如何利用Xpath抓取京东网商品信息

前几小编分别利用Python正则表达式和BeautifulSoup爬取了京东网商品信息,今天小编利用Xpath来为大家演示一下如何实现京东商品信息的精准匹配~~
HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树;XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
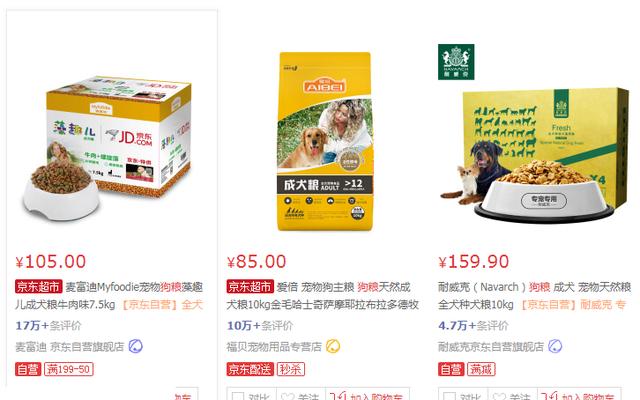
京东网狗粮商品
首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求。在这里小编仍以关键词“狗粮”作为搜索对象,之后得到后面这一串网址:
https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数的意思就是我们输入的keyword,在本例中该参数代表“狗粮”,具体详情可以参考Python大神用正则表达式教你搞定京东商品信息。所以,只要输入keyword这个参数之后,将其进行编码,就可以获取到目标URL。之后请求网页,得到响应,尔后利用bs4选择器进行下一步的数据采集。
商品信息在京东官网上的部分网页源码如下图所示:

狗粮信息在京东官网上的网页源码
仔细观察源码,可以发现我们所需的目标信息是存在<li data-sku="/*/*/*/*/*" class="gl-item">标签下的,那么接下来我们就像剥洋葱一样,一层一层的去获取我们想要的信息。
通常URL编码的方式是把需要编码的字符转化为%xx的形式,一般来说URL的编码是基于UTF-8的,当然也有的于浏览器平台有关。在Python的urllib库中提供了quote方法,可以实现对URL的字符串进行编码,从而可以进入到对应的网页中去。
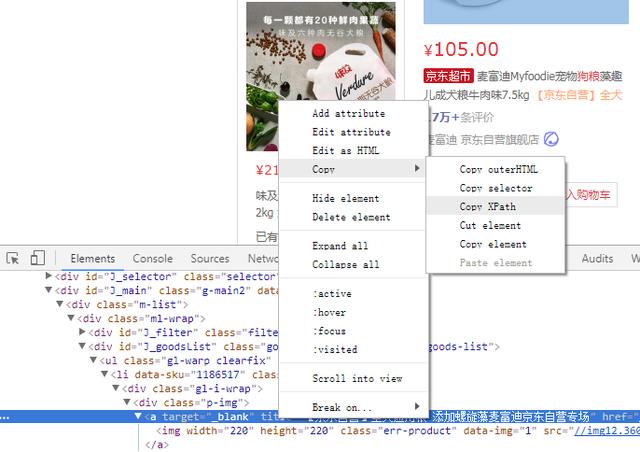
在线复制Xpath表达式
很多小伙伴都觉得Xpath表达式很难写,其实掌握了基本的用法也就不难了。在线复制Xpath表达式如上图所示,可以很方便的复制Xpath表达式。但是通过该方法得到的Xpath表达式放在程序中一般不能用,而且长的没法看。所以Xpath表达式一般还是要自己亲自上手。
直接上代码,利用Xpath去提取目标信息,如商品的名字、链接、图片和价格,具体的代码如下图所示:
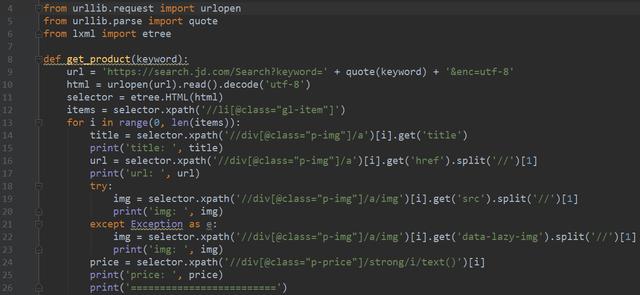
爬虫代码
在这里,小编告诉大家一个Xpath表达式匹配技巧。之前看过好几篇文章,大佬们都推荐Xpath表达式使用嵌套匹配的方式。在本例中,首先定义items,如下所示:
items = selector.xpath('//li[@class="gl-item"]')
之后通过range函数,逐个从网页中进行匹配目标信息,而不是直接通过复制Xpath表达式的方式一步到位。希望小伙伴们以后都可以少入这个坑~~
最后得到的效果图如下所示:
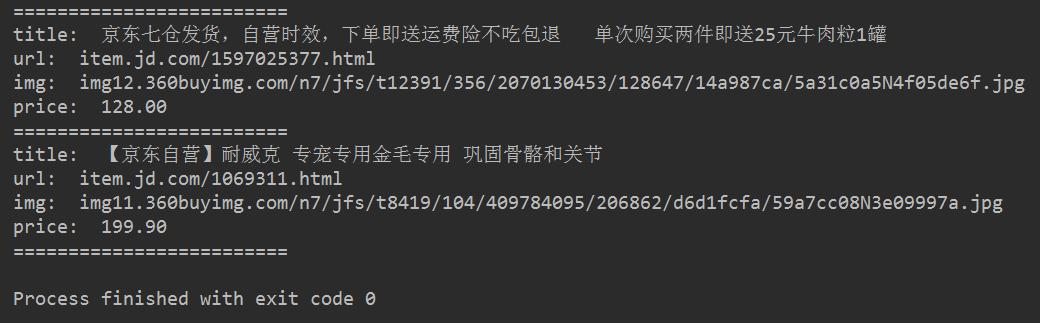
最终效果图
新鲜的狗粮再一次出炉咯~~~
小伙伴们,有没有发现利用Xpath来获取目标信息比正则表达式要简单一些呢?
想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
如何利用Xpath抓取京东网商品信息的更多相关文章
- 如何利用CSS选择器抓取京东网商品信息
前几天小编分别利用Python正则表达式.BeautifulSoup.Xpath分别爬取了京东网商品信息,今天小编利用CSS选择器来为大家展示一下如何实现京东商品信息的精准匹配~~ CSS选择器 目前 ...
- 如何利用BeautifulSoup选择器抓取京东网商品信息
昨天小编利用Python正则表达式爬取了京东网商品信息,看过代码的小伙伴们基本上都坐不住了,辣么多的规则和辣么长的代码,悲伤辣么大,实在是受不鸟了.不过小伙伴们不用担心,今天小编利用美丽的汤来为大家演 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- 【爬虫】利用Scrapy抓取京东商品、豆瓣电影、技术问题
1.scrapy基本了解 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说,网络抓 ...
- 利用xpath爬取招聘网的招聘信息
爬取招聘网的招聘信息: import json import random import time import pymongo import re import pandas as pd impor ...
- [Python爬虫] 之十七:Selenium +phantomjs 利用 pyquery抓取梅花网数据
一.介绍 本例子用Selenium +phantomjs爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字: ...
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- 使用Pyquery+selenium抓取淘宝商品信息
配置文件,配置好数据库名称,表名称,要搜索的产品类目,要爬取的页数 MONGO_URL = 'localhost' MONGO_DB = 'taobao' MONGO_TABLE = 'phone' ...
- 使用selenium+BeautifulSoup 抓取京东商城手机信息
1.准备工作: chromedriver 传送门:国内:http://npm.taobao.org/mirrors/chromedriver/ vpn: selenium BeautifulSo ...
随机推荐
- JavaScript toFixed() 实现四舍五入保留两位小数
const num = 18.186; let result; result = num.toFixed(2) console.log(result) // 18.19 注意,返回值为String类型
- FastDFS文件服务器安装指南附安装包和自启动(看此篇就够了)
安装包在最后,本文为博主自己亲自安装记录 转载请注明出处 注意文字不清晰请放大看,放大看!! 安装包地址
- JWT安全问题
Json Web Tokens 在线工具网站:https://jwt.io/ python 用到的库 jwt // pip install pyjwt JWTCrack key // git c ...
- Java——Java是什么一门什么语言
解释型语言 源代码不能直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行: 程序不需要编译,程序在运行时才翻译成机器语言,每执行一次都要翻译一次: 解释性语言代表:Python ...
- CSS3.16
<style>#back-top { position: fixed; bottom: 10px; right: 5px; z-index: 99;}#back-top span { wi ...
- spring boot的核心注解
1.@SpringBootApplication 是SpingBoot的启动类 此注解等同于@Configuration+@EnableAutoConfiguration+@ComponentScan ...
- Spring官网阅读(十四)Spring中的BeanWrapper及类型转换
文章目录 接口定义 继承关系 接口功能 1.PropertyEditorRegistry(属性编辑器注册器) 接口定义 PropertyEditor 概念 Spring中对PropertyEditor ...
- ActiveMQ 持久订阅者,执行结果与初衷相违背,验证离线订阅者无效,问题解决
导读 最新在接触ActiveMQ,里面有个持久订阅者模块,功能是怎么样也演示不出来效果.配置参数比较简单(配置没几个参数),消费者第一次运行时,需要指定ClientID(此时Broker已经记录离线订 ...
- 【Hadoop离线基础总结】CDH版本的zookeeper环境搭建
CDH版本的zookeeper环境搭建 下载 下载地址 http://archive.cloudera.com/cdh5/cdh/5/ 修改配置文件 创建ZooKeeper数据存放目录 mkdir - ...
- Altium Designer PCB封装bug,元件焊盘位置偏移解决方法
1.问题描述:在拖动几个电阻位置时,意外发现Altium designer20版本软件的一个bug——0805的电阻两焊盘位置发生了偏移,如下图所示. 2.解决办法: ①选中焊盘偏移的封装,右键剪切掉 ...