Redis 详解 (二) redis的配置文件介绍
目录
上一篇博客我们介绍了如何安装Redis,在Redis的解压目录下有个很重要的配置文件 redis.conf (/opt/redis-4.0.9目录下),关于Redis的很多功能的配置都在此文件中完成的,在上一讲我也说过,一般为了不破坏安装的文件,出厂默认配置最好不要去改,所以我们将此配置文件复制到 /etc/redis/目录下了。
通过 vim /etc/redis/redis.conf 命令打开此文件。下面我们将详细介绍此配置文件。
ps:大家不懂这些配置意思没关系,后面会在具体实例中进行介绍,先过个眼熟即可。
1、开头说明
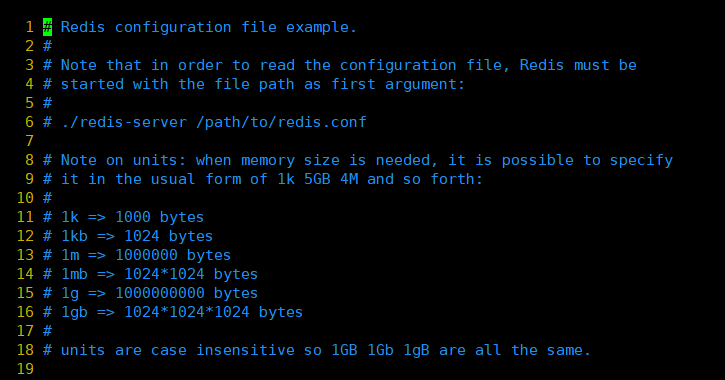
这里没什么好说的,需要注意的是后面需要使用内存大小时,可以指定单位,通常是以 k,gb,m的形式出现,并且单位不区分大小写。
2、INCLUDES
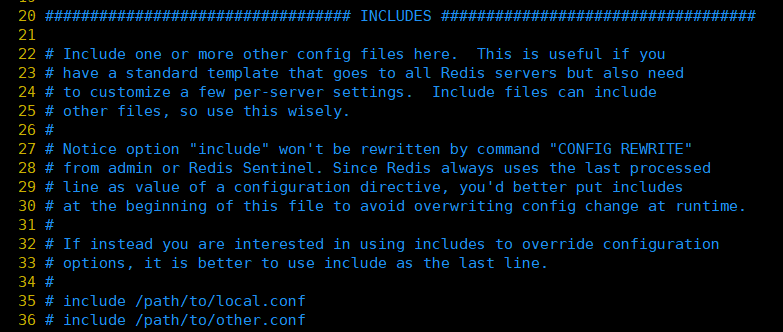
我们知道Redis只有一个配置文件,如果多个人进行开发维护,那么就需要多个这样的配置文件,这时候多个配置文件就可以在此通过 include /path/to/local.conf 配置进来,而原本的 redis.conf 配置文件就作为一个总闸。
ps:如果用过struts2 开发的同学,在项目组中多人开发的情况下,通常会有多个struts2.xml 文件,这时候也会通过类时的配置引入进来。
另外需要注意的时,如果将此配置写在redis.conf 文件的开头,那么后面的配置会覆盖引入文件的配置,如果想以引入文件的配置为主,那么需要将 include 配置写在 redis.conf 文件的末尾。
3、MODULES

redis3.0的爆炸功能是新增了集群,而redis4.0就是在3.0的基础上新增了许多功能,其中这里的 自定义模块配置就是其中之一。通过这里的 loadmodule 配置将引入自定义模块来新增一些功能。
4、NETWORK
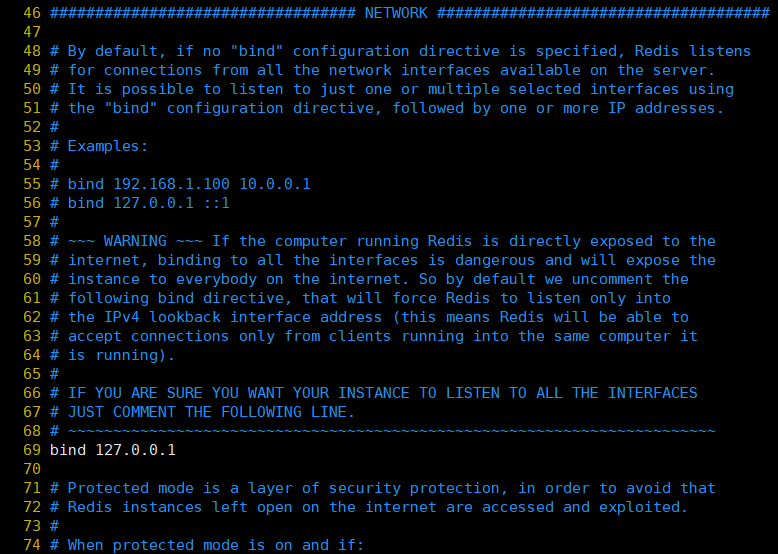
ps:这里的配置较长,我只截取了一部分,下同。
①、bind:绑定redis服务器网卡IP,默认为127.0.0.1,即本地回环地址。这样的话,访问redis服务只能通过本机的客户端连接,而无法通过远程连接。如果bind选项为空的话,那会接受所有来自于可用网络接口的连接。
②、port:指定redis运行的端口,默认是6379。由于Redis是单线程模型,因此单机开多个Redis进程的时候会修改端口。
③、timeout:设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接。默认值为0,表示不关闭。
④、tcp-keepalive :单位是秒,表示将周期性的使用SO_KEEPALIVE检测客户端是否还处于健康状态,避免服务器一直阻塞,官方给出的建议值是300s,如果设置为0,则不会周期性的检测。
5、GENERAL
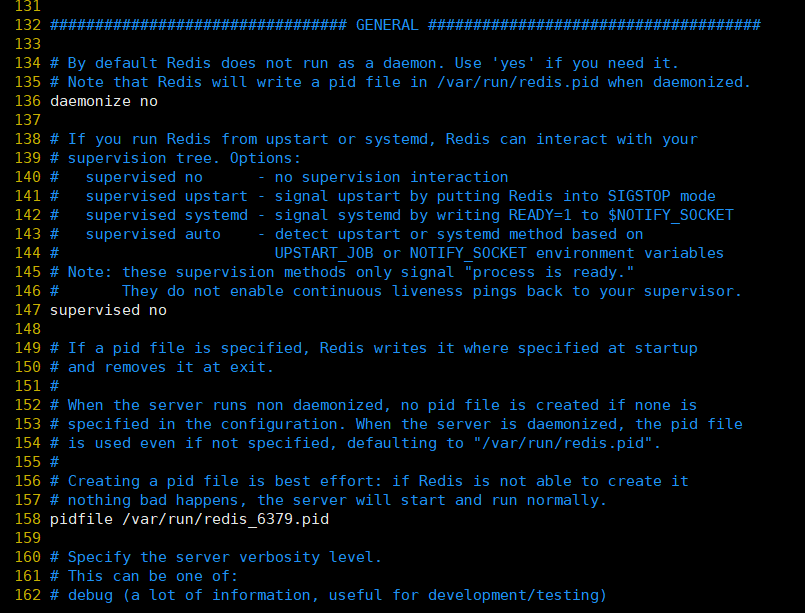
具体配置详解:
①、daemonize:设置为yes表示指定Redis以守护进程的方式启动(后台启动)。默认值为 no
②、pidfile:配置PID文件路径,当redis作为守护进程运行的时候,它会把 pid 默认写到 /var/redis/run/redis_6379.pid 文件里面
③、loglevel :定义日志级别。默认值为notice,有如下4种取值:
debug(记录大量日志信息,适用于开发、测试阶段)
verbose(较多日志信息)
notice(适量日志信息,使用于生产环境)
warning(仅有部分重要、关键信息才会被记录)
④、logfile :配置log文件地址,默认打印在命令行终端的窗口上
⑤、databases:设置数据库的数目。默认的数据库是DB 0 ,可以在每个连接上使用select <dbid> 命令选择一个不同的数据库,dbid是一个介于0到databases - 1 之间的数值。默认值是 16,也就是说默认Redis有16个数据库。
6、SNAPSHOTTING
这里的配置主要用来做持久化操作。
①、save:这里是用来配置触发 Redis的持久化条件,也就是什么时候将内存中的数据保存到硬盘。默认如下配置:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
当然如果你只是用Redis的缓存功能,不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。可以直接一个空字符串来实现停用:save ""
②、stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
③、rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
④、rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
⑤、dbfilename :设置快照的文件名,默认是 dump.rdb
⑥、dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。使用上面的 dbfilename 作为保存的文件名。
7、REPLICATION
①、slave-serve-stale-data:默认值为yes。当一个 slave 与 master 失去联系,或者复制正在进行的时候,slave 可能会有两种表现:
1) 如果为 yes ,slave 仍然会应答客户端请求,但返回的数据可能是过时,或者数据可能是空的在第一次同步的时候
2) 如果为 no ,在你执行除了 info he salveof 之外的其他命令时,slave 都将返回一个 "SYNC with master in progress" 的错误
②、slave-read-only:配置Redis的Slave实例是否接受写操作,即Slave是否为只读Redis。默认值为yes。
③、repl-diskless-sync:主从数据复制是否使用无硬盘复制功能。默认值为no。
④、repl-diskless-sync-delay:当启用无硬盘备份,服务器等待一段时间后才会通过套接字向从站传送RDB文件,这个等待时间是可配置的。 这一点很重要,因为一旦传送开始,就不可能再为一个新到达的从站服务。从站则要排队等待下一次RDB传送。因此服务器等待一段 时间以期更多的从站到达。延迟时间以秒为单位,默认为5秒。要关掉这一功能,只需将它设置为0秒,传送会立即启动。默认值为5。
⑤、repl-disable-tcp-nodelay:同步之后是否禁用从站上的TCP_NODELAY 如果你选择yes,redis会使用较少量的TCP包和带宽向从站发送数据。但这会导致在从站增加一点数据的延时。 Linux内核默认配置情况下最多40毫秒的延时。如果选择no,从站的数据延时不会那么多,但备份需要的带宽相对较多。默认情况下我们将潜在因素优化,但在高负载情况下或者在主从站都跳的情况下,把它切换为yes是个好主意。默认值为no。
8、SECURITY
①、rename-command:命令重命名,对于一些危险命令例如:
flushdb(清空数据库)
flushall(清空所有记录)
config(客户端连接后可配置服务器)
keys(客户端连接后可查看所有存在的键)
作为服务端redis-server,常常需要禁用以上命令来使得服务器更加安全,禁用的具体做法是是:
- rename-command FLUSHALL ""
也可以保留命令但是不能轻易使用,重命名这个命令即可:
- rename-command FLUSHALL abcdefg
这样,重启服务器后则需要使用新命令来执行操作,否则服务器会报错unknown command。
9、CLIENTS

①、maxclients :设置客户端最大并发连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件。 描述符数-32(redis server自身会使用一些),如果设置 maxclients为0 。表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
10、MEMORY MANAGEMENT
①、maxmemory:设置客户端最大并发连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件。描述符数-32(redis server自身会使用一些),如果设置 maxclients为0 。表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息。
②、maxmemory-policy :当内存使用达到最大值时,redis使用的清楚策略。有以下几种可以选择:
1)volatile-lru 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used )
2)allkeys-lru 利用LRU算法移除任何key
3)volatile-random 移除设置过过期时间的随机key
4)allkeys-random 移除随机ke
5)volatile-ttl 移除即将过期的key(minor TTL)
6)noeviction noeviction 不移除任何key,只是返回一个写错误 ,默认选项
③、maxmemory-samples :LRU 和 minimal TTL 算法都不是精准的算法,但是相对精确的算法(为了节省内存)。随意你可以选择样本大小进行检,redis默认选择3个样本进行检测,你可以通过maxmemory-samples进行设置样本数。
11、APPEND ONLY MODE
①、appendonly:默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,会导致可能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式, 可以提供更好的持久化特性。Redis会把每次写入的数据在接收后都写入appendonly.aof文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。默认值为no。
②、appendfilename :aof文件名,默认是"appendonly.aof"
③、appendfsync:aof持久化策略的配置;no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快;always表示每次写入都执行fsync,以保证数据同步到磁盘;everysec表示每秒执行一次fsync,可能会导致丢失这1s数据
④、no-appendfsync-on-rewrite:在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,执行fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置为no。如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no,建议yes。Linux的默认fsync策略是30秒。可能丢失30秒数据。默认值为no。
⑤、auto-aof-rewrite-percentage:默认值为100。aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程。
⑥、auto-aof-rewrite-min-size:64mb。设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写。
⑦、aof-load-truncated:aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。重启可能发生在redis所在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项,出现这种现象 redis宕机或者异常终止不会造成尾部不完整现象,可以选择让redis退出,或者导入尽可能多的数据。如果选择的是yes,当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。如果是no,用户必须手动redis-check-aof修复AOF文件才可以。默认值为 yes。
12、LUA SCRIPTING
①、lua-time-limit:一个lua脚本执行的最大时间,单位为ms。默认值为5000.
13、REDIS CLUSTER
①、cluster-enabled:集群开关,默认是不开启集群模式。
②、cluster-config-file:集群配置文件的名称,每个节点都有一个集群相关的配置文件,持久化保存集群的信息。 这个文件并不需要手动配置,这个配置文件有Redis生成并更新,每个Redis集群节点需要一个单独的配置文件。请确保与实例运行的系统中配置文件名称不冲突。默认配置为nodes-6379.conf。
③、cluster-node-timeout :可以配置值为15000。节点互连超时的阀值,集群节点超时毫秒数
④、cluster-slave-validity-factor :可以配置值为10。在进行故障转移的时候,全部slave都会请求申请为master,但是有些slave可能与master断开连接一段时间了, 导致数据过于陈旧,这样的slave不应该被提升为master。该参数就是用来判断slave节点与master断线的时间是否过长。判断方法是:比较slave断开连接的时间和(node-timeout * slave-validity-factor) + repl-ping-slave-period 如果节点超时时间为三十秒, 并且slave-validity-factor为10,假设默认的repl-ping-slave-period是10秒,即如果超过310秒slave将不会尝试进行故障转移
⑤、cluster-migration-barrier :可以配置值为1。master的slave数量大于该值,slave才能迁移到其他孤立master上,如这个参数若被设为2,那么只有当一个主节点拥有2 个可工作的从节点时,它的一个从节点会尝试迁移。
⑥、cluster-require-full-coverage:默认情况下,集群全部的slot有节点负责,集群状态才为ok,才能提供服务。 设置为no,可以在slot没有全部分配的时候提供服务。不建议打开该配置,这样会造成分区的时候,小分区的master一直在接受写请求,而造成很长时间数据不一致。
Redis 详解 (二) redis的配置文件介绍的更多相关文章
- Redis 详解 (一) redis的简介和安装
目录 1.Redis 的简介 2.Redis 下载 3.安装环境 4.编译安装 5.启动Redis 6.关闭Redis 7.注意事项 工作中一直在用 Redis,但是一直没有进行系统的总结,这个系列的 ...
- Redis 详解 (五) redis的五大数据类型实现原理
目录 1.对象的类型与编码 ①.type属性 ②.encoding 属性和 *prt 指针 2.字符串对象 3.列表对象 4.哈希对象 5.集合对象 6.有序集合对象 7.五大数据类型的应用场景 8. ...
- Redis 详解 (四) redis的底层数据结构
目录 1.演示数据类型的实现 2.简单动态字符串 3.链表 4.字典 5.跳跃表 6.整数集合 7.压缩列表 8.总结 上一篇博客我们介绍了 redis的五大数据类型详细用法,但是在 Redis 中, ...
- Redis 详解 (三) redis的五大数据类型详细用法
目录 1.string 数据类型 2.hash 数据类型 3.list 数据类型 4.set 数据类型 5.zset 数据类型 6.系统相关命令 7.key 相关命令 我们说 Redis 相对于 Me ...
- Redis详解(二)——AOF
Redis详解(二)--AOF 前言 RDB 持久化存在一个缺点是一定时间内做一次备份,如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失).对于数据完整性要求很严格的需求 ...
- Redis详解入门篇
Redis详解入门篇 [本教程目录] 1.redis是什么2.redis的作者3.谁在使用redis4.学会安装redis5.学会启动redis6.使用redis客户端7.redis数据结构 – 简介 ...
- Redis详解入门篇(转载)
Redis详解入门篇(转载) [本教程目录] 1.redis是什么2.redis的作者3.谁在使用redis4.学会安装redis5.学会启动redis6.使用redis客户端7.redis数据结构 ...
- Redis详解(九)------ 哨兵(Sentinel)模式详解
在上一篇博客----Redis详解(八)------ 主从复制,我们简单介绍了Redis的主从架构,但是这种主从架构存在一个问题,当主服务器宕机,从服务器不能够自动切换成主服务器,为了解决这个问题,我 ...
- 基础拾遗------redis详解
基础拾遗 基础拾遗------特性详解 基础拾遗------webservice详解 基础拾遗------redis详解 基础拾遗------反射详解 基础拾遗------委托详解 基础拾遗----- ...
随机推荐
- R语言 table()函数
table函数 用 table() 函数统计因子各水平的出现次数(称为频数或频率).也可以对一般的向量统计每个不同元素的出现次数.如 sex = c("女","女&quo ...
- 设计模式课程 设计模式精讲 8-3 单例设计模式-DoubleCheck双重检查实战及原理解析
1 课程讲解 1.1 为何要使用双重检查 1.2 双重检查的缺点 1.3 指令重排序讲解 1.4 指令重排序比喻(自己理解) 1.5 如何解决指令重排序问题 2 代码演练 2.1 代码演练1(双重检查 ...
- 142、Java内部类之在普通方法里面定义内部类
01.代码如下: package TIANPAN; class Outer { // 外部类 private String msg = "Hello World !"; publi ...
- Java程序挂掉的几种可能
今天花了一整天在跟踪一个问题,每次感觉已经快找到原因的时候发现现象又变了,我觉得从中吸取的教训可以给大家分享一下. 为了重现这个现象,我写了一个简单的例子.在本例中,先初始化了一个map,然后用一个无 ...
- Xcode下载途径
Xcode除了能在Appstore直接下载外,还可以用开发者账号登陆开发者中心[https://developer.apple.com/download/]下载对应的资源. 在开发者中心下载的好处是, ...
- css 图形样式
参考:https://css-tricks.com/examples/ShapesOfCSS/
- JS动态获取 Url 参数
此操作主要用于动态 ajax 请求 1.首先封装一个函数 GetRequest(),能动态获取到 url 问号"?"后的所有参数 , function GetRequest() { ...
- 30 整数中1出现的次数(从1到n整数中1出现的次数)这题很难要多看*
题目描述 求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1.10.11.12.13因此共出现6次,但是对于后面问题他就没辙了. ...
- Maven项目- "null" 的java.lang.reflect.InvocationTargetException 解决方法
异常显示: 解决方法:
- LIS问题
LIS定义LIS(Longest Increasing Subsequence)最长上升子序列 .一个数的序列bi,当b1 < b2 < … < bS的时候,我们称这个序列是上升的. ...