HashMap 底层探索
其实HashMap就是一个Node数组,只是这个数组很奇怪它的每一个Node节点都有自己的下一个Node;这个是hashMap的Node的源码;
- static class Node<K,V> implements Map.Entry<K,V> {
- final int hash;
- final K key;
- V value;
- Node<K,V> next;
- Node(int hash, K key, V value, Node<K,V> next) {
- this.hash = hash;
- this.key = key;
- this.value = value;
- this.next = next;
- }
HashMap中的数组
第一个结构是它的数组,看下源码是怎么定义它的。
- // 数组,又叫作桶(bucket)
- transient Node<K,V>[] table;
是定义了一个Node类型的数组对象,Node类型等下再说,其实它就HaspMap的链表结构,在看它的构造方法;
HashMap提供了四种构造方法;
这里我们以第一个构造器参数
- public HashMap(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0)
- throw new IllegalArgumentException("Illegal initial capacity: " +
- initialCapacity);
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- if (loadFactor <= 0 || Float.isNaN(loadFactor))
- throw new IllegalArgumentException("Illegal load factor: " +
- loadFactor);
- this.loadFactor = loadFactor;
- this.threshold = tableSizeFor(initialCapacity);
- }
主要注意最后一个方法,在我们new HashMap时,如果没有传参,那么initialCapacity就是默认值,默认值是1 << 4 依旧是16,那么现在就可以得出第一个结论,HashMap的默认大小是16。
至于initialCapacity为什么是11我现在还是不明白?
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
桶的大小
- static final int tableSizeFor(int cap) {
- int n = cap - 1;
- n |= n >>> 1;
- n |= n >>> 2;
- n |= n >>> 4;
- n |= n >>> 8;
- n |= n >>> 16;
- return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
- }
这段代码主要就是描述HashMap在进行变化的时候总是选择2的n次方的最近的一个。
小总结:
- HashMap中数组长度最大为MAXIMUM_CAPACITY = 1 << 30 即2的30次方
- HashMap中,桶的个数总是2的n次方。但是这又引出了一个问题,为什么HashMap桶的个数为什么一定要是2的n次方,等下说链表就清楚了。
桶的扩容
- final Node<K, V>[] resize() {
- // 旧数组
- Node<K, V>[] oldTab = table;
- // 旧容量
- int oldCap = (oldTab == null) ? 0 : oldTab.length;
- // 旧扩容门槛
- int oldThr = threshold;
- int newCap, newThr = 0;
- if (oldCap > 0) {
- if (oldCap >= MAXIMUM_CAPACITY) {
- // 如果旧容量达到了最大容量,则不再进行扩容
- threshold = Integer.MAX_VALUE;
- return oldTab;
- } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
- oldCap >= DEFAULT_INITIAL_CAPACITY)
- // 如果旧容量的两倍小于最大容量并且旧容量大于默认初始容量(16),则容量扩大为两部,扩容门槛也扩大为两倍
- newThr = oldThr << 1; // double threshold
- } else if (oldThr > 0) // initial capacity was placed in threshold
- // 使用非默认构造方法创建的map,第一次插入元素会走到这里
- // 如果旧容量为0且旧扩容门槛大于0,则把新容量赋值为旧门槛
- newCap = oldThr;
- else { // zero initial threshold signifies using defaults
- // 调用默认构造方法创建的map,第一次插入元素会走到这里
- // 如果旧容量旧扩容门槛都是0,说明还未初始化过,则初始化容量为默认容量,扩容门槛为默认容量*默认装载因子
- newCap = DEFAULT_INITIAL_CAPACITY;
- newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
- }
- if (newThr == 0) {
- // 如果新扩容门槛为0,则计算为容量*装载因子,但不能超过最大容量
- float ft = (float) newCap * loadFactor;
- newThr = (newCap < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ?
- (int) ft : Integer.MAX_VALUE);
- }
- // 赋值扩容门槛为新门槛
- threshold = newThr;
- // 新建一个新容量的数组
- @SuppressWarnings({"rawtypes", "unchecked"})
- Node<K, V>[] newTab = (Node<K, V>[]) new Node[newCap];
- ....
- }
根据桶扩容的代码,我们可以得出下面三个点:(扩容门槛就是指当数组容量为多少时候进行扩容)
- 如果使用是默认构造方法,则第一次插入元素时初始化为默认值,容量为16,扩容门槛为12,扩容门槛=当前容量*扩容因子,扩容因子默认为0.75;
- 如果使用的是非默认构造方法,则第一次插入元素时初始化容量等于扩容门槛,扩容门槛在构造方法里等于传入容量向上最近的2的n次方;
- 如果旧容量大于0,则新容量等于旧容量的2倍,但不超过最大容量2的30次方,新扩容门槛为旧扩容门槛的2倍;
在桶方面,就是这些了。继续看看关于它的链表。
HashMap中的链表
首先对链表要进行一下回忆,什么是链表?链表就是一个结构体,有头有尾。有Next指向。
- static class Node<K,V> implements Map.Entry<K,V> {
- final int hash;
- final K key;
- V value;
- Node<K,V> next;
- }
HashMap里面用的就是单链表节点,但是它除了存入节点值value外,还有一个变量,就是int类型的hash值。
都清楚HashMap中,链表是存放在桶中,那么,问题来了,关于这个链表,是通过什么标记来存入桶中的。
通过随机数来随机存??那样太不严谨了,同时在查找的时候,怎么才能找到这个key呢?这又是一个问题。那么,关键点就在于这个int类型的hash变量的。
1.int类型的hash值,我们看下源码hash(Object key)
- static final int hash(Object key) {
- int h;
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
小总结:通过key的hash值,并让高16位与整个hash异或
这样做是为了使计算出的hash更分散。在看它是怎么put进桶内,
查看put方法
- final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
- boolean evict) {
- Node<K, V>[] tab;
- Node<K, V> p;
- int n, i;
- // 如果桶的数量为0,则初始化
- if ((tab = table) == null || (n = tab.length) == 0)
- // 调用resize()初始化
- n = (tab = resize()).length;
- // (n - 1) & hash 计算元素在哪个桶中
- // 如果这个桶中还没有元素,则把这个元素放在桶中的第一个位置
- if ((p = tab[i = (n - 1) & hash]) == null)
- // 新建一个节点放在桶中
- tab[i] = newNode(hash, key, value, null);
- ....
- ....
- }
通过代码(n-1)&hash。现在就是以我们上一步得到的高16位和整个hash异或运算得到的值在于桶内长度进行与运算,解释就是如下。假如我们桶的长度是16,异或运算得出的值为11011
其实,这个算法就是取模运算,11011十进制就是27,27%16 = 11,使用位运算就是因为位运算比取模运算快很多很多。
现在又得出了另一个知识点,HashMap在确定node存放的数组位置是通过位运算通过与来得到取模的值来确定桶的位置。
同时,解决了一个疑问:为什么HashMap桶的容量总是2的n次方。因为2的n次方可以保证,每次的取模运算与上的桶大小值用二进制表示都是1111111...比如桶个数为16,那它就是(16-1)的二进制是1111,32就是(32-1)的二进制是11111
同时在为空的桶中,创建一条node。
那问题又来了,key的值虽然不同,但是他们的hash值可以相同,那么这样又是怎么解决。那么这就是HashMap使用链表的理由。(hash值相同,哈希冲突)
hash相等怎么办
查看put方法
- else {
- // 如果桶中已经有元素存在了
- Node<K, V> e;
- K k;
- // 如果桶中第一个元素的key与待插入元素的key相同,保存到e中用于后续修改value值
- if (p.hash == hash &&
- ((k = p.key) == key || (key != null && key.equals(k))))
- e = p;
- else if (p instanceof TreeNode)
- // 如果第一个元素是树节点,则调用树节点的putTreeVal插入元素
- e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
- else {
- // 遍历这个桶对应的链表,binCount用于存储链表中元素的个数
- for (int binCount = 0; ; ++binCount) {
- // 如果链表遍历完了都没有找到相同key的元素,说明该key对应的元素不存在,则在链表最后插入一个新节点
- if ((e = p.next) == null) {
- p.next = newNode(hash, key, value, null);
- // 如果插入新节点后链表长度大于8,则判断是否需要树化,因为第一个元素没有加到binCount中,所以这里-1
- if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
- treeifyBin(tab, hash);
- break;
- }
- ....
- ....
- }
这个源码涉及到了树化和key相等的情况,稍后再讲。
但是根据这上面那串源码,发现如果确定的桶位置中已有链表,那直接在尾部插入元素。这里又是HashMap在1.8的一个优化,在1.8以前,插入的算法是使用的头插法,可以想想,如果使用头插法,每次新插入的node都需要移位。那在并发状态下必然会发生问题。而使用尾插法,就可以直接在尾部插入,不需要其他node移位。
所以,这一步,得出结论,在hashMap中如果hash相同,那么就使用的链表结构,通过尾插法在链表中保存元素。
key相同怎么办
还是看put方法
- // 如果待插入的key在链表中找到了,则退出循环
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- break;
- p = e;
- }
- }
- // 如果找到了对应key的元素
- if (e != null) { // existing mapping for key
- // 记录下旧值
- V oldValue = e.value;
- // 判断是否需要替换旧值
- if (!onlyIfAbsent || oldValue == null)
- // 替换旧值为新值
- e.value = value;
- ....
- ....
- }
所以,这就是HashMap中key不能重复的原因。
自己测试,写的代码如下
测试结果如下:

扩容链表的变化 (jdk1.8)
看resize()源码
- table = newTab;
- // 如果旧数组不为空,则搬移元素
- if (oldTab != null) {
- // 遍历旧数组
- for (int j = 0; j < oldCap; ++j) {
- Node<K, V> e;
- // 如果桶中第一个元素不为空,赋值给e
- if ((e = oldTab[j]) != null) {
- // 清空旧桶,便于GC回收
- oldTab[j] = null;
- // 如果这个桶中只有一个元素,则计算它在新桶中的位置并把它搬移到新桶中
- // 因为每次都扩容两倍,所以这里的第一个元素搬移到新桶的时候新桶肯定还没有元素
- if (e.next == null)
- newTab[e.hash & (newCap - 1)] = e;
- else if (e instanceof TreeNode)
- // 如果第一个元素是树节点,则把这颗树打散成两颗树插入到新桶中去
- ((TreeNode<K, V>) e).split(this, newTab, j, oldCap);
- else { // preserve order
- // 如果这个链表不止一个元素且不是一颗树
- // 则分化成两个链表插入到新的桶中去
- // 比如,假如原来容量为4,3、7、11、15这四个元素都在三号桶中
- // 现在扩容到8,则3和11还是在三号桶,7和15要搬移到七号桶中去
- // 也就是分化成了两个链表
- Node<K, V> loHead = null, loTail = null;
- Node<K, V> hiHead = null, hiTail = null;
- Node<K, V> next;
- do {
- next = e.next;
- // (e.hash & oldCap) == 0的元素放在低位链表中
- // 比如,3 & 4 == 0
- if ((e.hash & oldCap) == 0) {
- if (loTail == null)
- loHead = e;
- else
- loTail.next = e;
- loTail = e;
- } else {
- // (e.hash & oldCap) != 0的元素放在高位链表中
- // 比如,7 & 4 != 0
- if (hiTail == null)
- hiHead = e;
- else
- hiTail.next = e;
- hiTail = e;
- }
- } while ((e = next) != null);
- // 遍历完成分化成两个链表了
- // 低位链表在新桶中的位置与旧桶一样(即3和11还在三号桶中)
- if (loTail != null) {
- loTail.next = null;
- newTab[j] = loHead;
- }
- // 高位链表在新桶中的位置正好是原来的位置加上旧容量(即7和15搬移到七号桶了)
- if (hiTail != null) {
- hiTail.next = null;
- newTab[j + oldCap] = hiHead;
- }
- }
- }
- }
- }
- return newTab;
- }
在看看 jdk1.7
简单点说,就是通过高低位来完成链表的迁移。然后分成两个新链表,一次性的存放到对应的桶中。这也是HashMap在1.8的优化,在迁移链表,是一次性迁移的,再看看1.7,hashMap是怎么迁移元素的
- void transfer(Entry[] newTable, boolean rehash) {
- int newCapacity = newTable.length;
- for (Entry<K,V> e : table) {
- while(null != e) {
- Entry<K,V> next = e.next; //寻找到下一个节点..
- if (rehash) {
- e.hash = null == e.key ? 0 : hash(e.key);
- }
- int i = indexFor(e.hash, newCapacity); //重新获取hashcode
- e.next = newTable[i];
- newTable[i] = e;
- e = next;
- }
- }
- }
遍历node,然后重新获取hash,一个一个迁移链表元素,并发状态下,也会出现问题。
那么关于HashMap中的链表,可以总结以下几点:
- HashMap中,通过key的hash值与桶大小进行与运算确定的元素位置。
- HashMap在遇到hash值相等的情况,是使用的链表尾插法来存储新key的值,这也算是对之前的优化。
- HashMap中key不能重复,因为如果key重复,会覆盖旧值。
- HashMap扩容迁移元素,原链表分化成两个链表,低位链表存储在原来桶的位置,高位链表搬移到原来桶的位置加旧容量的位置。
现在,我们的HashMap就是这样一个结构了。
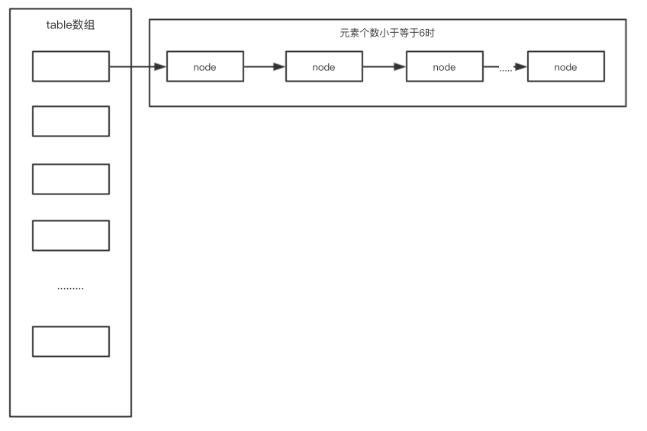
HashMap中的红黑树
红黑树是jdk1.8新加入的,当桶的数量大于64且单个桶中元素的数量大于8时,进行树化;当单个桶中元素数量小于6时,进行反树化。
不妨想想为什么要加入红黑树这样一个结构。
因为node是链表类型,链表这种数据结构,我们都知道,它增删快,但是查找慢。假如我们的node链表长度很长,那查找耗时是必然的,所以引入了红黑树这样一个结构。
后面介绍为什么桶的数量是64的时候进行树化(看源码即可)。
红黑树介绍
红黑树的本质上就是一颗二叉树,更确切的来说,红黑树是一颗平衡二叉树。叫它红黑树的原因是红黑树的每个节点上都有存储位表示节点的颜色,可以是红或黑。
梳理下红黑树的特性吧
红黑树具有以下5种性质:
- 节点是红色或黑色。
- 根节点是黑色。
- 每个叶节点(NIL节点,空节点)是黑色的。
- 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
这里要关于它的5中性质要注意两个
特性3中的叶子节点,是只为空(NIL或null)的节点。
特性5,确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树
红黑树的时间复杂度为O(log n),与树的高度成正比。
红黑树在查找元素的效率比链表高,但是增删元素的效率不如链表。这也算是一种取舍的。数组在增删慢,链表在查找慢,而树这种结构的特点夹在他们的中间。
hashMap中的红黑树定义
- static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
- TreeNode<K,V> parent; // red-black tree links
- TreeNode<K,V> left;
- TreeNode<K,V> right;
- TreeNode<K,V> prev; // needed to unlink next upon deletion
- boolean red;
- }
树化
- ....
- ....
- if ((e = p.next) == null) {
- p.next = newNode(hash, key, value, null);
- // 如果插入新节点后链表长度大于8,则判断是否需要树化,因为第一个元素没有加到binCount中,所以这里-1
- if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
- treeifyBin(tab, hash);
- break;
- }
- ....
- ....
树化的代码在这里。TREEIFY_THRESHOLD的默认值是8
static final int TREEIFY_THRESHOLD = 8;
所以,HashMap在链表元素大于等于8时,会开始进行树化。
- final void treeifyBin(Node<K, V>[] tab, int hash) {
- int n, index;
- Node<K, V> e;
- if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
- // 如果桶数量小于64,直接扩容而不用树化
- // 因为扩容之后,链表会分化成两个链表,达到减少元素的作用
- // 当然也不一定,比如容量为4,里面存的全是除以4余数等于3的元素
- // 这样即使扩容也无法减少链表的长度
- resize();
- else if ((e = tab[index = (n - 1) & hash]) != null) {
- TreeNode<K, V> hd = null, tl = null;
- // 把所有节点换成树节点
- do {
- TreeNode<K, V> p = replacementTreeNode(e, null);
- if (tl == null)
- hd = p;
- else {
- p.prev = tl;
- tl.next = p;
- }
- tl = p;
- } while ((e = e.next) != null);
- // 如果进入过上面的循环,则从头节点开始树化
- if ((tab[index] = hd) != null)
- hd.treeify(tab);
- }
- }
还记得另外一个条件嘛,就是桶的数量要大于64,这也是MIN_TREEIFY_CAPACITY的默认值。
static final int MIN_TREEIFY_CAPACITY = 64;
反树化
反树化只有在扩容和remove元素时才会发生,先看resize方法
- else if (e instanceof TreeNode)
- ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
这就是判断它是否需要反树化的方法
- final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
- TreeNode<K,V> b = this;
- // Relink into lo and hi lists, preserving order
- TreeNode<K,V> loHead = null, loTail = null;
- TreeNode<K,V> hiHead = null, hiTail = null;
- int lc = 0, hc = 0;
- for (TreeNode<K,V> e = b, next; e != null; e = next) {
- next = (TreeNode<K,V>)e.next;
- e.next = null;
- if ((e.hash & bit) == 0) {
- if ((e.prev = loTail) == null)
- loHead = e;
- else
- loTail.next = e;
- loTail = e;
- ++lc;
- }
- else {
- if ((e.prev = hiTail) == null)
- hiHead = e;
- else
- hiTail.next = e;
- hiTail = e;
- ++hc;
- }
- }
- if (loHead != null) {
- if (lc <= UNTREEIFY_THRESHOLD)
- tab[index] = loHead.untreeify(map);
- else {
- tab[index] = loHead;
- if (hiHead != null) // (else is already treeified)
- loHead.treeify(tab);
- }
- }
- if (hiHead != null) {
- if (hc <= UNTREEIFY_THRESHOLD)
- tab[index + bit] = hiHead.untreeify(map);
- else {
- tab[index + bit] = hiHead;
- if (loHead != null)
- hiHead.treeify(tab);
- }
- }
- }
主要还是根据高低位判断,来切割树,然后判断树中元素是不是<=UNTREEIFY_THRESHOLD
其实UNTREEIFY_THRESHOLD的默认值就是6。
- if (root == null
- || (movable
- && (root.right == null
- || (rl = root.left) == null
- || rl.left == null))) {
- tab[index] = first.untreeify(map); // too small
- return;
- }
看源码的注释。太小了,所以反树化,根据判断条件树的高度不超过3,就反树化了。
那么,总的来说,Jdk1.8的HashMap长的就是这个样子。
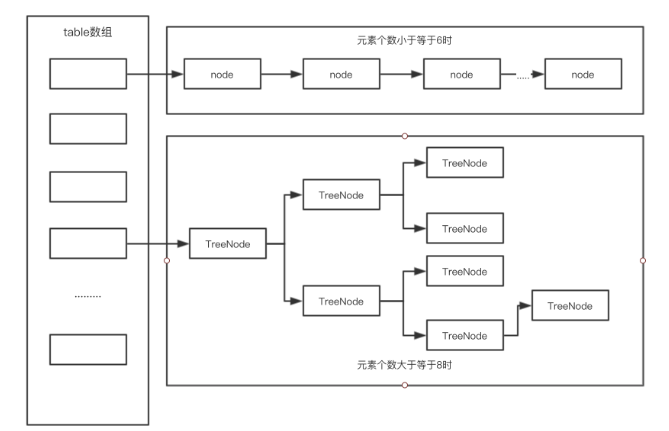
总结
总的来说,hashMap在Jdk就是数组+链表+红黑树的结构。
关于hashMap数组:
- HashMap的默认初始容量为16(1<<4),默认装载因子为0.75f,容量总是2的n次方;
- HashMap扩容时每次容量变为原来的两倍;
关于hashMap链表:
- HashMap链表在增加元素是通过尾插法实现的
- HashMap链表扩容是采用高低位来分割链表一次性迁移到新的桶
关于hashMap红黑树:
- 当桶的数量小于64时不会进行树化,只会扩容;
- 当桶的数量大于64且单个桶中元素的数量大于8时,进行树化;
- 当单个桶中元素数量小于6时,进行反树化;
hashMap在Jdk 1.8的更新:
- 插入链表的方式采用尾插法插入。旧的方法是头插法。
- 迁移元素根据高低位分割元素一次性迁移。旧的方法是遍历链表,一次一次重新计算桶位置然后一个一个迁移。
- 加入了红黑树的结构。
HashMap 底层探索的更多相关文章
- HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别(转)
HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别 文章来源:http://www.cnblogs.com/beatIteWeNerverGiveU ...
- hashMap底层put和get方法逻辑
1.hashmap put方法的实现: public V put(K key, V value) { if (key == null) return putForNullKey(value); int ...
- ArrayList、LinkedList、HashMap底层实现
ArrayList 底层的实现就是一个数组(固定大小),当数组长度不够用的时候就会重新开辟一个新的数组,然后将原来的数据拷贝到新的数组内. LinkedList 底层是一个链表,是由java实现的一个 ...
- HashMap底层实现原理
HashMap底层实现 HashMap底层数据结构如下图,HashMap由“hash函数+数组+单链表”3个要素构成 通过写一个迷你版的HashMap来深刻理解 MyMap接口,定义一个接口,对外暴露 ...
- HashMap底层结构、原理、扩容机制
https://www.jianshu.com/p/c1b616ff1130 http://youzhixueyuan.com/the-underlying-structure-and-princip ...
- HashMap 底层分析
以下基于 JDK1.7 分析 如图所示,HashMap底层是基于数组和链表实现的,其中有两个重要的参数: ---容量 ---负载因子 容量的默认大小是16,负载因子是0.75,当HashMap的siz ...
- 最简单的HashMap底层原理介绍
HashMap 底层原理 1.HashMap底层概述 2.JDK1.7实现方式 3.JDK1.8实现方式 4.关键名词 5.相关问题 1.HashMap底层概述 在JDK1.7中HashMap采用的 ...
- HashMap底层原理分析(put、get方法)
1.HashMap底层原理分析(put.get方法) HashMap底层是通过数组加链表的结构来实现的.HashMap通过计算key的hashCode来计算hash值,只要hashCode一样,那ha ...
- HashMap底层原理
原文出自:http://zhangshixi.iteye.com/blog/672697 1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射 ...
随机推荐
- [科普向] Roguelike游戏到底是什么?
简单的说 Roguelike 是 RPG(角色扮演游戏)的一个分支,也是最重要的一个分支.这个名字源于 1980 年发布的著名电子游戏<Rogue>.按字面上理解,Roguelike 就是 ...
- Redis linux 下安装
Redis linux 下安装 下载Redis安装包,可以从Redis中文网站中下载 下载地址:http://www.redis.cn/download.html Redis4.0 稳定版本 使用&l ...
- Gallery实现图片拖动切换
Gallery中文意思为画廊,通过Gallery能够实现用手指在屏幕上滑动实现图片的拖动.效果如下: 上面,为了学习了解,只用了android默认的Icon图片. 主程序中创建了一个继承自BaseAd ...
- 基于linux或windows平台上的c/s简单通信
linux: tcpclient.cpp #include<iostream> #include<unistd.h> #include<sys/types.h> # ...
- x86汇编之栈与子程序调用
什么是栈 栈与普通数据结构所说的栈的概念是相似的,遵循后进先出原则.不同的是汇编中所说的栈是一个在内存中连续的保存数据的区域,也即是实际存在的内存区域,进栈和出栈遵循后进先出原则. 在x86架构中,栈 ...
- D - Three Integers CodeForces - 1311D
题意: a<=b<=c 输出A,B,C要求B是A的倍数,C是B的倍数,并且输出a,b,c变成A,B,C需要的最小次数. 题解:写了半天的二分,后来发现思路错了,,,暴力就能过.. 三层fo ...
- 关于树的重心--POJ 1655
树的重心的定义: 在一棵树中,找到一个点,其所有的子树中最大的子树节点数最少,那么这个点就是这棵树的重心,删去重心后,生成的多棵树尽可能平衡. 通俗来说就是以这个点为根节点,找到他最大的衣蛾子树,然后 ...
- .NET Core3.1总体预览和第一个Core程序的创建
小伙伴们大家好!欢迎阅读本贴,这里是常哥说编程的专栏,.NetCore已经出来一段时间了,很多小伙伴可能也开始了学习,但是.NetCore毕竟在学习上和我们常用的.NET Framework还是有很大 ...
- Java 导出Excel xlsx、xls, CSV文件
通用导出功能: 1.支持Excel xlsx.xls 2.支持CSV文件导出 3.数据库查询分页导出.内存导出 4.支持大批量数据导出 使用步骤如下 导入jar <dependency> ...
- PE文件学习(1)DOS和NT
大致结构 DOS头和NT头之间通常还有个DOS Stub DOS头 DOS头的作用是兼容MS-DOS操作系统中的可执行文件 一般没啥用 记录着PE头的位置 DOS头定义部分 typedef struc ...