Scala——的并行集合
当出现Kafka单个分区数据量很大,但每个分区的数据量很平均的情况时,我们往往采用下面两种方案增加并行度:
l 增加Kafka分区数量
l 对拉取过来的数据执行repartition
但是针对这种情况,前者的改动直接影响所有使用消费队列的模型性能,后者则存在一个shuffle的性能消耗。有没有既不会发生shuffle,又能成倍提升性能的方法呢?
/*
推荐使用Scala的并行集合:
在上述场景中存在的情况是,单核数据量很大,但是又由于分区数量限制导致多核无法分配到数据。因此如果使用foreachPartition算子,就可以获取到每个分区的数据集,对这些数据集使用多线程并行执行。
*/ //具体代码如下:
rdd.foreachPartition(datas=>{
//使用一个集合创建对应的并行集合
val seqPar = datas.toSeq.par
//为并行集合设置线程池,默认的参数是CPU的核数
seqPar.tasksupport = new ForkJoinTaskSupport(new ForkJoinPool())
//执行遍历逻辑,自动实现多线程并行
seqPar.foreach{...}
}) //经本地测试,该方法有效。但没有测试复杂的逻辑,如:多个遍历算子、Kafka场景等
如果Spark会优先为每个executor拉取数据,就可以通过设置executor num=Kafka分区数,然后为每个executor设置多个cpu core的方式实现成倍的处理速度。
经实验,Spark在拉取Kafka数据时,不管Cpu核数多少,会优先为每个executor分配一份Kafka分区,只有当总executor数量<Kafka分区时,才会分配多份数据到同一个节点上。
以下是我使用10个节点,每个节点分配4个线程拉取一个分区数量为10的Kafka时,Task的分布情况:

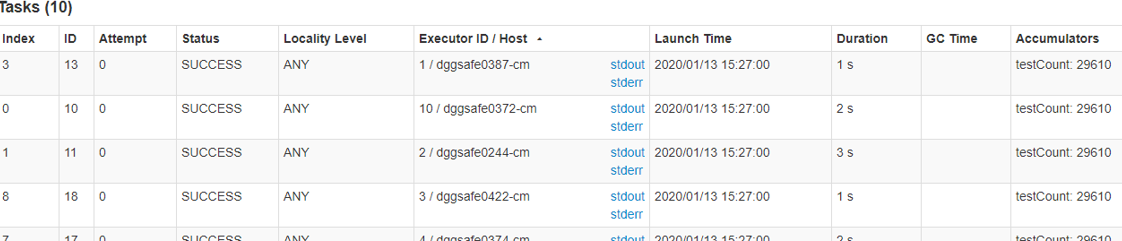
可以看到,数据被很好的分散到了十个节点上。并且在这个测试模型中,我使用了并行集合执行累加器操作。可以看到,并行集合并没有造成数据丢失,而是正常的执行了计算逻辑。
可惜从少量的数据中看不出并行集合带来的提升。此外,关于该方案是否适用于复杂逻辑和持久稳定运行,还需要后续观察。
Scala——的并行集合的更多相关文章
- scala 数据结构(十一):流 Stream、视图 View、线程安全的集合、并行集合
1 流 Stream stream是一个集合.这个集合,可以用于存放无穷多个元素,但是这无穷个元素并不会一次性生产出来,而是需要用到多大的区间,就会动态的生产,末尾元素遵循lazy规则(即:要使用结果 ...
- 大数据学习day15----第三阶段----scala03--------1.函数(“_”的使用, 函数和方法的区别)2. 数组和集合常用的方法(迭代器,并行集合) 3. 深度理解函数 4 练习(用java实现类似Scala函数式编程的功能(不能使用Lambda表达式))
1. 函数 函数就是一个非常灵活的运算逻辑,可以灵活的将函数传入方法中,前提是方法中接收的是类型一致的函数类型 函数式编程的好处:想要做什么就调用相应的方法(fliter.map.groupBy.so ...
- 11. Scala数据结构(下)-集合操作
11.1 集合元素的映射-map映射操作 11.1.1 看一个实际需求 要求:请将List(3,5,8)中所有的元素都*2,将其结果放到一个新的集合中返回,即返回一个新的List(6,10,16),请 ...
- Scala学习十三——集合
一.本章要点 所有集合都扩展自Iterable特质; 集合有三大类,分别为序列,集和映射; 对于几乎所有集合类,Scala都同时提供可变和不可变的版本; Scala列表要么是空的,要么拥有一头一尾,其 ...
- Programming In Scala笔记-第十七章、Scala中的集合类型
本章主要介绍Scala中的集合类型,主要包括:Array, ListBuffer, Arraybuffer, Set, Map和Tuple. 一.序列 序列类型的对象中包含多个按顺序排列好的元素,可以 ...
- scala的多种集合的使用(1)之集合层级结构与分类
一.在使用scala集合时有几个概念必须知道: 1.谓词是什么? 谓词就是一个方法,一个函数或者一个匿名函数,接受一个或多个函数,返回一个Boolean值. 例如:下面方法返回true或者false, ...
- C#编程(五十八)----------并行集合
并行集合 对于并行任务,与其相关紧密的就是对一些共享资源,数据结构的并行访问.经常要做的就是对一些队列进行加锁-解锁,然后执行类似插入,删除等等互斥操作. .NET4提供了一些封装好的支持并行操作数据 ...
- 9、scala函数式编程-集合操作
一.集合操作1 1.Scala的集合体系结构 // Scala中的集合体系主要包括:Iterable.Seq.Set.Map.其中Iterable是所有集合trait的根trai.这个结构与Java的 ...
- C#高级编程五十八天----并行集合
并行集合 对于并行任务,与其相关紧密的就是对一些共享资源,数据结构的并行訪问.常常要做的就是对一些队列进行加锁-解锁,然后运行类似插入,删除等等相互排斥操作. .NET4提供了一些封装好的支持并行操作 ...
随机推荐
- 作为一位Vue工程师,这些开发技巧你都会吗?
路由参数解耦 一般在组件内使用路由参数,大多数人会这样做: export default { methods: { getParamsId() { return this.$route.params. ...
- WEB应用之httpd基础入门(一)
前文我们聊了下http协议web服务的一些常识和httpd服务器软件三种响应模型的简单介绍,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/12515075.ht ...
- 040.集群网络-CNI网络模型
一 CNM网络模型 1.1 网络模型 生产环境中,跨主机容器间的网络互通已经成为基本要求,更高的要求包括容器固定IP地址.一个容器多个IP地址.多个子网隔离.ACL控制策略.与SDN集成等.目前主流的 ...
- 云CRM系统安全吗
云CRM系统有一个特点只要连接互联网就能够进行访问,这种访问可以是移动端也可以是电脑端的,而且本地CRM系统只允许电脑端访问.云CRM系统将数据存储在云服务器上,很多人就会问云CRM系统安全吗?下面和 ...
- fastjson JSONObject.toJSONString 出现 $ref: "$."的解决办法(重复引用)
首先,fastjson作为一款序列化引擎,不可避免的会遇到循环引用的问题,为了避免StackOverflowError异常,fastjson会对引用进行检测. 如果检测到存在重复/循环引用的情况,fa ...
- [剑指offer]3.数组中的重复数字
3.数组中的重复数字 题目 找出数组中重复的数字. 在一个长度为 n 的数组 nums 里的所有数字都在 0-n-1 的范围内.数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了 ...
- Django之模板层细说
django的模板层,基于我们前面学习的内容,也知道主要语法是{{变量相关}}{%逻辑相关%},那么具体还有哪些内容呢?且听我娓娓道来. 模板层(模板语法) 标签 过滤器 自定义标签,过滤器,incl ...
- 【webpack 系列】基础篇
Webpack 基础篇 基本概念 Webpack 是一个现代 JavaScript 应用程序的静态模块打包器.当 webpack 处理应用程序时,它会递归地构建一个依赖关系图,其中包含应用程序需要的每 ...
- 动态规划/MinMax-Predict the Winner
2018-04-22 19:19:47 问题描述: Given an array of scores that are non-negative integers. Player 1 picks on ...
- Android适配器
Android适配器 安卓的适配器在我看来是一个非常重要的知识点,面对形式相同但数据源较多的情况时,适配器是一个比较好的解决方法.数据适配器是建立了数据源与控件之间的适配关系,将数据源转换为控件能够显 ...