TensorFlow从0到1之常量、变量和占位符详解(6)
最基本的 TensorFlow 提供了一个库来定义和执行对张量的各种数学运算。张量,可理解为一个 n 维矩阵,所有类型的数据,包括标量、矢量和矩阵等都是特殊类型的张量。

TensorFlow 支持以下三种类型的张量:
- 常量:常量是其值不能改变的张量。
- 变量:当一个量在会话中的值需要更新时,使用变量来表示。例如,在神经网络中,权重需要在训练期间更新,可以通过将权重声明为变量来实现。变量在使用前需要被显示初始化。另外需要注意的是,常量存储在计算图的定义中,每次加载图时都会加载相关变量。换句话说,它们是占用内存的。另一方面,变量又是分开存储的。它们可以存储在参数服务器上。
- 占位符:用于将值输入 TensorFlow 图中。它们可以和 feed_dict 一起使用来输入数据。在训练神经网络时,它们通常用于提供新的训练样本。在会话中运行计算图时,可以为占位符赋值。这样在构建一个计算图时不需要真正地输入数据。需要注意的是,占位符不包含任何数据,因此不需要初始化它们。
TensorFlow 常量
声明一个标量常量:
t_1 = tf.constant(4)
一个形如 [1,3] 的常量向量可以用如下代码声明:
t_2 = tf.constant([4,3,2])
要创建一个所有元素为零的张量,可以使用 tf.zeros() 函数。这个语句可以创建一个形如 [M,N] 的零元素矩阵,数据类型(dtype)可以是 int32、float32 等:
tf.zeros([M,N],tf.dtype)
例如:
zero_t = tf.zeros([2,3],tf.int32)
# Results in an 2x3 array of zeros:[[0 0 0],[0 0 0]]
还可以创建与现有 Numpy 数组或张量常量具有相同形状的张量常量,如下所示:
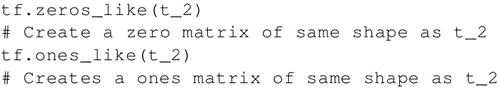
创建一个所有元素都设为 1 的张量。下面的语句即创建一个形如 [M,N]、元素均为 1 的矩阵:
tf.ones([M,N],tf,dtype)
例如:
ones_t = tf.ones([2,3],tf.int32)
# Results in an 2x3 array of ones:[[1 1 1],[1 1 1]]
更进一步,还有以下语句:
- 在一定范围内生成一个从初值到终值等差排布的序列:
tf.linspace(start,stop,num)
相应的值为 (stop-start)/(num-1)。例如:
range_t = tf.linspace(2.0,5.0,5)
#We get:[2. 2.75 3.5 4.25 5.] - 从开始(默认值=0)生成一个数字序列,增量为 delta(默认值=1),直到终值(但不包括终值):
tf.range(start,limit,delta)
下面给出实例:
range_t = tf.range(10)
#Result:[0 1 2 3 4 5 6 7 8 9]
TensorFlow 允许创建具有不同分布的随机张量:
- 使用以下语句创建一个具有一定均值(默认值=0.0)和标准差(默认值=1.0)、形状为 [M,N] 的正态分布随机数组:
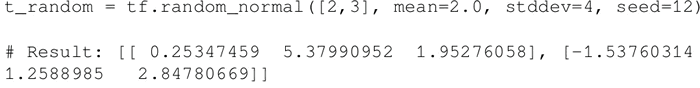
- 创建一个具有一定均值(默认值=0.0)和标准差(默认值=1.0)、形状为 [M,N] 的截尾正态分布随机数组:

- 要在种子的 [minval(default=0),maxval] 范围内创建形状为 [M,N] 的给定伽马分布随机数组,请执行如下语句:

- 要将给定的张量随机裁剪为指定的大小,使用以下语句:
tf.random_crop(t_random,[2,5],seed=12)
这里,t_random 是一个已经定义好的张量。这将导致随机从张量 t_random 中裁剪出一个大小为 [2,5] 的张量。
很多时候需要以随机的顺序来呈现训练样本,可以使用 tf.random_shuffle() 来沿着它的第一维随机排列张量。如果 t_random 是想要重新排序的张量,使用下面的代码:
tf.random_shuffle(t_random)
- 随机生成的张量受初始种子值的影响。要在多次运行或会话中获得相同的随机数,应该将种子设置为一个常数值。当使用大量的随机张量时,可以使用 tf.set_random_seed() 来为所有随机产生的张量设置种子。以下命令将所有会话的随机张量的种子设置为 54:
tf.set_random_seed(54)
TIP:种子只能有整数值。
TensorFlow 变量
它们通过使用变量类来创建。变量的定义还包括应该初始化的常量/随机值。下面的代码中创建了两个不同的张量变量 t_a 和 t_b。两者将被初始化为形状为 [50,50] 的随机均匀分布,最小值=0,最大值=10:

注意:变量通常在神经网络中表示权重和偏置。
下面的代码中定义了两个变量的权重和偏置。权重变量使用正态分布随机初始化,均值为 0,标准差为 2,权重大小为 100×100。偏置由 100 个元素组成,每个元素初始化为 0。在这里也使用了可选参数名以给计算图中定义的变量命名:

在前面的例子中,都是利用一些常量来初始化变量,也可以指定一个变量来初始化另一个变量。下面的语句将利用前面定义的权重来初始化 weight2:
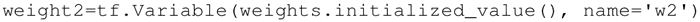
变量的定义将指定变量如何被初始化,但是必须显式初始化所有的声明变量。在计算图的定义中通过声明初始化操作对象来实现:
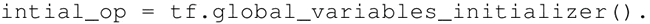
每个变量也可以在运行图中单独使用 tf.Variable.initializer 来初始化:

保存变量:使用 Saver 类来保存变量,定义一个 Saver 操作对象:
saver = tf.train.Saver()
TensorFlow 占位符
介绍完常量和变量之后,我们来讲解最重要的元素——占位符,它们用于将数据提供给计算图。可以使用以下方法定义一个占位符:
tf.placeholder(dtype,shape=None,name=None)
dtype 定占位符的数据类型,并且必须在声明占位符时指定。在这里,为 x 定义一个占位符并计算 y=2*x,使用 feed_dict 输入一个随机的 4×5 矩阵:

解读分析
需要注意的是,所有常量、变量和占位符将在代码的计算图部分中定义。如果在定义部分使用 print 语句,只会得到有关张量类型的信息,而不是它的值。
为了得到相关的值,需要创建会话图并对需要提取的张量显式使用运行命令,如下所示:
print(sess.run(t_1))
#Will print the value of t_1 defined in step 1
拓展阅读
很多时候需要大规模的常量张量对象;在这种情况下,为了优化内存,最好将它们声明为一个可训练标志设置为 False 的变量:
t_large = tf.Varible(large_array,trainable = False)
TensorFlow 被设计成与 Numpy 配合运行,因此所有的 TensorFlow 数据类型都是基于 Numpy 的。使用 tf.convert_to_tensor() 可以将给定的值转换为张量类型,并将其与 TensorFlow 函数和运算符一起使用。该函数接受 Numpy 数组、Python 列表和 Python 标量,并允许与张量对象互操作。
下表列出了 TensorFlow 支持的常见的数据类型:

请注意,与 Python/Numpy 序列不同,TensorFlow 序列不可迭代。试试下面的代码:
for i in tf.range(10)
你会得到一个错误提示:
#typeError("'Tensor'object id not iterable.")
TensorFlow从0到1之常量、变量和占位符详解(6)的更多相关文章
- tensorflow学习笔记(二)常量、变量、占位符、会话
常量.变量.占位符.会话是tensorflow编程的基础也是最常用到的东西,tensorflow中定义的变量.常量都是tensor(张量)类型. 常量tf.constant() tensorflow中 ...
- TensorFlow解析常量、变量和占位符
TensorFlow解析常量.变量和占位符 最基本的 TensorFlow 提供了一个库来定义和执行对张量的各种数学运算.张量,可理解为一个 n 维矩阵,所有类型的数据,包括标量.矢量和矩阵等都是特殊 ...
- 初学C#之变量、占位符、转义符、还有就是类型转换
㈠.定义变量 先定义再赋值 int Num1; Num1 = ; 定义的同时赋值 ; 定义多个变量同时赋值,先决条件变量类型相同,例如: string phome = "1891250888 ...
- tensorflow中张量_常量_变量_占位符
1.tensor 在tensorflow中,数据是被封装在tensor对象中的.tensor是张量的意思,即包含从0到任意维度的张量.常数是0维度的张量,向量是1维度的张量,矩阵是二维度的张量,以及还 ...
- Java堆、栈和常量池以及相关String详解
一:在JAVA中,有六个不同的地方可以存储数据: 1. 寄存器(register). 这是最快的存储区,因为它位于不同于其他存储区的地方——处理器内部.但是寄存器的数量极其有限,所以寄存器由编译器根据 ...
- 条件变量pthread_cond_wait()和pthread_cond_signal()详解
条件变量 条件变量是利用线程间共享的全局变量进行同步的一种机制,主要包括两个动作:一个线程等待"条件变量的条件成立"而挂起:另一个线程使"条件成立" ...
- 好用的wget命令从下载添加环境变量到各参数详解
本文是因为(笔者使用的windows系统)使用过好几次wget后,始终存在各种细节问题,于是下定决定细致的研究一下,并记录下其中细节. 下载与安装 第一步:下载wget,网络地址:http://dow ...
- 总结:C#变量,占位符等相关知识
新年耽误了不少时间,好久没认真的坐下来学习了,新年也快完了,又要开始正式学习了,按着视频教学学习,用了一天的时间,学习了下简单的变量及其相关的输入输出和应用,学了几种最基本的类型: int(整型) c ...
- shell-的特殊变量-进程状态变量$$ $! $? $_详解
一:shell的特殊变量-进程状态变量详解 1. 进程状态变量 $$ 获取当前shell的进程号(pid) $! 执行上一个指令的pid,上一个后台运行进程的进程号 $? 获取执行上一个指令的返回值 ...
随机推荐
- 解决删除~/Library/Caches/CocoaPods/search_index.json重新pod search还是不起作用
今天新苹果机安装cocoapods,安装完以后发现怎么pod search 都没有用 命令行提示: swhcxp@iosdevmac ~ % pod search Almofire Setup com ...
- Windows系统下Git的下载和配置
简介:Git是一款免费.开源的分布式版本控制系统,可记录文件每次改动,便于多人协作编辑. 下载:git-for-windows下载地址https://git-for-windows.github.io ...
- CF912D Fishes
题目链接:http://codeforces.com/contest/912/problem/D 题目大意: 在一个\(n \times m\)的网格中放鱼(每个网格只能放一条鱼),用一个\(r \t ...
- 花费一周刷完两份面试pdf(含答案)轻松拿下了抖音、头条、京东、小米等大厂的offer,成功度过程序员的寒冬。
整理出一篇Java进阶架构师之路的核心知识,同时也是面试时面试官必问的知识点,篇章也是包括了很多知识点,其中包括了有基础知识.Java集合.JVM.多线程并发.spring原理.微服务.Netty 与 ...
- Java——日期格式化YYYYMMdd与yyyyMMdd的区别
public static void main(String[] args) { //YYYY 是表示:当天所在的周属于的年份,一周从周日开始,周六结束,只要本周跨年,那么这周就算入下一年. //20 ...
- [JavaWeb基础] 014.Struts2 标签库学习
在Struts1和Struts2中都有很多很方便使用的标签库,使用它可以让我们的页面代码更加的简洁,易懂,规范.标签的形式就跟html的标签形式一样.上面的篇章中我们也讲解了自定义标签那么在如何使用标 ...
- 枚举&注解
枚举:自定义枚举类 使用Enum关键字定义的枚举类 注解:jdk内置的基本注解类型(3个) 自定义注解类型 对注解进行注解(元注解4个) 利用反射获取注解信息(反射部分涉及) 自定义枚举类: Test ...
- 02 . Mysql基础操作及增删改查
SQL简介 SQL(Structured Query Language 即结构化查询语言) SQL语言主要用于存取数据.查询数据.更新数据和管理关系数据库系统,SQL语言由IBM开发. SQL语句四大 ...
- Rocket - debug - TLDebugModuleOuterAsync
https://mp.weixin.qq.com/s/PSeMVZjSjEFHJgCYZzfa9Q 简单介绍TLDebugModuleOuterAsync的实现. 1. dmi2tl dmi2tl是T ...
- 使用turtle库画同切圆
import turtle as t t.setup(600,600,None,None) t.pensize(5) t.penup() t.pendown() t.pencolor("re ...