为核心概念开发的,它的运行也是以RDD为中心.有两种RDD:第一种是并行Col ...
- Spark学习笔记5:Spark集群架构
Spark的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展计算能力.Spark可以在各种各样的集群管理器(Hadoop YARN , Apache Mesos , 还有Spark自带的独立 ...
随机推荐
- JavaScript学习总结(一)基础部分
转自:http://segmentfault.com/a/1190000000652749 基本概念 javascript是一门解释型的语言,浏览器充当解释器. js执行引擎并不是一行一行的执行,而是 ...
- 吴裕雄--天生自然HTML学习笔记:HTML 标题
在 HTML 文档中,标题很重要. HTML 标题 标题(Heading)是通过 <h1> - <h6> 标签进行定义的. <h1> 定义最大的标题. <h6 ...
- 基于Jquery的textarea滚动条插件(原创)
之前项目中自己写的滚动条插件.先前太忙没有好好整理.现在项目间歇期拿出来整理后贴出来 Demo Here css 我是把mCustomScrollbar 的UI 扣下来的. 这里我要介绍下这个插件不错 ...
- C\C++ 位域操作
几篇较全面的位域相关的文章: http://www.uplook.cn/blog/9/93362/ C/C++位域(Bit-fields)之我见 C中的位域与大小端问题 内存对齐全攻略–涉及位域的内存 ...
- linux系统加固方案
Linux主机操作系统加固规范 目 录 第1章 概述... 1 1.1 目的... 1 1.2 适用范围... 1 1.3 适用版本... 1 1 ...
- Python拾遗(2)
包括Python中的常用数据类型. int 在64位平台上,int类型是64位整数: 从堆上按需申请名为PyIntBlcok的缓存区域存储整数对象 使用固定数组缓存[-5, 257]之间的小数字,只需 ...
- Ceph块设备
Ceph块设备 来自这里. 块是一个字节序列(例如,一个512字节的数据块).基于块的存储接口是最常见的存储数据的方法,它通常基于旋转介质,像硬盘.CD.软盘,甚至传统的9道磁带. 基本的块设备命令 ...
- 解密JDK8 枚举
写一个枚举类 1 2 3 4 5 6 public enum Season { SPRING, SUMMER, AUTUMN, WINTER } 然后我们使用javac编译上面的类,得到class文件 ...
- water
webchacking.kr 第5题 打开题目发现了两个按钮,分别是Login和join 打开Login发现url是http://webhacking.kr/challenge/web/web-05/ ...
- JavaScript中如何给按钮设置隐藏与显示属性
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.html * 作者:常轩 * 微信公众号:Worldh ...