爬取动态网页:Selenium
参考:http://blog.csdn.net/wgyscsf/article/details/53454910
概述
- 在爬虫过程中,一般情况下都是直接解析html源码进行分析解析即可。但是,有一种情况是比较特殊的:网页的数据采用异步加载的,比如ajax加载的数据,在我们“查看网页源代码”是查看不到的。采用常规的爬虫这一块是解析不到的。
第一种解决方案是采用一些第三方的工具,模拟浏览器的行为,去加载数据。比如:
Selenium、PhantomJs。- 优点:不必考虑动态页面的各种变化多端(无论动态数据如何变化,最终呈现在页面上的效果是固定的,我们只关心最终结果。),我们只用关心最终的现实结果即可。可以统一处理。
- 缺点:性能低下,比如使用
Selenium,每次我们都需要去启动一个浏览器进程;配置繁琐,不同的浏览器需要下载不同的驱动以及jar包,并且驱动和jar包之间有严格版本匹配关系,如果不匹配就不能使用(至少本人因为版本匹配的关系,花了很大的时间)。
第二种解决方案是分析页面,找到对应请求接口,直接获取数据。
- 优点:性能高,使用方便。我们直接获取原数据接口(换句话说就是直接拿取网页这一块动态数据的API接口),肯定会使用方便,并且改变的可能性也比较小。
- 缺点:缺点也是明显的,如何获取接口API?有些网站可能会考虑到数据的安全性,做各种限制、混淆等。这就需要看开发者个人的基本功了,进行各种分析了。
1、下载安装
谷歌和驱动版本匹配可以参考这篇文章:http://blog.csdn.net/huilan_same/article/details/51896672
chromedriver下载地址(不需要翻墙):http://chromedriver.storage.googleapis.com/index.html
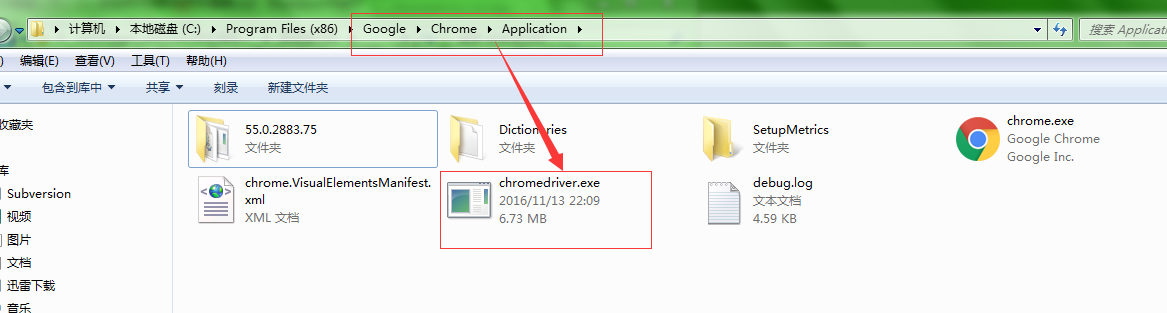
将下载的驱动放到谷歌浏览器的安装目录下,如下图
2、导包
3、编写测试代码
package Test;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class SeleniumTest {
public static void main(String[] args) {
// 第一步: 设置chromedriver地址。一定要指定驱动的位置。
System.setProperty("webdriver.chrome.driver",
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
// 第二步:初始化驱动
WebDriver driver = new ChromeDriver();
// 第三步:获取目标网页
driver.get("http://blog.csdn.net/wgyscsf/article/details/52835845");
// 第四步:解析。以下就可以进行解了。使用webMagic、jsoup等进行必要的解析。
System.out.println("Page title is: " + driver.getTitle());
//System.out.println("Page title is: " + driver.getPageSource());
}
}

爬取动态网页:Selenium的更多相关文章
- R语言爬取动态网页之环境准备
在R实现pm2.5地图数据展示文章中,使用rvest包实现了静态页面的数据抓取,然而rvest只能抓取静态网页,而诸如ajax异步加载的动态网页结构无能为力.在R语言中,爬取这类网页可以使用RSele ...
- 爬虫(三)通过Selenium + Headless Chrome爬取动态网页
一.Selenium Selenium是一个用于Web应用程序测试的工具,它可以在各种浏览器中运行,包括Chrome,Safari,Firefox 等主流界面式浏览器. 我们可以直接用pip inst ...
- 利用selenium并使用gevent爬取动态网页数据
首先要下载相应的库 gevent协程库:pip install gevent selenium模拟浏览器访问库:pip install selenium selenium库相应驱动配置 https: ...
- 记录几个爬取动态网页时的问题(下拉框,旧的元素无法获取,获取的源代码和f12看到的不一致,爬取延迟)
更新.....这个动态网页其实直接抓取ajax请求就可以了,很简单,我之前想复杂了,虽然也实现了,但是效率极低,不过没关系,就当作是对Selenium的一次学习吧 1.最近在爬取一个动态网页,其中为了 ...
- python爬取动态网页数据,详解
原理:动态网页,即用js代码实现动态加载数据,就是可以根据用户的行为,自动访问服务器请求数据,重点就是:请求数据,那么怎么用python获取这个数据了? 浏览器请求数据方式:浏览器向服务器的api(例 ...
- python爬取动态网页2,从JavaScript文件读取内容
import requests import json head = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) ...
- phantomjs+selenium实现爬取动态网址
之前使用 selenium + firefox驱动浏览器来实现爬取动态网址,但是firefox经常更新,更新后时常会导致webdriver启动不来,所以改用phantomjs+selenium来改善一 ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
随机推荐
- Excel应用----制作二级下拉菜单【转】
应用: 原始数据源是两列的源数据,那该如何制作二级下拉菜单, 当然可以将这两列的数据源,转换成上面的那种格式,再用上面的方法来制作. 今天教大学的方法是直接通过这种两列式的数据源来制作下拉菜单,如果A ...
- Toad 使用中遇到的问题
1:智能提示: 视图-->toad选项-->Editor-->Code Assist-->Toad Insight---->sort pick list alphabet ...
- WPF02(concept)
(转自http://www.cnblogs.com/huangxincheng/archive/2012/06/17/2552322.html)这些天从项目上接触到了wpf,感觉有必要做一个笔记,首篇 ...
- Django知识梳理
请求周期: url > 路由 > 函数或类 > 返回字符串或模板语言 Form 表单提交: 先处理模板语言再讲HTML发出去 提交 > url > 函数或类中的方法 — ...
- Jquery放大镜插件---imgzoom.js(原创)
Jquery放大镜插件imgzoom能够实现图片放大的功能,便于与原图进行比较. 使用方法: 1.引入jQuery与imgzoom,imgzoom.css <link rel="sty ...
- 在苹果iOS平台中获取当前程序进程的进程名等信息
本文由EasyDarwin开源团队成员Penggy供稿: Objective-C 提供 NSProcessInfo 这个类来获取当前 APP 进程信息, 然而我们的静态库是 pure C++ 工程. ...
- EasyDarwin流媒体服务器高性能优化方向
我们在EasyDarwin开源流媒体服务器上做了很多的优化,包括前面说到的<EasyDarwin开源流媒体服务器将select改为epoll的方法>.<EasyDarwin开源流媒体 ...
- 修改JDK环境变量,不生效的问题
一般是在/etc/profile下面配置JDK的环境变量 JAVA_HOME=/data/jdk1.7.0_72 JRE_HOME=/data/jdk1.7.0_72/jre PATH=$PATH:$ ...
- CentOS 更换 usr 挂载分区
由于之前挂载在/usr目录的分区空间过小,无法安装更多需要的软件,现在添加一块硬盘重新挂载在/usr目录,并将之前/usr 目录下的内容(包括权限.连接等)完整拷贝到新磁盘分区的/usr目录. 操作系 ...
- R in Action(0) 开篇
这几年数据挖掘的火热,也越来越多的人把R作为数据挖掘的一个辅助工具,据国际性组织kkguter统计有60%的人在挖掘过程中用到R工具,可见这个工具是多么的流行,对于数据统计.筛选以及画图绝对是神器.尽 ...