GAN网络从入门教程(二)之GAN原理
在一篇博客GAN网络从入门教程(一)之GAN网络介绍中,简单的对GAN网络进行了一些介绍,介绍了其是什么,然后大概的流程是什么。
在这篇博客中,主要是介绍其数学公式,以及其算法流程。当然数学公式只是简单的介绍,并不会设计很复杂的公式推导。如果想详细的了解GAN网络的原理,推荐去看李宏毅老师的课程。B站和Youtube上面都有。
概率分布
生成器
首先我们是可以知道真实图片的分布函数\(p_{data}(x)\),同时我们把假的图片也看成一个概率分布,称之为\(p_g = (x,\theta)\)。那么我们的目标是什么呢?我们的目标就是使得\(p_g(x,\theta)\)尽量的去逼近\(p_{data}(x)\)。在GAN中,我们使用神经网络去逼近\(p_g = (x,\theta)\)。
在生成器中,我们有如下模型:
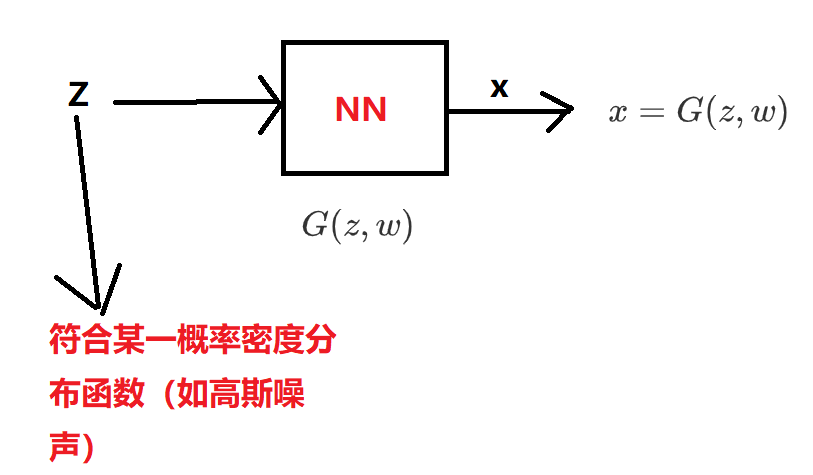
其中\(z \sim P_{z}(z)\),因此\(G(z)\)也是一个针对于\(z\)概率密度分布函数。
判别器
针对于判别器,我们有\(D(x,\theta)\),其代表某一张z图片\(x\)为真的概率。
目标函数
在Generative Adversarial Nets论文中给出了以下的目标函数,也就是GAN网络需要优化的东西。
\]
公式看起来很复杂,但是我们分开来看还是比较简单的。
\(D^*\)
\(D\)网络的目标是什么?能够辨别真假,也就是说,给定一张真的图片\(x\),\(D\)网络能够给出一个高分,也就是\(D(x)\)尽量大一点。而针对于生成器\(G\)生成的图片\(G(z)\),我们希望判别器\(D\)尽量给低分,也就是\(D(G(z))\)尽量的小一点。因此\(D\)网络的目标函数如下所示:
\]
在目标函数中,\(x\)代表的是真实数据(也就是真的图片),\(G(z)\)代表的是生成器生成的图片。
\(G^*\)
\(G\)网络的目标就是使得\(D(G(z))\)尽量得高分,因此其目标函数可以写成:
\]
\(D(G(z))\)尽量得高分(分数在\([0,1]\)之间),等价于\(1 - D(G(z))\)尽量的低分,因此,上述目标函数等价于:
\]
因此我们优化\(D^*\)和优化\(G^*\)结合起来,也就是变成了论文中的目标函数:
\]
证明存在全局最优解
上面的公式看起来很合理,但是如果不存在最优解的话,一切也都是无用功。
D最优解
首先,我们固定G,来优化D,目标函数为:
\(\begin{equation} V(G, D)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))]\end{equation}\)
我们可以写做:
V(G, D) &=\int_{\boldsymbol{x}} p_{\text {data }}(\boldsymbol{x}) \log (D(\boldsymbol{x})) d x+\int_{\boldsymbol{z}} p_{\boldsymbol{z}}(\boldsymbol{z}) \log (1-D(g(\boldsymbol{z}))) d z \\
&=\int_{\boldsymbol{x}} [ p_{\text {data }}(\boldsymbol{x}) \log (D(\boldsymbol{x}))+p_{g}(\boldsymbol{x}) \log (1-D(\boldsymbol{x}))] d x
\end{aligned}\end{equation}
\]
我们设(\(D\)代表\(D(x)\),可以代表任何函数):
\]
对于每一个固定的\(x\)而言,为了使\(V\)最大,我们当然是希望\(f(D)\)越大越好,这样积分后的值也就越大。因为固定了\(G\),因此\(p_g(x)\)是固定的,而\(P_{data}\)是客观存在的,则值也是固定的。我们对\(f(D)\)求导,然后令\(f'(D) = 0\),可得:
\]
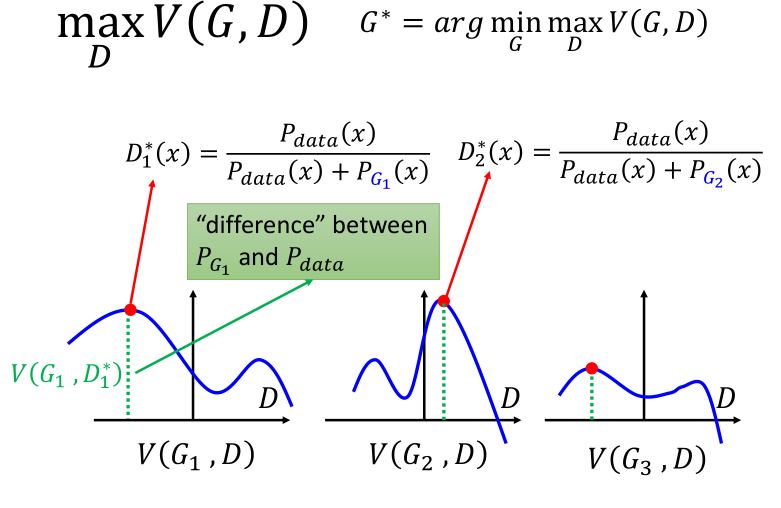
下图表示了,给定三个不同的 \(G1,G3,G3\) 分别求得的令 \(V(G,D)\)最大的那个$ D^∗\(,横轴代表了\)P_{data}$,蓝色曲线代表了可能的 \(P_G\),绿色的距离代表了 \(V(G,D)\):
G最优解
同理,我们可以求\(\underset{D}{max}\ V(G,D)\),我们将前面的得到的\(D^{*}=\frac{P_{d a t a}(x)}{P_{d a t a}(x)+P_{G}(x)}\)带入可得:
\begin{align}
& \underset{D}{min}\ V(G,D) \\
& = V(G,D^{* })\\
& = E_{x \sim P_{data} } \left [\ log\ D^{* }(x) \ \right ] + E_{x \sim P_{G} } \left [\ log\ (1-D^{* }(x)) \ \right ] \\
& = E_{x \sim P_{data} } \left [\ log\ \frac{P_{data}(x)}{P_{data}(x)+P_G(x)} \ \right ] + E_{x \sim P_{G} } \left [\ log\ \frac{P_{G}(x)}{P_{data}(x)+P_G(x)} \ \right ]\\
& = \int_{x} P_{data}(x) log \frac{P_{data}(x)}{P_{data}(x)+P_G(x)} dx+ \int_{x} P_G(x)log(\frac{P_{G}(x)}{P_{data}(x)+P_G(x)})dx \\
& = \int_{x} P_{data}(x) log \frac{\frac{1}{2}P_{data}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } dx+ \int_{x} P_{G}(x) log \frac{\frac{1}{2}P_{G}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } dx \\
& = \int_{x}P_{data}(x)\left ( log \frac{1}{2}+log \frac{P_{data}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } \right ) dx \\
& \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ + \int_{x}P_{G}(x)\left ( log \frac{1}{2}+log \frac{P_{G}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } \right ) dx \\
& = \int_{x}P_{data}(x) log \frac{1}{2} dx + \int_{x}P_{data}(x) log \frac{P_{data}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } dx \\
& \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ + \int_{x}P_{G}(x) log \frac{1}{2} dx + \int_{x}P_{G}(x) log \frac{P_{G}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } dx \\
& = 2 log \frac{1}{2} + \int_{x}P_{data}(x) log \frac{P_{data}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } dx + \int_{x}P_{G}(x) log \frac{P_{G}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } dx\\
& = 2 log \frac{1}{2} + 2 \times \left [ \frac{1}{2} KL\left( P_{data}(x) || \frac{P_{data}(x)+P_{G}(x)}{2}\right )\right ] \\
& \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ + 2 \times \left [ \frac{1}{2} KL\left( P_{G}(x) || \frac{P_{data}(x)+P_{G}(x)}{2}\right )\right ] \\
& = -2 log 2 + 2 JSD \left ( P_{data}(x) || P_G(x) \right)
\end{align} %]]>
\]
其中\(JSD ( P_{data}(x) || P_G(x))\)的取值范围是从 \(0\)到\(log2\),其中当\(P_{data} = P_G\)是,\(JSD\)取最小值0。也就是说$ V(G,D)$的取值范围是\(0\)到\(-2log2\),也就是说$ V(G,D)\(存在最小值,且此时\)P_{data} = P_G$。
算法流程
上述我们从理论上讨论了全局最优值的可行性,但实际上样本空间是无穷大的,也就是我们没办法获得它的真实期望(\(\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}\)和\(\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}(\boldsymbol{z})\)是未知的),因此我们使用估测的方法来进行。
\]
算法流程图如下所示(来自生成对抗网络——原理解释和数学推导):

总结
上述便是GAN网络的数学原理,以及推导流程还有算法。我也是刚开始学,参考了如下的博客,其中生成对抗网络——原理解释和数学推导非常值得一看,里面非常详细的对GAN进行了推导,同时,bilibili——【机器学习】白板推导系列(三十一) ~ 生成对抗网络(GAN)中的视频也不错,手把手白板的对公式进行了推导。如有任何问题,或文章有任何错误,欢迎在评论区下方留言。
参考
GAN网络从入门教程(二)之GAN原理的更多相关文章
- GAN网络从入门教程(一)之GAN网络介绍
GAN网络从入门教程(一)之GAN网络介绍 稍微的开一个新坑,同样也是入门教程(因此教程的内容不会是从入门到精通,而是从入门到入土).主要是为了完成数据挖掘的课程设计,然后就把挖掘榔头挖到了GAN网络 ...
- GAN网络之入门教程(五)之基于条件cGAN动漫头像生成
目录 Prepare 在上篇博客(AN网络之入门教程(四)之基于DCGAN动漫头像生成)中,介绍了基于DCGAN的动漫头像生成,时隔几月,序属三秋,在这篇博客中,将介绍如何使用条件GAN网络(cond ...
- GAN网络之入门教程(四)之基于DCGAN动漫头像生成
目录 使用前准备 数据集 定义参数 构建网络 构建G网络 构建D网络 构建GAN网络 关于GAN的小trick 训练 总结 参考 这一篇博客以代码为主,主要是来介绍如果使用keras构建一个DCGAN ...
- GAN网络从入门教程(三)之DCGAN原理
目录 DCGAN简介 DCGAN的特点 几个重要概念 下采样(subsampled) 上采样(upsampling) 反卷积(Deconvolution) 批标准化(Batch Normalizati ...
- SpringBoot入门教程(二)CentOS部署SpringBoot项目从0到1
在之前的博文<详解intellij idea搭建SpringBoot>介绍了idea搭建SpringBoot的详细过程, 并在<CentOS安装Tomcat>中介绍了Tomca ...
- 无废话ExtJs 入门教程二十一[继承:Extend]
无废话ExtJs 入门教程二十一[继承:Extend] extjs技术交流,欢迎加群(201926085) 在开发中,我们在使用视图组件时,经常要设置宽度,高度,标题等属性.而这些属性可以通过“继承” ...
- 无废话ExtJs 入门教程二十[数据交互:AJAX]
无废话ExtJs 入门教程二十[数据交互:AJAX] extjs技术交流,欢迎加群(521711109) 1.代码如下: 1 <!DOCTYPE html PUBLIC "-//W3C ...
- 无废话ExtJs 入门教程二[Hello World]
无废话ExtJs 入门教程二[Hello World] extjs技术交流,欢迎加群(201926085) 我们在学校里学习任何一门语言都是从"Hello World"开始,这里我 ...
- mongodb入门教程二
title: mongodb入门教程二 date: 2016-04-07 10:33:02 tags: --- 上一篇文章说了mongodb最基本的东西,这边博文就在深入一点,说一下mongo的一些高 ...
随机推荐
- Java实现夺冠概率模拟
足球比赛具有一定程度的偶然性,弱队也有战胜强队的可能. 假设有甲.乙.丙.丁四个球队.根据他们过去比赛的成绩,得出每个队与另一个队对阵时取胜的概率表: 甲 乙 丙 丁 甲 - 0.1 0.3 0.5 ...
- 原生js实现点击添加购物车按钮出现飞行物飞向购物车
效果演示: 思路:核心->抛物线公式 let a = -((y2-y3)*x1 - (x2-x3)*y1 + x2*y3 - x3*y2) / ((x2-x3) * (x1-x2) * (x1- ...
- mybatis技术总结
一.框架概述 day1 1.什么是框架 框架是系统的可重用设计,是对J2EE底层技术的封装(JDBC,IO流,多线程,Servlet,Socket). 2.框架解决了哪些问题? 1.解决了技术整合问题 ...
- 深入浅出-TCP/IP协议族剖析&&Socket
Posted by 微博@Yangsc_o 原创文章,版权声明:自由转载-非商用-非衍生-保持署名 | Creative Commons BY-NC-ND 3.0 #简介 该篇文章主要回顾–TCP/I ...
- 数据结构与算法-python描述-双向链表
# coding:utf-8 # 双向链表的相关操作: # is_empty() 链表是否为空 # length() 链表长度 # travel() 遍历链表 # add(item) 链表头部添加 # ...
- SpringCloud+Ehcache
1.pom文件引入 <!-- https://mvnrepository.com/artifact/org.ehcache/ehcache --><dependency>< ...
- jstl中<c:if>标签属性用法
今天用jstl+el从session域中获取属性,遇到了问题 org.apache.jasper.JasperException: <h3>Validation error message ...
- ubuntu opensips环境搭建
1.安装前准备,需要安装如下工具: perl. libdbi-perl. libdbd-mysql-perl. libdbd-pg-perl. libfrontier-rpc-perl. libter ...
- 问题解决:psql: could not connect to server: No such file or directory Is the server running locally and accepting connections on Unix domain socket "/var/run/postgresql/.s.PGSQL.5432"?
错误提示: psql: could not connect to server: No such file or directory Is the server running locally and ...
- OpenSSH详解
OpenSSH详解(思维导图) 1. SSH概述 SSH 软件架构 认证方式 2. OpenSSH 2.1 客户端程序ssh 配置文件 ssh命令 客户端免密登录 scp sftp 2.2 服务端程序 ...