大数据学习之hadoop伪分布式集群安装(一)公众号undefined110
hadoop的基本概念:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
准备搭建环境:
1.选择合适的操作系统(linux)和语言(java)。
2.准备虚拟机:我的电脑是windows系统还要玩游戏,当然要准备一个虚拟机。虚拟机选择VMware Workstation。首先创建新的虚拟机,分配好内存和硬盘,网络适配器调为VMNET8模式配置,方便以后对网络的使用。
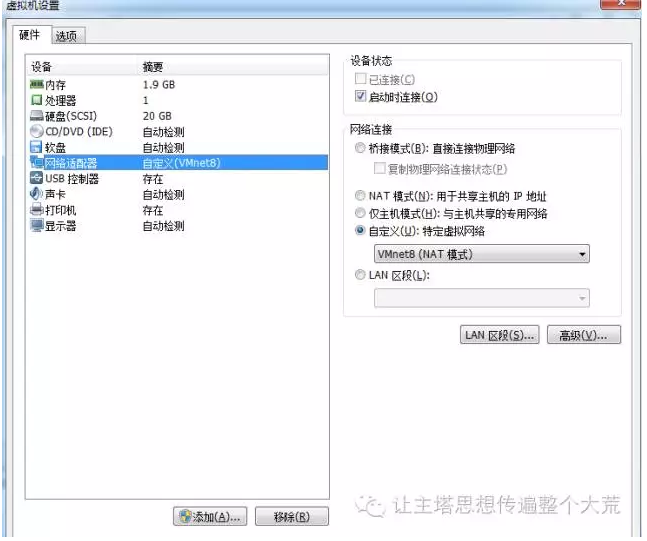
3.安装操作系统:首先得要安装linux系统吧,因为linux系统有太多可选择了,例如最著名的RedHat咱中国人开发的红旗Linux,Ubuntu、Fedora、CentOS等等,因为学习,一切为了有更多资料,安装CentOS6.4这个版本的系统。
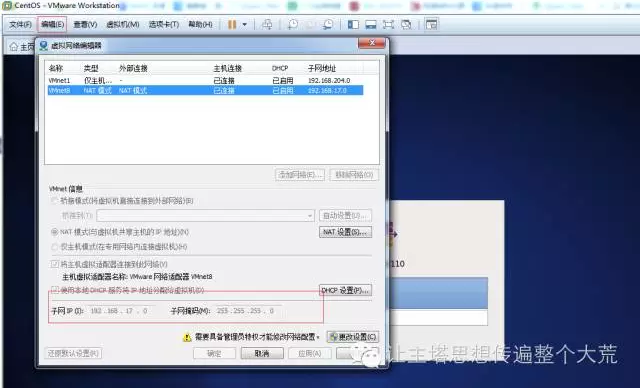
4.设置网络:点击虚拟机的编辑-虚拟网络编辑器,设置子网IP和子网掩码。子网IP:
192.168.17.0 子网掩码:255.255.255.0
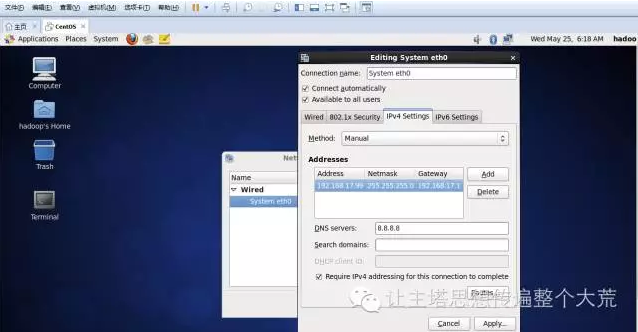
5.在系统中不要用root账号,权限太大,不安全,在实际生产环境中也不会用到root账号。创建名字为hadoop的用户,登录进去。设置网络使用和虚拟机同一子网上的IP,便于本地与虚拟机的交互通信。
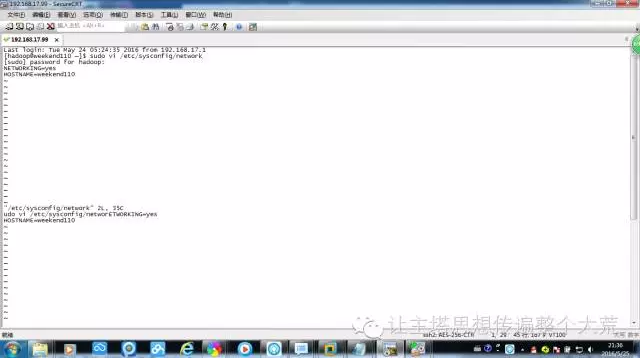
6.使用Securecrt连接上虚拟机,方便在本地直接通过命令操作虚拟机。用sudo vi /etc/sysc onfig/network打开系统文件修改主机名和IP的映射关系,保存后source /etc/profile刷新配置立即生效。关闭防火墙,因为在内网环境而且学习使用,对每个端口进行配置太麻烦,
#查看防火墙状态 service iptables status
#关闭防火墙 service iptables stop
#查看防火墙开机启动状态 chkconfig iptables --list
#关闭防火墙开机启动 chkconfig iptables off
给hadoop赋予root账号权限
重启linux系统
7.使用SecureFx将要安装的软件包传到虚拟机,连接上虚拟机后,把软件包直接拖到hadoop文件夹下
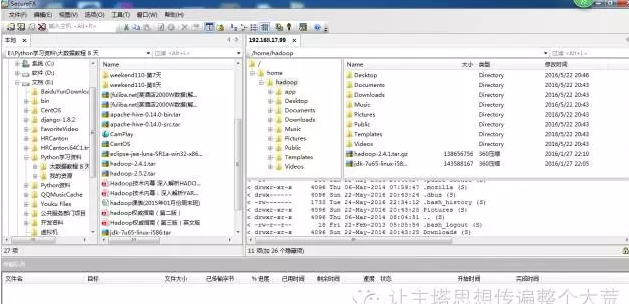
8.创建一个app文件夹将解压的文件都统一放在这里(怎么创建文件夹,解压需要学习Linux基本操作,这里不多说)。
9.方便每次直接使用,需要配置环境变量。
①配置java的jdk环境变量:命令vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source /etc/profile
②配置hadoop,伪分布式需要修改5个配置文件,查找到这五个文件.
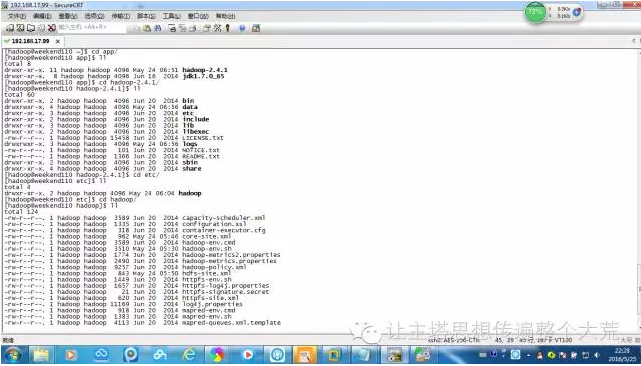
1:sudo vim hadoop-env.sh
#第27行
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
2:sudo vim core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://weekend110:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4.1/data</value>
</property>
3:sudo vim hdfs-site.xml
<!-- 指定HDFS副本的数量 -->虚拟机中配置一个就行了,多了浪费
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4: 将mapred-site.xml.template重命名 为mapred-site.xml
(mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5: sudo vi yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>weekend-1206-01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
③ 将hadoop添加到环境变量
命令:sudo vim /etc/proflie
Shift+G直接跳到最后添加如下配置信息
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新 source /etc/profile
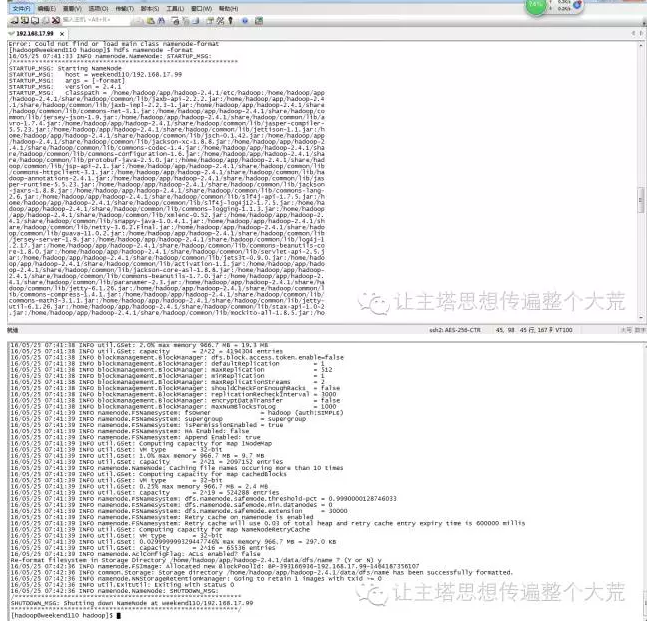
10: 格式化namenode(是对namenode进行初始化,像U盘一样第一次使用需要格式化)
hdfs namenode -format (hadoop namenode -format)
11:启动hadoop
先启动HDFS
start-dfs.sh
再启动YARN
start-yarn.sh
12.执行命名: jps验证是否启动成功。以为本机原来已经启动故有标红信息。最后看到hadoop启动成功。

扫下这个二维码一起学习hadoop:

大数据学习之hadoop伪分布式集群安装(一)公众号undefined110的更多相关文章
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
随机推荐
- zzuoj 10408: C.最少换乘【最短路dijkstra】
10408: C.最少换乘 Time Limit: 2 Sec Memory Limit: 128 MBSubmit: 31 Solved: 8[Submit][Status][Web Board ...
- the identity used to sign the executable is no longer valid.解决方法
the identity used to sign the executable is no longer valid.解决方法 一.重新下载Provisioning Profile 1.到devel ...
- 数位DP初步 bzoj1026 hdu2089 hdu3555
为了搞SCOI的几道题先做水数位.之前听过课,半懂不懂吧,现在清楚了些. 这类题一般满足区间减法,即只需要我们求出(1,n)即可,然后打表也是为了sovle(DataType)服务.先想好怎么计算,再 ...
- 设计模式----代理模式(Proxy)
为还有一个对象提供一个替身或占位符以控制对这个对象的訪问. 代理模式的组成: 主题接口(Subject):提取真正主题与代理的公共方法,让使用真正主题的地方也能用代理取代. 真正主题(RealSubj ...
- [Angular 2] Pipes with Multiple Parameters
Showing how to set up a Pipe that takes multiple updating inputs for multiple Component sources. imp ...
- rsyslog 报 WARNING: rsyslogd is running in compatibility mode.
[root@localhost log]# uname -a Linux localhost.localdomain 2.6.32 #1 SMP Sun Sep 20 18:58:21 PDT 2 ...
- Dagger2学习之由浅入深
概述 Dagger2是一款使用在Java和Android上的静态的,运行时依赖注入框架.官方地址:http://google.github.io/dagger/ 记得当初刚学习Dagger2的时候看了 ...
- Android系统移植与驱动开发----第一章
第一章 Android系统移植与驱动开发 Android源代码定制完全属于自己的嵌入式系统,但是支持的设备不多,所以要移植,而在移植的过程中使用的不得不提的是驱动开发. Android系统构架主要包括 ...
- SSL证书制作
1.创建根证书秘钥文件(自己做CA)root.key: openssl genrsa -out root.key -aes256 2048 2.创建根证书的申请文件root.csr openssl r ...
- python栈的实现(入栈,出栈)
#coding=utf-8 class Stack(): def __init__(st,size):#栈的初始化 st.stack=[]; st.size=size; st.top=-1 def p ...