聚类算法总结以及python代码实现
一、聚类(无监督)的目标
使同一类对象的相似度尽可能地大;不同类对象之间的相似度尽可能地小。
二、层次聚类
层次聚类算法实际上分为两类:自上而下或自下而上。自下而上的算法在一开始就将每个数据点视为一个单一的聚类,然后依次合并(或聚集)类,直到所有类合并成一个包含所有数据点的单一聚类。因此,自下而上的层次聚类称为合成聚类或HAC。聚类的层次结构用一棵树(或树状图)表示。树的根是收集所有样本的唯一聚类,而叶子是只有一个样本的聚类。在继续学习算法步骤之前,先查看下面的图表
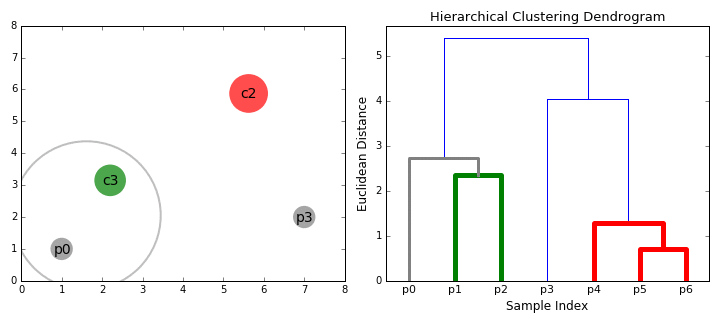
1.我们首先将每个数据点作为一个单独的聚类进行处理。如果我们的数据集有X个数据点,那么我们就有了X个聚类。然后我们选择一个度量两个聚类之间距离的距离度量。作为一个示例,我们将使用平均连接(average linkage)聚类,它定义了两个聚类之间的距离,即第一个聚类中的数据点和第二个聚类中的数据点之间的平均距离。
2.在每次迭代中,我们将两个聚类合并为一个。将两个聚类合并为具有最小平均连接的组。比如说根据我们选择的距离度量,这两个聚类之间的距离最小,因此是最相似的,应该组合在一起。
3.重复步骤2直到我们到达树的根。我们只有一个包含所有数据点的聚类。通过这种方式,我们可以选择最终需要多少个聚类,只需选择何时停止合并聚类,也就是我们停止建造这棵树的时候!
层次聚类算法不要求我们指定聚类的数量,我们甚至可以选择哪个聚类看起来最好。此外,该算法对距离度量的选择不敏感;它们的工作方式都很好,而对于其他聚类算法,距离度量的选择是至关重要的。层次聚类方法的一个特别好的用例是,当底层数据具有层次结构时,你可以恢复层次结构;而其他的聚类算法无法做到这一点。层次聚类的优点是以低效率为代价的,因为它具有O(n³)的时间复杂度,与K-Means和高斯混合模型的线性复杂度不同。
层次聚类方法对给定的数据集进行层次的分解,直到某种条件满足或者达到最大迭代次数。具体又可分为:
凝聚的层次聚类(AGNES算法):一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇(一般是计算所有簇的中心之间的距离,选取距离最小的两个簇合并),直到某个终结条件被满足或者达到最大迭代次数。
分裂的层次聚类(DIANA算法):采用自顶向下的策略,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇(一般是每次迭代分裂一个簇为两个),直到达到了某个终结条件或者达到最大迭代次数。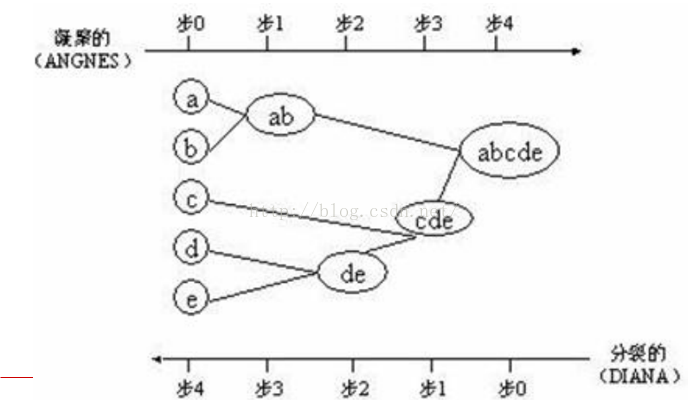
import sys,os
import numpy as np class Hierarchical:
def __init__(self,center,left=None,right=None,flag=None,distance=0.0):
self.center = center
self.left = left
self.right = right
self.flag = flag
self.distance = distance def traverse(node):
if node.left==None and node.right==None:
return [node.center]
else:
return traverse(node.left)+traverse(node.right) def distance(v1,v2):
if len(v1)!=len(v2):
print("出现错误了")
distance = 0
for i in range(len(v1)):
distance+=(v1[i]-v2[i])**2
distance = np.sqrt(distance)
return distance def hcluster(data,n):
if len(data)<=0:
print('invalid data')
clusters = [Hierarchical(data[i],flag=i) for i in range(len(data))]
#print(clusters)
distances = {}
min_id1 = None
min_id2 = None
currentCluster = -1 while len(clusters)>n:
minDist = 100000000000000 for i in range(len(clusters)-1):
for j in range(i+1,len(clusters)):
#print(distances.get((clusters[i], clusters[j])))
if distances.get((clusters[i],clusters[j]))==None: distances[(clusters[i].flag,clusters[j].flag)]=distance(clusters[i].center,clusters[j].center) if distances[(clusters[i].flag,clusters[j].flag)]<= minDist:
min_id1 = i
min_id2 = j
minDist = distances[(clusters[i].flag,clusters[j].flag)] if min_id1!=None and min_id2!=None and minDist!=1000000000:
newCenter = [(clusters[min_id1].center[i]+clusters[min_id2].center[i])/2 for i in range(len(clusters[min_id2].center))]
newFlag = currentCluster
currentCluster -= 1
newCluster = Hierarchical(newCenter,clusters[min_id1],clusters[min_id2],newFlag,minDist)
del clusters[min_id2]
del clusters[min_id1]
clusters.append(newCluster)
finalCluster = [traverse(clusters[i]) for i in range(len(clusters))]
return finalCluster if __name__ == '__main__':
data = [[123,321,434,4325,345345],[23124,141241,434234,9837489,34743],\
[128937,127,12381,424,8945],[322,4348,5040,8189,2348],\
[51249,42190,2713,2319,4328],[13957,1871829,8712847,34589,30945],
[1234,45094,23409,13495,348052],[49853,3847,4728,4059,5389]]
#print(len(data))
finalCluster = hcluster(data,3)
print(finalCluster)
#print(len(finalCluster[0])) 在聚类过程中,基于相关系数的距离是区分价格指数序列的主要指标,而 Manhattan距离则用于处理相关系数无法区分的部分。分裂的层次聚类方法优于凝聚的层次聚类方法,因为凝聚的方法无法判断使用何种距离度量,而分裂的方法则依次使用基于相关系数的距离和 Manhattan距离
【褚洪洋,柴跃廷,刘义.基于层次分裂算法的价格指数序列聚类[J].清华大学学报(自然科学版),2015,55(11):1178-1183.】大家可以参考这个文献对比层次聚类中的这两算法。论文的主要内容。 (该文提出一种基于层次分裂算法的价格指数序列聚类方法,选择基于相关系数的距离和 Manhattan距 离 作 为 距 离 度 量,分 两 步 对 价格指数序列进行聚类。算法通过设置不同的终止条件停止分裂,不需要事先设置簇数。
本文提出一种价格指数序列的层次分裂算法,使用基于相关系数的距 离和 Manhattan 距离作为距离度量,分两步对价格指数序列进行聚类。在编制网购价格指数时,
算法能够有效划分价格指数序列,找到同类商品的基本价格指数,为分类价格指数的编制提供依据。与其他时序数据的聚类算法相比,本算法有如下特点:
1)不直接采用相关系数作为距离度量,而是采用剔除整体趋势后的相关系数,能够更准确地反映价格指数序列间的关系;
2)结合价格指数序列的实际情况,分别采用两种不同的距离度量对价格指 数序列进行分裂聚类,有效地对价格指数序列进行划分;
3)不需要事先设置簇数,通过分裂终止条件控制簇分裂的停止,算法根据价格指数序列数据和终止条件参数自动获取簇数。)
三、基于密度的聚类方法
基于密度的聚类算法从样本密度的角度考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇得到最终结果。
DBSCAN:具有噪声的基于聚类方法,能够处理非球状结构数据

大致思想如下:
初始化核心对象集合T为空,遍历一遍样本集D中所有的样本,计算每个样本点的ε-邻域中包含样本的个数,如果个数大于等于MinPts,则将该样本点加入到核心对象集合中。初始化聚类簇数k = 0, 初始化未访问样本集和为P = D。
当T集合中存在样本时执行如下步骤:
2.1记录当前未访问集合P_old = P
2.2从T中随机选一个核心对象o,初始化一个队列Q = [o]
2.3P = P-o(从T中删除o)
2.4当Q中存在样本时执行:
2.4.1取出队列中的首个样本q
2.4.2计算q的ε-邻域中包含样本的个数,如果大于等于MinPts,则令S为q的ε-邻域与P的交集,
Q = Q+S, P = P-S
2.5 k = k + 1,生成聚类簇为Ck = P_old - P
2.6 T = T - Ck
划分为C= {C1, C2, ……, Ck}

import numpy as np
import pylab as pl data = '''
1,0.697,0.46,2,0.774,0.376,3,0.634,0.264,4,0.608,0.318,5,0.556,0.215,
6,0.403,0.237,7,0.481,0.149,8,0.437,0.211,9,0.666,0.091,10,0.243,0.267,
11,0.245,0.057,12,0.343,0.099,13,0.639,0.161,14,0.657,0.198,15,0.36,0.37,
16,0.593,0.042,17,0.719,0.103,18,0.359,0.188,19,0.339,0.241,20,0.282,0.257,
21,0.748,0.232,22,0.714,0.346,23,0.483,0.312,24,0.478,0.437,25,0.525,0.369,
26,0.751,0.489,27,0.532,0.472,28,0.473,0.376,29,0.725,0.445,30,0.446,0.459''' a = data.split(',')
dataset = [(float(a[i]),float(a[i+1])) for i in range(1,len(a)-1,3)] #计算欧几里得距离,a,b分别为两个元组
def dist(a,b):
return np.sqrt(pow((a[0]-b[0]),2))+np.sqrt(pow((a[1]-b[1]),2)) def DBSCAN(D,e,Minpts):# 初始化核心对象集合T,聚类个数k,聚类集合C, 未访问集合P
T =set();k=0;C = [];P = set(D)
for d in D:
if len([i for i in D if dist(d,i)<=e])>= Minpts:
T.add(d)
#开始聚类
while len(T):
P_old = P
o = list(T)[np.random.randint(0,len(T))]
P = P - set(o)
Q = [];Q.append(o)
while len(Q):
q = Q[0]
Nq = [i for i in D if dist(q,i)<=e]
if len(Nq)>=Minpts:
S = P&set(Nq)
Q += (list(S))
P = P - S
Q.remove(q)
k += 1
Ck = list(P_old-P)
T = T - set(Ck)
C.append(Ck)
return C #画图
def draw(C):
colValue = ['r', 'y', 'g', 'b', 'c', 'k', 'm']
for i in range(len(C)):
coo_X = [] #x坐标列表
coo_Y = [] #y坐标列表
for j in range(len(C[i])):
coo_X.append(C[i][j][0])
coo_Y.append(C[i][j][1])
pl.scatter(coo_X, coo_Y, marker='x', color=colValue[i%len(colValue)], label=i) pl.legend(loc='upper right')
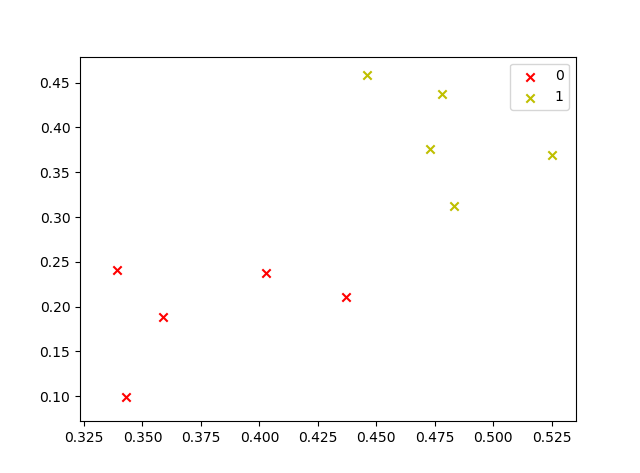
pl.show() C = DBSCAN(dataset, 0.11, 5)
draw(C)
运行结果如下:
聚类算法总结以及python代码实现的更多相关文章
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 神经网络BP算法C和python代码
上面只显示代码. 详BP原理和神经网络的相关知识,请参阅:神经网络和反向传播算法推导 首先是前向传播的计算: 输入: 首先为正整数 n.m.p.t,分别代表特征个数.训练样本个数.隐藏层神经元个数.输 ...
- KNN算法原理(python代码实现)
kNN(k-nearest neighbor algorithm)算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性 ...
- 第十三篇:K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- Kmeans文档聚类算法实现之python
实现文档聚类的总体思想: 将每个文档的关键词提取,形成一个关键词集合N: 将每个文档向量化,可以参看计算余弦相似度那一章: 给定K个聚类中心,使用Kmeans算法处理向量: 分析每个聚类中心的相关文档 ...
随机推荐
- springboot - 返回xml error 从自定义的 ErrorController
1.概览 2.在<springboot - 返回JSON error 从自定义的 ErrorController>基础上,做如下调整: 1).新增Attribute类和Error类 pac ...
- 32位CPU和64位CPU 区别
操作系统只是硬件和应用软件中间的一个平台. 32位操作系统针对的32位的CPU设计. 64位操作系统针对的64位的CPU设计.操作系统只是硬件和应用软件中间的一个平台. 32位操作系统针对的32位的C ...
- UVA - 10635 Prince and Princess(LCS,可转化为LIS)
题意:有两个长度分别为p+1和q+1的序列,每个序列中的各个元素互不相同,且都是1~n2的整数.两个序列的第一个元素均为1.求出A和B的最长公共子序列长度. 分析: A = {1,7,5,4,8,3, ...
- Fedora Workstation 31众多功能得到改进
导读 周一,Red Hat的桌面高级经理Christian F.K. Schaller分享了一篇博客文章,概述了Fedora Workstation 31的各种改进和特性.这些包括Wayland的改进 ...
- netty权威指南学习笔记四——TCP粘包/拆包之粘包问题解决
发生了粘包,我们需要将其清晰的进行拆包处理,这里采用LineBasedFrameDecoder来解决 LineBasedFrameDecoder的工作原理是它依次遍历ByteBuf中的可读字节,判断看 ...
- Sass 安装到使用
sass学习 Sass 可以通过以下三种方式使用:作为命令行工具:作为独立的 Ruby 模块 (Ruby module):或者作为 Rack-enabled 框架的插件(例如 Ruby on Rail ...
- maven-本地安装jar包
maven 安装本地jar包,通过install插件的install-file mojo进行工作,具体可通过如下命令进行查看 mvn help:describe -Dplugin=install -D ...
- 151-PHP nl2br函数(二)
<?php $str="h\nt\nm\nl"; //定义一个多处换行的字串 echo "未处理前的输出形式:<br />{$str}"; $ ...
- 080-PHP的if与elseif用法
<?php /* 正确的使用方法: */ $a = 10; $b = 20; if ($a > $b): echo $a . "大于" . $b; elseif ($a ...
- NumPy 基于数值区间创建数组
来源:Python Numpy 教程 章节 Numpy 介绍 Numpy 安装 NumPy ndarray NumPy 数据类型 NumPy 数组创建 NumPy 基于已有数据创建数组 NumPy 基 ...