FastText的内部机制
文章来源:https://towardsdatascience.com/fasttext-under-the-hood-11efc57b2b3
译者 | Revolver
fasttext是一个被用于对词向量和句子分类进行高效学习训练的工具库,采用c++编写,并支持训练过程中的多进程处理。你可以使用这个工具在监督和非监督情况下训练单词和句子的向量表示。这些训练出来的词向量,可以应用于许多处理数据压缩的应用程序,或者其他模型的特征选择,或者迁移学习的初始化。
FastText支持使用negative sampling,softmax或层次softmax损失函数等方法来训练CBOW或Skip-gram模型。我已经使用了fastText对一个规模有千万个单词的语料库进行语义词向量训练,对于它的表现以及它对原任务的扩展,我都感到非常满意。在此之前,我很难找到除了 getting started之外的关于fasttext的相关说明文档,因此在这篇文章中,我将带您了解fastText的内部原理以及它是如何工作的。对word2vec模型如何工作的理解是需要的,克里斯·麦考密克的文章(见链接)很好地阐述了word2vec模型。
一、运行fasttext
我们可以通过下面这条命令来用fastText训练一个Skip-gram模型:
$ fasttext skipgram -input data.txt -output model
data.txt是一个包含一串文本序列的输入文件,输出模型保存在model.bin文件下,词向量则保存在model.vec中。
二、表示方法
fasttext可以在词向量的训练和句子分类上取得非常好的表现,尤其表现在对罕见词进行了字符粒度上的处理。
每个单词除了单词本身外还被表示为多个字符级别的n-grams(有时也称为N元模子)。例如,对于单词matter,当n = 3时,fasttext对该词对字符ngram就表示为<ma, mat, att, tte, ter, er>。其中<和>是作为边界符号被添加,来将一个单词的ngrams与单词本身区分开来。再举个例子,如果单词mat属于我们的词汇表,则会被表示为<mat>。这么做刚好让一些短词以其他词的ngram出现,有助于更好学习到这些短词的含义。从本质上讲,这可以帮助你捕捉后缀/前缀的含义。
可以通过-minn和-maxn这两个参数来控制ngrams的长度,这两个标志分别决定了ngrams的最小和最大字符数,也即控制了ngrams的范围。这个模型被认为是一个词袋模型,因为除了用于选择n-gram的滑动窗口外,它并没有考虑到对单词的内部结构进行特征选择。它只要求字符落在窗口以内,但并不关心ngrams的顺序。你可以将这两个值都设为0来完全关闭n-gram,也就是不产生n-gram符号,单纯用单词作为输入。当您的模型中的“单词”不是特定语言的单词时或者说字符级别的n-gram没有意义的时候,这会变得很有用。最常见的例子是当您将id作为您的单词输入。在模型更新期间,fastText会学习到每个ngram以及整个单词符号的权重。
三、读取数据
虽然fastText的训练是多线程的,但是读取数据却是通过单线程来完成。而文本解析和分词则在读取输入数据时就被完成了。让我们来看看具体是怎么做到的:
FastText通过-input参数获取一个文件句柄用于输入数据。FastText不支持从stdin读取数据,它初始化两个向量word2int_和words_来跟踪输入信息。word2int_是一个字符串到数值的映射集,索引键是单词字符串,根据字符串哈希值可以得到一个数值作为它的值,同时这个数值恰好就对应到了words_数组(std:::vector)的索引。words_ 数组在读取输入时根据单词出现的顺序递增创建索引,每个索引对应的值是一个结构体entry,这个entry封装了单词的所有信息。条目包含以下信息:
struct entry {
std::string word;
int64_t count;
entry_type type;
std::vector<int32_t> subwords;
};
在这个entry里,word是单词的字符串表示形式,count是各个单词在输入序列里的出现频次,entry_type的值是word或label中的一个,label选项仅在有监督情况下有效。所有的输入符号,包括entry_type都存储在同一个词典中,这使得扩展fastText来包含其他类型的实体变得更加容易(我将在后续的文章中详细讨论这一点)。最后,subword是一个包含一个单词所有的n-grams的向量。这个subword也会在读取输入数据时被创建,然后被传递到训练过程中。
word2int_的大小为MAX_VOCAB_SIZE = 30000000,这是一个硬编码的数字。当在大型语料库上进行训练时,这个大小可以是受限制的,但也可以在保持性能的同时有效地增加。word2int_数组的索引是由字符串得到的整数哈希值,并且是0和MAX_VOCAB_SIZE之间的唯一数字。如果出现哈希冲突,得到的哈希值已经存在,那么这个值就会增加,直到我们找到一个唯一的id来分配给一个单词为止。
因此,一旦词汇表的大小达逼近MAX_VOCAB_SIZE,算法性能就会显著下降。为了防止这种情况,每当哈希值的大小超过MAX_VOCAB_SIZE的75%时,fastText就会对词汇表进行删减。删减过程是这样的,首先增加单词最小计数阈值来重新确定一个单词是否有资格出现在单词表里,然后对词典里所有计数小于这个的单词进行删减。当添加一个新单词时,会检查这个单词对应的哈希值是否超过75%阈值,因此这种自动删减可以在文件读取过程的任何阶段进行。
除了自动删减过程,对于已经存在于词汇表里的单词的最小计数是通过使用-minCount和-minCountLabel(用于监督训练)这两个参数来控制的。基于这两个参数的删减在整个训练文件被处理之后进行。如果单词表的总数已经触发了前面所说的因哈希值太大发生的自动删减,那么您的词典可能就需要手动设置一个较高值的minCount阈值了。但无论如何,你都必须手动指定minCount阈值,才能确保较低词频的单词不会被用作输入的一部分。
在求解负采样损失函数过程中,一个大小NEGATIVE_TABLE_SIZE = 10000000的负采样单词表会被构造。注意它的大小是MAX_VOCAB_SIZE的三分之一。该表是从每个词词频的平方根的一元模型分布(unigram distribution)中进行采样构造的,这确保了每个词出现在负采样单词表中的次数与它的频率的平方根成正比。接着再对该表打乱词序以确保其随机性。
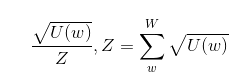
图一 U(w)是一个特定单词的计数,W是所有单词计数的集合
接下来,一个用于删除高频词的采样表会被构建,这个表在the original word2vec extension paper这篇论文的2.3节中有大概描述。这背后的思想是,高频词所能提供的信息比罕见的单词更少,而且高频词即使在遇见到更多相同单词的实例后,它们的词向量也不会发生太大的变化。
该论文提出了一种删除训练词的方法,通过下面公式计算训练词被丢弃的概率:克里斯·麦考密克
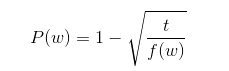
图二 t为所选阈值,f(w)为单词w的出现频率
作者认为t = 10e-5是一个较为合理的默认值。该公式丢弃了丢弃频率大于阈值的词,并在有效对低频词进行采样的同时又保持了它们的相对频率,从而抑制了高频词的夸大作用。
但另一方面,FastText又重新定义了这种分布。
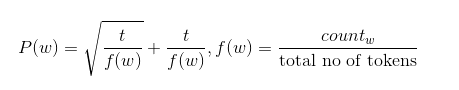
图三 t = 10e-4为所选阈值,f(w)为单词w的出现频率
默认的阈值可以通过 -t 手动设置。阈值t在fastText中的含义和最初的word2vec论文中的含义有所不同,你应该针对自己的应用程序进行调优。
在训练阶段,只有当从(0,1)的均匀分布中随机抽取一个值的大小大于单词被丢弃的概率时,该单词才会被丢弃。下面是在默认阈值情况下,单词被丢弃概率与词频f(w)的关系。如图所示,随着单词频率的增加,被抽到的概率大于被丢弃的概率P(w)的概率增加。因此,随着单词频率的增加,被丢弃的概率也增加。注意这只适用于无监督模型,在有监督模型中,单词不会被丢弃。
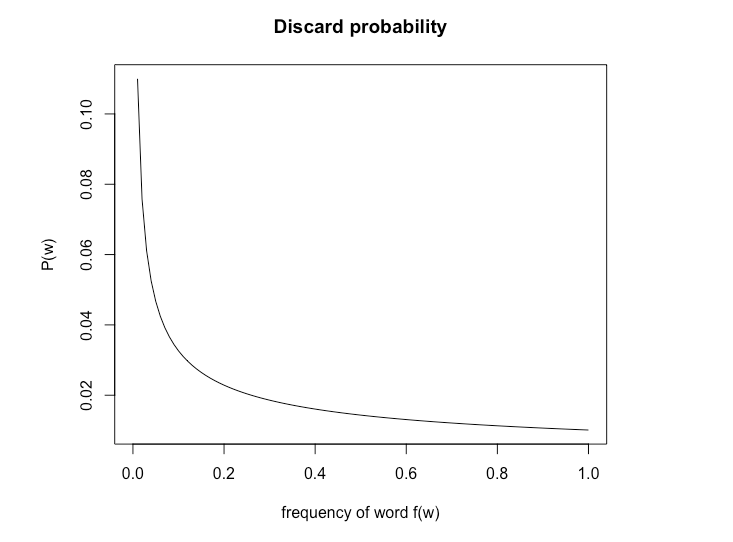
图四 fasttext中默认阈值下单词被丢弃概率与词频f(w)的关系
如果我们用-pretrainedVectors参数初始化训练,输入文件中的值将被用于初始化输入层向量。如果未指定,一个维度MxN的矩阵将会被创建,其中M = MAX_VOCAB_SIZE + bucket_size, N = dim。 bucket_size是一个数组的长度大小,这个数组是为所有的ngrams符号分配的。它通过-bucket标志进行设置,默认设置为2000000。
所有的ngrams在矩阵里的位置信息是通过取得ngram字符串的哈希值(同一个哈希函数)来进行初始化的,并将对该哈希值取模之后的值填到初始化后的矩阵中,其位置对应到MAX_VOCAB_SIZE + hash。注意到在ngrams空间中可能存在哈希冲突,但对于原始单词来说则是不存在这种情况。这也会影响到模型的性能。
Dim表示训练中隐藏层的维度,因此词向量的维度可以通过-dim参数进行设置,默认值为100。矩阵的每个值被初始化为0到1/dim之间的均匀实数分布。
四、训练
一旦输入层和隐藏层向量被初始化成功,多个训练线程就会启动。线程数量由-thread参数指定。所有训练线程都共享一个指向输入层和隐藏层向量矩阵的指针。所有线程都从输入文件中读取数据,并使用读取到的每一行来更新模型,其实也就相当于批次大小为1的随机梯度下降法。如果遇到换行字符,或者读入的单词数量超过允许的行最大数量,则会截断该行的后续输入。这里通过MAX_LINE_SIZE设置,默认值为1024。
CBOW模型和Skip-gram模型都会同时对一段上下文文本的权重进行更新,这段文本的单词数量是1到-ws(参数设置)之间的随机均匀分布,也就是说窗口大小是随机的。
损失函数的目标向量是这样计算的,先对每个输入向量作归一化计算,再把归一化后的所有向量求和可得。输入向量是原始单词以及该词的所有ngrams的向量表示。通过计算这个损失函数,可以在前向传播的过程中设置权重,然后又一路将影响反向传播传递到输入层的向量。在反向传播过程中对输入向量权重的调整帮助我们学到了使得共现相似性(co occurrence similarity)最大化的词向量。学习速率参数-lr会决定每条特定的实例样本对权重的影响究竟有多大。
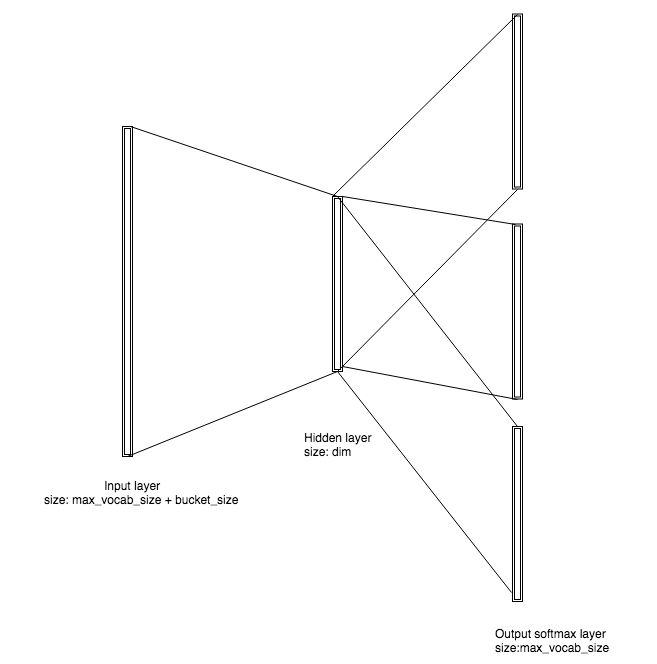
图五 无监督Skip-gram fastText模型的拓扑结构
模型的输入层权重、隐藏层权重以及传入的参数都会保存在.bin格式的文件中,-saveOutput标志控制了是否输出一个包含隐藏层向量的word2vec文件格式的.vec文件。
我希望这篇文章能帮助我们了解fasttext的内部工作原理。我个人已经通过使用这个库取得了很多成功,并强烈推荐你用它去解决你的问题。在下一篇文章中,我将讨论我为fastText添加的一些可以泛化它的能力的附加功能。敬请继续关注。
FastText的内部机制的更多相关文章
- ThreadLocal内部机制及使用方法
一.介绍ThreadLocal内部机制之前,先简单说明一下其特点及用途: 1.ThreadLocal是单线程内共享资源,多线程间无法共享(即线程A访问不了线程B中ThreadLocal存放的值): 2 ...
- 搭建高可用mongodb集群(三)—— 深入副本集内部机制
在上一篇文章<搭建高可用mongodb集群(二)—— 副本集> 介绍了副本集的配置,这篇文章深入研究一下副本集的内部机制.还是带着副本集的问题来看吧! 副本集故障转移,主节点是如何选举的? ...
- SQL Server 内存中OLTP内部机制概述(四)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- SQL Server 内存中OLTP内部机制概述(三)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- SQL Server 内存中OLTP内部机制概述(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- SQL Server 内存中OLTP内部机制概述(一)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- LocalActivityManager的内部机制
LocalActivityManager内部机制的核心在于,它使用了主线程对象mActivityThread来装载指定的Activity.注意,这里是装载,而不是启动,这点很重要. 所谓的启动,一般是 ...
- new和instanceof的内部机制
new和instanceof的内部机制 首先我们来看看obj = new o()这条语句发生了什么: var obj = (function(){ var obj = {}; obj.__proto_ ...
- zookeeper 内部机制学习
zookeeper 内部机制学习 1. zk的设计目标 最终一致性:client不论连接到那个Server,展示给它的都是同一个视图. 可靠性:具有简单.健壮.良好的性能.如果消息m被到一台服务器接收 ...
随机推荐
- ajax+lazyload时lazyload失效问题及解决
最近写公司的项目的时候遇到一个关于图片加载的问题,所做的页面是一个商城的商品列表页,其中需要显示商品图片,名称等信息,因为商品列表可能会很长,所以其中图片需要滑到可以显示的区域再进行加载. 首先我的图 ...
- Spring Cloud Feign 优雅的服务调用
Fegin 是由NetFlix开发的声明式.模板化HTTP客户端,可用于SpringCloud 的服务调用.提供了一套更优雅.便捷的HTTP调用API,并且SpringCloud整合了Fegin.Eu ...
- Keras在MNIST实现LeNet-5模型训练时的错误?
当使用Keras API 训练模型时,训练时报错? UnknownError (see above for traceback): Failed to get convolution algorith ...
- Cake URAL - 1755
1755. Cake Time limit: 0.5 secondMemory limit: 64 MB Karlsson and Little Boy have found a cake in th ...
- Centos7 U盘安装
以下内容来自 https://www.cnblogs.com/Hello-java/p/8628917.html 和 https://blog.csdn.net/fiiber/article/deta ...
- 22 Specifications动态查询
Specifications动态查询 有时我们在查询某个实体的时候,给定的条件是不固定的,这时就需要动态构建相应的查询语句,在Spring Data JPA中可以通过JpaSpecificationE ...
- 【Python challenge】通关代码及攻略(0-11)
前言: 最近找到一个有关python的游戏闯关,这是游戏中的思考及通关攻略 最开始位于:http://www.pythonchallenge.com/pc/def/0.html 第0关 题目分析 提示 ...
- 上线前测试的bug,要不要处理,跟版本的关系
最近有两个项目是在旧版本上实施的.上线前经过一轮测试后,发现了一些产品(我们的产品确实不稳定) 在这个项目上,修改产品bug是肯定的.但是要不要追踪这些bug? 这就跟版本使用范围有关系了,毕竟要考虑 ...
- Pocket+Evernote 打造个人知识库体系
俗话说巧妇难为无米之炊,还是那个不太恰当的例子. 写作就好比人类的消化系统,想要持续的输出...那么就要持续的输入... 今天就来说一说如何进行持续有效的输入. 信息处理过程 先放一张图,这是我的整个 ...
- .net webapi 接收保存图片到服务器,并居中剪裁压缩图片
原文链接:https:////www.cnblogs.com/Jackyye/p/12510943.html 每天解决一些c#小问题,在写微信小程序,或者一些手机软件接口,我们经常要用到上传图片到服务 ...