中阶 d04.1 xml解析
##XML 解析 > 其实就是获取元素里面的字符数据或者属性数据。 ###XML解析方式(面试常问) > 有很多种,但是常用的有两种。 * DOM * SAX 
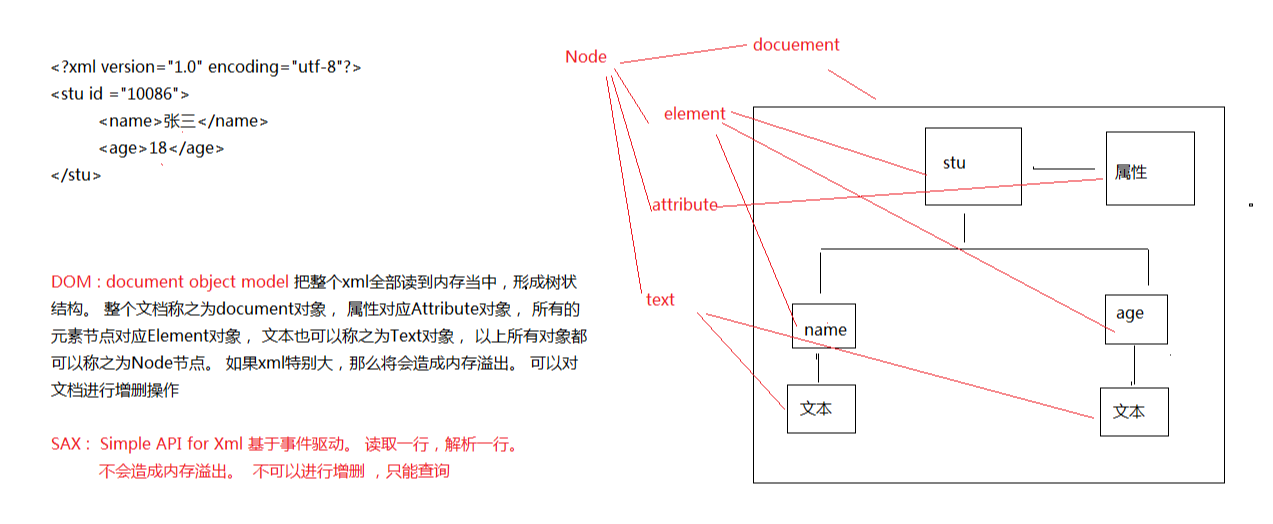
###针对这两种解析方式的API
> 一些组织或者公司, 针对以上两种解析方式, 给出的解决方案有哪些?
jaxp sun公司。 比较繁琐
jdom
dom4j 使用比较广泛
###Dom4j 基本用法
element.element("stu") : 返回该元素下的第一个stu元素
element.elements(); 返回该元素下的所有子元素。
1. 创建SaxReader对象(需要添加dom4j-1.6.1.jar)
2. 指定解析的xml
3. 获取根元素。
4. 根据根元素获取子元素或者下面的子孙元素
try {
//1. 创建sax读取对象
SAXReader reader = new SAXReader(); //jdbc -- classloader
//2. 指定解析的xml源
Document document = reader.read(new File("src/xml/stus.xml"));
//3. 得到元素、
//得到根元素
Element rootElement= document.getRootElement();
//获取根元素下面的子元素 age
//rootElement.element("age")
//System.out.println(rootElement.element("stu").element("age").getText());
//获取根元素下面的所有子元素 。 stu元素
List<Element> elements = rootElement.elements();
//遍历所有的stu元素
for (Element element : elements) {
//获取stu元素下面的name元素
String name = element.element("name").getText();
String age = element.element("age").getText();
String address = element.element("address").getText();
System.out.println("name="+name+"==age+"+age+"==address="+address);
}
} catch (Exception e) {
e.printStackTrace();
}
###Dom4j 的 Xpath使用
> dom4j里面支持Xpath的写法。 xpath其实是xml的路径语言,支持我们在解析xml的时候,能够快速的定位到具体的某一个元素。
1. 添加jar包依赖
jaxen-1.1-beta-6.jar
2. 在查找指定节点的时候,根据XPath语法规则来查找
3. 后续的代码与以前的解析代码一样。
//要想使用Xpath, 还得添加支持的jar 获取的是第一个 只返回一个。
Element nameElement = (Element) rootElement.selectSingleNode("//name");
System.out.println(nameElement.getText());
System.out.println("----------------");
//获取文档里面的所有name元素
List<Element> list = rootElement.selectNodes("//name");
for (Element element : list) {
System.out.println(element.getText());
}
##XML 约束【了解】
如下的文档, 属性的ID值是一样的。 这在生活中是不可能出现的。 并且第二个学生的姓名有好几个。 一般也很少。那么怎么规定ID的值唯一, 或者是元素只能出现一次,不能出现多次? 甚至是规定里面只能出现具体的元素名字。
<stus>
<stu id="10086">
<name>张三</name>
<age>18</age>
<address>深圳</address>
</stu>
<stu id="10086">
<name>李四</name>
<name>李五</name>
<name>李六</name>
<age>28</age>
<address>北京</address>
</stu>
</stus>
###DTD
语法自成一派, 早起就出现的。 可读性比较差。
1. 引入网络上的DTD
<!-- 引入dtd 来约束这个xml -->
<!-- 文档类型 根标签名字 网络上的dtd dtd的名称 dtd的路径
<!DOCTYPE stus PUBLIC "//UNKNOWN/" "unknown.dtd"> -->
2. 引入本地的DTD
<!-- 引入本地的DTD : 根标签名字 引入本地的DTD dtd的位置 -->
<!-- <!DOCTYPE stus SYSTEM "stus.dtd"> -->
2. 直接在XML里面嵌入DTD的约束规则
<!-- xml文档里面直接嵌入DTD的约束法则 -->
<!DOCTYPE stus [
<!ELEMENT stus (stu)>
<!ELEMENT stu (name,age)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
]>
<stus>
<stu>
<name>张三</name>
<age>18</age>
</stu>
</stus>
<!ELEMENT stus (stu)> : stus 下面有一个元素 stu , 但是只有一个
<!ELEMENT stu (name , age)> stu下面有两个元素 name ,age 顺序必须name-age
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ATTLIST stu id CDATA #IMPLIED> stu有一个属性 文本类型, 该属性可有可无
元素的个数:
+ 一个或多个
* 零个或多个
? 零个或一个
属性的类型定义
CDATA : 属性是普通文字
ID : 属性的值必须唯一
<!ELEMENT stu (name , age)> 按照顺序来
<!ELEMENT stu (name | age)> 两个中只能包含一个子元素
###Schema
其实就是一个xml , 使用xml的语法规则, xml解析器解析起来比较方便 , 是为了替代DTD 。
但是Schema 约束文本内容比DTD的内容还要多。 所以目前也没有真正意义上的替代DTD
约束文档:
<!-- xmlns : xml namespace : 名称空间 / 命名空间
targetNamespace : 目标名称空间 。 下面定义的那些元素都与这个名称空间绑定上。
elementFormDefault : 元素的格式化情况。 -->
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itheima.com/teacher"
elementFormDefault="qualified">
<element name="teachers">
<complexType>
<sequence maxOccurs="unbounded">
<!-- 这是一个复杂元素 -->
<element name="teacher">
<complexType>
<sequence>
<!-- 以下两个是简单元素 -->
<element name="name" type="string"></element>
<element name="age" type="int"></element>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
实例文档:
<?xml version="1.0" encoding="UTF-8"?>
<!-- xmlns:xsi : 这里必须是这样的写法,也就是这个值已经固定了。
xmlns : 这里是名称空间,也固定了,写的是schema里面的顶部目标名称空间
xsi:schemaLocation : 有两段: 前半段是名称空间,也是目标空间的值 , 后面是约束文档的路径。
-->
<teachers
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itheima.com/teacher"
xsi:schemaLocation="http://www.itheima.com/teacher teacher.xsd"
>
<teacher>
<name>zhangsan</name>
<age>19</age>
</teacher>
<teacher>
<name>lisi</name>
<age>29</age>
</teacher>
<teacher>
<name>lisi</name>
<age>29</age>
</teacher>
</teachers>
##名称空间的作用
一个xml如果想指定它的约束规则, 假设使用的是DTD ,那么这个xml只能指定一个DTD , 不能指定多个DTD 。 但是如果一个xml的约束是定义在schema里面,并且是多个schema,那么是可以的。简单的说: 一个xml 可以引用多个schema约束。 但是只能引用一个DTD约束。
名称空间的作用就是在 写元素的时候,可以指定该元素使用的是哪一套约束规则。 默认情况下 ,如果只有一套规则,那么都可以这么写
<name>张三</name>
<aa:name></aa:name>
<bb:name></bb:name>
xml文件

dom4j用法代码示例(获取元数要多层element)
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader; import java.io.File;
import java.util.List; public class dom4j_demo {
public static void main(String[] args) {
try {
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("D:\\java\\java_workspace\\9_xml\\src\\sutdents.xml")); //得到根元素
Element element = document.getRootElement();
//获取根元素下面的子元素 age
System.out.println(element.element("stu").element("name").getText()); //获取根元素下面的所有子元素 。 stu元素
List<Element> list = element.elements();
//遍历所有的stu元素
for (Element elm : list) {
String name = elm.element("name").getText();
String age = elm.element("age").getText();
System.out.println("name:"+name +"---"+ "age:"+age);
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
输出
xpath用法(用法 优点:根据路径直接查找/stu //name ///dsaf...)多层查找
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.dom4j.xpath.DefaultXPath; import java.io.File;
import java.util.List; public class Dom4j_xpath_demo {
public static void main(String[] args) {
try {
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("D:\\java\\java_workspace\\9_xml\\src\\sutdents.xml"));
Element rootElement = document.getRootElement(); /* //想要使用Xpath,需要添加依赖的jar:jaxen-1.1-beta-6.jar。否则会报错notfound class jaxenxxx
//Node可以理解为对象,参考parse_type.png
//向下转型使用Element接收
// "//name"用法参考xpath api:XPathTutorial.chm
Element nameelement = (Element) rootElement.selectSingleNode("//age");
System.out.println(nameelement.getText());*/ List<Element> list = rootElement.selectNodes("//name");
for(Element element1 : list) {
String name = element1.getText();
System.out.println(name);
} } catch (DocumentException e) {
e.printStackTrace();
}
}
}
输出
中阶 d04.1 xml解析的更多相关文章
- Android中的三种XML解析方式
在Android中提供了三种解析XML的方式:SAX(Simple API XML),DOM(Document Objrect Model),以及Android推荐的Pull解析方式.下面就对三种解析 ...
- 中阶 d04 xml 概念及使用
idea新建xml文件https://www.jianshu.com/p/b8aeadae39b0 或https://blog.csdn.net/Hi_Boy_/article/details/804 ...
- 在Java中使用xpath对xml解析
xpath是一门在xml文档中查找信息的语言.xpath用于在XML文档中通过元素和属性进行导航.它的返回值可能是节点,节点集合,文本,以及节点和文本的混合等.在学习本文档之前应该对XML的节点,元素 ...
- PHP中的XML解析的5种方法
[前言]不管是桌面软件开发,还是WEB应用,XML无处不在!然而在平时的工作中,仅仅是使用一些已经封装好的类对XML对于处理,包括生成,解析等.假期有空,于是将PHP中的几种XML解析方法总结如下: ...
- java基础71 XML解析中的【DOM和SAX解析工具】相关知识点(网页知识)
本文知识点(目录):本文下面的“实例及附录”全是DOM解析的相关内容 1.xml解析的含义 2.XML的解析方式 3.xml的解析工具 4.XML的解析原理 5.实例 6 ...
- 【Android】实现XML解析的几种技术
本文介绍在Android平台中实现对XML的三种解析方式. XML在各种开发中都广泛应用,Android也不例外.作为承载数据的一个重要角色,如何读写XML成为Android开发中一项重要的技能. 在 ...
- iOS-数据解析XML解析的多种平台介绍
在iPhone开发中,XML的解析有很多选择,iOS SDK提供了NSXMLParser和libxml2两个类库,另外还有很多第三方类库可选,例如TBXML.TouchXML.KissXML.Tiny ...
- IOS-JSON & XML解析
XML & JSON 简介 •JSON –作为一种轻量级的数据交换格式,正在逐步取代XML,成为网络数据的通用格式 –基于JavaScript的一个子集 –易读性略差,编码手写难度大,数据量小 ...
- iOS平台XML解析类库对比和安装说明
在iPhone开发中,XML的解析有很多选择,iOS SDK提供了NSXMLParser和libxml2两个类库,另外还有很多第三方类库可选,例如TBXML.TouchXML.KissXML.Tiny ...
随机推荐
- Map-->HashMap练习(新手)
//导入的包.import java.util.*;//创建的一个类.public class zylx1 { //公共静态的主方法. public static void main(String[] ...
- 基于 HTML5 WebGL 与 GIS 的智慧机场大数据可视化分析【转载】
前言:大数据,人工智能,工业物联网,5G 已经或者正在潜移默化地改变着我们的生活.在信息技术快速发展的时代,谁能抓住数据的核心,利用有效的方法对数据做数据挖掘和数据分析,从数据中发现趋势,谁就能做到精 ...
- Dubbo反序列化漏洞(CVE-2019-17564) 重现
1. 下载官方 demo 代码(暴出的漏洞是 http 协议的,故使用 http 的 demo 来重现)https://github.com/apache/dubbo-samples/tree/mas ...
- canvas绘制流星雨特效
源码: <!DOCTYPE html><html> <head> <meta charset="utf-8"> <meta n ...
- Spring Controller单例与线程安全那些事儿
目录 单例(siingleton)作用域 原型(Prototype)作用域 多个HTTP请求在Spring控制器内部串行还是并行执行方法? 实现单例模式并模拟大量并发请求,验证线程安全 附录:Spri ...
- hdu2203kmp匹配
拼接字符串即可解决移位的问题: 代码如下: #include<bits/stdc++.h> using namespace std; typedef unsigned int ui; ty ...
- 关于手机淘宝3.25bug我的一些思考与建议
这两天被手淘ios版3.25bug刷屏了,影响还是挺大的,仅3.25日当天截止到下午5点在微博上的话题阅读量,已经突破8000万.给广大网友带来一次吃瓜盛宴.我们先简单回顾下这个bug的故事线: 我查 ...
- [dfs] 2019牛客暑期多校训练营(第十场) Coffee Chicken
题目地址: https://ac.nowcoder.com/acm/contest/890/B 时间限制:C/C++ 1秒,其他语言2秒空间限制:C/C++ 524288K,其他语言1048576 ...
- IP协议的助手 —— ICMP 协议
IP协议的助手 —— ICMP 协议 IP协议的助手 —— ICMP 协议 ping 是基于 ICMP 协议工作的,所以要明白 ping 的工作,首先我们先来熟悉 ICMP 协议. ICMP 是什么? ...
- PyTorch专栏(二)
专栏目录: 第一章:PyTorch之简介与下载 PyTorch简介 PyTorch环境搭建 第二章:PyTorch之60min入门 PyTorch 入门 PyTorch 自动微分 PyTorch 神经 ...