Web Scraper——轻量数据爬取利器

日常学习工作中,我们多多少少都会遇到一些数据爬取的需求,比如说写论文时要收集相关课题下的论文列表,运营活动时收集用户评价,竞品分析时收集友商数据。
当我们着手准备收集数据时,面对低效的复制黏贴工作,一般都会萌生一个想法:我要是会爬虫就好了,分分钟就把数据爬取下来了。可是当我们搜索相关教程时,往往会被高昂的学习成本所劝退。拿现在最通用的 python 爬虫来说,对于小白来说往往要跨过下面几座大山:

学习一门编程语言:python 学习网页的基础构成——HTML 标签和 CSS 选择器,有时候还要了解一些 JavaScript 学习网络通信的基础协议——HTTP 协议 学习 python 中常见的爬虫框架和解析库 ......
上面的知识点,没有几个月是掌握不完的。而且对于非强需求的人来说,这么多的知识点,你还会时时刻刻和遗忘做斗争。
那么有没有不学 python 也能爬取数据的利器呢?结合文章标题,我想你已经知道我要安利什么了。今天我要推荐的就是Web Scraper,一个轻量的数据爬虫利器。

Web Scraper 的优点就是对新手友好,在最初抓取数据时,把底层的编程知识和网页知识都屏蔽了,可以非常快的入门,只需要鼠标点选几下,几分钟就可以搭建一个自定义的爬虫。
我在过去的半年里,写了很多篇关于 Web Scraper 的教程,本文类似于一篇导航文章,把爬虫的注意要点和我的教程连接起来。最快一个小时,最多一个下午,就可以掌握 Web Scraper 的使用,轻松应对日常生活中的数据爬取需求。
插件安装
Web Scraper 作为一个 Chrome 插件,网络条件良好的用户可以直接上chrome 网上应用店安装,不太好的用户可以下载插件安装包手动安装,具体的安装流程可以看我的教程:Web Scraper 的下载与安装。
常见网页的类型
结合我的数据爬取经验和读者反馈,我一般把网页分为三大类型:单页、分页列表和筛选表单。
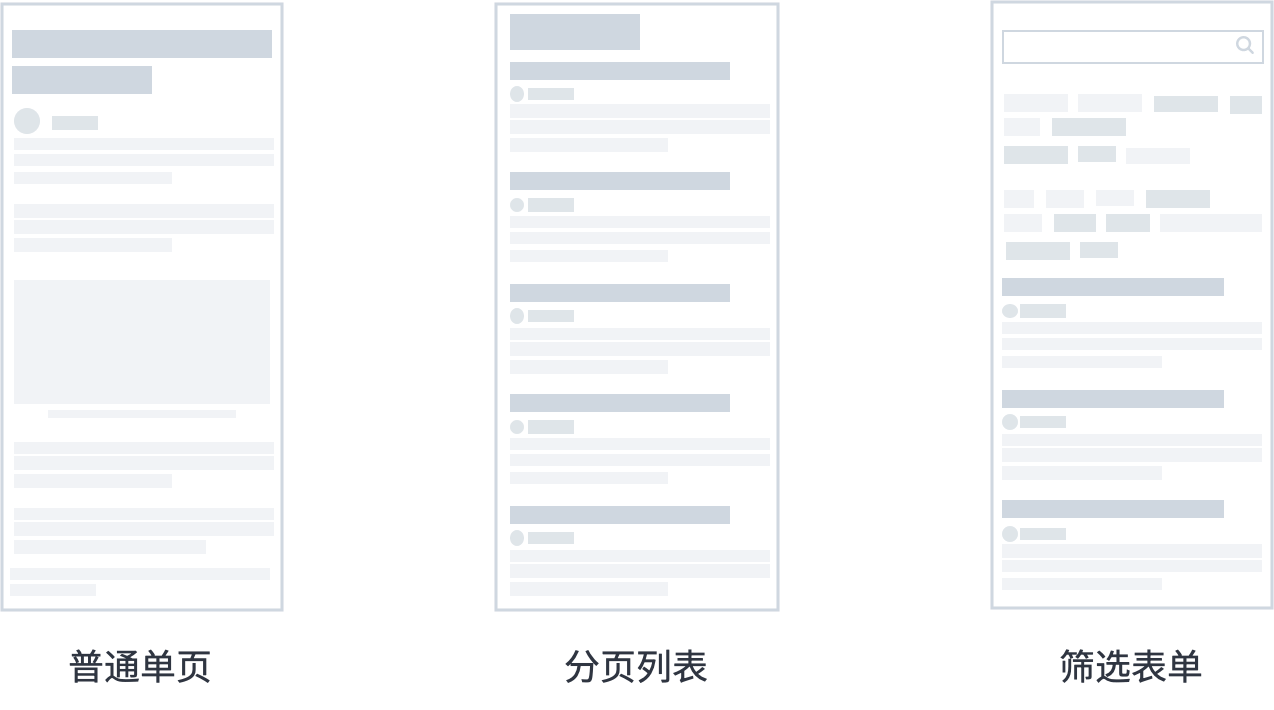
1.单页
单页是最常见的网页类型。
我们日常阅读的文章,推文的详情页都可以归于这种类型。作为网页里最简单最常见的类型,Web Scraper 教程里第一篇爬虫实战就拿豆瓣电影作为案例,入门 Web Scraper 的基础使用。
2.分页列表
分页列表也是非常常见的网页类型。
互联网的资源可以说是无限的,当我们访问一个网站时,不可能一次性把所有的资源都加载到浏览器里。现在的主流做法是先加载一部分数据,随着用户的交互操作(滚动、筛选、分页)才会加载下一部分数据。
教程里我费了较大的笔墨去讲解 Web Scraper 如何爬取不同分页类型网站的数据,因为内容较多,我放在本文的下一节详细介绍。
3.筛选表单
表单类型的网页在 PC 网站上比较常见。
这种网页的最大特点就是有很多筛选项,不同的选择会加载不同的数据,组合多变,交互较为复杂。比如说淘宝的购物筛选页。
比较遗憾的是,Web Scraper 对复杂筛选页的支持不是很好,如果筛选条件可以反映在 URL 链接上就可以爬取相关数据,如果不能就无法爬取筛选后的数据。
常见的分页类型
分页列表是很常见的网页类型。根据加载新数据时的交互,我把分页列表分为 3 大类型:滚动加载、分页器加载和点击下一页加载。

1.滚动加载

我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏幕末尾的时候,APP 就会自动加载下一页的数据,从体验上来看,数据会源源不断的加载出来,永远没有尽头。
Web Scraper 有一个选择器类型叫 Element scroll down,意如其名,就是滚动到底部加载的意思。利用这个选择器,就可以抓取滚动加载类型的网页,具体的操作可以见教程:Web Scraper 抓取「滚动加载」类型网页。
2.分页器加载

分页器加载数据的网页在 PC 网页上非常常见,点击相关页码就能跳转到对应网页。
Web Scraper 也可以爬取这种类型的网页。相关的教程可见: Web Scraper 控制链接分页、Web Scraper 抓取分页器类型网页 和 Web Scraper 利用 Link 选择器翻页。
3.点击下一页加载
点击下一页按钮加载数据其实可以算分页器加载的一种,相当于把分页器中的「下一页」按钮单独拿出来自成一派。
这种网页需要我们手动点击加载按钮来加载新的数据。Web Scraper 可以 Element click 选择器抓取这种分页网页,相关教程可见:Web Scraper 点击「下一页」按钮翻页。
进阶使用
学习了上面列出的几篇教程,Web Scraper 这个插件 60% 的功能基本上就掌握了。下面是一些进阶内容,掌握了可以更高效的抓取数据。
1.列表页 + 详情页

互联网资讯最常见的架构就是「列表页 + 详情页」的组合结构了。
列表页是内容的标题和摘要,详情页是详细说明。有时候我们需要同时抓取列表页和详情页的数据,Web Scraper 也支持这种常见的需求。我们可以利用 Web Scraper 的 Link 选择器来抓取这种组合网页,具体操作可以看教程:Web Scraper 抓取二级网面。
2.HTML 标签与 CSS 选择器

我在前面说了 Web Scraper 屏蔽了一些网页知识,比如说 HTML 和 CSS 的一些内容,只需要简单的鼠标点选就可以搭建一个自定义爬虫。但是如果我们花半个小时了解一些基础的 HTML 和 CSS 知识,其实可以更好的使用 Web Scraper。所以我专门写了一篇介绍 CSS 选择器的文章,十分钟读下来可以上手自定义 CSS 选择器。
3.正则表达式的使用

Web Scraper 其实是一款专注于文本爬取的爬虫工具。如果你日常工作中经常和文本打交道,或者使用过一些效率工具,那你一定听说过正则表达式。没错,Web Scraper 也支持基础的正则表达式,用来筛选和过滤爬取的文本,我也写了一篇文章介绍正则表达式,如果爬取过程中使用它,可以节省不少数据清洗的时间。
4.Sitemap 的导入和导出
SItemap 是个什么东西?其实它就是我们操作 Web Scraper 后生成的配置文件,相当于 python 爬虫的源代码。我们可以通过分享 Sitemap 来分享我们制作的爬虫,相关操作我也写了教程:Web Scraper 导入导出爬虫配置。
5.换一个存储数据库

Web Scraper 导出数据时有一个缺点,默认使用浏览器的 localStorage 存储数据,导致存储的数据是乱序的。这种情况可以通过 Excel 等软件进行排序,也可以通过换一个数据存储库的方式来解决。
Web Scraper 支持 CouchDB 数据库,配置成功后导出的数据就是正序了。相关的配置过程可以看我写的教程:Web Scraper 使用 CouchDB。
Web Scraper 的优点
轻量:非常的轻量。上手只需要一个 Chrome 浏览器和一个 Web Scraper 插件。对于一些限制安装第三方软件的公司电脑,可以很轻易的突破这层限制 提效:Web Scraper 支持绝大多数的网页的爬取,可以无侵入的加入你的日常工作流中 快:抓取速度取决于你的网速与浏览器加载速度,其他的数据采集软件可能有限速现象(充钱就能不限速)
Web Scraper 的缺点
只支持文本数据抓取:图片短视频等多媒体数据无法批量抓取 不支持范围抓取:例如一个网页有 1000 条数据,默认是全量抓取的,无法配置抓取范围。想停止抓取,只能断网模拟数据加载完毕的情况 不支持复杂网页抓取:对于那些加了复杂交互、酷炫的特效和反人类的反爬虫网页,Web Scraper 无能为力(其实这种网页写 python 爬虫也挺头疼) 导出数据乱序:想让数据正序就得用 Excel 或者用 CouchDB,相对复杂了一些
总结
掌握了 Web Scraper 的使用,基本上可以应付学习工作中 90% 的数据爬取需求。相对于 python 爬虫,虽然灵活度上受到了限制,但是低廉的学习成本可以大大节省学习时间,快速解决手头的工作,提高整体的工作效率。综合来看,Web Scraper 还是非常值得去学习的。
联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤代烃实验室」,(或 wx 搜索 egglabs)关注上车防失联。

Web Scraper——轻量数据爬取利器的更多相关文章
- 第十四节:Web爬虫之Ajax数据爬取
有时候在爬取数据的时候我们需要手动向上滑一下,网页才加载一定量的数据,但是网页的url并没有发生变化,这时我们就要考虑使用ajax进行数据爬取了...
- CYQ.Data 轻量数据层之路 优雅V1.4 现世 附API帮助文档(九)
继上一版本V1.3版本发布到现在,时隔N天了:[V1.3版本开源见:CYQ.Data 轻量数据层之路 华丽V1.3版本 框架开源] N天的时间,根据各路网友的反映及自身的想法,继续修改优化着本框架,力 ...
- 一个免费ss网站的数据爬取过程
一个免费ss网站的数据爬取过程 Apr 14, 2019 引言 爬虫整体概况 主要功能方法 绕过DDOS保护(Cloudflare) post中参数a,b,c的解析 post中参数a,b,c的解析 p ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- Python爬虫入门教程 15-100 石家庄政民互动数据爬取
石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的.网址为 http://www.sjz.gov.cn/col/14900 ...
- Web侦察工具HTTrack (爬取整站)
Web侦察工具HTTrack (爬取整站) HTTrack介绍 爬取整站的网页,用于离线浏览,减少与目标系统交互,HTTrack是一个免费的(GPL,自由软件)和易于使用的离线浏览器工具.它允许您从I ...
- 百度地图POI数据爬取,突破百度地图API爬取数目“400条“的限制11。
1.POI爬取方法说明 1.1AK申请 登录百度账号,在百度地图开发者平台的API控制台申请一个服务端的ak,主要用到的是Place API.检校方式可设置成IP白名单,IP直接设置成了0.0.0.0 ...
- CYQ.Data 轻量数据层之路 使用篇二曲 MAction 数据查询(十三)----002
原文链接:https://blog.csdn.net/cyq1162/article/details/53303390 前言说明: 本篇继续上一篇内容,本节介绍所有相关查询的使用. 主要内容提要: 1 ...
随机推荐
- RANet : 分辨率自适应网络,效果和性能的best trade-off | CVPR 2020
基于对自适应网络的研究,论文提出了自适应网络RANet(Resolution Adaptive Network)来进行效果与性能上的取舍,该网络包含多个不同输入分辨率和深度的子网,难易样本的推理会自动 ...
- 【JAVA基础】05 Java语言基础:数组
1. 数组概述和定义格式说明 为什么要有数组(容器) 为了存储同种数据类型的多个值 数组概念 数组是存储同一种数据类型多个元素的集合.也可以看成是一个容器. 数组既可以存储基本数据类型,也可以存储引用 ...
- 什么是.pyc文件
1. Python是一门解释型语言? Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在. 如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled ...
- require.context的妙用
比较好用,记录下来. 以下方法将获取vuex中Modules文件夹里的所有modules并导出. const files = require.context(".", false, ...
- 详解Linux 安装 JDK、Tomcat 和 MySQL(图文并茂)
https://www.jb51.net/article/120984.htm
- JS中switch语句做选择时为什么可以不用break?
在JavaScript中,switch语句相比其他语言并没有特殊之处. 在使用时,我们要注意每个分支后都应加一条break语句,否则后面的分支仍然会执行.实际程序中,我发现有时没用break语句,仍然 ...
- 第 38 章 OCR - Optical Character Recognition
38.1. Tesseract 查找Tesseract安装包 $ apt-cache search Tesseract ocrodjvu - tool to perform OCR on DjVu d ...
- 现代软件工程讲义 如何提出靠谱的项目建议 NABCD
互联网时代对于创新者来说, 既是一个伟大的时代, 又是一个糟糕的时代. 你有很多机会做出影响世界的产品, 但是, 似乎任何想法都被别人想到过了, 做出来了, 上市了, 移植到各种平台上去了- 那么 ...
- 状态压缩DP(大佬写的很好,转来看)
奉上大佬博客 https://blog.csdn.net/accry/article/details/6607703 动态规划本来就很抽象,状态的设定和状态的转移都不好把握,而状态压缩的动态规划解决的 ...
- POJ 1176 Party Lamps&& USACO 2.2 派对灯(搜索)
题目地址 http://poj.org/problem?id=1176 题目描述 在IOI98的节日宴会上,我们有N(10<=N<=100)盏彩色灯,他们分别从1到N被标上号码. 这些灯都 ...