如何利用CSS选择器抓取京东网商品信息
前几天小编分别利用Python正则表达式、BeautifulSoup、Xpath分别爬取了京东网商品信息,今天小编利用CSS选择器来为大家展示一下如何实现京东商品信息的精准匹配~~

CSS选择器
目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup使用的技术书籍和博客软文并不多,而在这仅有的资料中介绍CSS选择器的少之又少。在网络爬虫的页面解析中,CCS选择器实际上是一把效率甚高的利器。虽然资料不多,但官方文档却十分详细,然而美中不足的是需要一定的基础才能看懂,而且没有小而精的演示实例。
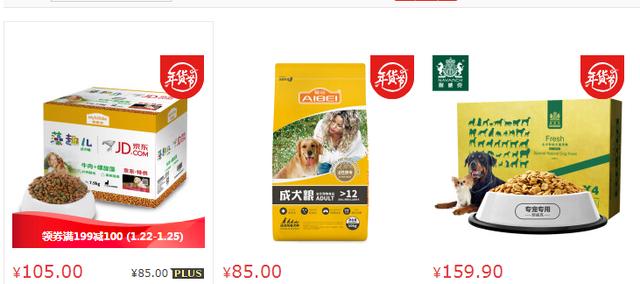
京东商品图
首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求。在这里小编仍以关键词“狗粮”作为搜索对象,之后得到后面这一串网址:
https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数的意思就是我们输入的keyword,在本例中该参数代表“狗粮”,具体详情可以参考Python大神用正则表达式教你搞定京东商品信息。所以,只要输入keyword这个参数之后,将其进行编码,就可以获取到目标URL。之后请求网页,得到响应,尔后利用CSS选择器进行下一步的数据采集。
商品信息在京东官网上的部分网页源码如下图所示:
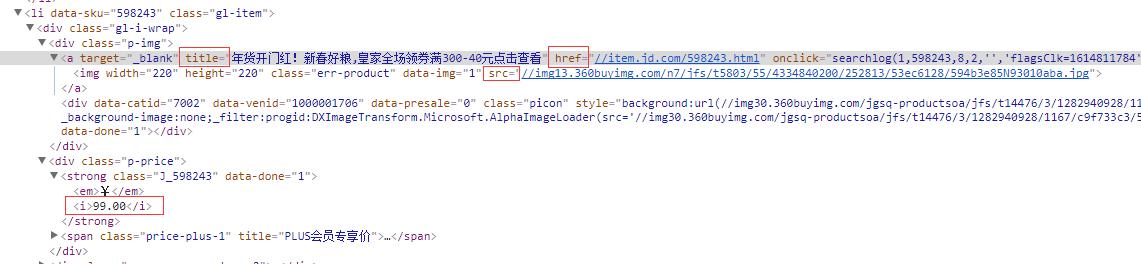
部分网页源码
仔细观察源码,可以发现我们所需的目标信息在红色框框的下面,那么接下来我们就要一层一层的去获取想要的信息。
在Python的urllib库中提供了quote方法,可以实现对URL的字符串进行编码,从而可以进入到对应的网页中去。
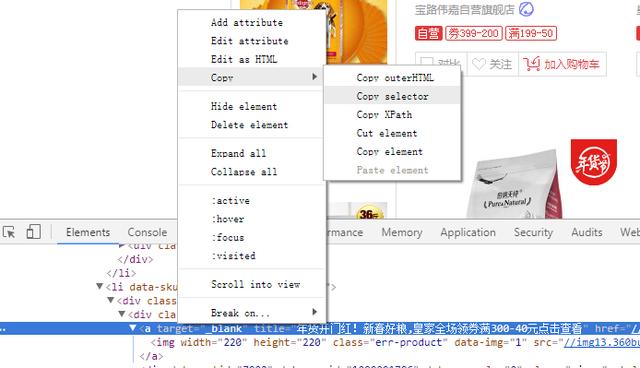
CSS选择器在线复制
很多小伙伴都觉得CSS表达式很难写,其实掌握了基本的用法也就不难了。在线复制CSS表达式如上图所示,可以很方便的复制CSS表达式。但是通过该方法得到的CSS表达式放在程序中一般不能用,而且长的没法看。所以CSS表达式一般还是要自己亲自上手。
直接上代码,利用CSS去提取目标信息,如商品的名字、链接、图片和价格,具体的代码如下图所示:
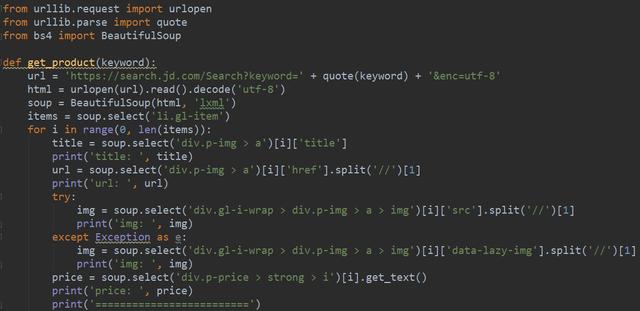
代码实现
如果你想快速的实现功能更强大的网络爬虫,那么BeautifulSoupCSS选择器将是你必备的利器之一。BeautifulSoup整合了CSS选择器的语法和自身方便使用API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人,使用CSS选择器是个非常方便的方法。
最后得到的效果图如下所示:
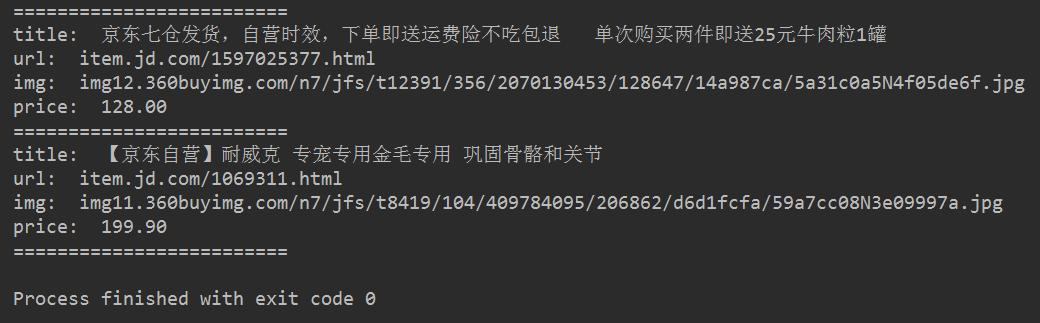
最终效果图
新鲜的狗粮再一次出炉咯~~~

CSS选择器
关于CSS选择器的简单介绍:
BeautifulSoup支持大部分的CSS选择器。其语法为:向tag对象或BeautifulSoup对象的.select()方法中传入字符串参数,选择的结果以列表形式返回,即返回类型为list。
tag.select("string")
BeautifulSoup.select("string")
注意:在取得含有特定CSS属性的元素时,标签名不加任何修饰,如class类名前加点,id名前加 /#。
想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
如何利用CSS选择器抓取京东网商品信息的更多相关文章
- 如何利用BeautifulSoup选择器抓取京东网商品信息
昨天小编利用Python正则表达式爬取了京东网商品信息,看过代码的小伙伴们基本上都坐不住了,辣么多的规则和辣么长的代码,悲伤辣么大,实在是受不鸟了.不过小伙伴们不用担心,今天小编利用美丽的汤来为大家演 ...
- 如何利用Xpath抓取京东网商品信息
前几小编分别利用Python正则表达式和BeautifulSoup爬取了京东网商品信息,今天小编利用Xpath来为大家演示一下如何实现京东商品信息的精准匹配~~ HTML文件其实就是由一组尖括号构成的 ...
- C#使用CSS选择器抓取页面内容
最近在查wpf绘图资料时,偶然看到Python使用CSS选择器抓取网页的功能.觉得很强,这里用C#也实现一下. 先介绍一下CSS选择器 在 CSS 中,选择器是一种模式,用于选择需要添加样式的元素. ...
- 使用selenium+BeautifulSoup 抓取京东商城手机信息
1.准备工作: chromedriver 传送门:国内:http://npm.taobao.org/mirrors/chromedriver/ vpn: selenium BeautifulSo ...
- 使用Pyquery+selenium抓取淘宝商品信息
配置文件,配置好数据库名称,表名称,要搜索的产品类目,要爬取的页数 MONGO_URL = 'localhost' MONGO_DB = 'taobao' MONGO_TABLE = 'phone' ...
- 003.[python学习] 简单抓取豆瓣网电影信息程序
声明:本程序仅用于学习爬网页数据,不可用于其它用途. 本程序仍有很多不足之处,请读者不吝赐教. 依赖:本程序依赖BeautifulSoup4和lxml,如需正确运行,请先安装.下面是代码: #!/us ...
- php+phpquery简易爬虫抓取京东商品分类
这是一个简单的php加phpquery实现抓取京东商品分类页内容的简易爬虫.phpquery可以非常简单地帮助你抽取想要的html内容,phpquery和jquery非常类似,可以说是几乎一样:如果你 ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 【爬虫】利用Scrapy抓取京东商品、豆瓣电影、技术问题
1.scrapy基本了解 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说,网络抓 ...
随机推荐
- Centos7网络配置( 网关、dns、ip地址配置)
0.前提:设置VMware的虚拟网络编辑器 子网和网关设置 虚拟网络编辑器 1.配置DNS(可忽略) $vim /etc/resolv.conf nameserver 192.168.0.1 2. ...
- CSS3.16
<style>#back-top { position: fixed; bottom: 10px; right: 5px; z-index: 99;}#back-top span { wi ...
- D. Yet Another Subarray Problem 思维 难 dp更好理解
D. Yet Another Subarray Problem 这个题目很难,我比赛没有想出来,赛后又看了很久别人的代码才理解. 这个题目他们差不多是用一个滑动窗口同时枚举左端点和右端点,具体如下: ...
- WCF(一)
在学习WCF之前要知道几个术语: 一:终结点 终结点由3个要素组成:契约,绑定,地址. 1.契约:契约属于一个服务公开接口的一部分.一个服务的契约,定义了服务端公开的服务方法,使用的传输协议,可访问的 ...
- Day_09【常用API】扩展案例3_删除源字符串中的指定字符,并计算指定字符出现的次数
分析以下需求,并用代码实现 1.键盘录入一个源字符串由字符串变量scrStr接收 2.键盘录入一个要删除的字符串由字符串变量delStr接收 3.要求 删除该字scrStr符串中的所有delStr字符 ...
- LeetCode 62,从动态规划想到更好的解法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode专题第36篇文章,我们一起来看下LeetCode的62题,Unique Paths. 题意 其实这是一道老掉牙的题目了 ...
- 移动端网站开发要点-meta设置
<!DOCTYPE html> <!-- 使用 HTML5 doctype,不区分大小写 --> <html lang="zh-cmn-Hans"&g ...
- Docker之commit制作镜像
一.docker是什么? Docker是一个为开发人员和系统管理员提供分布式应用程序的开放平台.它是一个开源的容器引擎,基于Go语言并遵从Apche2.0协议开源. 功能:Docker可以让开发者打包 ...
- webpack使用babel
几个月没用webpack都忘了好多了. webpack构建前端,使用时除了entry/output,就是plugins和module.loaders,还有本地测试的devServer. npm ins ...
- noi7219 复杂的整数划分问题
noi7219 复杂的整数划分问题 #include <bits/stdc++.h> using namespace std; ; int dp1[maxn][maxn], dp2[max ...