pandas实践——美国人口分析
1.导入文件,并查看数据样本
abbr = pd.read_csv("./state-abbrevs.csv")
areas =pd.read_csv("./state-areas.csv")
pop = pd.read_csv("./state-population.csv")
display(abbr.head(),areas.head(),pop.head())
abbr:
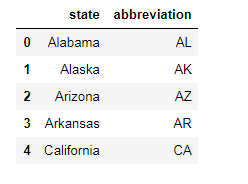
areas:
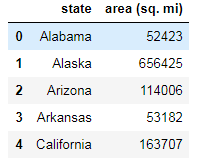
pop
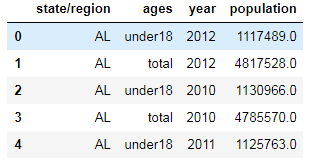
2.合并数据,并对数据进行处理。
合并pop和abbr,两个dataframe,并删除合并后的abbreviation列
pop2 = pop.merge(abbr,how="outer",left_on="state/region",right_on="abbreviation") #设置how,合并后保留全部的数据
pop2.head() #展示前五条数据
pop2:
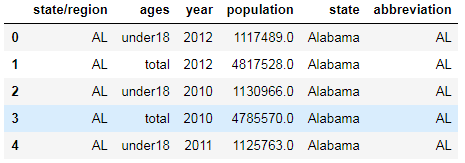
pop2.drop(labels="abbreviation",axis=1,inplace=True) #删除abbreviation的列
判断合并后有空数据
pop2.isnull().any(axis=0)
结果:

可以看到population列和state列中有空数据。
找到‘state’列中那些数据为空,并作为条件。
cond = pop2["state"].isnull()
根据条件判断出那个州有数据为空
cond = pop2["state"].isnull()
结果:array(['PR', 'USA'], dtype=object)
3.对空数据进行填充。
先添加填充条件
cond1 =pop2["state/region"]=="USA"
cond2 = pop2["state/region"]=="PR"
根据条件对为NaN的数数据进行补全
pop2["state"][cond2]="Puerto Rico"
pop2["state"][cond1]="United states"
正之前查询到的空数据的列还有population,对这些空数据进行删除。
cond3 = pop2["population"].isnull()
pop2[cond3].dropna(inplace=True)
pop2.notnull().all() #然后再对空数据进行查询
结果:
可以看到就没有空数据的列了
对areas表中数据添加到pop2中
pop3 = pop2.merge(areas,how="outer")
pop3.isnull().any() #判断融合后是否有空数据
结果:
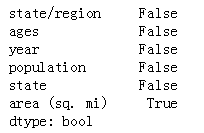 #可以看到area列含有空数据
#可以看到area列含有空数据
将有空数据的列作为条件
cond4 = pop3["area (sq. mi)"].isnull()
pop3[cond4]
结果:
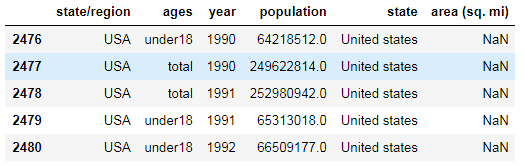 #可以看到美国国土总面积数据为空
#可以看到美国国土总面积数据为空
求出美国国土总面积。并将数据填充到pop3表中
a = areas["area (sq. mi)"].sum ()
pop3.fillna(a,inplace=True)
pop3.isnull().any()
结果:
 #可以看到pop3中都没有空数据了
#可以看到pop3中都没有空数据了
4.求出2010年美国各个州的人口密度
查询2010年各州的人口数据
pop4 = pop3.query("year==2010 and ages =='total'")
pop4.set_index(keys="state",inplace=True) #给查询出来的数据添加索引,并以州名作为索引。
pop4.tail()

pd.set_option("display.float_format",lambda x:"%0.1f"%(x))
pop_density = pop4["population"]/pop4["area (sq. mi)"]
pop_density1 = DataFrame(pop_density,columns=["pop_density(pop/area)"])
pop_density1.tail()
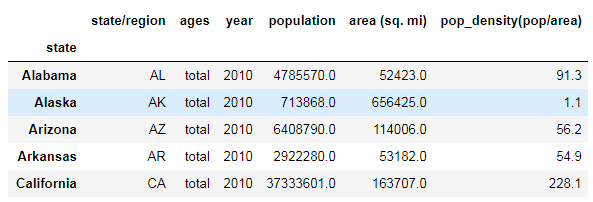
pop5 = pop4.merge(pop_density1,on="state")
pop5.head()
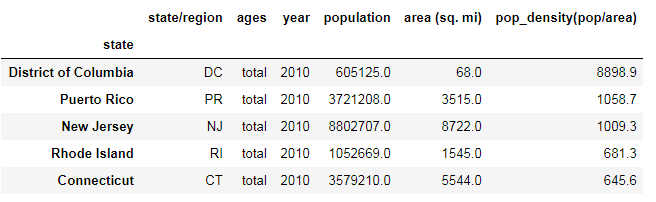
# 排序找到人口密度最高的五个州
pop6 = pop5.sort_values(by="pop_density(pop/area)",ascending=False)
pop6.head()
pandas实践——美国人口分析的更多相关文章
- pandas实例美国人口分析
- Python 的 pandas 实践
Python 的 pandas 实践: # !/usr/bin/env python # encoding: utf-8 __author__ = 'Administrator' import pan ...
- pandas - 案例(美国各州人口普查)
需求: 导入文件,查看原始数据 将人口数据和各州简称数据进行合并 将合并的数据中重复的abbreviation列进行删除 查看存在缺失数据的列 找到有哪些state/region使得state的值为N ...
- pandas - 案例(美国2012年总统候选人政治献金数据分析)
# 提供数据 months = {'JAN' : 1, 'FEB' : 2, 'MAR' : 3, 'APR' : 4, 'MAY' : 5, 'JUN' : 6, 'JUL' : 7, 'AUG' ...
- Python之numpy,pandas实践
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言. Jupyter Notebook 的本质是一个 Web 应用程序,便 ...
- pandas之美国2012年总统候选人政治献金数据分析
- 数据分析实际案例之:pandas在餐厅评分数据中的使用
目录 简介 餐厅评分数据简介 分析评分数据 简介 为了更好的熟练掌握pandas在实际数据分析中的应用,今天我们再介绍一下怎么使用pandas做美国餐厅评分数据的分析. 餐厅评分数据简介 数据的来源是 ...
- python 全栈之路
目录 Python 全栈之路 一. Python 1. Python基础知识部分 2. Python -函数 3. Python - 模块 4. Python - 面对对象 5. Python - 文 ...
- 数据分析06 /pandas高级操作相关案例:人口案例分析、2012美国大选献金项目数据分析
数据分析06 /pandas高级操作相关案例:人口案例分析.2012美国大选献金项目数据分析 目录 数据分析06 /pandas高级操作相关案例:人口案例分析.2012美国大选献金项目数据分析 1. ...
随机推荐
- Docker安装nginx以及负载均衡
首先在linux系统中新建一个data文件夹进行nginx容器的创建--即为:mkdir data. 一:第一次 1 第一步: 使用 docker pull nginx将nginx的镜像从仓库下载下来 ...
- 【面试】迄今为止把同步/异步/阻塞/非阻塞/BIO/NIO/AIO讲的这么清楚的好文章(快快珍藏)
常规的误区 假设有一个展示用户详情的需求,分两步,先调用一个HTTP接口拿到详情数据,然后使用适合的视图展示详情数据. 如果网速很慢,代码发起一个HTTP请求后,就卡住不动了,直到十几秒后才拿到HTT ...
- thinkphp5修改入口文件位置及相应的问题
问题1:thinkphp5修改入口文件 解决:参考手册 http://www.kancloud.cn/manual/thinkphp5/129746,然后需要把.htaccess跟入口文件放到同一目录 ...
- Beanshell vs JSR223 vs Java JMeter脚本:性能关闭你一直在等待!
有几个选项可用于执行自定义JMeter脚本并扩展基线JMeter功能.查看最流行的扩展机制,比较性能并分析哪一个是最好的. 这是乐队之战,JMeter风格. Beanshell V. JSR223 V ...
- Codeforces 384E-线段树+dfs序
如果这题只传到儿子不继续向下就是裸的dfs序+线段树,继续往下传的还改变正负号,我们可以根据它的层数来确定正负号 #include<bits/stdc++.h> #define inf 0 ...
- Hive进阶_开发Hive的自定义函数
Hive中的自定义函数简介 (1) 在类中创建自定义函数.自定义UDF需要继承'org.apache.hadoop.hive.ql.exec.UDF',实现evaluate函数,evaluate函数支 ...
- redis 拒绝远程访问解决
启动时报的警告: 1.Warning: no config file specified, using the default config. In order to specify a config ...
- jQuery.data() 与 jQuery(elem).data()源码解读
之前一直以为 jQuery(elem).data()是在内部调用了 jQuery.data(),看了代码后发现不是.但是这两个还是需要放在一起看,因为它们内部都使用了jQuery的数据缓存机制.好吧, ...
- Fleet(集群管理器)
工作原理 fleet 是通过systemd来控制你的集群的,控制的任务被称之为unit(单元),控制的命令是fleetctl unit运行方式 unit的运行方式有两种: standard globa ...
- 使用 swift3.0高仿新浪微博
项目地址:https://github.com/SummerHH/swift3.0WeBo 使用 swift3.0 高仿微博,目前以实现的功能有,添加访客视图,用户信息授权,首页数据展示(支持正文中连 ...