大二暑假第一周总结--初次安装配置Hadoop
本次配置主要使用的教程:http://dblab.xmu.edu.cn/blog/install-hadoop-in-centos/
以下是自己在配置中的遇到的一些问题和解决方法,或者提示
一.使用虚拟机安装centos7并设置图形界面
在安装的过程中,由于自己还是熟悉图形界面,所以还是在安装之后又继续安装了图形界面
yum groupinstall "GNOME Desktop" "Graphical Administration Tools"
这行代码是安装图形界面,但是我们需要注意的是,我们需要设置好网络连接,否则无法下载成功,再次之前最好先ping一下,如果不想麻烦的设置网络连接,最好在安装的时候就设置好网络,否则从命令界面设置网络还是有些麻烦的。安装图形界面的具体连接:https://www.cnblogs.com/passer101/p/9899249.html。
二.创建Hadoop用户
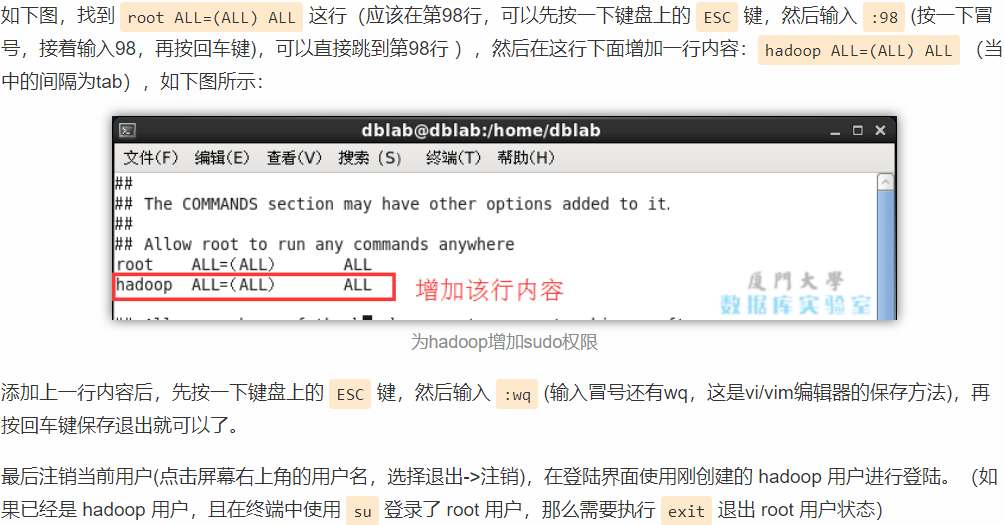
这里唯一需要注意的是要对Hadoop用户添加管理员权限
visudo
三.安装SSH、配置SSH无密码登陆
这个具体流程可以参考连接,实现上没有难度,至少我在操作的时候没有遇到问题
http://dblab.xmu.edu.cn/blog/install-hadoop-in-centos/
四.安装Java环境
这里我们没有按照教程上面的使用openjdk,而是选择了Oraclejdk,这里我们需要注意的就是精简版的centos安装包和完整版centos都有预装openjdk,所以我们首先需要的是卸载openjdk,然后再安装Oraclejdk才可以。我们在此之前使用java -version命令先查看自己是否有openjdk,如果有的话然后再进行卸载。
rpm -qa | grep java | xargs rpm -e --nodeps //使用此代码来进行openjdk的卸载
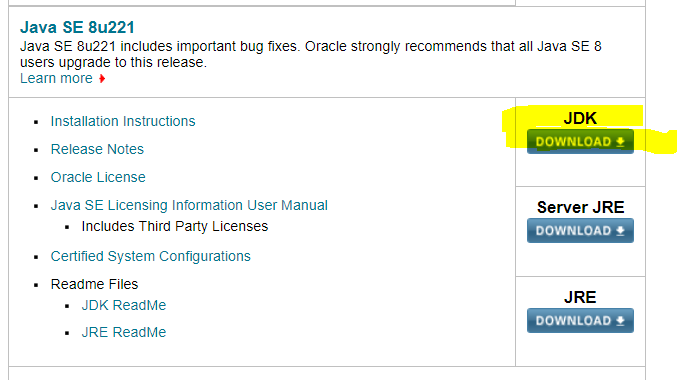
然后进入Oracle官网:https://www.oracle.com/technetwork/java/javase/downloads/index.html,然后找到选择你要的jdk,并进行下载,我们需要注意的是,现在新版的jdk下载需要注册账户,比较繁琐一点。

解压JDK
1 将"/root/下载/jdk-8u211-linux-x64.tar.gz"文件拷贝到/usr/java 目录下
[root@localhost 下载]# cp jdk-8u211-linux-x64.tar.gz /usr/java
2 解压缩该压缩文件到 /usr/java目录
[root@localhost java]#tar -zxvf jdk-8u211-linux-x64.tar.gz
配置jdk环境变量
1 编辑
[root@localhost java]#vim /etc/profile
在最后一行加上如下值
#java environment
export JAVA_HOME=/usr/java/jdk1.8.0_211
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
注:CentOS6上面的是JAVAHOME,CentOS7是{JAVA_HOME}
接着需要配置一下 JAVA_HOME 环境变量,为方便,我们在 ~/.bashrc 中进行设置
vim ~/.bashrc 在文件最后面添加如下单独一行(指向 JDK 的安装位置),并保存:
- export JAVA_HOME=/usr/java/jdk1.8.0_211
接着还需要让该环境变量生效,执行如下代码:source ~/.bashrc 使变量设置生效
设置好后我们来检验一下是否设置正确:
- echo $JAVA_HOME # 检验变量值
- java -version
- $JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
- 如果设置正确的话,
$JAVA_HOME/bin/java -version会输出 java 的版本信息,且和java -version的输出结果一样
需要注意的是,上面的方法是需要中文输入法的(就是拼音),所以我们需要再添加一个拼音的输入法,然后就是最好在VMware上面安装VMware Tool,这样有时候就会在输入命令直接粘贴就好,比较便捷省事
具体的安装操作可以参考连接:https://jingyan.baidu.com/article/597a0643356fdc312b5243f6.html。
五.安装hadoop2
按照第三步骤给出的教程即可完成安装,总体不算十分复杂,安装的时候也没有遇到什么困难。
六.Hadoop单机配置(非分布式)
此部分也没有遇到什么困难,依照教程即可。
七.Hadoop伪分布式配置
在设置 Hadoop 伪分布式配置前,我们还需要设置 HADOOP 环境变量,执行如下命令在 ~/.bashrc 中设置:
gedit ~/.bashrc
在文件最后面增加如下内容
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
保存后,不要忘记执行如下命令使配置生效:source ~/.bashrc
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),
将当中的
- <configuration>
- </configuration>
修改为下面配置:(序号不要添加)
- <configuration>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/usr/local/hadoop/tmp</value>
- <description>Abase for other temporary directories.</description>
- </property>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
同样的,修改配置文件 hdfs-site.xml:
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/usr/local/hadoop/tmp/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/usr/local/hadoop/tmp/dfs/data</value>
- </property>
- </configuration>
配置完成后,执行 NameNode 的格式化:./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
接着开启 NaneNode 和 DataNode 守护进程:./sbin/start-dfs.sh
如果正常打开,我们可以看到大致如下的图片:
如果只是单独一个21323 jps类似的输出的话就是有问题的,那么可能是格式化出现了问题,多次格式化会导致namenode和DataNode的ID不同,所以就不会同时出现。或者说端口号被占用也会导致这种情况出现。
可参考以下链接:
端口号问题:https://blog.csdn.net/kangkanggegeg/article/details/73960642
权限问题:https://blog.csdn.net/qq_38082431/article/details/78727084
多次格式化问题:https://blog.csdn.net/Fly_TheWind/article/details/80444750
最终解决方法:先停止进程,删除/usr/local/hadoop/目录下的tmp目录,然后重新再来一遍。
八.运行Hadoop伪分布式实例
按照主教程走是没有问题的,这里主要是总结一下,在运行中出现的问题,就是有时候会显示 input目标不是文件或是目录,这个问题是有因为使用的相对位置错误,我们需要在input和output前加一个/,使它成为相对地址才可以,如果不想的话,也可以使用绝对地址/usr/hadoop/input。还有就是一定要是使用Hadoop用户来创建,如果你不是使用Hadoop用户来创建的话,或者使用了sudo 命令来创建,可能用户就会变成root,那么就地址相应的也会出错,绝对地址就会变成user/root/input,或者你使用的用户的地址,所以就会出现不存在的情况。
九.启动YARN
这一部分也是比较简单,很容易就配置好了,按照教程来就好。
大二暑假第一周总结--初次安装配置Hadoop的更多相关文章
- 大二暑假第二周总结--开始学习Hadoop基础(一)
一.简单视频学习Hadoop的处理架构 二.简单视频学习分布式文件系统HDFS并进行简单的实践操作 简单操作教程:http://dblab.xmu.edu.cn/blog/290-2/ 注意:在建立H ...
- 2019-2020-2 20175121杨波《网络对抗技术》第一周kali的安装
2019-2020-2 20175121杨波<网络对抗技术>第一周kali的安装 标签 : Linux 一.下载安装kali 1.下载kali 下载链接 打开链接进入官网后,点击Torre ...
- 从零开始使用git第一篇:下载安装配置
从零开始使用git 第一篇:下载安装配置 第一篇:从零开始使用git第一篇:下载安装配置 第二篇:从零开始使用git第二篇:git实践操作 第三篇:从零开始使用git第三篇:git撤销操作.分支操作和 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 集群安装配置Hadoop具体图解
集群安装配置Hadoop 集群节点:node4.node5.node6.node7.node8. 详细架构: node4 Namenode,secondnamenode,jobtracker node ...
- 虚拟机Ubuntu(18.04.2)下安装配置Hadoop(2.9.2)(伪分布式+Java8)
[本文结构] [1]安装Hadoop前的准备工作 [1.1] 创建新用户 [1.2] 更新APT [1.3] 安装SSH [1.4] 安装Java环境 [2]安装和配置hadoop [2.1] Had ...
- Linux中安装配置hadoop集群
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择 ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- Centos 7环境下安装配置Hadoop 3.0 Beta1简记
前言 由于以前已经写过一篇Centos 7环境下安装配置2.8的随笔,因此这篇写得精简些,只挑选一些重要环节记录一下. 安装环境为:两台主机均为Centos 7.*操作系统,两台机器配置分别为: 主机 ...
随机推荐
- SpringBoot初试牛刀
新建 Spring Boot 项目常用的两种方式 你可以通过 https://start.spring.io/ 这个网站来生成一个 Spring Boot 的项目. 你可以选择自己喜欢的依赖进行加载到 ...
- rapid-generator JAVA代码生成器
有感于马上要做个比较大的业务系统,想到那无止境的增删改查.粘贴复制,顿时脑后升起一阵凉风.于是想到个找或者写一个Java代码的生成器,这样在正常开发进度下,也能余下更多的时间去做些别的事情. 闲话少说 ...
- vb.net导出CSV文件
Public Function WriteToCSV(ByVal dataTable As DataTable, ByVal filePath As String, ByVal records As ...
- python列表元组 魔法方法
1.元祖 count() 统计某个字符串的出现次数 tuple.count('22') 返回一个整数 index() 获取某个值出现的位置 2.列表 字符串可以直接转换列表 l ...
- js学习(三)对象与事件
JavaScript 对象 1.JavaScript 对象:拥有属性和方法的数据. 2.在 JavaScript中,几乎所有的事物都是对象. 3.定义一个person对象 var person = { ...
- 记一次Redis+Getshell经验分享
前言: 当我们接到一个授权渗透测试的时候,常规漏洞如注入.文件上传等尝试无果后,扫描端口可能会发现意外收获. 知己知彼乃百战不殆,Redis介绍: 简单来说 redis 就是一个Key-Value类型 ...
- 我的第一个爬虫【python selenium】
去年写的一个小功能,一年过得好快,好快! 目的:爬取京东商品详情页面的内容(商品名称.价格.评价数量)后存储到xls文档中,方便商家分析自己商品的动态. 软件:chrome(windows).chro ...
- SpringMVC 文件的上传、下载
文件上传 (1)下载添加2个jar包 commons-fileupload.jar commons-io.jar SpringMVC的文件上传依赖于Apache的FileUpload组件,需要下载添加 ...
- php导出合同模板到excel
/** * [export_excel 合同导出] * [@param itemid:单号] * @return [type] */ public function export_excel() { ...
- 盘姬工具箱WV1.10
========================================================================== {盘姬工具箱CruiserEXPforWin版是一 ...