CTR学习笔记&代码实现4-深度ctr模型 NFM/AFM
这一节我们总结FM另外两个远亲NFM,AFM。NFM和AFM都是针对Wide&Deep 中Deep部分的改造。上一章PNN用到了向量内积外积来提取特征交互信息,总共向量乘积就这几种,这不NFM就带着element-wise(hadamard) product来了。AFM则是引入了注意力机制把NFM的等权求和变成了加权求和。
以下代码针对Dense输入感觉更容易理解模型结构,针对spare输入的代码和完整代码
https://github.com/DSXiangLi/CTR
NFM
NFM的创新点是在wide&Deep的Deep部分,在Embedding层和全联接层之间加入了BI-Pooling层,也就是Embedding两两做element-wise乘积得到 \(N*(N-1)/2\)个 \(1*K\)的矩阵然后做sum_pooling得到最终\(1*k\)的矩阵。
Deep部分的模型结构如下

和其他模型的联系
NFM不接全连接层,直接weight=1输出就是FM,所以NFM可以在FM上学到更高阶的特征交互。
有看到一种说法是DeepFM是FM和Deep并联,NFM是把FM和Deep串联,也是可以这么理解,但感觉本质是在学习不同的信息,把FM放在wide侧是帮助学习二阶‘记忆特征’,把FM放在Deep侧是帮助学习高阶‘泛化特征’。
NFM和PNN都是用向量相乘的方式来帮助全联接层提炼特征交互信息。虽然一个是element-wise product一个是inner product,但区别其实只是做sum_pooling时axis的差异。 IPNN是在k的axis上求和得到\(N^2\)个scaler拼接成输入, 而NFM是在\(N^2\)的axis上求和得到\(1*K\)的输入。
下面这个例子可以比较直观的比较一下FM,NFM,IPNN对Embedding的处理(为了简单理解给了Embedding简单数值)
NFM几个想吐槽的点
- 和FNN,PNN一样对低阶特征的提炼比较有限
- 这个sum_pooling同样会存在信息损失,不同的特征交互对Target的影响不同,等权加和一定不是最好的方法,但也算是为特征交互提供了一种新方法
代码实现
@tf_estimator_model
def model_fn_dense(features, labels, mode, params):
dense_feature, sparse_feature = build_features()
dense = tf.feature_column.input_layer(features, dense_feature)
sparse = tf.feature_column.input_layer(features, sparse_feature)
field_size = len( dense_feature )
embedding_size = dense_feature[0].variable_shape.as_list()[-1]
embedding_matrix = tf.reshape( dense, [-1, field_size, embedding_size] ) # batch * field_size *emb_size
with tf.variable_scope('Linear_output'):
linear_output = tf.layers.dense( sparse, units=1 )
add_layer_summary( 'linear_output', linear_output )
with tf.variable_scope('BI_Pooling'):
sum_square = tf.pow(tf.reduce_sum(embedding_matrix, axis=1), 2)
square_sum = tf.reduce_sum(tf.pow(embedding_matrix, 2), axis=1)
dense = tf.subtract(sum_square, square_sum)
add_layer_summary( dense.name, dense )
dense = stack_dense_layer(dense, params['hidden_units'],
dropout_rate = params['dropout_rate'], batch_norm = params['batch_norm'],
mode = mode, add_summary = True)
with tf.variable_scope('output'):
y = linear_output + dense
add_layer_summary( 'output', y )
return y
AFM
AFM和NFM同样使用element-wise product来提取特征交互信息,和NFM直接等权重做pooling不同的是,AFM增加了一层Attention Layer来学习pooling的权重。
Deep部分的模型结构如下
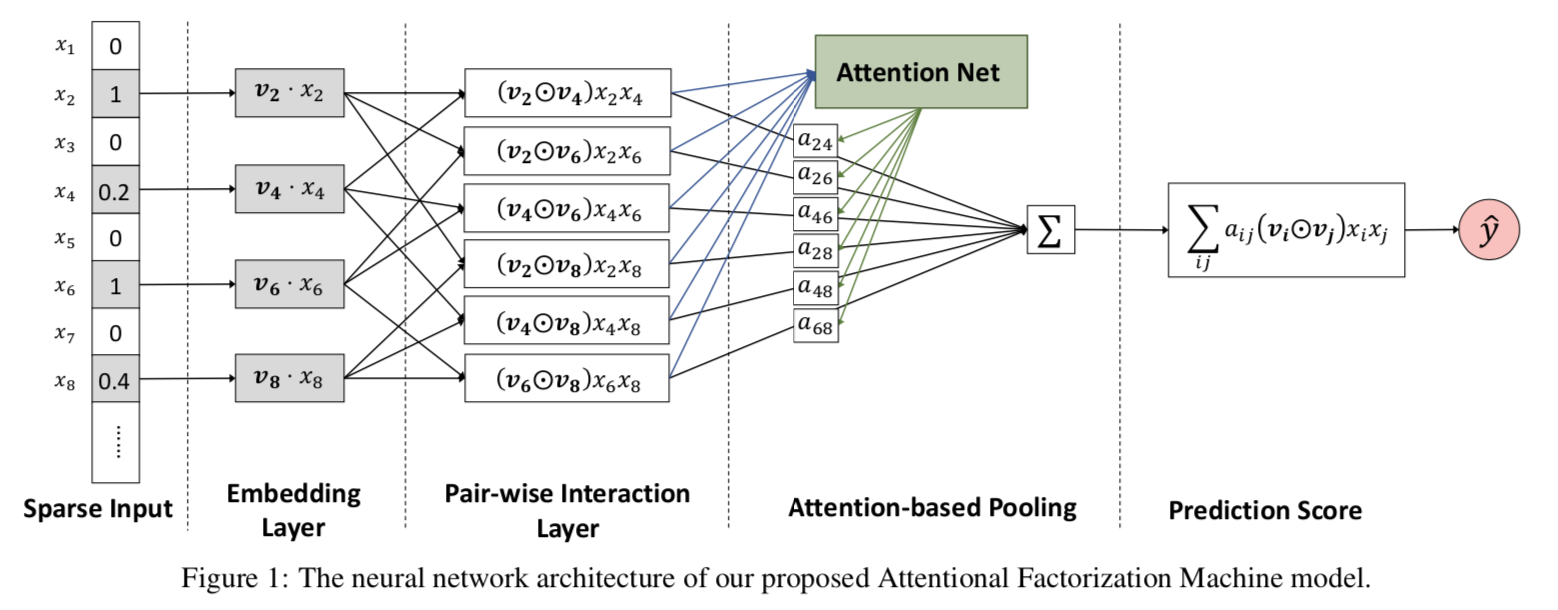
注意力部分是一个简单的全联接层,输出的是\(N(N-1)/2\)的矩阵,作为sum_pooling的权重向量,对element-wise特征交互向量进行加权求和。加权求和的向量直接连接output,不再经过全联接层。如果权重为1,那AFM和不带全联接层的NFM是一样滴。
AFM几个想吐槽的点
- 不带全联接层会导致高级特征表达有限,不过这个不重要啦,AFM更多还是为特征交互提供了Attention的新思路
代码实现
@tf_estimator_model
def model_fn_dense(features, labels, mode, params):
dense_feature, sparse_feature = build_features()
dense = tf.feature_column.input_layer(features, dense_feature) # lz linear concat of embedding
sparse = tf.feature_column.input_layer(features, sparse_feature)
field_size = len( dense_feature )
embedding_size = dense_feature[0].variable_shape.as_list()[-1]
embedding_matrix = tf.reshape( dense, [-1, field_size, embedding_size] ) # batch * field_size *emb_size
with tf.variable_scope('Linear_part'):
linear_output = tf.layers.dense(sparse, units=1)
add_layer_summary( 'linear_output', linear_output )
with tf.variable_scope('Elementwise_Interaction'):
elementwise_list = []
for i in range(field_size):
for j in range(i+1, field_size):
vi = tf.gather(embedding_matrix, indices=i, axis=1, batch_dims=0,name = 'vi') # batch * emb_size
vj = tf.gather(embedding_matrix, indices=j, axis=1, batch_dims=0,name = 'vj')
elementwise_list.append(tf.multiply(vi,vj)) # batch * emb_size
elementwise_matrix = tf.stack(elementwise_list) # (N*(N-1)/2) * batch * emb_size
elementwise_matrix = tf.transpose(elementwise_matrix, [1,0,2]) # batch * (N*(N-1)/2) * emb_size
with tf.variable_scope('Attention_Net'):
# 2 fully connected layer
dense = tf.layers.dense(elementwise_matrix, units = params['attention_factor'], activation = 'relu') # batch * (N*(N-1)/2) * t
add_layer_summary( dense.name, dense )
attention_weight = tf.layers.dense(dense, units=1, activation = 'softmax') # batch *(N*(N-1)/2) * 1
add_layer_summary( attention_weight.name, attention_weight)
with tf.variable_scope('Attention_pooling'):
interaction_output = tf.reduce_sum(tf.multiply(elementwise_matrix, attention_weight), axis=1) # batch * emb_size
interaction_output = tf.layers.dense(interaction_output, units=1) # batch * 1
with tf.variable_scope('output'):
y = interaction_output + linear_output
add_layer_summary( 'output', y )
return y
CTR学习笔记&代码实现系列
https://github.com/DSXiangLi/CTR
CTR学习笔记&代码实现1-深度学习的前奏LR->FFM
CTR学习笔记&代码实现2-深度ctr模型 MLP->Wide&Deep
CTR学习笔记&代码实现3-深度ctr模型 FNN->PNN->DeepFM
资料
- Jun Xiao, Hao Ye ,2017, Attentional Factorization Machines - Learning the Weight of Feature Interactions via Attention Networks
- Xiangnan He, Tat-Seng Chua,2017, Neural Factorization Machines for Sparse Predictive Analytics
- https://zhuanlan.zhihu.com/p/86181485
CTR学习笔记&代码实现4-深度ctr模型 NFM/AFM的更多相关文章
- CTR学习笔记&代码实现3-深度ctr模型 FNN->PNN->DeepFM
这一节我们总结FM三兄弟FNN/PNN/DeepFM,由远及近,从最初把FM得到的隐向量和权重作为神经网络输入的FNN,到把向量内/外积从预训练直接迁移到神经网络中的PNN,再到参考wide& ...
- CTR学习笔记&代码实现5-深度ctr模型 DeepCrossing -> DCN
之前总结了PNN,NFM,AFM这类两两向量乘积的方式,这一节我们换新的思路来看特征交互.DeepCrossing是最早在CTR模型中使用ResNet的前辈,DCN在ResNet上进一步创新,为高阶特 ...
- CTR学习笔记&代码实现6-深度ctr模型 后浪 xDeepFM/FiBiNET
xDeepFM用改良的DCN替代了DeepFM的FM部分来学习组合特征信息,而FiBiNET则是应用SENET加入了特征权重比NFM,AFM更进了一步.在看两个model前建议对DeepFM, Dee ...
- CTR学习笔记&代码实现2-深度ctr模型 MLP->Wide&Deep
背景 这一篇我们从基础的深度ctr模型谈起.我很喜欢Wide&Deep的框架感觉之后很多改进都可以纳入这个框架中.Wide负责样本中出现的频繁项挖掘,Deep负责样本中未出现的特征泛化.而后续 ...
- CTR学习笔记&代码实现1-深度学习的前奏LR->FFM
CTR学习笔记系列的第一篇,总结在深度模型称王之前经典LR,FM, FFM模型,这些经典模型后续也作为组件用于各个深度模型.模型分别用自定义Keras Layer和estimator来实现,哈哈一个是 ...
- GIS案例学习笔记-明暗等高线提取地理模型构建
GIS案例学习笔记-明暗等高线提取地理模型构建 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 目的:针对数字高程模型,通过地形分析,建立明暗等高线提取模型,生成具有 ...
- 【PyTorch深度学习】学习笔记之PyTorch与深度学习
第1章 PyTorch与深度学习 深度学习的应用 接近人类水平的图像分类 接近人类水平的语音识别 机器翻译 自动驾驶汽车 Siri.Google语音和Alexa在最近几年更加准确 日本农民的黄瓜智能分 ...
- [原创]java WEB学习笔记44:Filter 简介,模型,创建,工作原理,相关API,过滤器的部署及映射的方式,Demo
本博客为原创:综合 尚硅谷(http://www.atguigu.com)的系统教程(深表感谢)和 网络上的现有资源(博客,文档,图书等),资源的出处我会标明 本博客的目的:①总结自己的学习过程,相当 ...
- cips2016+学习笔记︱简述常见的语言表示模型(词嵌入、句表示、篇章表示)
在cips2016出来之前,笔者也总结过种类繁多,类似词向量的内容,自然语言处理︱简述四大类文本分析中的"词向量"(文本词特征提取)事实证明,笔者当时所写的基本跟CIPS2016一 ...
随机推荐
- Java 为 Excel 中的行设置交替背景色
在制作Excel表格时,通过将数据表中上下相邻的两行用不同的背景色填充,可以使各行的数据看起来更清楚,避免看错行,同时也能增加Excel表格的美观度.本文将介绍如何在Java程序中为 Excel 奇数 ...
- Docker常用yml
GitLib version: '3.1' services: web: image: 'twang2218/gitlab-ce-zh:11.0.5' restart: always hostname ...
- web页面调用支付宝支付
web页面调用支付宝支付 此文章是前端单独模拟完成支付,若在线上环境则需要后台配合产生签名等参数 在蚂蚁金服开放平台申请沙箱环境 将沙箱环境中的密钥.应用网关.回调地址补全,生成密钥的方法在此 配置好 ...
- Java内存可见性volatile
概述 JMM规范指出,每一个线程都有自己的工作内存(working memory),当变量的值发生变化时,先更新自己的工作内存,然后再拷贝到主存(main memory),这样其他线程就能读取到更新后 ...
- .Net微服务实践(四)[网关]:Ocelot限流熔断、缓存以及负载均衡
目录 限流 熔断 缓存 Header转化 HTTP方法转换 负载均衡 注入/重写中间件 后台管理 最后 在上篇.Net微服务实践(三)[网关]:Ocelot配置路由和请求聚合中我们介绍了Ocelot的 ...
- Nginx知多少系列之(五)Linux下托管.NET Core项目
目录 1.前言 2.安装 3.配置文件详解 4.Linux下托管.NET Core项目 5.Linux下.NET Core项目负载均衡 6.Linux下.NET Core项目Nginx+Keepali ...
- 从一个慢查询到MySQL字符集编码
从一个慢查询到MySQL字符集编码 目录 从一个慢查询到MySQL字符集编码 1. 问题起源 2. MySQL字符集和字符集排序规则 2.1 字符集相关概念 2.2 MySQL中的字符集和字符集排序规 ...
- PHP中嵌入正则表达式常用的函数
PHP中嵌入正则表达式常用的函数有四个: 1.preg_match() :preg_match() 函数用于进行正则表达式匹配,成功返回 1 ,否则返回 0 . 语法:int preg_match( ...
- matplotlib Transform
2020-04-09 15:09:02 -- Edit by yangray Transform 类是TransformNode的子类,它是所有执行变换的TransformNode的实例的基类.所有非 ...
- public、private、protected继承区别