str中的join方法,fromkeys(),set集合,深浅拷贝(重点)
一丶对之前的知识点进行补充
1.str中的join方法.把列表转换成字符串
# 将列表转换成字符串,每个元素之间用_拼接
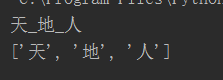
s = "_".join(["天","地","人"])
print(s)
ss = "天_地_人"
s = ss.split("_")
print(s)
2.列表和字典在循环的时候不能直接删除
需要把删除的内容记录在新列表中
然后循环新列表,删除字典或列表
lst = ["a","b","c"]
n = []
for a in lst:
n.append(a)
for b in n:
lst.remove(b)
print(lst) lst = ["张国荣", '张铁林', '张国立', "张曼玉", "汪峰"]
# 删掉姓张的
# 记录姓张的.
zhangs = []
for el in lst:
if el.startswith("张"):
zhangs.append(el)
for el in zhangs:
lst.remove(el)
print(lst)
print(zhangs)
3.fromkeys()
1.返回新字典..对原字典没有影响
2.后面的value.是多个key共享一个value
dic = {"apple":"苹果","banana":"香蕉"}
##返回新字典,跟原来的没有关系
ret = dic.fromkeys("orange","橘子") #直接用字典去访问fromkeys不会对字典产生影响
print(ret)
ret = dic.fromkeys("ab",["哈哈","呵呵","吼吼"]) #fromkeys直接使用类名进行访问
print(ret)

二丶set集合
特点: 无序,不重复,元素必须可哈希(不可变)
作用: 去重复
本身是可变的数据类型,有增删改查操作.
增:
s = {"剑圣","剑豪","剑魔"}
s.add("剑姬")
print(s) #{'剑姬', '剑魔', '剑豪', '剑圣'}
s.add("剑圣")
print(s) #重复的添加不进去的 {'剑姬', '剑魔', '剑豪', '剑圣'}
s.update("天道酬勤") #迭代添加
print(s) #{'天', '剑豪', '剑魔', '道', '酬', '勤', '剑圣'} 无序的
删:
s = {"猎空","源氏","半藏","死神"}
ret = s.pop() #随机删除一个元素
print(ret)
s.remove("源氏") #直接删除元素
print(s) #{'死神', '猎空', '半藏'}
s.clear() #清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和dict区分的.
print(s)
改:
# set集合中的数据没有索引. 也没有办法去定位⼀个元素. 所以没有办法进⾏直接修改.
# 我们可以采⽤先删除后添加的⽅式来完成修改操作
s = {"猎空","源氏","半藏","死神"}
s.remove("猎空")
print(s) #{'死神', '源氏', '半藏'}
s.add("堡垒")
print(s) #{'源氏', '半藏', '死神', '堡垒'}
查:
# set集合是一个可迭代对象,可用for循环进行查找
s = {"猎空","源氏","半藏","死神"}
for e in s:
print(e)

frozenset()冻结的集合.不可变的.可哈希的
s = frozenset(["赵本山","常贵","皮长山"])
print(s) #frozenset({'赵本山', '常贵', '皮长山'})
dic = {s:""} #{frozenset({'赵本山', '常贵', '皮长山'}): '123'}
print(dic)
集合的其它操作:
s1 = {"刘能","赵四","皮长山"}
s2 = {"刘科长","冯乡长","皮长山"}
# 交集
# 两个集合中的共有元素
print(s1 & s2) #{"皮长山"}
print(s1.intersection(s2)) #{"皮长山"}
# 并集
print(s1|s2) #{'冯乡长', '刘科长', '皮长山', '刘能', '赵四'}
print(s1.union(s2)) #{'冯乡长', '皮长山', '刘能', '刘科长', '赵四'}
# 差集
print(s1 - s2) # {'赵四', '刘能'} 得到第⼀个中单独存在的
print(s1.difference(s2)) #{'刘能', '赵四'}
# 反交集
print(s1^s2) #两个集合中单独存在的数据 {'刘科长', '刘能', '冯乡长', '赵四'}
print(s1.symmetric_difference(s2)) #{'刘科长', '刘能', '冯乡长', '赵四'}
s1 = {"刘能","赵四"}
s2 = {"刘能","赵四","皮长山"}
# 子集
print(s1<s2) #set1是set2的子集吗? Ture
print(s1.issubset(s2))
# 超集
print(s1>s2) #set1是set2的超集吗? False
print(s1.issuperset(s2))
s = frozenset(["赵本山","刘能","皮长山","常贵"])
dic = {s:""}
print(dic) #{frozenset({'常贵', '皮长山', '刘能', '赵本山'}): '123'}
三丶深浅拷贝(难点)
1.赋值.没有创建新对象.公用同一个对象
lst1 = ["金毛狮王","紫衫龙王","白眉鹰王","青翼蝠王"]
lst2 = lst1
print(lst1) #['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王']
print(lst2) #['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王']
lst1.append("杨逍")
print(lst1) #['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王', '杨逍']
print(lst2) #['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王', '杨逍'] dic1 = {"id":123,"name":"谢逊"}
dic2 = dic1
print(dic1) #{'id': 123, 'name': '谢逊'}
print(dic2) #{'id': 123, 'name': '谢逊'}
dic1["name"] = "范瑶"
print(dic1) #{'id': 123, 'name': '范瑶'}
print(dic2) #{'id': 123, 'name': '范瑶'}
2.浅拷贝.拷贝第一层内容.[:]或copy()
#浅拷贝 lst1 = ["何炅","杜海涛","周渝民"]
lst2 = lst1.copy()
lst1.append("李嘉诚")
print(lst1)
print(lst2)
print(id(lst1),id(lst2)) #结果
# ['何炅', '杜海涛', '周渝民', '李嘉诚']
# ['何炅', '杜海涛', '周渝民']
# 1653894977480 1653895005704 # 两个lst完全不一样,内存地址和内容也不一样,发现实现了内存的拷贝
lst1 = ["何炅","杜海涛","周渝民",["麻花藤","马芸","周笔畅"]]
lst2 = lst1.copy()
lst1[3].append("无敌是多么寂寞")
print(lst1)
print(lst2)
print(id(lst1[3]),id(lst2[3])) # 结果
# ['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', '周笔畅', '无敌是多么寂寞']]
# ['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', '周笔畅', '无敌是多么寂寞']]
# 1479533238216 1479533238216 # 浅拷贝:只会拷贝第一层,第二层的内容不会拷贝,所以被称为浅拷贝
3.深拷贝.拷贝所有内容.包括内部的所有
#深拷贝
import copy
lst1 = ["何炅","杜海涛","周渝民",["麻花藤","马芸","周笔畅"]]
lst2 = copy.deepcopy(lst1)
lst1[3].append("无敌是多么寂寞")
print(lst1)
print(lst2)
print(id(lst1[3]),id(lst2[3]))
#结果
# ['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', '周笔畅', '无敌是多么寂寞']]
# ['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', '周笔畅']]
# 1589080305224 1589080421384
str中的join方法,fromkeys(),set集合,深浅拷贝(重点)的更多相关文章
- str中的join方法; set集合;深浅拷贝
一.str中的join方法 1,用join可以吧列表转换为字符串 将列表转换成字符串. 每个元素之间用_拼接 s = "_". join(['德玛', ''赵信'', '易']) ...
- 【转载】 C#中使用CopyTo方法将List集合元素拷贝到数组Array中
在C#的List集合操作中,有时候需要将List元素对象拷贝存放到对应的数组Array中,此时就可以使用到List集合的CopyTo方法来实现,CopyTo方法是List集合的扩展方法,共有3个重载方 ...
- python随笔 join 字典,列表的清空 set集合 以及深浅拷贝(重点..难点)
一,字符串和列表的转换 1.str中的 join 方法: 把列表转换成字符串 # 将列表转换成字符串. 每个元素之间用_连接 s = '**'.join(['李启政',' 郑强' , '孙福来']) ...
- set集合深浅拷贝以及知识补充
一. 对之前的知识点进行补充. 1. str中的join方法. 把列表转换成字符串 li = ["李嘉诚", "麻花藤", "黄海峰", & ...
- jQuery中的join方法
和JS 中的JOIN 方法一样,将一数组按照JOIN的参数连接起来.比如: var arr = [ "a", "b", "c", " ...
- Java多线程中的join()方法
一.join()方法介绍 join() 定义在Thread.java中.join()方法把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程.比如在线程B中调用了线程A的join( ...
- Java并发编程--多线程中的join方法详解
Java Thread中, join()方法主要是让调用该方法的thread在完成run方法里面的部分后, 再执行join()方法后面的代码 例如:定义一个People类,run方法是输出姓名年龄. ...
- Thread类中的join方法
package charpter06; //类实现接口public class Processor implements Runnable { // 重写接口方法 @Override public v ...
- 【转载】C#中使用Insert方法往ArrayList集合指定索引位置插入新数据
ArrayList集合是C#中的一个非泛型的集合类,是弱数据类型的集合类,可以使用ArrayList集合变量来存储集合元素信息,在ArrayList集合操作过程中,可以使用ArrayList集合类的I ...
随机推荐
- [转]从onload和DOMContentLoaded谈起
这篇文章是对这一两年内几篇dom ready文章的汇总(文章的最后会标注参考文章),因为浏览器进化的关系,可能他们现在的行为与本文所谈到的一些行为不相符.我也并没有一一去验证,所以本文仅供参考,在具体 ...
- [转]深入了解 CSS3 新特性
简介 CSS 即层叠样式表(Cascading Stylesheet).Web 开发中采用 CSS 技术,可以有效地控制页面的布局.字体.颜色.背景和其它效果.只需要一些简单的修改,就可以改变网页的外 ...
- Python3解leetcode Maximum SubarrayClimbing Stairs
问题: You are climbing a stair case. It takes n steps to reach to the top. Each time you can either cl ...
- vijos:P1053Easy sssp(spfa判环)
描述 输入数据给出一个有N(2 <= N <= 1,000)个节点,M(M <= 100,000)条边的带权有向图. 要求你写一个程序, 判断这个有向图中是否存在负权回路. 如果从一 ...
- jquery、javascript实现(get、post两种方式)跨域解决方法
一.实现get方式跨域请求数据 浏览器端 <script> $(document).ready(function(){ $.ajax({ url: "http://www.xxx ...
- 我们团队是如何落地DDD的(1)
最近发现文章老是被窃取,有些平台举报了还没有用.请识别我的id方丈的寺院. 摘要 DDD领域驱动设计,起源于2004年著名建模专家Eric Evans发表的他最具影响力的著名书籍:Domain-Dri ...
- PHP 数字补零 固定位数补0
在处理订单编号的时候,需要固定位数的数字,比如需要固定四位数格式: 1->0001 56->0056 288->0288 1992->1992 可以使用php内置函数str_p ...
- Picture poj1177
Picture Time Limit: 2000MS Memory Limit: 10000K Total Submissions: 12265 Accepted: 6484 Descript ...
- birt启动后访问地址详解
发布设计完成的报表文件,可在web项目中创建reports目录,用于存放报表设计文件. 在应用中通过正确格式的访问路径,例如:http://localhost:8080/birtApp/framese ...
- nodejs ejs 引擎脱离express使用
之前用ejs都是使用express创建项目,然后在app.js中配置好的ejs直接使用即可,但是最近项目中使用的手工路由模式,脱离了express,不知道怎么用了,去扒ejs的网站,各种资料,也是懵懵 ...