c#,pagerank算法实现一
PageRank让链接来"投票"
一个页面的“得票数”由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(“链入页面”)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
2005年初,Google为网页链接推出一项新属性nofollow,使得网站管理员和网站作者可以做出一些Google不计票的链接,也就是说这些链接不算作"投票"。nofollow的设置可以抵制评论垃圾。
假设一个由4个页面组成的小团体:A,B,C和D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的Pagerank总和。
继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
换句话说,根据链出总数平分一个页面的PR值。
最后,所有这些被换算为一个百分比再乘上一个系数。由于“没有向外链接的页面”传递出去的PageRank会是0,所以,Google通过数学系统给了每个页面一个最小值:
说明:在Sergey Brin和Lawrence Page的1998年原文中给每一个页面设定的最小值是1-d,而不是这里的
(1-d)/N。 所以一个页面的PageRank是由其他页面的PageRank计算得到。Google不断的重复计算每个页面的PageRank。如果给每个页面一个随机PageRank值(非0),那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。这就是搜索引擎使用它的原因。
实验数据a.txt是小的随机生成的图(图中没有终止点)。节点个数n=1000,边数m=8192
该图有一个1000条边构成的有向环(遍历了所有的节点),这确保了该图是连通的。显然,这样的一个有向环确保了该图中没有终止点(即任何一个点都有出边)。如果存在一对节点之间有多条相同的有向边,你的算法应该把它们当做是同一条边。a.txt的每一行表示一条有向边,第一列表示边的源结点,第二列表示边的目的节点。
l 实现过程:
设有向图 G=(V,E)有n个节点(编号为1,2,...N)和M条边,所有的节点都有至少一个出边,且M=[Mji](n*n)是一个m*n的随机邻接矩阵,定义如下:对任意i,j€[1,n]
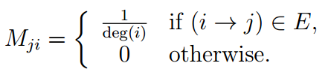
里,deg(i)是图G中节点i的出边个数。基于PageRank的定义,设1-Β为随机跳转概率,我们将PageRank向量记为r,有如下等式
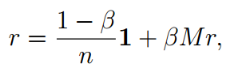
基于上面的公式,计算PageRank向量的迭代过程如下:

矩阵运算调用了 MathNet.Numerics
public static double[,] Get()
{
double[,] m = new double[, ];
for (int i = ; i < ; i++)
{
for (int j = ; j < ; j++)
{
m[i, j] = ;
}
}
double[] s = new double[];
double[,] M = new double[, ];
for (int i = ; i < ; i++)
{
for (int j = ; j < ; j++)
{
M[i, j] = ;
} }
StreamReader sr = File.OpenText(@"E:\a.txt");
string nextLine;
while ((nextLine = sr.ReadLine()) != null)
{
char[] charTemp = { '\t' };
string[] arr = nextLine.Split(charTemp);
int[] d = Array.ConvertAll(arr, int.Parse);
int a1 = d[] - ;
int a2 = d[] - ;
m[a1, a2] = ;
}
sr.Close();
for (int i = ; i < ; i++)
{
for (int j = ; j < ; j++)
{
s[i] += m[i, j];
}
}
for (int i = ; i < ; i++)
{
for (int j = ; j < ; j++)
{
if (m[i, j] == )
M[j, i] = 1.0 / s[i];
}
}
return M;
}
public static double [] Getmtrix(double[,] M)
{ double num = 0.8;
double[,] result = Get();
var mb = Matrix<double>.Build;
var A= mb.DenseOfArray(result);
var matrixR = mb.Dense(, , 0.001);
var matrixL = mb.Dense(, , 0.0002);
for (int p = ; p < ; p++)
{
matrixR = matrixL + (A * matrixR) * num;
}
double[,]b= matrixR.ToArray();
double[] d = new double[b.Length];
for (int i = ; i < b.Length; i++)
{
for (int j = ; j < ; j++)
{
d[i] = b[i, j];
}
}
return d;
}
public static void show(double[] a)
{
double[] a1 = Getmtrix(Get());
double max = ;
int maxindex = -;
for (int j = ; j < ; j++)
{
max = a1.Max();
maxindex = Array.IndexOf(a1, max);
a1[maxindex] = ;
Console.WriteLine("最大:{0}" + "节点:{1}", j+, maxindex+); } }
public static void show2(double[] a)
{
double[] a1 = Getmtrix(Get());
for (int j = ; j < ; j++)
{
double min = 1.0;
int minindex = -;
min = a1.Min();
minindex = Array.IndexOf(a1, min);
a1[minindex] = ;
Console.WriteLine("最小:{0}" + "节点:{1}", j + , minindex + );
}
Console.ReadKey();
}
static void Main(string[] args)
{
show(Getmtrix(Get()));
show2(Getmtrix(Get())); }
pagerank算法
l 输出
ü PageRank分值最高的5个节点的id
ü PageRank分值最低的5个节点的id
l graph-full.txt
c#,pagerank算法实现一的更多相关文章
- 【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解.从上一篇文章可以很快的了解Pa ...
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- 张洋:浅析PageRank算法
本文引自http://blog.jobbole.com/23286/ 很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看 ...
- PageRank算法简介及Map-Reduce实现
PageRank对网页排名的算法,曾是Google发家致富的法宝.以前虽然有实验过,但理解还是不透彻,这几天又看了一下,这里总结一下PageRank算法的基本原理. 一.什么是pagerank Pag ...
- PageRank算法
PageRank,网页排名,又称网页级别,传说中是PageRank算法拯救了谷歌,它是根据页面之间的超链接计算的技术,作为网页排名的要素之一.它通过网络浩瀚的超链接关系来确定一个页面的等级.Googl ...
- [转]PageRank算法
原文引自: 原文引自: http://blog.csdn.net/hguisu/article/details/7996185 感谢 1. PageRank算法概述 PageRank,即网页排名,又称 ...
- Hadoop应用开发实战(flume应用开发、搜索引擎算法、Pipes、集群、PageRank算法)
Hadoop是2013年最热门的技术之一,通过北风网robby老师<深入浅出Hadoop实战开发>.<Hadoop应用开发实战>两套课程的学习,普通Java开发人员可以在最快的 ...
- 关于pagerank算法的一点点总结
1. PageRank算法每个顶点收敛的值与每个点的初值是没有关系的,每个点随便赋初值. 2.像q=0.8这样的阻尼系数已经解决了PageRank中处在的孤立点问题.黑洞效应问题. 3.当有那个点进行 ...
- 浅析PageRank算法
很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看了一些相关的资料(PS:在动车上看看书真是一种享受),趁热打铁,将所看 ...
- PageRank算法第一篇
摘要by crazyhacking: 一 搜索引擎的核心问题就是3个:1.建立资料库,通过爬虫系统实现:2.建立一种数据结构,可以根据关键词找到含有这个词的页面.通过索引系统(倒排索引)实现.3排序系 ...
随机推荐
- Javascript书写位置
1.行内式js(很少使用) 以on开头,如onclick HTML中推荐双引号,JS推荐单引号 2.内嵌式js(常用) <script> alert('hello world'); < ...
- 01 . Mysql简介及部署
Mysql数据库简介 什么是数据? 数据(data)是事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的原始素材,数据是信息的表现形式和载体,可以是符号,文字,数字,语音,图 ...
- Spring boot Sample 012之spring-boot-web-upload
一.环境 1.1.Idea 2020.1 1.2.JDK 1.8 二.目的 spring boot 整合web实现文件上传下载 三.步骤 3.1.点击File -> New Project -& ...
- Vue3.0+ElementUI打包之后,为什么部分页面按钮图标找不到
有的页面可以显示这个按钮,有的页面不可以,找了好久,看这都webpack路径问题,到但是我这个没有webpack,没有build文件夹,最后发现是因为没有绑定点击事件 加上这个之后就好了
- Rocket - diplomacy - NodeHandle相关类
https://mp.weixin.qq.com/s/GWL41P1G1BXm2sTeLmckdA 介绍NodeHandle相关的类. 1. NoHandle 顶层类(tra ...
- Javascript中target事件属性,事件的目标节点的获取。
window.event.srcElement与window.event.target 都是指向触发事件的元素,它是什么就有什么样的属性 srcElement是事件初始化目标html元素对象引用,因为 ...
- Java实现 LeetCode 63 不同路径 II(二)
63. 不同路径 II 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为"Start" ). 机器人每次只能向下或者向右移动一步.机器人试图达到网格的右下角(在 ...
- Java实现 洛谷 P1000 超级玛丽游戏
public class Main { public static void main(String[] args){ System.out.println(" ********" ...
- java实现第六届蓝桥杯空心菱形
空心菱形 标题:空心菱形 小明刚刚开发了一个小程序,可以打印出任意规模的空心菱形,规模为6时,如下图: ****** ****** ***** ***** **** **** *** *** ** * ...
- Linux 重装MySQL
1.首先查看当前MySQL的安装情况,查找之前是否安装了MySQL rpm -qa|grep -i mysql 可以看到如下图: 因为我是使用的宝塔面板一键安装的LAMP,所以显示安装了bt-mysq ...