吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据
import requests url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
print(strhtml.text)

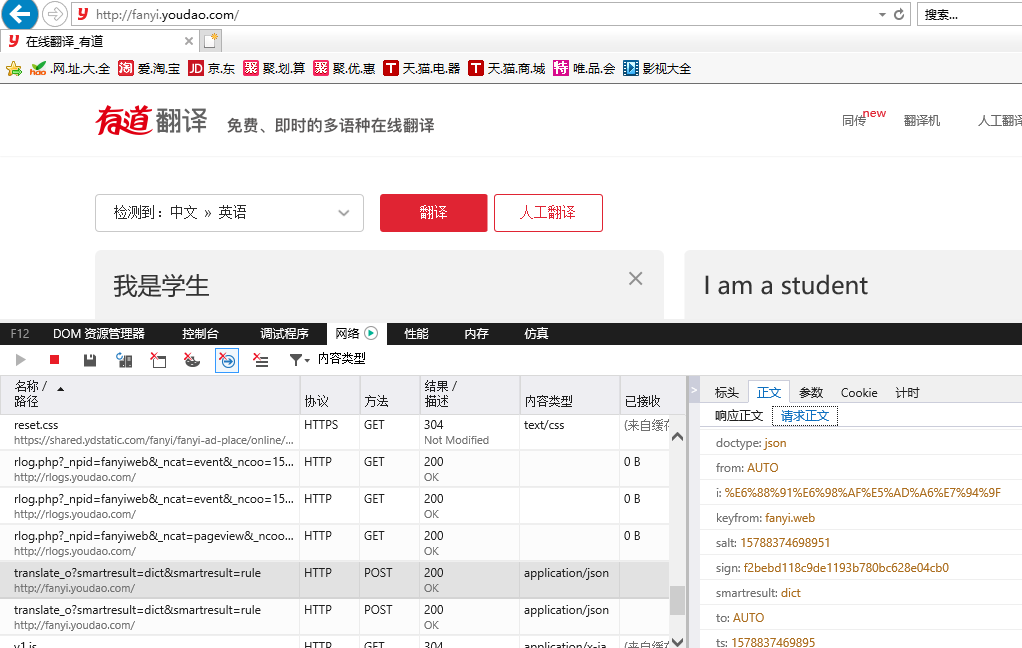

URL='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #post请求需要写请求访问,请求内容可以在对应网页的开发者模式中获取,谷歌浏览器显示不出来,我使用的是IE浏览器
Form_data = {
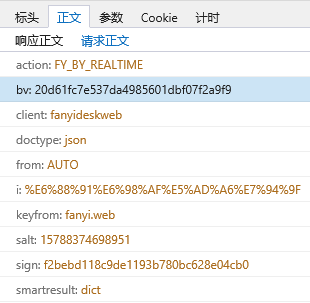
'action': 'FY_BY_REALTlME',
'bv': '20d61fc7e537da4985601dbf07f2a9f9',
'client': 'fanyideskweb',
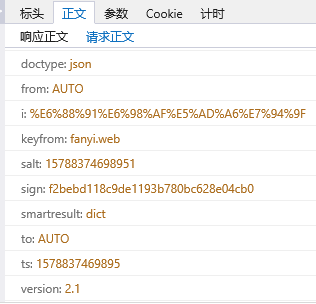
'doctype': 'json',
'from': 'AUTO',
'i': '我是学生',
'keyfrom': 'fanyi.web',
'salt': '',
'sign': 'f2bebd118c9de1193b780bc628e04cb0',
'smartresult': 'dict',
'to': 'AUTO',
'ts': '',
'version': '2.1'
} import requests response = requests.post(URL,data=Form_data)

import json
import requests def get_translate_date(word=None):
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
Form_data = {'i':word, 'from':'AUTO','to': 'AUTO','smartresult': 'dict', 'client':'fanyideskweb',
'salt':'','sign':'78181ebbdcb38de9b4a3f4cd1d38816b','doctype':'json',
'version': '2.1','keyfrom':'fanyi.web','action':'FY_BY_CLICKBUTTION','typoResult':'false'}
response = requests.post(url, data=Form_data) # 请求表单数据
print(response.text)
content = json.loads(response.text) # 将JSON格式字符串转字典
print(content['translateResult'][0][0]['tgt']) # 打印翻译后的数据
if __name__ == '__main__':
get_translate_date('我爱数据')

吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然PYTHON爬虫:爬虫攻防战
我们在开发者模式下不仅可以找到URL.Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己.服务器识别浏览器访问的方法就是判断keywor是否为Request h ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
- 吴裕雄--天生自然python编程:turtle模块绘图(3)
turtle(海龟)是Python重要的标准库之一,它能够进行基本的图形绘制.turtle图形绘制的概念诞生于1969年,成功应用于LOGO编程语言. turtle库绘制图形有一个基本框架:一个小海龟 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(1)
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行 ...
随机推荐
- 【C语言】计算N名同学的某门功课的平均成绩
分析: 循环输入number只童鞋的成绩,累加为sum,最后输出sum/number即可! 代码: #include<stdio.h> int main() { , score;//sco ...
- android studio中project structure配置
android studio project structure 1.project中填jdk路径 2.module中添androidsdk路径 3.sdks中填jdk路径
- Navicat连接两个不同机子上的mysql数据库,端口用换吗?--不用
经过了上一篇的努力,成功的连上了远程的mysql数据库 dos 命令行下的成功连接 在用Navicat连接的时候要注意: 端口仍然是3306,而不用去更改,并不会和上面的本机的Mysql连接使用的端口 ...
- utf-8无bom格式编码
BOM——Byte Order Mark,就是字节序标记 在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF.而FFFE在U ...
- Linux 一些有用的能力
编程能力 Linux产生于一群真正的黑客.尽管人们习惯于认为Linus是Linux的缔造者,在linux包含的数以千计的文件中,也有一个名为Credits的文件记录了主要的Linux Hacker们的 ...
- 【PAT甲级】1054 The Dominant Color (20 分)
题意: 输入两个正整数M和N(M<=800,N<=600),分别代表一张图片的宽度和高度,接着输入N行每行包括M个点的颜色编号,输出这张图片主导色的编号.(一张图片的主导色占据了一半以上的 ...
- phpsduty安装SSL证书,apache不能启动,解决方案
最近给客户开发微信小程序,因为本人也不太懂服务器的安装,(大神勿喷),顾个人一直使用的集成环境,原来一直是客户提供主机什么的,都是我们和客户说一下需要什么环境啊,配置啊,之类的,这次首次自己动手. 废 ...
- Educational Codeforces Round 81 + Gym 102267
UPD:变色了!!!历史最高1618~ Educational Codeforces Round 81 (Rated for Div. 2) The 2019 University of Jordan ...
- shell coding about mac ox
1, mac path---http://blog.csdn.net/playstudy/article/details/50149021 Mac系统的环境变量,加载顺序为:/etc/profile ...
- @implementer,抽象类,接口
@implementer,抽象类,接口 1. implementer 在看twisted源码时,经常出现@implementer(IReactorFDSet) 它来自zope.interfa ...