python字符串操作方法详解
字符串
字符串序列用于表示和存储文本,python中字符串是不可变对象。字符串是一个有序的字符的集合,用于存储和表示基本的文本信息,一对单,双或三引号中间包含的内容称之为字符串。其中三引号可以由多行组成,编写多行文本的快捷语法,常用文档字符串,在文件的特定地点,被当做注释。便捷的多行注释。
Python实际三类字符串:
1.通常意义字符串(str)
2.原始字符串,以大写R 或 小写r开始,r'',不对特殊字符进行转义
3.Unicode字符串,u'' basestring子类
python中字符串支持索引、切片操作。
根据python3.x的字符串源码文件可见,总共44个方法,查找列出如下:


| 方法 | 描述 |
|---|---|
|
把字符串的第一个字符大写 |
|
|
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
|
|
返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
|
|
以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除 非 errors 指 定 的 是 'ignore' 或 者'replace' |
|
|
以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
|
|
检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
|
|
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
|
|
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
|
|
跟find()方法一样,只不过如果str不在 string中会报一个异常. |
|
|
如果 string 至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
|
|
如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
|
|
如果 string 只包含十进制数字则返回 True 否则返回 False. |
|
|
如果 string 只包含数字则返回 True 否则返回 False. |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
|
|
如果 string 中只包含数字字符,则返回 True,否则返回 False |
|
|
如果 string 中只包含空格,则返回 True,否则返回 False. |
|
|
如果 string 是标题化的(见 title())则返回 True,否则返回 False |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
|
|
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
|
|
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
|
|
转换 string 中所有大写字符为小写. |
|
|
截掉 string 左边的空格 |
|
|
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
|
|
返回字符串 str 中最大的字母。 |
|
|
返回字符串 str 中最小的字母。 |
|
|
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
|
|
把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
|
|
类似于 find()函数,不过是从右边开始查找. |
|
|
类似于 index(),不过是从右边开始. |
|
|
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
|
|
string.rpartition(str) |
类似于 partition()函数,不过是从右边开始查找. |
|
删除 string 字符串末尾的空格. |
|
|
以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串 |
|
|
按照行分隔,返回一个包含各行作为元素的列表,如果 num 指定则仅切片 num 个行. |
|
|
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
|
|
在 string 上执行 lstrip()和 rstrip() |
|
|
翻转 string 中的大小写 |
|
|
返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
|
|
根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
|
|
转换 string 中的小写字母为大写 |
|
|
返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
|
|
isdecimal()方法检查字符串是否只包含十进制字符。这种方法只存在于unicode对象。 |
此表格参考了https://www.cnblogs.com/A-FM/p/5691468.html,主要因为它的方法点进去,有详细解释,借鉴过来,主要方便大家。
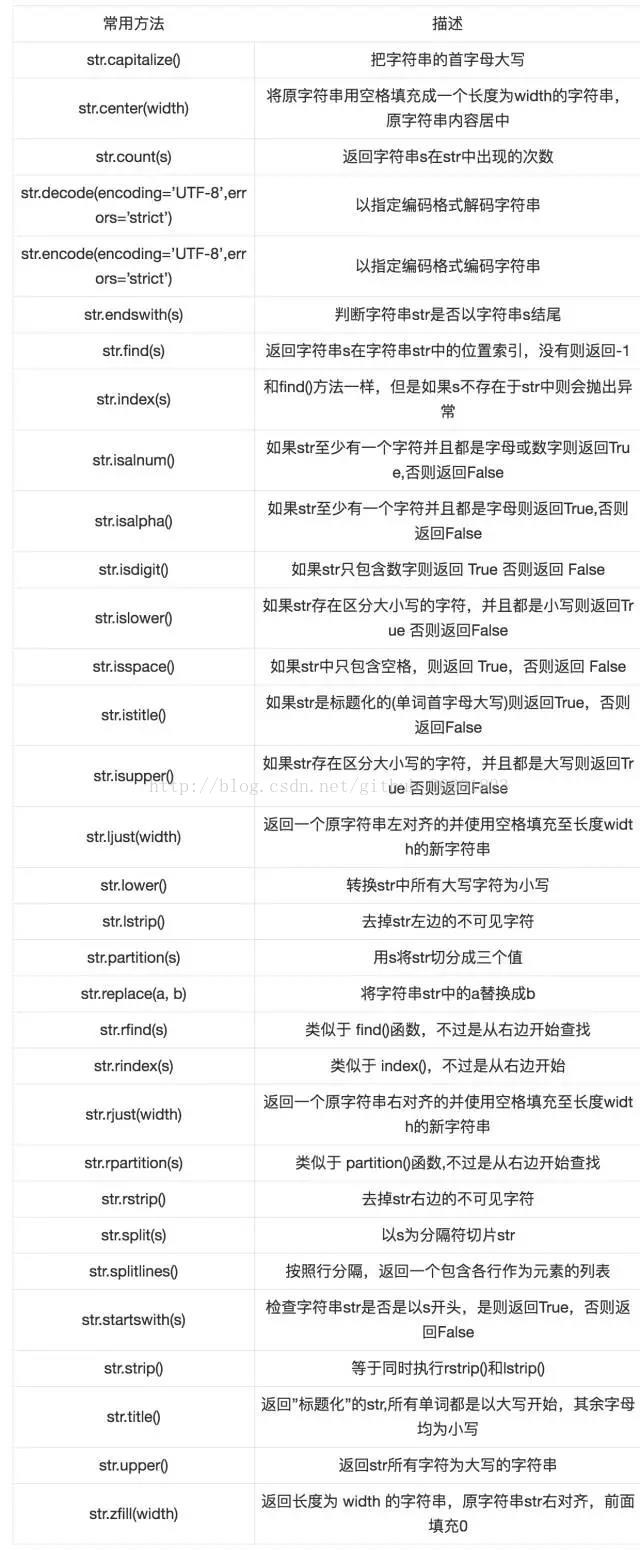
总结上面的用法,对其分个类,我们可以把字符串操作分为字符串的替换、删除、截取、复制、连接、比较、查找、分割等
但是,首先得判断这个对象是不是字符串,方法如下:
如何判断一个对象是不是字符串
python中字符串有两重,一种是str,一种是unicode。那如何判断一个对象是不是字符串呢?应该使用isinstance(s,basestring),而不是isinstance(s,str)。看下面例子
>>>a = 'hi' >>>isinstance(a,str) True >>>b = u'Hi' >>>isinstance(b,str) False >>>isinstance(b,basestring) True >>>isinstance(b,unicode) True >>>isinstance(a,unicode) False
要正确判读一个对象是不是字符串,要有basestring,因为basestring是str和unicode的基类,包含了普通字符串和unicode类型。
如何去掉字符串的双引号
a = '"string"' print(a,type(a)) b = eval(a) print(b,type(b)) 结果: "string" <class 'str'> string <class 'str'>
下面讲str对象的基本用法
字符串的基本用法可以分以下五类,即性质判定、查找替换、分切与连接、变形、填空与删减。
(a)性质判定
性质判定有以下几个方法。
isalnum():是否全是字母和数字,并至少有一个字符 isalpha():是否全是字母,并至少有一个字符 isdigit():是否全是数字,并至少有一个字符 islower():字符串中字母是否全是小写 isupper():字符串中字母是否全是小写 isspace():是否全是空白字符,并至少有一个字符 istitle():判断字符串是否每个单词都有且只有第一个字母是大写 startswith(prefix[,start[,end]]):用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返 回 False。如果参数 start 和 end 指定值,则在指定范围内检查。 endswith(suffix[,start[,end]]):用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。可选参数"start"与"end"为检索字符串的开始与结束位置。 is*()这些都比较简单,从字母的字面上就可以理解,*with()函数可以接受start和end参数,如果善加利用可以优化性能。另外,从python 2.5版本起,*with()函数族的第一个参数可接受tuple类型实参,当实参中某个元素匹配时,即返回True
(b)查找与替换
count(sub[,start[,end]]):统计字符串里某个字符sub出现的次数。可选参数为在字符串搜索的开始与结束位置。这个数值在调用replace方法时用得着。 find(sub[,start[,end]]):检测字符串中是否包含子字符串sub,如果指定start(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1 index(sub[,start[,end]]):跟find()方法一样,只不过如果sub不在 string中会抛出ValueError异常。 rfind(sub[,start[,end]]):类似于 find()函数,不过是从右边开始查找。 rindex(sub[,start[,end]]):类似于 index(),不过是从右边开始。 replace(old,new[,count]):用来替换字符串的某些子串,用new替换old。如果指定count参数话,就最多替换count次,如果不指定,就全部替换
前面五个方法都可以接受start、end参数,善加利用可以优化性能。对于查找某个字符串中是否有子串,不推荐使用index族和find族方法,推荐使用in和not in操作
(c)分切与连接
partition(sep):用来根据指定的分隔符将字符串进行分割,如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。如果sep没有出现在字符串中,则返回值为(sep,",")。partition() 方法是在2.5版中新增的。
rpartition(sep):类似于 partition()函数,不过是从右边开始查找.
splitness([keepends]):按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
split(sep[,maxsplit]]):通过指定分隔符对字符串进行切片,如果参数maxsplit 有指定值,则仅分隔 maxsplit 个子字符串,返回分割后的字符串列表。
rsplit(sep[,maxsplit]]):同split(),不过是从右边开始。
看下面例子
str1 = 'ab c\n\nde fg\rkl\r\n' print str1.splitlines(); str2 = 'ab c\n\nde fg\rkl\r\n' print str2.splitlines(True)
输出如下:
['ab c', '', 'de fg', 'kl'] ['ab c\n', '\n', 'de fg\r', 'kl\r\n']
split()函数有个小陷阱,比如对于字符串s,s.split()和s.split(" ")的返回值不同。看下面代码
s = " hello world"#前面有两个空格
print s.split()
print s.split(' ')
输出结果如下
['hello', 'world'] ['', '', 'hello', 'world']
这是为什么呢?原因在于:当忽略sep参数或者sep参数为None时与明确给sep赋予字符串值时,split()采用了两种不同的算法。对于前者,split()先除去两端的空白符,然后以任意长度的空白符串作为界定符分切字符串(即连续空白符串会被单一空白符看待);对于后者则认为两个两个连续空白符之间存在一个空字符串,因此对空字符串,它们的返回值也不同。
>>>".split()
[]
>>>''.split(' ')
['']
(d)变形
lower():转换字符串中所有大写字符为小写。 upper():将字符串中的小写字母转为大写字母。 capitalize():将字符串的第一个字母变成大写,其他字母变小写。对于 8 位字节编码需要根据本地环境。 swapcase():用于对字符串的大小写字母进行转换,大写转小写,小写转大写。 title():返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写。
这些都是大小写切换,title()并不能除去字符串两端的空白符也不会把连续空白符替换成一个空格,如果有这样的需求,可以用string模块的capwords(s)函数,它能除去两端空白符,并且能将连续的空白符用一个空格符代替。看下面例子:
#coding=utf-8 import string s = " hello world" print s.title() print string.capwords(s)
输出结果如下:
Hello World Hello World
(e)删减与填充
strip([chars]):用于移除字符串头尾指定的字符(默认为空格),如果有多个就会删除多个。
ltrip([chars]):用于截掉字符串左边的空格或指定字符。
rtrip([chars]):用于截掉字符串右边的空格或指定字符。
center(width[,fillchar]):返回一个原字符串居中,并使用fillchar填充至长度 width 的新字符串。默认填充字符为空格
ljust(width[,fillchar]):返回一个原字符串左对齐,并使用fillchar填充至指定长度的新字符串,默认为空格。如果指定的长度小于原字符串的长度则返回原字符串。
rjust(width[,fillchar]):返回一个原字符串右对齐,并使用fillchar填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。
zfill(width):返回指定长度的字符串,原字符串右对齐,前面填充0
expandtabs([tabsize]):把字符串中的 tab 符号('\t')转为适当数量的空格,默认情况下是转换为8个。
(f)字符串切片
切片操作(slice)可以从一个字符串中获取子字符串(字符串的一部分)。我们使用一对方括号、起始偏移量start、终止偏移量end 以及可选的步长step 来定义一个分片。
格式: [start:end:step]
- • [:] 提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串
- • [start:] 从start 提取到结尾
- • [:end] 从开头提取到end - 1
- • [start:end] 从start 提取到end - 1
- • [start:end:step] 从start 提取到end - 1,每step 个字符提取一个
- • 左侧第一个字符的位置/偏移量为0,右侧最后一个字符的位置/偏移量为-1
str = '0123456789′ print str[0:3] #截取第一位到第三位的字符 print str[:] #截取字符串的全部字符 print str[6:] #截取第七个字符到结尾 print str[:-3] #截取从头开始到倒数第三个字符之前 print str[2] #截取第三个字符 print str[-1] #截取倒数第一个字符 print str[::-1] #创造一个与原字符串顺序相反的字符串 print str[-3:-1] #截取倒数第三位与倒数第一位之前的字符 print str[-3:] #截取倒数第三位到结尾 print str[:-5:-3] #逆序截取,截取倒数第五位数与倒数第三位数之间<br>print str[::2] #按照步长为二,返回所有值
(g) maketrans和translate的用法
开发敏感词语过滤程序,提示用户输入内容,如果用户输入的内容中包含特殊的字符:
如:"苍老师"“东京热”,则将内容替换为***
sentence_input = input("请输入:")
sensitive_varcabulary1 = str.maketrans("苍老师",'***')
sensitive_varcabulary2 = str.maketrans("东京热",'***')
new_sentence = sentence_input.translate(sensitive_varcabulary1).translate(sensitive_varcabulary2)
print(new_sentence)
# 请输入:dads大大的苍老师
# dads大大的***
(h)字符串格式化(format)
用法:它通过 {} 和 : 代替传统的 % 方法
1,使用关键字参数
要点:关键字参数值要对得上,可用字典当关键字参数传入值,字典前加**即可
>>> hash = {'name':'hoho','age':18}
>>> 'my name is {name},age is {age}'.format(name='hoho',age=19)
'my name is hoho,age is 19'
>>> 'my name is {name},age is {age}'.format(**hash)
'my name is hoho,age is 18'
2,填充与格式化
:[填充字符][对齐方式 <^>][宽度]
'{:<20}'.format(10) #左对齐
'10 '
'{:>20}'.format(10) #右对齐
' 10'
'{:^20}'.format(10) #居中对齐
' 10 '
3,使用位置参数
要点:从以下例子可以看出位置参数不受顺序约束,且可以为{},只要format里有相对应的参数值即可,参数索引从0开,传入位置参数列表可用*列表
>>> li = ['hoho',18]
>>> 'my name is {} ,age {}'.format('hoho',18)
'my name is hoho ,age 18'
>>> 'my name is {1} ,age {0}'.format(10,'hoho')
'my name is hoho ,age 10'
>>> 'my name is {1} ,age {0} {1}'.format(10,'hoho')
'my name is hoho ,age 10 hoho'
>>> 'my name is {} ,age {}'.format(*li)
'my name is hoho ,age 18'
4,精度与进制
>>> '{0:.2f}'.format(1/3)
'0.33'
>>> '{0:b}'.format(10) #二进制
'1010'
>>> '{0:o}'.format(10) #八进制
'12'
>>> '{0:x}'.format(10) #16进制
'a'
>>> '{:,}'.format(12369132698) #千分位格式化
'12,369,132,698'
5,使用索引
>>> li
['hoho', 18]
>>> 'name is {0[0]} age is {0[1]}'.format(li)
'name is hoho age is 18
(i)常用字符串技巧
1,反转字符串
>>> s = '1234567890' >>> print s[::-1] 0987654321
2,关于字符串的拼接
尽量使用join()链接字符串,因为’+’号连接n个字符串需要申请n-1次内存,使用join()需要申请1次内存。
3,固定长度分割字符串
>>> import re
>>> s = '1234567890'
>>> re.findall(r'.{1,3}', s) # 已三个长度分割字符串
['123', '456', '789', '0']
4,使用()括号生成字符串
sql = ('SELECT count() FROM table '
'WHERE id = "10" '
'GROUP BY sex')
print sql
SELECT count() FROM table WHERE id = "10" GROUP BY sex
5,将print的字符串写到文件
>>> print >> open("somefile.txt", "w+"), "Hello World"
# Hello World将写入文件somefile.txt
string模块

| 方法 | 描述 |
| ascii_letters | 获取所有ascii码中字母字符的字符串(包含大写和小写) |
| ascii_uppercase | 获取所有ascii码中的大写英文字母 |
| ascii_lowercase | 获取所有ascii码中的小写英文字母 |
| digits | 获取所有的10进制数字字符 |
| octdigits | 获取所有的8进制数字字符 |
| hexdigits | 获取所有16进制的数字字符 |
| printable | 获取所有可以打印的字符 |
| whitespace | 获取所有空白字符 |
| punctuation | 获取所有的标点符号 |
python 如何从指定文件夹中读取csv文件格式
遍历文件夹,找到csv格式的文件
import os
Path_list = os.listdir(PathName0)
for name in Path_list:
if name.endswith('.csv'):
print(name)
python字符串操作方法详解的更多相关文章
- python 字符串操作方法详解
字符串序列用于表示和存储文本,python中字符串是不可变对象.字符串是一个有序的字符的集合,用于存储和表示基本的文本信息,一对单,双或三引号中间包含的内容称之为字符串.其中三引号可以由多行组成,编写 ...
- python 字典操作方法详解
字典是一种通过名字或者关键字引用的得数据结构,key 类型需要时被哈希,其键可以是数字.字符串.元组,这种结构类型也称之为映射.字典类型是Python中唯一內建的映射类型. 注意,浮点数比较很不精确, ...
- python 列表操作方法详解
列表是Python中最基本的数据结构,列表是最常用的Python数据类型,列表是一个数据的集合,集合内可以放任何数据类型,可对集合方便的增删改查操作.Python已经内置确定序列的长度以及确定最大和最 ...
- Python 字符串方法详解
Python 字符串方法详解 本文最初发表于赖勇浩(恋花蝶)的博客(http://blog.csdn.net/lanphaday),如蒙转载,敬请保留全文完整,切勿去除本声明和作者信息. ...
- python 集合操作方法详解
说集合之前,我们先说一个小例子,假设某公司有五个人喜欢打篮球,五个人喜欢打游戏,问即打游戏有打篮球 的人都有哪些? play_basketball = ['a','b','c','d','e'] pl ...
- Python字符串操作详解
菜鸟学Python第五天 流程控制 for循环 while循环 VS for循环: while循环:称之为条件循环,循环的次数取决于条件何时为false for循环:称之为迭代器循环,循环的次数取决于 ...
- python列表操作方法详解
列表 列表是Python中最基本的数据结构,列表是最常用的Python数据类型,列表是一个数据的集合,集合内可以放任何数据类型,可对集合方便的增删改查操作.Python已经内置确定序列的长度以及确 ...
- python字典操作方法详解
前言 字典是一种通过名字或者关键字引用的得数据结构,key 类型需要时被哈希,其键可以是数字.字符串.元组,这种结构类型也称之为映射.字典类型是Python中唯一內建的映射类型. 注意,浮点数比较很不 ...
- Python - 字符串格式化详解(%、format)
Python在字符串格式化的两种方式 % format %,关于整数的输出 %o:oct 八进制%d:dec 十进制%x:hex 十六进制 print("整数:%d,%d,%d" ...
随机推荐
- java1.8特性
java1.8特性 1.lambda表达式 Java8为集合类引入了另一个重要概念:流(stream).一个流通常以一个集合类实例为其数据源,然后在其上定义各种操作 例如 .filter .forEa ...
- 前端知识之css
css的几种引入方式 行内样式 行内式是在标记的style属性中设定css样式,不推荐大规模使用 <p style='color:red'>hello world</p> 内部 ...
- NAT ALG原理与应用
1 NAT ALG简介 普通NAT实现了对UDP或TCP报文头中的的IP地址及端口转换功能,但对应用层数据载荷中的字段无能为力,在许多应用层协议中,比如多媒体协议(H.323.SIP等).FTP.S ...
- 寒假安卓app开发学习记录(5)
第一个项目运行成功! 今天主要是看视频 ,学习Android项目的目录结构.大概学习了一个小时左右.然后在网上学习和对比eclipse上的目录,了解每个目录的功能是什么. 了解了Android项目的目 ...
- bit Buffer
在音频流解析过程中,常常会涉及到顺序读取某些bit的操作. #include<stdio.h> typedef struct _BIT_BUF { unsigned char buffer ...
- 【Python】字符串(String)
python中单引号和双引号使用完全相同. 使用三引号('''或""")可以指定一个多行字符串. 转义符 '\' 反斜杠可以用来转义,使用r可以让反斜杠不发生转义.. 如 ...
- 【WPF学习】第十四章 事件路由
由上一章可知,WPF中的许多控件都是内容控件,而内容控件可包含任何类型以及大量的嵌套内容.例如,可构建包含图形的按钮,创建混合了文本和图片内容的标签,或者为了实现滚动或折叠的显示效果而在特定容器中放置 ...
- JS高级---利用原型共享数据
什么样子的数据是需要写在原型中? 需要共享的数据就可以写原型中 原型的作用之一: 数据共享 //属性需要共享, 方法也需要共享 //不需要共享的数据写在构造函数中,需要共享的数据写在原型中 //构造函 ...
- stopWatch 用法
package com.example.stopwatch; import org.springframework.util.StopWatch; public class TestStopWatch ...
- java编译器不匹配问题(java compiler level does not match the version of the installed java project facet)
问题:项目经常copy过来,经常会报说Java编译器不匹配 解决方法:找到项目所在的目录,在.settings子目录里面,用文本编辑器打开org.eclipse.wst.common.project. ...