解析器组件和序列化组件(GET / POST 接口设计)
前言
我们知道,Django无法处理 application/json 协议请求的数据,即,如果用户通application/json协议发送请求数据到达Django服务器,我们通过request.POST获取到的是个空对象.
引入
Django RestFramework帮助我们实现了处理application/json协议请求的数据,另外,我们也提到,如果不使用DRF,直接从request.body里面拿到原始的客户端请求的字节数据,经过decode,然后json反序列化之后,也可以得到一个Python字典类型的数据。
但是,这种方式并不被推荐,因为已经有了非常优秀的第三方工具,那就是Django RestFramework的解析器组件,序列化组件。
序列化就是可以帮助我们快速的进行符合规范的接口开发,也就是增删改查接口,包含错误信息定义,成功之后的返回信息定义等等。
一 . 知识点回顾
1 . 三元运算
# 定义两个变量
a = 1
b = 2
# 判断a的真假值,如果为True,则将判断表达式的前面的值赋给c,否则将判断表达式后面的值赋给c
c = a if a else b print(c) # 1 # 因为a的真假值判断为True,所以c为1
# 定义两个变量
a = 0
b = 2
# 判断a的真假值,如果为True,则将判断表达式的前面的值赋给c,否则将判断表达式后面的值赋给c
c = a if a else b print(c) # 2 # 因为a的真假值判断为False,所以c为2
2 . 列表推导式
列表推导式的返回结果任然是一个列表
li = [1, 2, 3, 4]
# 方式一:使用普通for循环
new_list = list()
for item in li:
new_list.append(item * 2) # 方式二:使用列表推导式
li = [ x * 2 for x in li]
作用 : 可以大大的简化代码.
class JsonParser(object):
pass class FormParser(object):
pass class Parser(object):
parser_classes = [JsonParser, FormParser] def _get_parse(self):
parser_list = [parser() for parser in self.parser_classes]
return parser_list parser = Parser()
parser_list = parser._get_parse()
print(parser_list) # [<__main__.JsonParser object at 0x103f07048>, <__main__.FormParser object at 0x103f072e8>]
parser_list 是 parser_classes中每个类的实例化对象列表,
3 . getattr
在学习面向对象时,我们知道可以通过对象加点号获取该对象的属性,也可以通过对象dict访问属性.例如 :
class Father(object):
country = "china" class Person(Father):
def __init__(self, name, age):
self.name = name
self.age = age p = Person("pizza", 18)
print(p.__dict__) # {'name': 'pizza', 'age': 18}
print(Person.__dict__) # {'__module__': '__main__', '__init__': <function Person.__init__ at 0x103f132f0>, '__doc__': None}
print(p.name) # pizza
print(p.age) #
print(p.country) # china 如果对象不存在这个属性,则会到其父类中查找这个属性
print(p.hobby) # 如果在父类中也找不到这个属性,则会报错:AttributeError: 'Person' object has no attribute 'hobby'
对象的属性查找首先会在该对象的一个名为dict的字典中查找这个属性,如果找不到,则会到其父类中查找这个属性,如果在父类中都找不到相应的属性,就会抛出异常AttributeError, 我们可以通过在类中定义一个getattr来重定向未查找到属性后的行为.
class Father(object):
country = "china" class Person(Father):
def __init__(self, name, age):
self.name = name
self.age = age def __getattr__(self, value):
raise ValueError("属性%s不存在" % value) p = Person("pizza", 18)
print(p.hobby) # ValueError: 属性hobby不存在
可以看到,我们能够重新定义异常,也可以做其他任何事情,这就是getattr,一句话总结,通过对象查找属性,如果找不到属性,且该对象有getattr方法,那么getattr方法会被执行,至于执行什么逻辑,我们可以自定义。
4 . Django settings文件查找顺序
我们在使用Django的时候,会经常用到它的settings文件,通过在settings文件里面定义变量,我们可以在程序的任何地方使用这个变量, 比如:在settings里定义变量 NAME=”Pizza”, 虽然可以在项目的任何地方使用:
>>> from drf_server import settings
>>> print(settings.NAME) # Pizza
但是,这种方式并不是被推荐和建议的,因为除了项目本身的settings文件之外,Django程序本身也有许多配置变量,都存储在django/conf/global_setting.py模块里面,包括缓存、数据库、秘钥等,如果我们只是from drf_server import settings导入了项目本身的配置信息,当需要用到Django默认的配置信息的时候,还需要再次导入,from django.conf import settings,所以建议的使用方式是:
>>> from django.conf import settings
>>> print(settings.NAME)
使用上面的方式,我们除了可以使用自定义的配置信息(NAME)外,还可以使用global_settings中的配置信息,不需要重复导入,Django查找变量的顺序是先从用户的settings里面查找,然后在global_settings中查找,如果用户的settings中找到了,则不会继续查找global_settings中的配置信息,假设我在用户的settings里面定义了NAME=”Pizza”, 在global_settings中定义了NAME=”Ale”,请看下面的打印结果:
>>> from django.conf import settings
>>> print(settings.NAME) # Pizza
这个方式更加灵活高效.
5 . Django 原生serializer
Django框架原生的序列化功能.
from django.core.serializers import serialize
class StudentView(APIView):
def get(self, request):
origin_students = Student.objects.all()
serialized_students = serialize("json", origin_students)
return HttpResponse(serialized_students)
使用方式非常简单,导入模块后,将需要的格式和queryset传给 serialize 进行序列化,然后返回序列化后的数据.
注意 : 如果你的项目中仅仅只是需要序列化一部分数据,不需要进行认证 , 权限 等功能,可以使用Django原生的 serializer , 否则建议使用DRF.
二 . 解析器组件
解析器的使用
from django.http import JsonResponse from rest_framework.views import APIView
from rest_framework.parsers import JSONParser, FormParser
# Create your views here. class LoginView(APIView):
parser_classes = [FormParser] def get(self, request):
return render(request, 'parserver/login.html') def post(self, request):
# request是被drf封装的新对象,基于django的request
# request.data是一个property,用于对数据进行校验
# request.data最后会找到self.parser_classes中的解析器
# 来实现对数据进行解析 print(request.data) # {'username': 'alex', 'password': 123} return JsonResponse({"status_code": 200, "code": "OK"})
使用方式非常简单 :
○ 导入 from rest_framework.view import APIView
○ 继承 APIView
○ 直接使用 request.data 就可以获取json数据
如果你只需要解析json数据,不允许任何其他类型的数据请求 :
○ 导入 from rest_framework.parsers import JsonParser
○ 给视图类定义一个parser_classes变量,值为列表类型 [JsonParser]
○ 如果parser_classes = [ ] , 那就不处理任何数据类型的请求了.
解析器组件的源码剖析
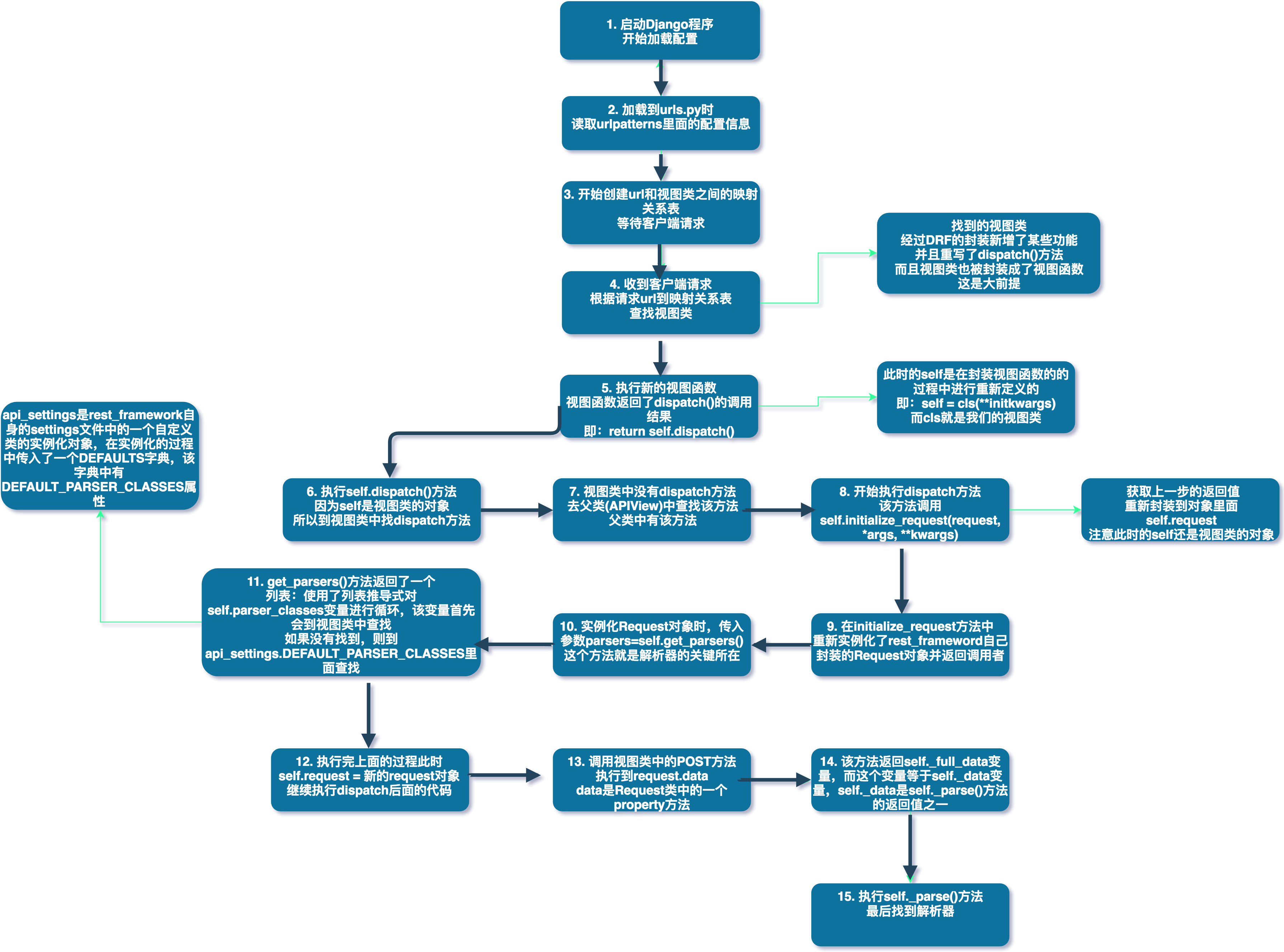
三 . 序列化组件
序列化组件的使用
先定义几个 model :
from django.db import models # Create your models here. class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField() def __str__(self):
return self.name class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField() def __str__(self):
return self.name class Book(models.Model):
title = models.CharField(max_length=32)
publishDate = models.DateField()
price = models.DecimalField(max_digits=5, decimal_places=2)
publish = models.ForeignKey(to="Publish", to_field="nid", on_delete=models.CASCADE)
authors = models.ManyToManyField(to="Author") def __str__(self):
return self.title
通过序列化组件进行GET接口设计
设计url ,
from django.urls import re_path from serializers import views urlpatterns = [
re_path(r'books/$', views.BookView.as_view())
]
我们新建一个名为app_serializers.py的模块,将所有的序列化的使用集中在这个模块里面,对程序进行解耦:
# -*- coding: utf-8 -*-
from rest_framework import serializers from .models import Book class BookSerializer(serializers.Serializer):
title = serializers.CharField(max_length=128)
publish_date = serializers.DateTimeField()
price = serializers.DecimalField(max_digits=5, decimal_places=2)
publish = serializers.CharField(max_length=32)
authors = serializers.CharField(max_length=32)
接着,使用序列化组件,开始写视图类:
from rest_framework.views import APIView
from rest_framework.response import Response # 当前app中的模块
from .models import Book
from .app_serializer import BookSerializer # Create your views here. class BookView(APIView):
def get(self, request):
origin_books = Book.objects.all()
serialized_books = BookSerializer(origin_books, many=True) return Response(serialized_books.data)
如此简单,我们就已经,通过序列化组件定义了一个符合标准的接口,定义好model和url后,使用序列化组件的步骤如下:
- 导入序列化组件:from rest_framework import serializers
- 定义序列化类,继承serializers.Serializer(建议单独创建一个专用的模块用来存放所有的序列化类):class BookSerializer(serializers.Serializer):pass
- 定义需要返回的字段(字段类型可以与model中的类型不一致,参数也可以调整),字段名称必须与model中的一致
- 在GET接口逻辑中,获取QuerySet
- 开始序列化:将QuerySet作业第一个参数传给序列化类,many默认为False,如果返回的数据是一个列表嵌套字典的多个对象集合,需要改为many=True
- 返回:将序列化对象的data属性返回即可
上面的接口逻辑中,我们使用了Response对象,它是DRF重新封装的响应对象。该对象在返回响应数据时会判断客户端类型(浏览器或POSTMAN),如果是浏览器,它会以web页面的形式返回,如果是POSTMAN这类工具,就直接返回Json类型的数据。
此外,序列化类中的字段名也可以与model中的不一致,但是需要使用source参数来告诉组件原始的字段名,如下:
class BookSerializer(serializers.Serializer):
BookTitle = serializers.CharField(max_length=128, source="title")
publishDate = serializers.DateTimeField()
price = serializers.DecimalField(max_digits=5, decimal_places=2)
# source也可以用于ForeignKey字段
publish = serializers.CharField(max_length=32, source="publish.name")
authors = serializers.CharField(max_length=32)
下面是通过POSTMAN请求该接口后的返回数据,大家可以看到,除ManyToManyField字段不是我们想要的外,其他的都没有任何问题:
[
{
"title": "Python入门",
"publishDate": null,
"price": "119.00",
"publish": "浙江大学出版社",
"authors": "serializers.Author.None"
},
{
"title": "Python进阶",
"publishDate": null,
"price": "128.00",
"publish": "清华大学出版社",
"authors": "serializers.Author.None"
}
]
那么,多对多字段如何处理呢?如果将source参数定义为”authors.all”,那么取出来的结果将是一个QuerySet,对于前端来说,这样的数据并不是特别友好,我们可以使用如下方式:
class BookSerializer(serializers.Serializer):
title = serializers.CharField(max_length=32)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
publishDate = serializers.DateField()
publish = serializers.CharField()
publish_name = serializers.CharField(max_length=32, read_only=True, source='publish.name')
publish_email = serializers.CharField(max_length=32, read_only=True, source='publish.email')
# authors = serializers.CharField(max_length=32, source='authors.all')
authors_list = serializers.SerializerMethodField() def get_authors_list(self, authors_obj):
authors = list()
for author in authors_obj.authors.all():
authors.append(author.name) return authors
注意 : get_ 必须和字段名字一样,否则会报错!!!!!!!!!
通过序列化组件经POST接口设计
接下来,我们设计POST接口,根据接口规范,我们不需要新增url,只需要在视图类中定义一个POST方法即可,序列化类不需要修改,如下:
from rest_framework.views import APIView
from rest_framework.response import Response # 当前app中的模块
from .models import Book
from .app_serializer import BookSerializer # Create your views here. class BookView(APIView):
def get(self, request):
origin_books = Book.objects.all()
serialized_books = BookSerializer(origin_books, many=True) return Response(serialized_books.data) def post(self, request):
verified_data = BookSerializer(data=request.data) if verified_data.is_valid():
book = verified_data.save()
# 可写字段通过序列化添加成功之后需要手动添加只读字段
authors = Author.objects.filter(nid__in=request.data['authors'])
book.authors.add(*authors) return Response(verified_data.data)
else:
return Response(verified_data.errors)
POST接口的实现方式,如下:
- url定义:需要为post新增url,因为根据规范,url定位资源,http请求方式定义用户行为
- 定义post方法:在视图类中定义post方法
- 开始序列化:通过我们上面定义的序列化类,创建一个序列化对象,传入参数data=request.data(application/json)数据
- 校验数据:通过实例对象的is_valid()方法,对请求数据的合法性进行校验
- 保存数据:调用save()方法,将数据插入数据库
- 插入数据到多对多关系表:如果有多对多字段,手动插入数据到多对多关系表
- 返回:将插入的对象返回
请注意,因为多对多关系字段是我们自定义的,而且必须这样定义,返回的数据才有意义,而用户插入数据的时候,serializers.Serializer没有实现create,我们必须手动插入数据,就像这样:
# 第二步, 创建一个序列化类,字段类型不一定要跟models的字段一致
class BookSerializer(serializers.Serializer):
# nid = serializers.CharField(max_length=32)
title = serializers.CharField(max_length=128)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
publish = serializers.CharField()
# 外键字段, 显示__str__方法的返回值
publish_name = serializers.CharField(max_length=32, read_only=True, source='publish.name')
publish_city = serializers.CharField(max_length=32, read_only=True, source='publish.city')
# authors = serializers.CharField(max_length=32) # book_obj.authors.all() # 多对多字段需要自己手动获取数据,SerializerMethodField()
authors_list = serializers.SerializerMethodField() def get_authors_list(self, book_obj):
author_list = list() for author in book_obj.authors.all():
author_list.append(author.name) return author_list def create(self, validated_data):
# {'title': 'Python666', 'price': Decimal('66.00'), 'publish': '2'}
validated_data['publish_id'] = validated_data.pop('publish')
book = Book.objects.create(**validated_data) return book def update(self, instance, validated_data):
# 更新数据会调用该方法
instance.title = validated_data.get('title', instance.title)
instance.publishDate = validated_data.get('publishDate', instance.publishDate)
instance.price = validated_data.get('price', instance.price)
instance.publish_id = validated_data.get('publish', instance.publish.nid) instance.save() return instance
但是这样有2个问题 :
不能自动插入数据
如果字段很多,写序列化类会很多,代码会很多
解决方法 :
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = Book fields = ('title',
'price',
'publish',
'authors',
'author_list',
'publish_name',
'publish_city'
)
extra_kwargs = {
'publish': {'write_only': True},
'authors': {'write_only': True}
} publish_name = serializers.CharField(max_length=32, read_only=True, source='publish.name')
publish_city = serializers.CharField(max_length=32, read_only=True, source='publish.city') author_list = serializers.SerializerMethodField() def get_author_list(self, book_obj):
# 拿到queryset开始循环 [{}, {}, {}, {}]
authors = list() for author in book_obj.authors.all():
authors.append(author.name) return authors
步骤如下:
- 继承ModelSerializer:不再继承Serializer
- 添加extra_kwargs类变量:extra_kwargs = {‘publish’: {‘write_only’: True}}
使用ModelSerializer完美的解决了上面两个问题。
解析器组件和序列化组件(GET / POST 接口设计)的更多相关文章
- DRF 的 版本,解析器,与序列化
DRF 的 版本,解析器,与序列化 补充 配置文件中的 类的调用: (字符串) v1 = ["view.xx.apth.Role","view.xx.apth.Role& ...
- DRF之解析器组件及序列化组件
知识点复习回顾一:三元运算 三元运算能够简化我们的代码, 请看如下代码: # 定义两个变量 a = 1 b = 2 # 判断a的真假值,如果为True,则将判断表达式的前面的值赋给c,否则将判断表达 ...
- pull解析器: 反序列化与序列化
pull解析器:反序列化 读取xml文件来获取一个对象的数据 import java.io.FileInputStream; import java.io.IOException; import ja ...
- django rest framework 解析器组件 接口设计,视图组件 (1)
一.解析器组件 -解析器组件是用来解析用户请求数据的(application/json), content-type 将客户端发来的json数据进行解析 -必须适应APIView -request.d ...
- 第三章、drf框架 - 序列化组件 | Serializer
目录 第三章.drf框架 - 序列化组件 | Serializer 序列化组件 知识点:Serializer(偏底层).ModelSerializer(重点).ListModelSerializer( ...
- Django序列化组件与数据批量操作与简单使用Forms组件
目录 SweetAlert前端插件 Django自带的序列化组件 批量数据操作 分页器与推导流程 Forms组件之创建 Forms组件之数据校验 Forms组件之渲染标签 Forms组件之信息展示 S ...
- 如何实现一个SQL解析器
作者:vivo 互联网搜索团队- Deng Jie 一.背景 随着技术的不断的发展,在大数据领域出现了越来越多的技术框架.而为了降低大数据的学习成本和难度,越来越多的大数据技术和应用开始支持SQL进 ...
- 用ExpressionTree实现JSON解析器
今年的春节与往年不同,对每个人来说都是刻骨铭心的.突入其来的新型冠状病毒使大家过上了“梦想”中的生活:吃了睡,睡了吃,还不用去公司上班,如今这样的生活就在我们面前,可一点都不踏实,只有不停的学习才能让 ...
- 笔记:XML-解析文档-流机制解析器(SAX、StAX)
DOM 解析器完整的读入XML文档,然后将其转换成一个树型的数据结构,对于大多数应用,DOM 都运行很好,但是,如果文档很大,并且处理算法又非常简单,可以在运行时解析节点,而不必看到完整的树形结构,那 ...
随机推荐
- ubuntu 配置L2tp出现的问题解决
运行环境:ubuntu 14.04 64位 配置推荐网址: https://linux.cn/article-3409-1.html 首先,官方教程是必须的: https://help.ubuntu. ...
- struts2拦截器实现session超时返回登录页面(iframe下跳转到其父页面)
需求:session超时时,返回登录页面,由于页面嵌套在iframe下,因此要跳转到登录页面的父页面,但是首页,登录页面等不需要进行跳转 实现: java文件:SessionIterceptor.ja ...
- Python批量复制和重命名文件
Python批量复制和重命名文件 示例代码 #! /usr/bin/env python # coding=utf-8 import os import shutil import time impo ...
- AngularJS中选择样式
代码下载:https://files.cnblogs.com/files/xiandedanteng/angularJSSelectClass.rar 要点,{{ctrl.name}}比<spa ...
- Timus : 1002. Phone Numbers 题解
把电话号码转换成为词典中能够记忆的的单词的组合,找到最短的组合. 我这道题应用到的知识点: 1 Trie数据结构 2 map的应用 3 动态规划法Word Break的知识 4 递归剪枝法 思路: 1 ...
- Win2003 IIS 安装方法 图文教程
最近水一水 质量不高 见谅 一般大家先安装好win2003系统,图文教程 Win2003 服务器系统安装图文教程要通过控制面板来安装.具体做法为: 1. 进入“控制面板”. 2. 双击“添加或删除程序 ...
- jquery中的clone()方法
jquery中不能直接把选择到的元素如$('div')添加到其他地方,而需要使用$('div')[0]等 clone()方法直接复制HTML代码,所以可以直接用来添加元素.
- Bootstrap学习速查表(一) 理论基础
参考网站http://www.bootcss.com/ 第一步,起步,引入基本样式 <!-- 新 Bootstrap 核心 CSS 文件 --> <link rel="st ...
- XFire Web Service客户端开发
一.项目创建: 创建一个Maven的web工程 Maven包导入pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0&qu ...
- html中文件类型的accept属性有哪些
*.3gpp audio/3gpp, video/3gpp 3GPP Audio/Video *.ac3 audio/ac3 AC3 Audio *.asf allpication/vnd.ms-as ...