Glusterfs的安装、创建卷、配置和优化卷、挂载使用
一、网站推荐
1、https://gluster.readthedocs.io/en/latest/ 这是官方的说明网站。这里面有安装Glusterfs原理,安装流程,各种卷的原理、创建方式、以及使用领域的说明。推荐直接访问官方网站学习使用。
2、https://download.gluster.org/pub/gluster/glusterfs 这是官方的资源网站。这里面有各种系统的Glusterfs资源下载路径。
二、安装流程(需要在每台服务器上操作)
假设我们有三台测试机分别是192.168.1.11 192.168.1.22 192.168.1.33,三台需要同时安装服务端和客户端。
常用术语简介(可去http://gluster.readthedocs.io/en/latest/Quick-Start-Guide/Terminologies/ 查看学习)
Brick: GFS中的存储单元,通过是一个受信存储池中的服务器的一个导出目录。可以通过主机名和目录名来标识,如'SERVER:EXPORT'
Client: 挂载了GFS卷的设备
Extended Attributes: xattr是一个文件系统的特性,其支持用户或程序关联文件/目录和元数据。
FUSE: Filesystem Userspace是一个可加载的内核模块,其支持非特权用户创建自己的文件系统而不需要修改内核代码。通过在用户空间运行文件系统的代码通过FUSE代码与内核进行桥接。
Node: 一个拥有若干brick的设备
Volume: 一组bricks的逻辑集合
1、查看系统版本,根据版本选择安装方式(常用的有Ubuntu、Red Hat等)
#cat /proc/version;


2、查看ip
#ifconfig;
3、配置/etc/hosts
#sudo echo "192.168.1.11 dn11" >> /etc/hosts;
#sudo echo "192.168.1.22 dn22" >> /etc/hosts;
#sudo echo "192.168.1.33 dn33" >> /etc/hosts;
#cat /etc/hosts;
4、更改主机名称
1)#hostname; #查看主机名 如果是localhost.localdomain就说明是默认的,现在我们把它改成我们自己主机名,
2)#sudo vim /etc/sysconfig/network; #重启后生效,临时生效可以直接hostname 主机名的方式
说明:也可以用以下命令更改主机名
#hostnamectl --static set-hostname dn11; #192.168.1.11上执行
#hostnamectl --static set-hostname dn22; #192.168.1.22上执行
#hostnamectl --static set-hostname dn33; #192.168.1.33上执行
5、安装glusterfs部分包依赖的epel源
#yum -y install epel-release;
6、安装资源包
#yum install centos-release-gluster -y
7、查看可用的资源包
#yum list glusterfs --showduplicates | sort -r;
8、添加下载配置源文件
#sudo vim /etc/yum.repos.d/gluster-epel.repo;
# CentOS-Gluster-6.repo
#
# Please see http://wiki.centos.org/SpecialInterestGroup/Storage for more
# information
[centos-gluster6]
name=CentOS-$releasever - Gluster 6
mirrorlist=http://mirrorlist.centos.org?arch=$basearch&release=$releasever&repo=storage-gluster-6
#baseurl=http://mirror.centos.org/$contentdir/$releasever/storage/$basearch/gluster-6/
gpgcheck=1
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-SIG-Storage
[centos-gluster6-test]
name=CentOS-$releasever - Gluster 6 Testing
baseurl=http://buildlogs.centos.org/centos/$releasever/storage/$basearch/gluster-6/
gpgcheck=0
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-SIG-Storage
9、安装Glusterfs
#yum -y install glusterfs-server glusterfs-fuse;
注意:上面5、6、7、8、9是在Red Hat上操作,Ubuntu上对应操作连接:https://launchpad.net/~gluster/+archive/ubuntu/glusterfs-6
Ubuntu对应的命令如下:
#add-apt-repository ppa:gluster/glusterfs-6
#apt-get update
10、开启glusterd服务
#systemctl enable glusterd.service
#systemctl start glusterd.service (或者service glusterd start)
#systemctl status glusterd.service
#chkconfig glusterd on (增添开机启动)
11、关闭selinux
#sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux /etc/selinux/config;
12、防火墙设置
#firewall-cmd --zone=public --permanent --add-port=24007-24008/tcp --add-port=49152-49158/tcp --add-port=38465-38469/tcp --add-port=111/tcp --add-port=111/udp --add-port=2049/tcp;
#firewall-cmd --reload;
13、磁盘准备:
每台服务器准备1-2T的磁盘用于文件系统数据存储;
14、磁盘挂载
14.1 查看磁盘信息
fdisk -l;

14.2 格式化磁盘
#mkfs.xfs /dev/sda3;
14.3 创建磁盘挂载路径
#mkdir -p /data/brick1;
14.4 磁盘开机自动挂载方式
#echo '/dev/sda3 /data/brick1 xfs defaults 1 2' >> /etc/fstab;
#mount -a && mount;
14.5 磁盘非开机自动挂载方式
mount /dev/sda3 /data/brick1;
*说明:没有磁盘也是可以的,创建卷的时候加上 force
三、创建卷(任意一台服务器上操作即可)
1、配置授信池
#gluster peer probe dn11
#gluster peer probe dn22
#gluster peer probe dn33
#gluster peer status 查看状态
(#gluster peer detach dn11 #在集群中删除节点dn11)
注意:这里的节点可以替换成对应的ip如:#gluster peer probe 192.168.1.11
2、卷操作(可以去官网上看,https://gluster.readthedocs.io/en/latest/ )
2.1 创建一个复制卷(可以在任意一台服务器上执行,本例在dn11上执行)
#gluster volume create Distributed-Replicate-volume replica 2 transport tcp dn11:/fleetDatas dn22:/fleetDatas force
2.2 启动卷
#gluster volume start Distributed-Replicate-volume
2.3 查看卷信息
#gluster volume info Distributed-Replicate-volume
2.4 停止、删除卷(慎操作)
#gluster volume stop Distributed-Replicate-volume 停止卷
#gluster volume delete Distributed-Replicate-volume 删除卷
四、配置(任意一台操作即可)
1、设置允许挂载范围,注意默认是允许所有客户端,哪怕不在授信池内的客户端
sudo gluster volume set Distributed-Replicate-volume auth.allow dn11,dn22,dn33;
2、开启ACL支持
sudo gluster volume set Distributed-Replicate-volume acl on
3、设置磁盘剩余空间最小阈值,达到这个值就不能再继续写入数据了
sudo gluster volume set Distributed-Replicate-volume cluster.min-free-disk 15;
4、设置请求等待超时时间,默认1800秒,设置范围0-1800秒,读写的数据超过1800秒未返回结果就认为超时
sudo gluster volume set Distributed-Replicate-volume network.frame-timeout 1500;
5、设置客户端检测服务器可用超时时间,默认42秒,范围为0-42秒
sudo gluster volume set Distributed-Replicate-volume network.ping-timeout 20;
6、关闭NFS服务,默认为开启
sudo gluster volume set Distributed-Replicate-volume nfs.disable off;
7、设置IO线程数,默认为16,范围为0-65
sudo gluster volume set Distributed-Replicate-volume performance.io-thread-count 32;
8、设置缓存数据校验周期,默认为1秒,默认为0-61秒,如果同时有多个用户在读写一个文件,一个用户更新了数据,另一个用户在Cache刷新周期到来前可能读到非最新的数据,即无法保证数据的强一致性。因此实际应用时需要在性>能和数据一致性之间进行折中,如果需要更高的数据一致性,就得调小缓存刷新周期,甚至禁用读缓存;反之,是可以把缓存周期调大一点,以提升读性能
sudo gluster volume set Distributed-Replicate-volume performance.cache-refresh-timeout 2;
9、设置读缓存大小,单位为字节,默认大小为32M
sudo gluster volume set Distributed-Replicate-volume performance.cache-size 128MB;
10、启用对小文件的优化性能,默认即为打开
sudo gluster volume set Distributed-Replicate-volume performance.quick-read on;
11、设置文件预读,用预读的方式提高读取的性能,读取操作前就预先抓取数据,这个有利于应用频繁持续性的访问文件,当应用完成当前数据块读取的时候,下一个数据块就已经准备好了,预读处理有page-size和page-count来定义,page-size定义了,一次预读取的数据块大小,page-count定义的是被预读取的块的数量,不过官方网站上说这个中继在以太网上没有必要,一般都能跑满带宽。主要是在IB-verbs或10G的以太网上用。
sudo gluster volume set Distributed-Replicate-volume performance.read-ahead on;
12、设置在写数据的时候先写入到缓存再写入到磁盘,以提高写入性能,默认为开启
sudo gluster volume set Distributed-Replicate-volume performance.nfs.write-behind on
13、缓存已经读过的数据,默认即开启,结合上面的performance.quick-read和performance.read-ahead使用
sudo gluster volume set Distributed-Replicate-volume performance.io-cache on;
14、开启磁盘修复功能(只适用于复制卷或分布式复制卷)
sudo gluster volume heal Distributed-Replicate-volume full;
15、查看磁盘状况
sudo gluster volume heal Distributed-Replicate-volume info;
16、查看卷信息
sudo gluster volume info Distributed-Replicate-volume;
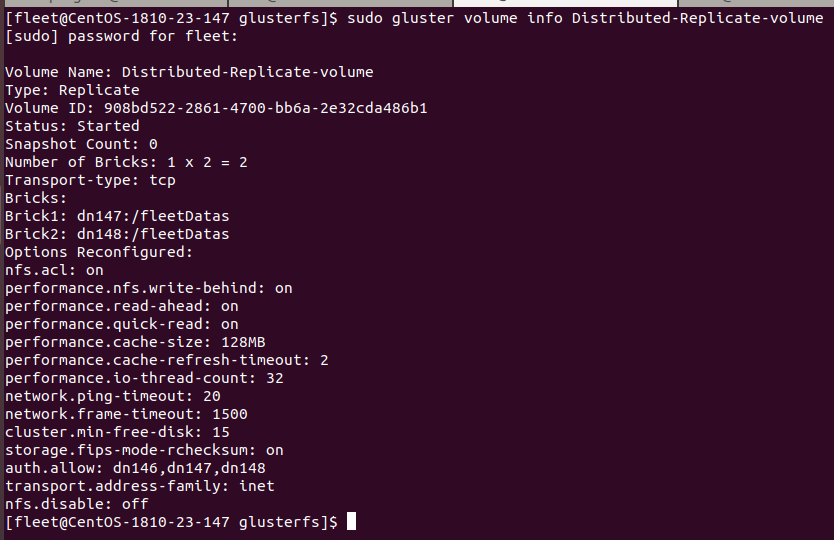
17、清空一个选项的参数,如清空acl的配置
sudo gluster volume reset Distributed-Replicate-volume acl force;
18、查看一个选项的参数,如查看acl的配置
sudo gluster volume get Distributed-Replicate-volume acl;
五、挂载使用(在auth.allow配置下的任意客户端都可以执行)
1、创建一个挂载路径
#mkdir -p /home/Distributed-Replicate-volume-test;
2、 文件系统开机自动挂载方式
#sudo echo "192.168.1.11:/Distributed-Replicate-volume /home/Distributed-Replicate-volume-test glusterfs defaults,_netdev,acl 0 0" >> /etc/fstab;
#mount -a && mount
3、文件系统非开机自动挂载方式
sudo mount -t glusterfs -o acl dn11:/Distributed-Replicate-volume /home/Distributed-Replicate-volume-test;
说明:上诉两种挂载方式是在开启了acl配置的前提下,如果没有开启acl配置,去掉acl的参数即可。
4、卸载文件系统挂载
#sudo umount /home/Distributed-Replicate-volume-test;
六、结束感言:
创作不易,如果对你有帮助,请帮忙点赞、收藏,谢谢!
=========================结束!=========================
Glusterfs的安装、创建卷、配置和优化卷、挂载使用的更多相关文章
- 自动安装php7(配置未优化版本)
#!/bin/bash #by dxd - #only suit for centos/aliyun os, and based on aliyun install script CURR_PATH= ...
- Tomcat8安装, 安全配置与性能优化(转)
一.Tomcat 安装 官网:http://tomcat.apache.org/ Tomcat8官网下载地址:http://tomcat.apache.org/download-80.cgi 为了便于 ...
- 实战Nginx与PHP(FastCGI)的安装、配置与优化
一.什么是 FastCGIFastCGI是一个可伸缩地.高速地在HTTP server和动态脚本语言间通信的接口.多数流行的HTTP server都支持FastCGI,包括Apache.Nginx和l ...
- Tomcat8安装, 安全配置与性能优化
一.Tomcat 安装 官网:http://tomcat.apache.org/ Tomcat8官网下载地址:http://tomcat.apache.org/download-80.cgi 为了便于 ...
- 【转】实战Nginx与PHP(FastCGI)的安装、配置与优化
原文连接:http://ixdba.blog.51cto.com/2895551/806622 原文作者:南非蚂蚁 转载注明以上信息 一.什么是 FastCGIFastCGI是一个可伸缩地.高速地在H ...
- Linux LVM逻辑卷配置过程详解(创建,增加,减少,删除,卸载)
Linux LVM逻辑卷配置过程详解 许多Linux使用者安装操作系统时都会遇到这样的困境:如何精确评估和分配各个硬盘分区的容量,如果当初评估不准确,一旦系统分区不够用时可能不得不备份.删除相关数据, ...
- php-fpm安装、配置与优化
转载自:https://www.zybuluo.com/phper/note/89081 1.php中fastcgi和php-fpm是什么东西 最近在研究和学习PHP的性能方面的知识,看到了factc ...
- 【收藏】实战Nginx与PHP(FastCGI)的安装、配置与优化
拜读南非蚂蚁大牛的文章真是有所收获 http://ixdba.blog.51cto.com/2895551/806622 一.什么是 FastCGI FastCGI是一个可伸缩地.高速地在HTTP s ...
- Mysql的安装、配置、优化
Mysql的安装.配置.优化 安装步骤 1.先单击中的安装文件,如果是win7系统,请选择以管理员的方式运行. 2.大概需要30秒的时间,开始进入安装界面.请先把标红的打勾,好进行下一步的动作. 3. ...
随机推荐
- Java实现 LeetCode 面试题 01.07. 旋转矩阵(按照xy轴转+翻转)
面试题 01.07. 旋转矩阵 给你一幅由 N × N 矩阵表示的图像,其中每个像素的大小为 4 字节.请你设计一种算法,将图像旋转 90 度. 不占用额外内存空间能否做到? 示例 1: 给定 mat ...
- Java实现 LeetCode 491递增子序列
491. 递增子序列 给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2. 示例: 输入: [4, 6, 7, 7] 输出: [[4, 6], [4, 7], [4, ...
- Java实现蓝桥杯打印图形
标题:打印图形 如下的程序会在控制台绘制分形图(就是整体与局部自相似的图形). 当n=1,2,3的时候,输出如下: 请仔细分析程序,并填写划线部分缺少的代码. n=1时: o ooo o n=2时: ...
- 洛谷 P1115 最大子序和
**原题链接** ##题目描述 给出一段序列,选出其中连续且非空的一段使得这段和最大. **解法**: 1.暴力枚举 时间:O(n^3) 2.简单优化 时间:O(n ...
- 利用mitmproxy实现抖音Cookie,设备ID获取(一)
先讲解一下思路,是利用mitmproxy代理https协议,从而判定抖音个人信息接口,在个人信息接口的返回体接收时将用户信息数据,以及Header头(主要是Cookie),Query体(包含设备ID) ...
- 使用PyQtGraph绘制图形(1)
首先利用numpy模块创建两个随机数组,用来作为图形绘制的数据: import pyqtgraph as pg import numpy as np x = np.random.random(50) ...
- [Google Guava] 强大的集合工具类:java.util.Collections中未包含的集合工具
转载的,有问题请联系我 原文链接 译文链接 译者:沈义扬,校对:丁一 尚未完成: Queues, Tables工具类 任何对JDK集合框架有经验的程序员都熟悉和喜欢java.util.Collecti ...
- 附022.Kubernetes_v1.18.3高可用部署架构一
kubeadm介绍 kubeadm概述 参考附003.Kubeadm部署Kubernetes. kubeadm功能 参考附003.Kubeadm部署Kubernetes. 本方案描述 本方案采用kub ...
- FR6安装问题备注
好久以前偶尔用用FR,采用安装执行文件的方式(5.3版安装没问题).及其编译包的方式都没有问题,最近在6.x提示如下(fr6_5_11_all_ent等),不知是系统原因还是文件问题,未解: ---- ...
- mysql小数类型
原文链接:https://blog.csdn.net/weixin_42047611/article/details/81449663 MySQL 中使用浮点数和定点数来表示小数. 浮点类型有两种,分 ...