MapReduce程序开发之流量求和(八)
1.分析记录手机流量的日志。
2.拿到日志中的一行数据,切分各个字段,抽取出我们需要的字段:手机号,上行流量,下行流量,然后封装成kv发送出去
3.使用java中的map方法;
public class FlowNumMapper extends Mapper<LongWritable,Text,Text,FlowBean> {
@Override
protected void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{
//拿一行数据
String line = value.toString();
//切分成各个字段
String[] fields=StringUtils.split(line, "\t");
String phoneNB=fields[1];
long u_flow=Long.parseLong(fields[7]);
long d_flow=Long.parseLong(fields[8]);
//封装数据为KV并输出
context.write(new Text(phoneNB), new FlowBean(phoneNB,u_flow,d_flow));
}
}
4.在map方法中FlowBean参数传递的是一个序列化实体。
package hadoop.mr.flownum;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class FlowBean implements Writable {
private String phoneNB;
private long up_flow;
private long d_flow;
private long s_flow;
// 在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean() {
}
// 为了对象数据的初始化方便,加入一个带参数的构造函数
public FlowBean(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
}
public String getPhoneNB() {
return phoneNB;
}
public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getD_flow() {
return d_flow;
}
public void setD_flow(long d_flow) {
this.d_flow = d_flow;
}
public long getS_flow() {
return s_flow;
}
public void setS_flow(long s_flow) {
this.s_flow = s_flow;
}
// 将对象数据序列化对流中
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(d_flow);
out.writeLong(s_flow);
}
// 从数据流中反序列出对象的数据
// 从数据流中读出对象字段时,必须跟序列化时的顺序保持一样
@Override
public void readFields(DataInput in) throws IOException {
phoneNB = in.readUTF();
up_flow = in.readLong();
d_flow = in.readLong();
s_flow = in.readLong();
}
@Override
public String toString(){
return ""+up_flow+"\t"+d_flow+"\t"+s_flow;
}
}
5.传一组数据调用一次我们的reduce方法,reduce中的业务逻辑就是遍历values,然后进行累加求和输出.
package hadoop.mr.flownum;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowNumReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context)
throws IOException, InterruptedException {
long up_flow_counter=0;
long d_flow_counter=0;
for (FlowBean bean : values) {
up_flow_counter +=bean.getD_flow();
d_flow_counter+=bean.getD_flow();
}
context.write(key, new FlowBean(key.toString(),up_flow_counter,d_flow_counter));
}
}
6.job提交:
package hadoop.mr.flownum;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
public class FlowNumRunner extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowNumRunner.class);
job.setMapperClass(FlowNumMapper.class);
job.setMapOutputKeyClass(FlowNumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new FlowNumRunner(), args);
System.exit(res);
}
}
7.对mapreduce进行打包。
8.把打包的jar包上传到虚拟机,把要统计的日志上传到hadoop
hadoop fs -put HTTP_20130313143750.dat /flow/data
在hadoop中执行flow.jar结果输出到flow/output文件下
hadoop jar flow.jar hadoop.mr.flownum.FlowNumRunner /flow/data /flow/output
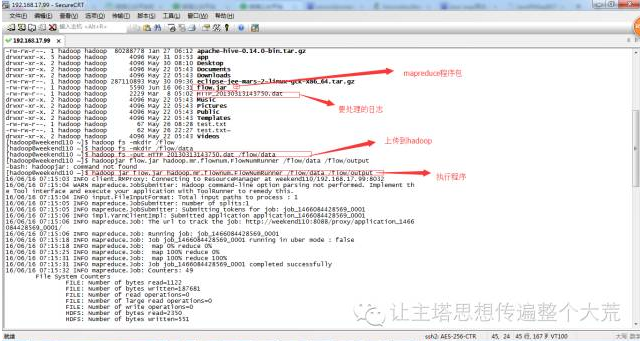
9.执行hadoop fs -cat /flow/output/part-r-00000命令查询里面输出的内容,对日志里面的内容统计如下:

MapReduce程序开发之流量求和(八)的更多相关文章
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- 基于HBase Hadoop 分布式集群环境下的MapReduce程序开发
HBase分布式集群环境搭建成功后,连续4.5天实验客户端Map/Reduce程序开发,这方面的代码网上多得是,写个测试代码非常容易,可是真正运行起来可说是历经挫折.下面就是我最终调通并让程序在集群上 ...
- 大数据笔记(七)——Mapreduce程序的开发
一.分析Mapreduce程序开发的流程 1.图示过程 输入:HDFS文件 /input/data.txt Mapper阶段: K1:数据偏移量(以单词记)V1:行数据 K2:单词 V2:记一次数 ...
- Hadoop(三):MapReduce程序(python)
使用python语言进行MapReduce程序开发主要分为两个步骤,一是编写程序,二是用Hadoop Streaming命令提交任务. 还是以词频统计为例 一.程序开发1.Mapper for lin ...
- 1 weekend110的复习 + hadoop中的序列化机制 + 流量求和mr程序开发
以上是,weekend110的yarn的job提交流程源码分析的复习总结 下面呢,来讲weekend110的hadoop中的序列化机制 1363157985066 13726230503 ...
- windows环境下Eclipse开发MapReduce程序遇到的四个问题及解决办法
按此文章<Hadoop集群(第7期)_Eclipse开发环境设置>进行MapReduce开发环境搭建的过程中遇到一些问题,饶了一些弯路,解决办法记录在此: 文档目的: 记录windows环 ...
- YARN应用程序开发流程(类似于MapReduce On Yarn)本内容版权归(小象学院所有)
MapReduce On Yarn和MapReduce程序区别 MapReduce On Yarn(由专业人员开发)1 为MapReduce作业运行在YARN上提供一个通用的运行时环境2 需要与Yar ...
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- Windows平台开发Mapreduce程序远程调用运行在Hadoop集群—Yarn调度引擎异常
共享原因:虽然用一篇博文写问题感觉有点奢侈,但是搜索百度,相关文章太少了,苦苦探寻日志才找到解决方案. 遇到问题:在windows平台上开发的mapreduce程序,运行迟迟没有结果. Mapredu ...
随机推荐
- Linq to sql语法
LINQ to SQL语句(1)之Where Where操作 适用场景:实现过滤,查询等功能. 说明:与SQL命令中的Where作用相似,都是起到范围限定也就是过滤作用的,而判断条件就是它后面所接的子 ...
- UBUNTU 札记(53条经验)
adobe_pdf 菜单栏 /etc/profile 是一个global config file,会影响系统全局用户,如果你只想对single user生效的话,可以修改vi ~/.bash_prof ...
- java基础之 IO流
javaIO流 IO流 : (input output) 输入输出流 :输入 :将文件读到内存中 输出:将文件从内存输出到其他地方. IO技术的作用:主要就是解决设备和设备之间的数据传输问题 ...
- 学习了几天的jQuery Mobile的一点感受
一.Write less Do more! 这好像就是jQuery Mobile的口号吧.基于jQuery类库的jQuery Mobile移动web插件,有了这个轻量级插件后,排版方便了许多,很多样 ...
- 用户体验设置和UI设计的10个不同点
在这个技术的世界,UX和UI这两个词条在差点儿全部公司都非常流行,不管大小,都在寻找招聘UX/UI设计师. 这两个缩写词条使得整个技术工业为之疯狂,由于它们是最先进的前沿技术. 那这两个词条实际上是什 ...
- QT+QT creator+OpenCV图像灰度化
1).pro文件 #------------------------------------------------- # # Project created by QtCreator 2014-05 ...
- 执行游戏时出现0xc000007b错误的解决方法
如图,这个错误使无数玩家烦恼. 出现这个错误,可能是硬件的问题,也可能是软件的问题.可是,因为硬件引起该问题的概率非常小,而且除了更换硬件之外没有更好的解决方法,因此本文将具体介绍怎样通过软件解决此问 ...
- [HNOI2012] 矿场搭建
/* codevs 1996 连通性问题 Tarjan+割点 可以感性的想一想 一定炸割点最好 否则 没有什么影响 先求出割点来 对于剩下的点们 缩一下 当然不能包括割点 这里的缩 因为删了割点就不是 ...
- C# gridview分頁導出excel
#region 导出Excel方法 //导出到Excel按钮 protected void btnExport_Click(object sender, EventArgs e) { Export(& ...
- C#获取类中所有方法
var t = typeof(HomeController); //获取所有方法 System.Reflection.MethodInfo[] methods = t.GetMethods(); // ...