OCR场景文本识别:文字检测+文字识别
一. 应用背景
OCR(Optical Character Recognition)文字识别技术的应用领域主要包括:证件识别、车牌识别、智慧医疗、pdf文档转换为Word、拍照识别、截图识别、网络图片识别、无人驾驶、无纸化办公、稿件编辑校对、物流分拣、舆情监控、文档检索、字幕识别文献资料检索等。OCR文字识别主要可以分为:印刷体文字识别和手写体文字识别。文字识别方法的一般流程为:识别出文字区域、对文字区域矩形分割成不同的字符、字符分类、识别出文字、后处理识别矫正。
二. 文字检测
文字检测是文字识别过程中的一个非常重要的环节,文字检测的主要目标是将图片中的文字区域位置检测出来,以便于进行后面的文字识别,只有找到了文本所在区域,才能对其内容进行识别。
1.【CTPN】
CTPN,全称是“Detecting Text in Natural Image with Connectionist Text Proposal Network”,将文本行在水平方向解耦成slices进行检测,再将slices区域合并成文本框。CTPN结构与Faster R-CNN类似,但加入了RNN(LSTM层)用于序列的特征识别来提高检测精度,目前CTPN针对水平长行文本的检测是工业级的,算法鲁棒。

算法流程:
Feature Map:N(images) - C(channels) - H(height) - W(width)
(1). 骨干网络VGG16提取特征,第5个block的第三个卷积层conv5(stride=16,size=N×C×H×W)作为特征图;
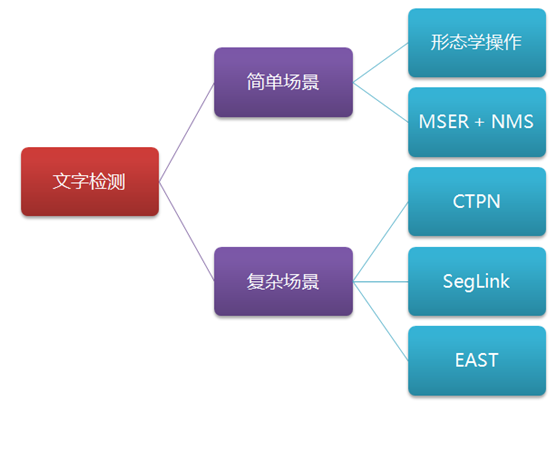
(2). 在con5上做3×3滑窗,每个点都结合周围3×3区域生成3×3×C特征向量,输出N×9C×H×W空间特征图;
(3). Reshape特征图:N×9C×H×W -> (NH)×W×9C;
(4). 以batch=NH,Tmax=W的数据流输入双向LSTM,学习每一行的序列特征(注:LSTM/Reverse-LSTM都包含128个hidden layer),BLSTM输出(NH)×W×256空间序列混合特征图;
(5). Reshape特征图:(NH)×W×256 -> N×256×H×W;
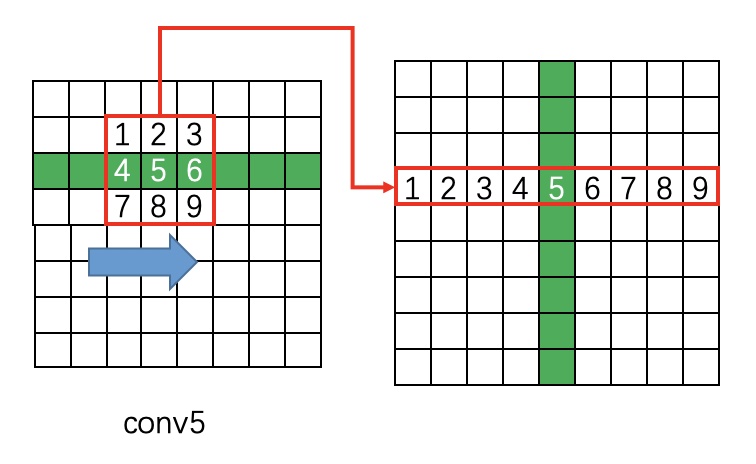
(6). 将RNN的结果输入到FC层(256×512的矩阵参数),变为N×512×H×W的特征;
(7). 将FC层得到的特征输入类似Faster R-CNN的RPN网络,获得text proposals。2k vertical coordinate和k side-refinement用来回归k个anchor的位置信息并进行校准,2k scores表示k个anchor的类别。
(8). 采用文本线构造办法,把text proposal连接成一个文本检测框。
关键策略:
(1). text proposals网络。
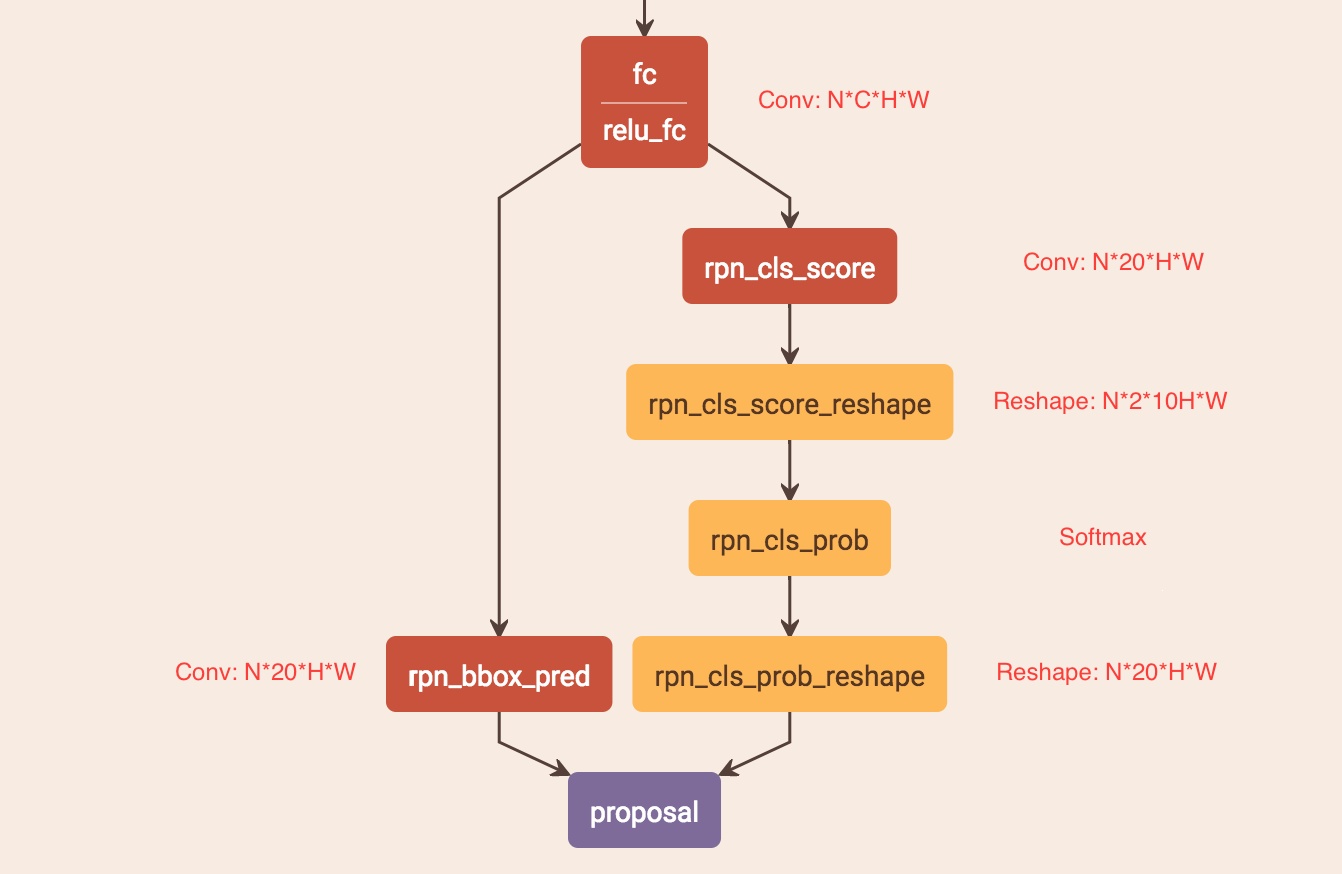
左侧分支用于b-box回归,FC特征图每个点配备了10个对应原图尺度的Anchor(红色小矩形框确定字符位置),宽度相等(width=[16]),高度10个尺度([11,16,23,33,48,68,97,138,198,283]),保证Anchor在x方向上覆盖原图每个点且不相互重叠并在y方向上覆盖差异较大的不同高度文本目标。获得Anchor后,b-box regression只修正并预测包含文本的Anchor的中心y坐标与高度h(没预测起始坐标x是因为在构造标签时有固定偏移),故rpn_bbox_pred有20个channels。右边分支用于Softmax分类,判断Anchor中是否包含文本,选出score大的正Anchor。
(2). 标签构造。
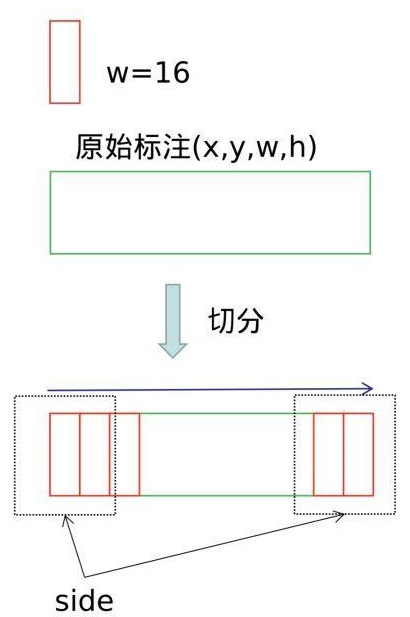
如图,给定一个文本的标注框(x, y, w, h),沿着水平方向进行切分,偏移为16个像素(conv5的stride为16,特征图中的一个像素对应标签的16的宽度),得到了一系列的文本小片。将左右标记为红色的小片(两端50像素以内)作为side-refinement时候的标签,约束网络对文本起始和终止点的矫正。
(3). 文本线构造。
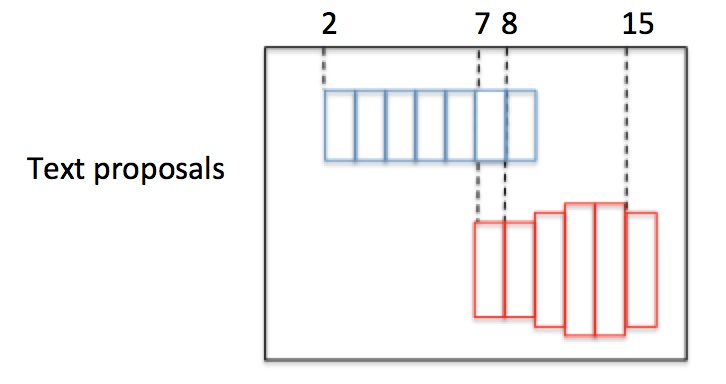
如图,有2个text proposal,包含红蓝2组Anchor。首先按水平x坐标排序Anchor。然后按照规则依次计算每个boxi的pair(boxj),组成pair(boxi,boxj),规则如下:
正向寻找:1. 沿水平正方向,寻找和boxi水平距离小于50的候选Anchor;2. 从候选Anchor中,挑出与boxi竖直方向overlapv>0.7的Anchor;3. 挑出符合条件2中Softmax score最大的boxj。
再反向寻找:1. 沿水平负方向,寻找和boxj水平距离小于50的候选Anchor;2. 从候选Anchor中,挑出与boxj竖直方向overlapv>0.7的Anchor;3. 挑出符合条件2中Softmax score最大的boxk。
最后对比scorei和scorek:如果scorei>=scorek,这是一个最长连接,设置Graph(i,j)=True;如果scorei<scorek,不是一个最长连接。
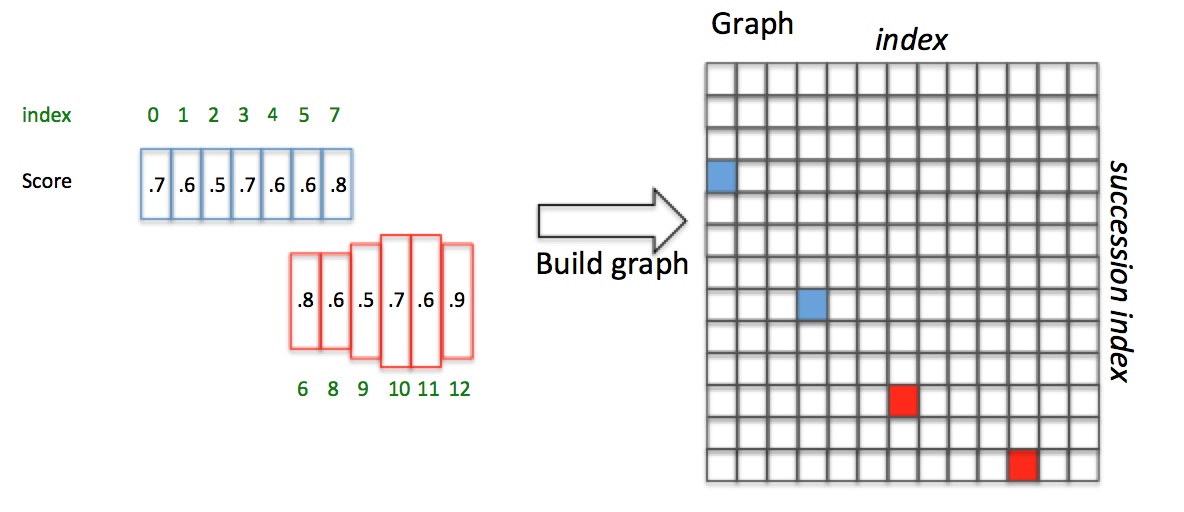 如上图,Anchor已经按照x坐标排序且Softmax score已知。对于box3(i=3),向前寻找50像素,满足overlapv>0.7且score最大的是box7(j=7);box7反向寻找,满足overlapv>0.7且score最大的是box3(k=3)。因为scorei=3>=scorek=3,pair(box3,box7)是一个最长连接,设置Graph(3,7)=True。对于box4,正向寻找得到box7;box7反向寻找得到box3,但scorei=4>=scorek=3,所以pair(box4,box7)不是最长连接,包含在pair(box3,box7)中。
如上图,Anchor已经按照x坐标排序且Softmax score已知。对于box3(i=3),向前寻找50像素,满足overlapv>0.7且score最大的是box7(j=7);box7反向寻找,满足overlapv>0.7且score最大的是box3(k=3)。因为scorei=3>=scorek=3,pair(box3,box7)是一个最长连接,设置Graph(3,7)=True。对于box4,正向寻找得到box7;box7反向寻找得到box3,但scorei=4>=scorek=3,所以pair(box4,box7)不是最长连接,包含在pair(box3,box7)中。
以这种方式,建立一个N×N(N是正Anchor数量)的connect graph,并遍历graph。Graph(0,3)=True且Graph(3,7)=True,所以Anchor index 0->3->7组成蓝色文本区域;Graph(6,10)=True且Graph(10,12)=True,所以Anchor index 6->10->12组成红色文本区域。
综上,我们通过Text proposals确定了文本检测框。
2.【SegLink】
Seglink是在SSD基础上改进的,基本思想是:一次性检测整个文本行比较困难,就先检测局部片段,然后通过规则将所有的片段进行连接,得到最终的文本行。可以检测任意长度和多方向的文本行,CTPN只能检测水平方向。
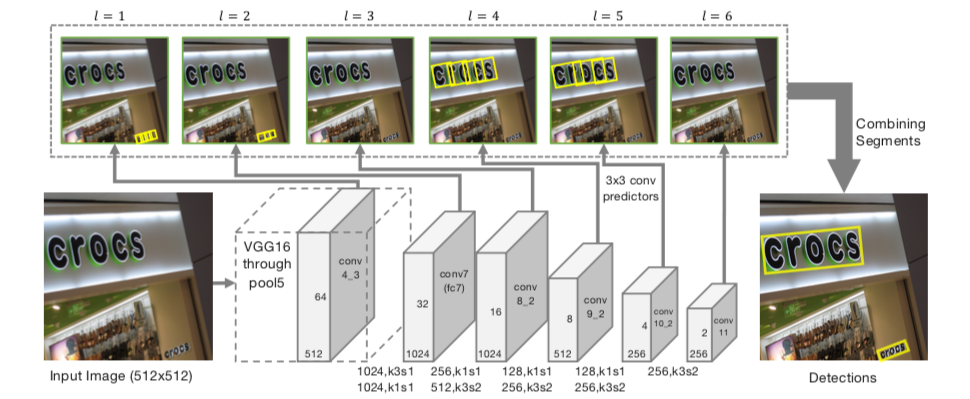
全卷积网络。输入:任意尺寸图像;输出:segments和links。
算法流程:
(1). 沿用SSD网络结构,VGG16作为backbone并将最后两个全连接层改成卷积层(fc6,fc7->conv6,conv7),再额外增加conv8, conv9, conv10, conv11,用于提取更深的特征,最后的修改SSD的Pooling层,将其改为卷积层;
(2). 提取conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11不同层的特征图,尺寸1/2倍递减;
(3). 对不同层的特征图使用3×3卷积,产生segments和links来检测不同尺度文本行;
(4). 通过融合规则,将segment的box信息和link信息进行融合,得到最终的文本行。
关键策略:
(1). Segment检测。
segment可以看作是增加了方向信息的b-box,可以表示为:b = (xb,yb,wb,hb,θb)。卷积后输出通道数为7,包含segment相对于默认框(default boxes)的偏移量(xs,ys,ws,hs,θs)及segment是否为文字的置信度(0,1)。特征图上的点在原图中的映射,就是默认框的位置。6层特征图,每层都要输出segments,例如:l层尺寸为 wl× hl,一个点在特征图上的坐标为(x,y),对应原图坐标(xa,ya)的点,那么一个默认框的中心坐标就是(xa,ya):

不同于SSD,特征图每个位置只有一个长宽比为1的默认框,根据当前层的感受野通过经验等式进行设置。最后,通过默认框和特征图回归segment的位置,预测的offsets里除了Δx, Δy, Δw, Δh, 多了一个Δθ。

(2). Link检测。
links分为Within-Layer Link和Cross-Layer Link:
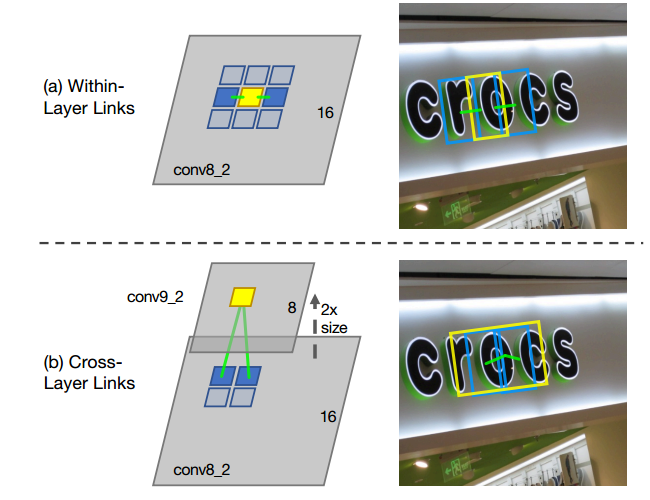
within-layer link在同一个feature map层,特征图中每个位置只预测一个segment,所以对于层内link,我们只考虑当前segment与它周围的8连通邻域的segment的连接情况,每个link有正负两个分数,正分用来表示二者是否属于同一个单词,负分表示二者是否属于不同单词(应断开连接)。这样,每个segment的link是8*2=16维的向量,links就是每个特征图卷积后输出16个通道,每两个通道表示segment与邻近的一个segment的link。

segment可能会被不同的feature map检测到,如果不同层输出segment是同一个位置,只是大小不一样,会造成重复检测的冗余问题。cross-layer link连接的是相邻两层feature map产生的segments。前一层特征图的size是后一层的特征图的两倍,这个size必须是偶数,所以输入图像的宽和高必须是128的倍数。对于跨层link,特征图的每个位置需要预测2*4=8个权重,4表示与上一层的4个邻域。

综上,conv4_3层输出的link维度为2*8=16;conv7, conv8_2, conv9_2, conv10_2, conv11其输出的link维度为2*8+2*4=24。
(3). 合并算法。
每层特征图提取出来后,再经过卷积,输出既有segments又有links的预测。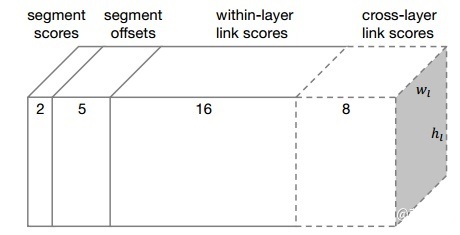 2表示二分类分数(是不是字符),5表示位置信息(x, y, w, h, θ),16表示8个同层的neighbor连接或不连接的2种情况,8表示前一层的4个neighbor连接与不连接情况。对于conv4_3:其预测输出维度为:2+5+2×8=23 ,因为该层没有cross-layer link;对于conv7, conv8_2, conv9_2, conv10_2, conv11,其预测输出维度为:2+5+2×8+2×4=31。
2表示二分类分数(是不是字符),5表示位置信息(x, y, w, h, θ),16表示8个同层的neighbor连接或不连接的2种情况,8表示前一层的4个neighbor连接与不连接情况。对于conv4_3:其预测输出维度为:2+5+2×8=23 ,因为该层没有cross-layer link;对于conv7, conv8_2, conv9_2, conv10_2, conv11,其预测输出维度为:2+5+2×8+2×4=31。

输出一系列的segments和links后,1. 首先人工设定α和β(对应segments和links的置信度设置不同的阈值)过滤噪声;2. 再采用DFS(depth first search)将segments看做node,links看做edge,将他们连接起来;3. 将连接后的所有结果作为输入,将连接在一起的segments当作是一个小的集合,称为B;4. 将B集合中所有segment的旋转角求平均值作为文本框的旋转角称为θb;5. 求tanθb作为斜率,得到一系列的平行线,求得B集合中所有segment的中心点到直线距离的和最小的那条直线;6. 将B集合中所有segment的中心点垂直投影到3步骤中找到的直线上;7. 在投影中找到距离最远的两个点(xp,yp),(xq,yq);8. 上述两点的均值作为框的中心点,距离为框的宽,B集合中所有segment的高的均值就是高。
注:3-5其实就是最小二乘法线性回归。
(4). 训练。
训练当前网络需要生成groundtruth,包括default box的label,偏移(x, y, w, h, θ),层内link及跨层link的label。求segments和links的标签前先确定与其对应的default box的标签值。图像只有一个文本框时,满足如下2点就是正样本(否则负样本):1. default box的中心在当前文本行内;2. default box的大小al与文本框的高h满足公式: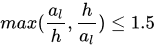 。图像中有多个文本框时,default box对于任意文本框都不满足上述条件时为负样本,否则为正样本,满足多个文本框时,该default box为与其大小最相近的文本框的正样本,大小相近指的是:
。图像中有多个文本框时,default box对于任意文本框都不满足上述条件时为负样本,否则为正样本,满足多个文本框时,该default box为与其大小最相近的文本框的正样本,大小相近指的是: 。通过上述规则得到default box的正样本后,基于这些正样本计算segments相对于default box的位置偏移量。offset只对正样本有效,负样本不需要计算。
。通过上述规则得到default box的正样本后,基于这些正样本计算segments相对于default box的位置偏移量。offset只对正样本有效,负样本不需要计算。
 将文本框顺时针旋转θ与default box进行水平对齐,然后进行裁剪,宽度保留与default box相交的部分,最后再绕文本框中心点逆时针转回到原来的角度,就可以得到一个segment。根据公式(segment检测),就可以求出segment和default box的偏移量,用来训练segment。link的标签值只要满足下面两个条件即为真:1. link连接的两个default box都为正样本;2. 两个default box属于同一个文本框。
将文本框顺时针旋转θ与default box进行水平对齐,然后进行裁剪,宽度保留与default box相交的部分,最后再绕文本框中心点逆时针转回到原来的角度,就可以得到一个segment。根据公式(segment检测),就可以求出segment和default box的偏移量,用来训练segment。link的标签值只要满足下面两个条件即为真:1. link连接的两个default box都为正样本;2. 两个default box属于同一个文本框。
损失函数定义如下:
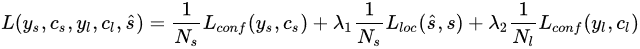
ys表示所有的segments的标签值,如果第i个default box为正样本,yis=1,否则为0;yl表示所有links的标签值;cs,cl分别为segments和links的预测值;Lconf为softmax loss,用于计算segments和links置信度的损失;Lloc为为Smooth L1 regression loss,用于计算segments预测偏移量和标签值的损失;Ns为图像中所有正样本的default box的数量;Nl为图像中所有正样本的links的个数;λ1=λ2=1。关于Data Augmentation和Online Hard Negative Mining,做法和SSD中一致。
3.【EAST/AdvancedEAST】
EAST可以实现端到端文本检测。
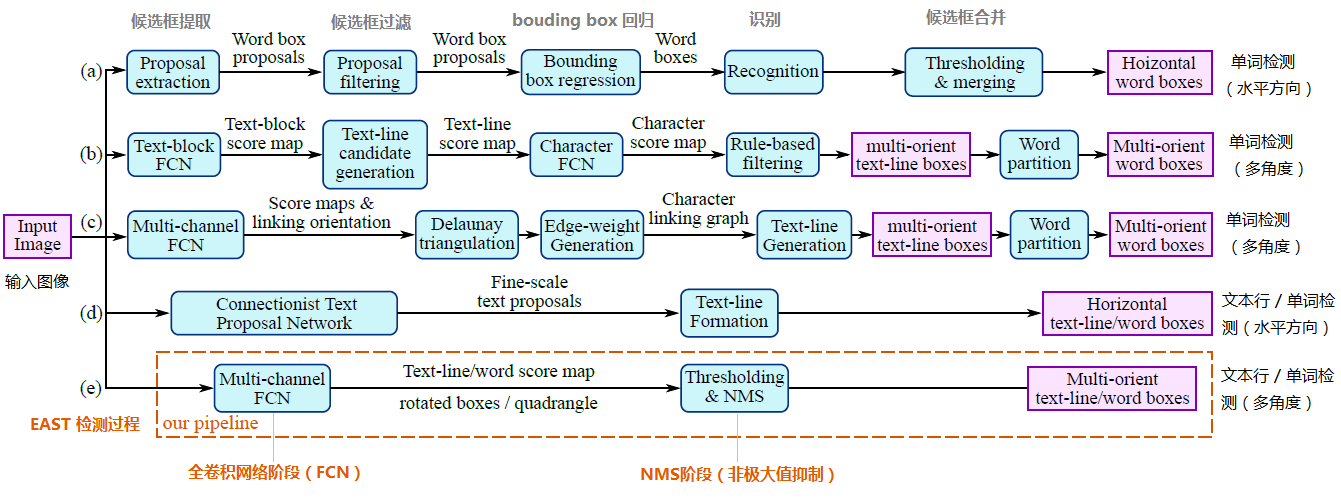
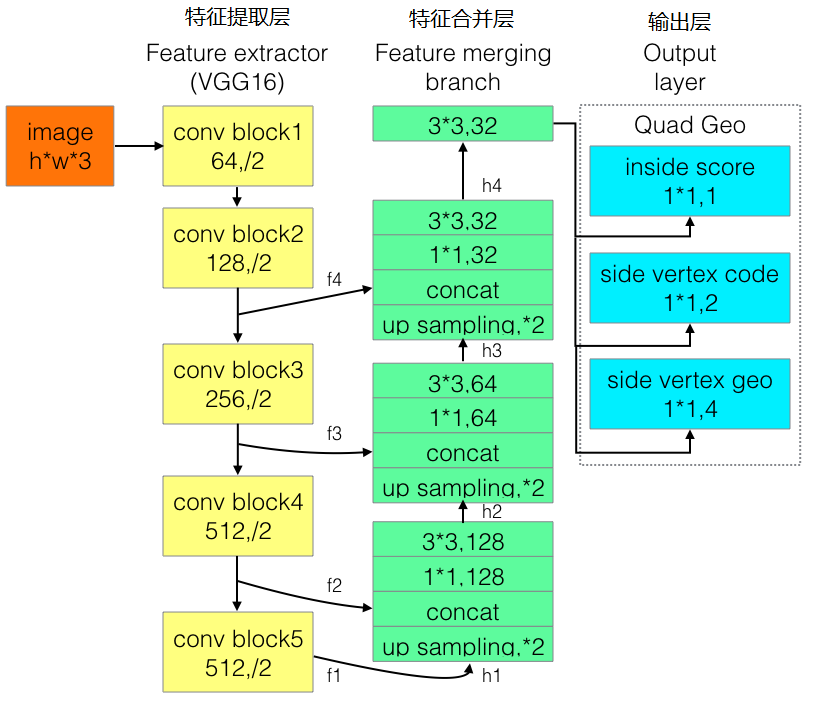
a~d是几种常见的文本检测过程,典型的检测过程包括候选框提取、候选框过滤、b-box回归、候选框合并等阶段,中间过程比较冗长。EAST模型检测过程简化为只有FCN,NMS阶段,中间过程大大缩减,且输出结果支持文本行、单词的多角度检测,高效准确,适应性强。EAST模型的网络结构分为特征提取层、特征融合层、输出层三大部分。
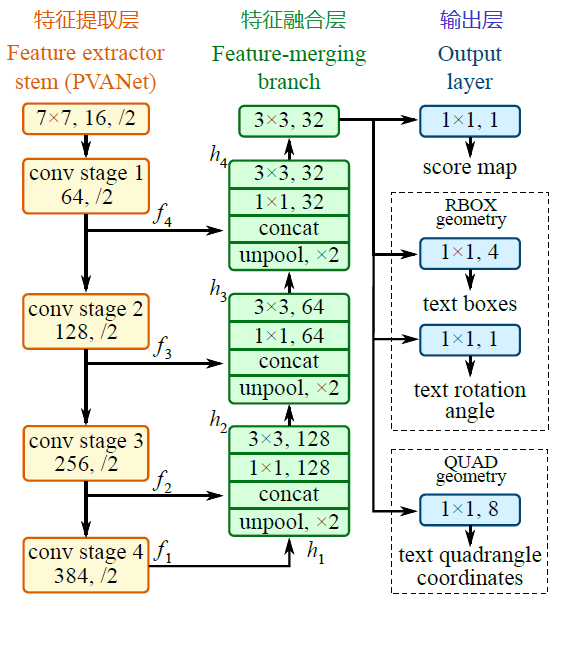
算法流程:
(1). PVANet(也可采用VGG16,Resnet等)作为主干网络提取特征,并借鉴FPN思想,抽取4个尺度(1/4,1/8,1/16,1/32 input)的特征图;
(2). 参考UNet的方法,从feature extractor顶部按规则向下合并特征;
(3). 输出文本得分和文本形状。检测形状为RBOX时,输出检测框置信度、检测框的位置角度(x,y,w,h,θ)共6个参数;检测形状为QUAD时,输出检测框置信度、任意四边形检测框(定位扭曲变形文本行)的位置坐标(x1, y1), (x2, y2), (x3, y3), (x4, y4)共9个参数。
关键策略:
(1). 特征融合规则。
最后一层特征图被最先送入uppooling层放大2倍,再与前一层的特征图进行concatenate,然后依次进行1×1和3×3卷积;再重复上述过程2次,卷积核的个数(128,64,32)依次递减;最后经过3×3,32的卷积层。
(2). 训练。
QUAD训练样本生成:
通常数据集提供的标注为平行四边形的四个顶点(x1, y1), (x2, y2), (x3, y3), (x4, y4),训练网络时,需要的将其转化为网络需要的形式,即这个平行四边形生成的9个单通道图片。
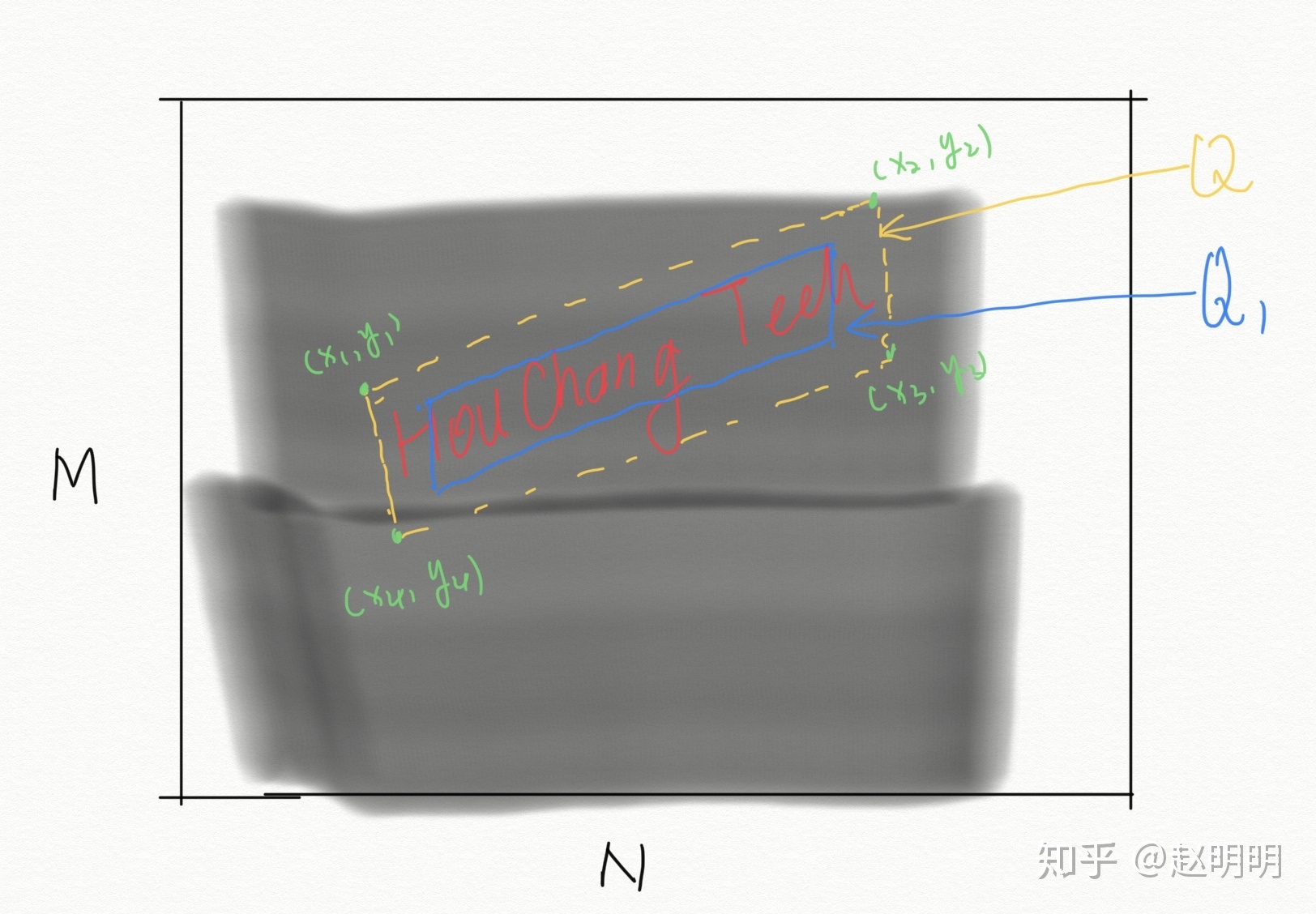

通道1:置信度score map。
1. 生成一个大小MxN为全零矩阵A,M,N为原图的长和宽;2. 将平行四边形的四个顶点两两相连,连成一个四边形Q;3. 将这个四边形向内缩小0.3,得到Q1;4. 将四边形Q1内的点置为1;5. 将矩阵A按比例缩小为原图的1/4,得到score map(长M/4,宽N/4)。
通道2:四边形位置germety map_1。
1. 生成一个大小为MxN的全零矩阵A,M,N为原图的长和宽;2. 将四边形的四个顶点两两相连,连成一个四边形Q;3. 给四边形Q内的每一个像素赋值,A(xi,yi) = x1-xi;将矩阵A按比例缩小为原图的1/4,得到germety map_1(长M/4,宽N/4)。
通道3:四边形位置germety map_2。
1. 生成一个大小为MxN的全零矩阵A,M,N为原图的长和宽;2. 将四边形的四个顶点两两相连,连成一个四边形Q;3. 给四边形Q内的每一个像素赋值,A(xi,yi) = y1-yi;将矩阵A按比例缩小为原图的1/4,得到germety map_2(长M/4,宽N/4)。
通道4:四边形位置germety map_3。
1. 生成一个大小为MxN的全零矩阵A,M,N为原图的长和宽;2. 将四边形的四个顶点两两相连,连成一个四边形Q;3. 给四边形Q内的每一个像素赋值,A(xi,yi) = x2-xi;将矩阵A按比例缩小为原图的1/4,得到germety map_3(长M/4,宽N/4)。
通道5:四边形位置germety map_4。
1. 生成一个大小为MxN的全零矩阵A,M,N为原图的长和宽;2. 将四边形的四个顶点两两相连,连成一个四边形Q;3. 给四边形Q内的每一个像素赋值,A(xi,yi) = y2-yi;将矩阵A按比例缩小为原图的1/4,得到germety map_4(长M/4,宽N/4)。
通道6:四边形位置germety map_5。
1. 生成一个大小为MxN的全零矩阵A,M,N为原图的长和宽;2. 将四边形的四个顶点两两相连,连成一个四边形Q;3. 给四边形Q内的每一个像素赋值,A(xi,yi) = x3-xi;将矩阵A按比例缩小为原图的1/4,得到germety map_5(长M/4,宽N/4)。
通道7:四边形位置germety map_6。
1. 生成一个大小为MxN的全零矩阵A,M,N为原图的长和宽;2. 将四边形的四个顶点两两相连,连成一个四边形Q;3. 给四边形Q内的每一个像素赋值,A(xi,yi) = y3-yi;将矩阵A按比例缩小为原图的1/4,得到germety map_6(长M/4,宽N/4)。
通道8:四边形位置germety map_7。
1. 生成一个大小为MxN的全零矩阵A,M,N为原图的长和宽;2. 将四边形的四个顶点两两相连,连成一个四边形Q;3. 给四边形Q内的每一个像素赋值,A(xi,yi) = x4-xi;将矩阵A按比例缩小为原图的1/4,得到germety map_7(长M/4,宽N/4)。
通道9:四边形位置germety map_8。
1. 生成一个大小为MxN的全零矩阵A,M,N为原图的长和宽;2. 将四边形的四个顶点两两相连,连成一个四边形Q;3. 给四边形Q内的每一个像素赋值,A(xi,yi) = y4-yi;将矩阵A按比例缩小为原图的1/4,得到germety map_8(长M/4,宽N/4)。
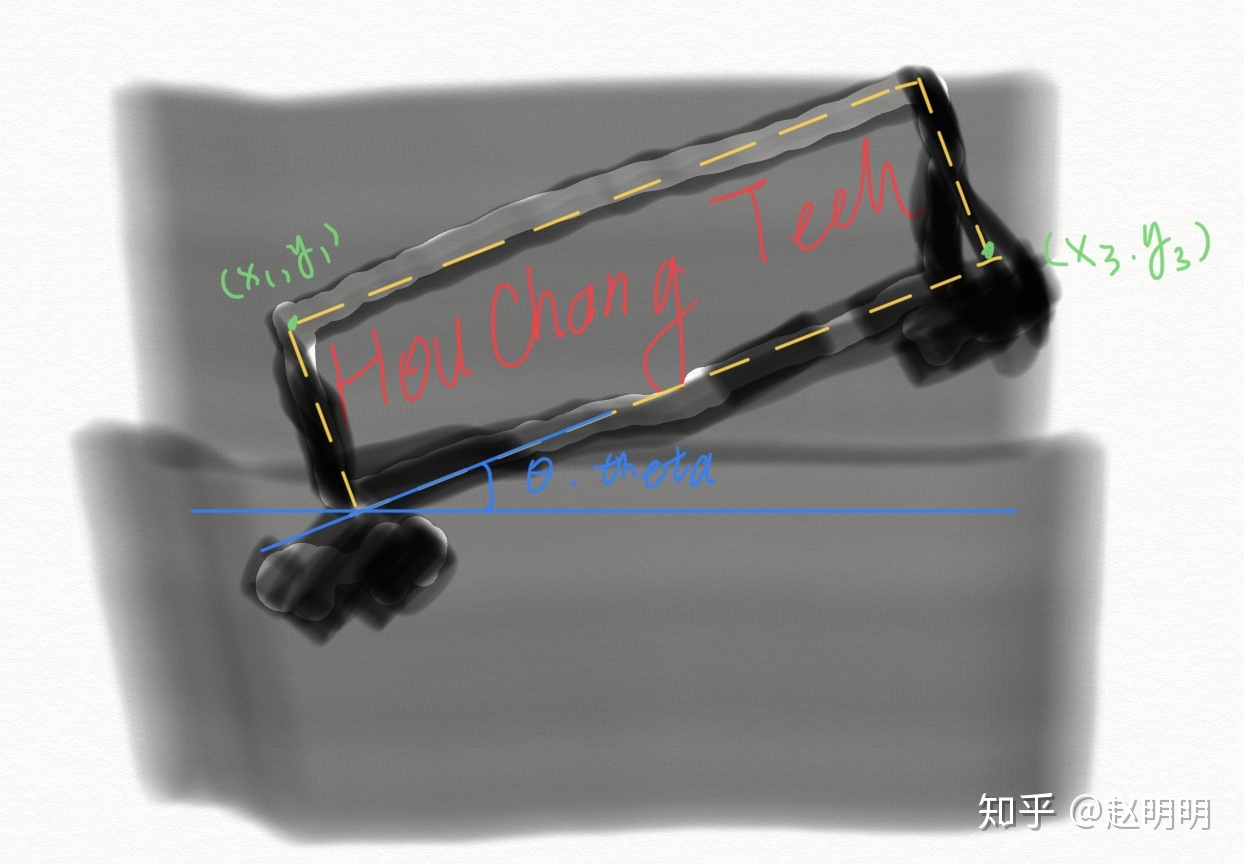
RBOX训练样本生成:
通常数据集提供的标注为5个值Theta,x1,y1,x3,y3,训练网络时,需要的将其转化为网络需要的形式,即这个旋转的矩阵生成的6个单通道图片。在此之前,先利用theta,x1,y1,x2,y2,生成矩形的另外两个顶点(x2,y2),(x4,y4),这样,矩形的四个顶点可以表示为(x1,y1),(x2,y2),(x3,y3),(x4,y4)。

通道1:置信度score map。
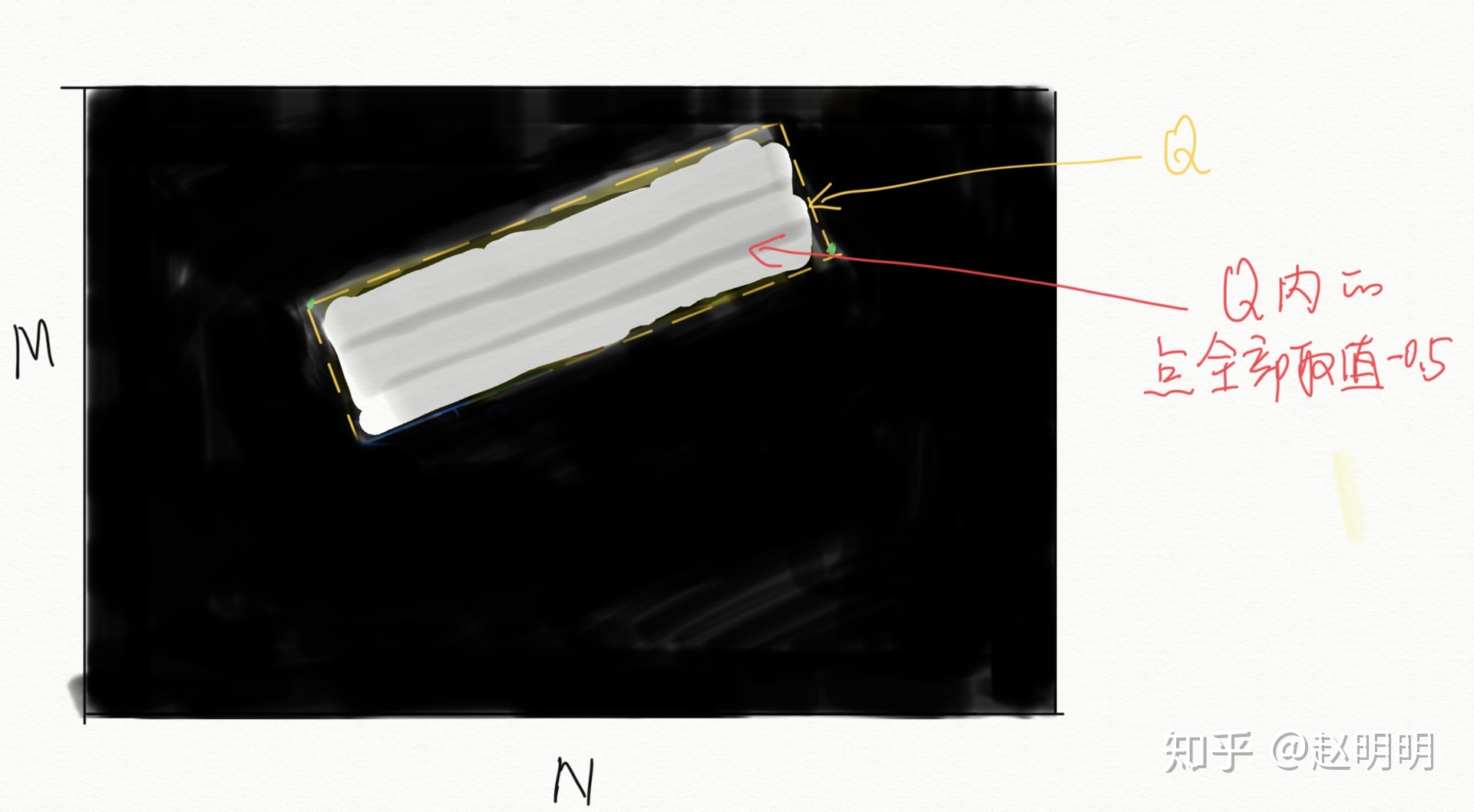
1. 生成一个大小MxN为全零矩阵A,M,N为原图的长和宽;2. 将矩形的四个顶点两两相连,形成一个矩形Q;3. 将矩形Q内的点置为1;4. 将矩阵A按比例缩小为原图的1/4,得到score map(长M/4,宽N/4)。
通道2:角度angle map。
1. 生成一个大小MxN为全零矩阵A,M,N为原图的长和宽;2. 将矩形的四个顶点两两相连,形成一个矩形Q;3. 将矩形Q内的点置为theta,如果theta=-0.5,那么Q内的所有点都为-0.5;4. 将矩阵A按比例缩小为原图的1/4,得到angle map(长M/4,宽N/4)。
通道3:矩形位置germety map_1。
1. 生成一个大小MxN为全零矩阵A,M,N为原图的长和宽;2. 将矩形的四个顶点两两相连,形成一个矩形Q;3. 给矩形Q内的每一个像素赋值,A(xi,yi) = distance[ A(xi,yi), 直线A(x1,y1)A(x2,y2)] ;4. 将矩阵A按比例缩小为原图的1/4,得到germety map_1(长M/4,宽N/4)。
通道4:矩形位置germety map_2。
1. 生成一个大小MxN为全零矩阵A,M,N为原图的长和宽;2. 将矩形的四个顶点两两相连,形成一个矩形Q;3. 给矩形Q内的每一个像素赋值,A(xi,yi) = distance[ A(xi,yi), 直线A(x2,y2)A(x3,y3)] ;4. 将矩阵A按比例缩小为原图的1/4,得到germety map_2(长M/4,宽N/4)。
通道5:矩形位置germety map_3。
1. 生成一个大小MxN为全零矩阵A,M,N为原图的长和宽;2. 将矩形的四个顶点两两相连,形成一个矩形Q;3. 给矩形Q内的每一个像素赋值,A(xi,yi) = distance[ A(xi,yi), 直线A(x3,y3)A(x4,y4)] ;4. 将矩阵A按比例缩小为原图的1/4,得到germety map_3(长M/4,宽N/4)。
通道6:矩形位置germety map_4。
1. 生成一个大小MxN为全零矩阵A,M,N为原图的长和宽;2. 将矩形的四个顶点两两相连,形成一个矩形Q;3. 给矩形Q内的每一个像素赋值,A(xi,yi) = distance[ A(xi,yi), 直线A(x4,y4)A(x1,y1)] ;4. 将矩阵A按比例缩小为原图的1/4,得到germety map_4(长M/4,宽N/4)。
训练Loss:
loss由分数图损失(score map loss)和几何形状损失(geometry loss)两部分组成。分数图损失采用的是类平衡交叉熵,用于解决类别不平衡训练,具体实战中,一般采用dice loss,收敛速度更快。几何形状损失,针对RBOX loss采用IoU损失,针对QUAD loss采用smoothed-L1损失。本文中几何体数量较多,普通的NMS计算复杂度过高,EAST提出了基于行合并几何体的方法,locality-aware NMS。
为改进EAST的长文本检测效果不佳的缺陷,有人提出了Advanced EAST。Advanced EAST以VGG16作为网络结构的骨干,同样由特征提取层、特征合并层、输出层三部分构成,比EAST,尤其是在长文本上的检测准确性更好。
三. 文字识别
文字识别,根据待识别的文字特点一般分为定长文字、不定长文字两大类,前者(如:验证码识别)相对简单,这里不做分析。
1.【LSTM+CTC】
LSTM(Long Short Term Memory,长短期记忆网络)是一种特殊结构的RNN,用于解决RNN的随着输入信息的时间间隔不断增大,出现“梯度消失”或“梯度爆炸”的长期依赖问题。CTC(Connectionist Temporal Classifier,联接时间分类器),主要用于解决输入特征与输出标签的对齐问题。由于字符变形等原因,分块识别时,相邻块可能会识别为同个结果,字符重复出现。通过CTC来解决对齐问题,模型训练后,对结果中去掉间隔字符、去掉重复字符。

2.【CRNN】
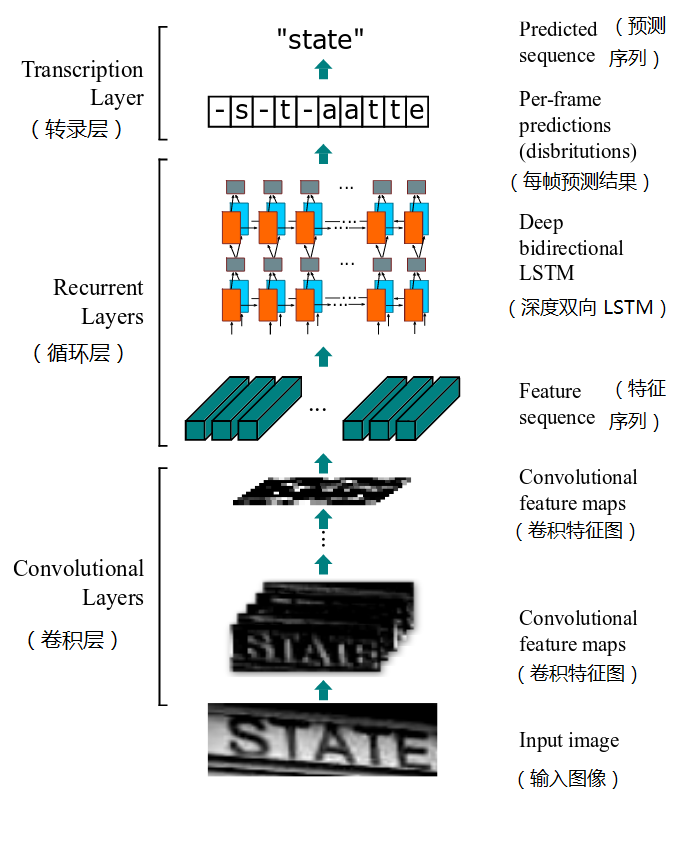
CRNN(Convolutional Recurrent Neural Network,卷积循环神经网络)是目前比较流行的文字识别模型,可以进行端到端的训练,不需要对样本数据进行字符分割,可识别任意长度的文本序列,模型速度快、性能好。

算法流程:
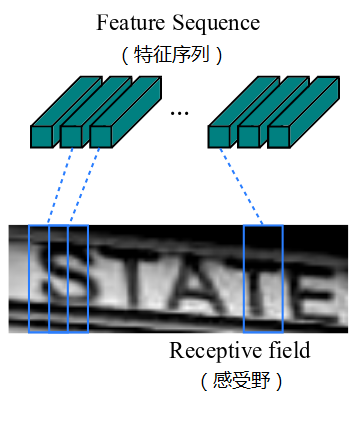
(1). 卷积层:从输入图像中提取出特征序列;
先做预处理,把所有输入图像缩放到相同高度,默认是32,宽度可任意长;然后进行卷积运算(由类似VGG的卷积、最大池化和BN层组成);再从左到右提取序列特征,作为循环层的输入,每个特征向量表示了图像上一定宽度内的特征,默认是单个像素1(由于CRNN已将输入图像缩放到同样高度了,因此只需按照一定的宽度提取特征即可)。
(2). 循环层:预测从卷积层获取的特征序列的标签分布;
循环层由一个双向LSTM构成,预测特征序列中的每一个特征向量的标签分布。由于LSTM需要时间维度,模型中把序列的width当作time steps。“Map-to-Sequence”层用于特征序列的转换,将误差从循环层反馈到卷积层,是卷积层和循环层之间的桥梁。
(3). 转录层:把从循环层获取的标签分布通过去重、整合等操作转换成最终的识别结果。
转录层是将LSTM网络预测的特征序列的结果进行整合,转换为最终输出的结果。在CRNN模型中双向LSTM网络层的最后连接上一个CTC模型,从而做到了端对端的识别。
四. 代码实现
CTPN:https://github.com/eragonruan/text-detection-ctpn
SegLink:https://github.com/dengdan/seglink
EAST:https://github.com/argman/EAST
AdvancedEAST:https://github.com/huoyijie/AdvancedEAST
CRNN:https://github.com/Belval/CRNN
五. Reference
https://my.oschina.net/u/876354
https://zhuanlan.zhihu.com/p/34757009
https://www.jianshu.com/p/109231be4a24
https://zhuanlan.zhihu.com/p/37781277
https://me.csdn.net/imPlok
OCR场景文本识别:文字检测+文字识别的更多相关文章
- CVPR2020论文解读:OCR场景文本识别
CVPR2020论文解读:OCR场景文本识别 ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗ 论文 ...
- 带你了解CANN的目标检测与识别一站式方案
摘要: 了解通用目标检测与识别一站式方案的功能与特性,还有实现流程,以及可定制点. 本文分享自华为云社区<玩转CANN目标检测与识别一站式方案>,作者: Tianyi_Li. 背景介绍 目 ...
- ocr 文字区域检测及识别
ocr 文字区域检测及识别 # coding=utf- from PIL import Image, ImageFilter, ImageEnhance from skimage.filters im ...
- OCR文字识别帮助录入文字信息
OCR文字识别是指将图片.照片上的文字内容,直接转换为可编辑文本的过程.目前各行各业不断地应用文字识别产品,解决文字录入工作的烦恼,提高工作效率. OCR文字识别用在哪里? 一个做社区工作的朋友透露, ...
- OpenCV_contrib里的Text(自然场景图像中的文本检测与识别)
平台:win10 x64 +VS 2015专业版 +opencv-3.x.+CMake 待解决!!!Issue说明:最近做一些字符识别的事情,想试一下opencv_contrib里的Text(自然场景 ...
- Android ocr识别文字介绍(文字识别)
最近在做身份证号码识别,在网上搜索的一番后发现目前开源的OCR中tesseract-ocr算是比较强大的了,它由HP于1985年到1995年间开发,后来由google直接负责,经过谷歌进一步开发后,目 ...
- 【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST)
文字识别分为两个具体步骤:文字的检测和文字的识别,两者缺一不可,尤其是文字检测,是识别的前提条件,若文字都找不到,那何谈文字识别.今天我们首先来谈一下当今流行的文字检测技术有哪些. 文本检测不是一件简 ...
- Windows下 训练Tesseract实现识别图片中的文字
介绍 Tesseract是一个基于Apache2.0协议开源的跨平台ocr引擎,支持多种语言的识别,在Windows和Linux上都有良好的支持. 源代码在这: 源码地址 有一个编译打包好的Windo ...
- C# 10分钟完成百度图片提取文字(文字识别)——入门篇
现在图片文字识别已经很成熟了,比如qq长按图片,点击图片识别就可以识别图片的文字,将不认识的.文字数量大的.或者不能赋值的值进行二次可复制功能. 我们现在就基于百度Ai开放平台进行个人文字识别,dem ...
随机推荐
- git commit撤回操作
git commit 之后没有push,怎么回撤commit操作呢? $ git reset HEAD~
- Codeforces Round#615 Div.3 解题报告
前置扯淡 真是神了,我半个小时切前三题(虽然还是很菜) 然后就开始看\(D\),不会: 接着看\(E\),\(dp\)看了半天,交了三次还不行 然后看\(F\):一眼\(LCA\)瞎搞,然后\(15m ...
- 作业:for循环,迭代法和穷举法
for()循环 四要素:初始条件,循环条件,状态改变,循环体. 执行过程:初始条件--循环条件--循环体 ...
- UTF虚拟对象
虚拟对象: 虚拟对象是为了让UFT识别某些不能识别的控件,把这些控件的范围定义为虚拟对象. 新建虚拟对象 管理虚拟对象 创建虚拟对象之后可通过菜单tools-Virutal Objects-Virut ...
- Qt Sleep、QCoreApplication::processEvents()(最佳的平衡:一边发送消息,一边睡眠)
sleep()//秒 msleep()//毫秒 usleep()//微秒 以前为了模拟鼠标点击用过这些函数,可以让进程中断,今天发现我原来的做法其实不对.这组函数会将你当前的线程/进程变为“睡眠”状态 ...
- go proxy转发工作中碰到的问题
A-B 需求是一个中转 A-Proxy-B 读取来源请求A,在proxy读取body作些处理,再转给B,再把返回内容转给A 问题出在proxy这里 如果先把请求给B,再读body res, err : ...
- 学习python-20191108(2)REST接口相关
一.客户登录验证 在使用接口前,需要对客户进行登录验证 enums.py文件代码: #定义枚举,客户端登录的方式有很多种形式:邮箱登录.手机登录.微信小程序登录.微信公众号登录 class Clien ...
- python-django框架-电商项目-购物车模块开发_20191125
python-django框架-电商项目-购物车模块开发 商品详情页js代码: 在商品详情页,有加入购物车按钮, 点击加减号可以增加减少,手动输入也可以, 点击加入购物车,就要加过去, 先实现加减的操 ...
- [LC] 84. Largest Rectangle in Histogram
Given n non-negative integers representing the histogram's bar height where the width of each bar is ...
- WebFilter 在springBoot工程中不起作用
[1]@ServletComponentScan 必须有一个注解将带有@WebFilter的类包含进去. [2]自定义 FiltersConfig extends WebMvcConfigurerAd ...