使用fastai完成图像分类

1. 使用现有数据集进行分类
图像数据为Oxford-IIIT Pet Dataset(12类猫和25类狗,共37类),这里仅使用原始图片集images.tar.gz
数据准备
import numpy as npfrom fastai.vision import *from fastai.metrics import error_ratepath_img = 'data/pets/images'bs = 64 #batch sizefnames = get_image_files(path_img) #get filenames(absolute path) from path_imgpat = re.compile(r'/([^/]+)_d+.jpg$') #get labels from filenames(e.g., 'american_bulldog' from 'data/pets/images/american_bulldog_20.jpg')### ImageDataBunch### 使用正则表达式pat从图像文件名fnames中提取标签,并和图像对应起来### ds_tfms: 图像转换(翻转、旋转、裁剪、放大等),用于图像数据增强(data augmentation)### size: 最终图像尺寸, bs: batch size, valid_pct: train/valid split### normalize: 使用提供的均值和标准差(每个通道对应一个均值和标准差)对图像数据进行归一化np.random.seed(2)data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs, valid_pct=0.2).normalize(imagenet_stats)data.show_batch(rows=3, figsize=(7,6)) #grab a batch and display 3x3 images
模型搭建和训练
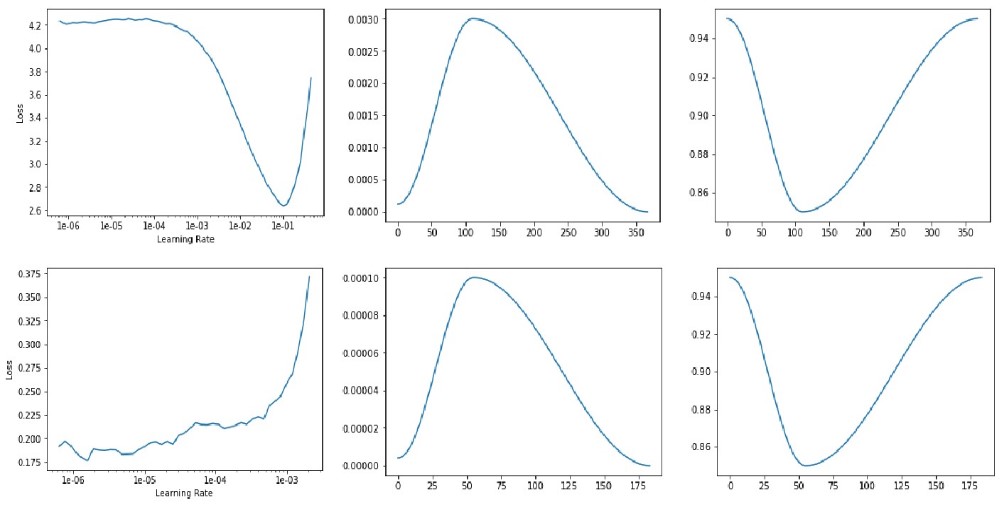
使用Resnet34进行迁移学习,首先通过lr_find确定最大学习率,再通过fit_one_cycle(1-Cycle style)进行训练
lr_find: 在前面几次的迭代中将学习率从一个很小的值逐渐增加,选择损失函数(train loss)处于下降趋势之中并且距离损失停止下降的拐点有一定距离的点做为模型的最大学习率max_lr
fit_one_cycle: 共分为两个阶段,在第一阶段学习率从max_lr/div_factor线性增长到max_lr,momentum线性地从moms[0]降到moms[1];第二阶段学习率以余弦形式从max_lr降为0,momentum也同样按余弦形式从moms[1]增长到moms[0]。第一阶段的迭代次数占总迭代次数的比例为pct_start
学习率和momentum: , , , 其中是要更新的参数,G为梯度, 为学习率, 为momentum
### Use Resnet34 to classify imageslearn = create_cnn(data, models.resnet34, metrics=error_rate)print(learn.model) #model summarylearn.lr_find()learn.recorder.plot() #由左上图可以看出max_lr可选择函数fit_one_cycle的默认值0.003learn.fit_one_cycle(4, max_lr=slice(0.003), div_factor=25.0, moms=(0.95, 0.85), pct_start=0.3) #4 epochslearn.recorder.plot_lr(show_moms=True) #中上图(学习率)和右上图(momentum), x轴表示迭代次数learn.save('stage-1') #save model### Unfreeze all the model layers and keep traininglearn.unfreeze()learn.lr_find()learn.recorder.plot() #左下图### 由左下图可以看出max_lr可选择1e-6, 但是模型的不同层可以设置不同的学习率加速训练### 模型的前面几层的学习率设置为max_lr, 后面几层的学习率可以适当增加(例如可以设置成比上一个fit_one_cycle的学习率小一个量级)### slice(1e-6,1e-4)表示模型每层的学习率由1e-6逐渐增加过渡到1e-4learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4), div_factor=25.0, moms=(0.95, 0.85), pct_start=0.3) #2 epochslearn.recorder.plot_lr(show_moms=True) #中下图(模型最后一层的学习率)和右下图(momentum)
可视化
interp = ClassificationInterpretation.from_learner(learn)interp.plot_confusion_matrix(figsize=(12,12), dpi=60) #confusion matrixprint(interp.most_confused(min_val=2)) #从大到小列出混淆矩阵中非对角线的最大的几个元素
2. 从谷歌图片下载数据并进行分类
获得图片链接
打开谷歌图片,输入想要下载的图像类别,页面上出现的图片即为可下载的图片
打开JavaScript Console(Windows/Linux:Ctrl+Shift+J, Mac:Cmd+Opt+J),运行下面的命令获取图片链接
大专栏 使用fastai完成图像分类 class="nx">urls = Array.from(document.querySelectorAll('.rg_di .rg_meta')).map(el=>JSON.parse(el.textContent).ou);window.open('data:text/csv;charset=utf-8,' + escape(urls.join('n')));
分别搜索teddy bears、 black bears、 grizzly bears, 将下载的保存链接的文件分别命名为urls_teddys.txt、 urls_black.txt、 urls_grizzly.txt
下载图片
import numpy as npfrom fastai.vision import *from fastai.metrics import error_rate### 建立目录并下载图片path = Path('data/bears')folders = ['teddys', 'black', 'grizzly']files = 'urls_teddys.txt', 'urls_black.txt', 'urls_grizzly.txt'for i,folder in enumerate(folders):dest = path/folderdest.mkdir(parents=True, exist_ok=True)download_images(files[i], dest, max_pics=200)print(path.ls())### 删除不能被打开的图片for folder in folders:verify_images(path/folder, delete=True, max_size=500)
训练模型
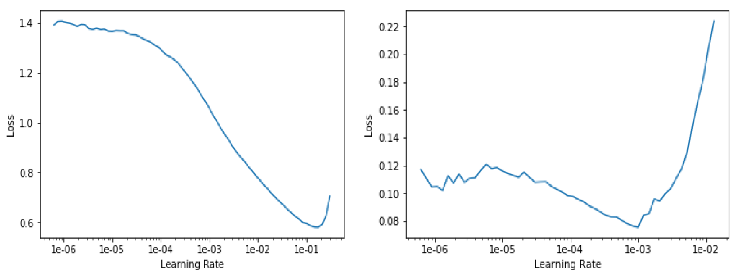
np.random.seed(42)data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2, ds_tfms=get_transforms(), size=224, bs=64, num_workers=4).normalize(imagenet_stats)print(data.classes)learn = create_cnn(data, models.resnet34, metrics=error_rate)learn.lr_find()learn.recorder.plot() #左图learn.fit_one_cycle(4)learn.save('stage-1')learn.unfreeze()learn.lr_find()learn.recorder.plot() #右图learn.fit_one_cycle(2, max_lr=slice(3e-5,3e-4)) #若数据量较小,该步不一定有正效果learn.save('stage-2')learn.load('stage-1') #选择stage-1interp = ClassificationInterpretation.from_learner(learn)interp.plot_confusion_matrix()
根据训练好的模型去除错误图片
模型预测效果不好不一定是因为模型本身的问题,还可能是由于图片自身的问题(例如下载了错误的图片,图片标签有误),需要进行检查和处理
from fastai.widgets import *### ds: 训练图片集, idxs: 具有最大损失的训练图片索引ds, idxs = DatasetFormatter().from_toplosses(learn, n_imgs=200) #选出前200个具有最大损失的训练图片ImageCleaner(ds, idxs, path) #手动处理,处理好的文件被存入path/cleaned.csv(该文件仅包含经过处理后的训练图片集,不包含验证图片)
可根据具体情况对处理之后的数据重新进行训练
保存模型并预测
learn.export() #将模型存入learn.path/export.pkllearn = load_learner(path) #从path中读取模型img = open_image(path/'black'/'00000021.jpg') #以训练集中的一个图片为例pred_class,pred_idx,outputs = learn.predict(img) #预测图片print(pred_class) #输出类别print(outputs) #输出每个类的概率
使用fastai完成图像分类的更多相关文章
- Atitit 图像处理--图像分类 模式识别 肤色检测识别原理 与attilax的实践总结
Atitit 图像处理--图像分类 模式识别 肤色检测识别原理 与attilax的实践总结 1.1. 五中滤镜的分别效果..1 1.2. 基于肤色的图片分类1 1.3. 性能提升2 1.4. --co ...
- 【转】[caffe]深度学习之图像分类模型AlexNet解读
[caffe]深度学习之图像分类模型AlexNet解读 原文地址:http://blog.csdn.net/sunbaigui/article/details/39938097 本文章已收录于: ...
- 基于Pre-Train的CNN模型的图像分类实验
基于Pre-Train的CNN模型的图像分类实验 MatConvNet工具包提供了好几个在imageNet数据库上训练好的CNN模型,可以利用这个训练好的模型提取图像的特征.本文就利用其中的 “im ...
- [caffe]深度学习之图像分类模型VGG解读
一.简单介绍 vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper.跟googlenet不同的是.vgg继承了lenet以及alexnet ...
- 如何在程序中调用Caffe做图像分类
Caffe是目前深度学习比较优秀好用的一个开源库,采样c++和CUDA实现,具有速度快,模型定义方便等优点.学习了几天过后,发现也有一个不方便的地方,就是在我的程序中调用Caffe做图像分类没有直接的 ...
- [caffe]深度学习之图像分类模型AlexNet解读
在imagenet上的图像分类challenge上Alex提出的alexnet网络结构模型赢得了2012届的冠军.要研究CNN类型DL网络模型在图像分类上的应用,就逃不开研究alexnet.这是CNN ...
- 【深度学习系列】用PaddlePaddle和Tensorflow进行图像分类
上个月发布了四篇文章,主要讲了深度学习中的"hello world"----mnist图像识别,以及卷积神经网络的原理详解,包括基本原理.自己手写CNN和paddlepaddle的 ...
- 【Keras】从两个实际任务掌握图像分类
我们一般用深度学习做图片分类的入门教材都是MNIST或者CIFAR-10,因为数据都是别人准备好的,有的甚至是一个函数就把所有数据都load进来了,所以跑起来都很简单,但是跑完了,好像自己还没掌握图片 ...
- OpenCV探索之路(二十八):Bag of Features(BoF)图像分类实践
在深度学习在图像识别任务上大放异彩之前,词袋模型Bag of Features一直是各类比赛的首选方法.首先我们先来回顾一下PASCAL VOC竞赛历年来的最好成绩来介绍物体分类算法的发展. 从上表我 ...
随机推荐
- 完整注册登陆php源码,附带session验证。
1.首先先写表单页面login.html. <!DOCTYPE html> <html lang="en"> <head> <me ...
- lvm镜像卷
镜像能够分配物理分区的多个副本,从而提高数据的可用性.当某个磁盘发生故障并且其物理分区变为不可用时,你仍然可以访问可用磁盘上的镜像数据.LVM在逻辑卷内执行镜像. 系统版本 # cat /etc/ce ...
- Chladni Figure CodeForces - 1162D (暴力,真香啊~)
Chladni Figure CodeForces - 1162D Inaka has a disc, the circumference of which is nn units. The circ ...
- Postgresql的导表
背景 前面已经介绍了常用的备份与恢复了,接下来介绍一下导表. 正文 很多情况,会有把数据导出的需求,轻重缓急总会有特别紧急的情况,但是又不是专业干db的人,还是记录下来,以防不时之需. 针对于导表,个 ...
- teminal / console / shell
console从应用程序角度看的(控制台是管理员用的,唯一的) teminal从用户角度看的(终端是用户用的) 应用程序与console交互 用户与teminal交互 teminal可以不存在 tem ...
- 获取文件MD5值(JS、JAVA)
文章HTML代码翻译于地址:https://www.cnblogs.com/linyihai/p/7040786.html 文件MD5有啥用? 文 ...
- iOS 加急审核的办法
前言:由于自己的APP在提交后,审核了大概一周左右还没有消息,而领导又不断询问情况,于是自己在网上看到了这篇文章.由于自己比较懒,所以在此记录下来,以供 大家参考. 说明:本文只是做一个记录,还望看到 ...
- POJ-1751 Highways(最小生成树消边+输出边)
http://poj.org/problem?id=1751 Description The island nation of Flatopia is perfectly flat. Unfortun ...
- ruoyi StringUtils
package com.ruoyi.common.utils; import java.util.Collection; import java.util.Map; import com.ruoyi. ...
- Perl:理解正则中“.”可匹配出回车符(“\n”)外任意字符的例子,配合 $^I 关键字
要把下面文件的内容改了, Program name: graniteAuthor: Gilbert BatesCompany: RockSoftDepartment: R&DPhone: +1 ...