小型文件数据库 (a file database for small apps) SharpFileDB
小型文件数据库 (a file database for small apps) SharpFileDB
For english version of this article, please click here.
我并不擅长数据库,如有不当之处,请多多指教。
本文参考了(http://www.cnblogs.com/gaochundong/archive/2013/04/24/csharp_file_database.html),在此表示感谢!
目标(Goal)

我决定做一个以支持小型应用(万人级别)为目标的数据库。
既然是小型的数据库,那么最好不要依赖其它驱动、工具包,免得拖泥带水难以实施。
完全用C#编写成DLL,易学易用。
支持CRUD(增加(Create)、读取(Retrieve)、更新(Update)和删除(Delete))。
不使用SQL,客观原因我不擅长SQL,主观原因我不喜欢SQL,情景原因没有必要。
直接用文本文件或二进制文件存储数据。开发时用文本文件,便于调试;发布时用二进制文件,比较安全。
简单来说,就是纯C#、小型、无SQL。此类库就命名为SharpFileDB。
为了便于共同开发,我把这个项目放到Github上,并且所有类库代码的注释都是中英文双语的。中文便于理解,英文便于今后国际化。也许我想的太多了。
设计草图(sketch)
使用场景(User Scene)
SharpFileDB库的典型使用场景如下。
// common cases to use SharpFileDB.
FileDBContext db = new FileDBContext(); Cat cat = new Cat();
cat.Name = "xiao xiao bai";
db.Create(cat); Predicate<Cat> pre = new Predicate<Cat>(x => x.Name == "xiao xiao bai");
IList<Cat> cats = db.Retrieve(pre); cat.Name = "xiao bai";
db.Update(cat); db.Delete(cat);
这个场景里包含了创建数据库和使用CRUD操作的情形。
我们就从这个使用场景开始设计出第一版最简单的一个文件数据库。
核心概念(Core Concepts)
如下图所示,数据库有三个核心的东西:数据库上下文,就是数据库本身,能够执行CRUD操作;表,在这里是一个个文件,用一个FileObject类型表示一个表;持久化工具,实现CRUD操作,把信息存储到数据库中。
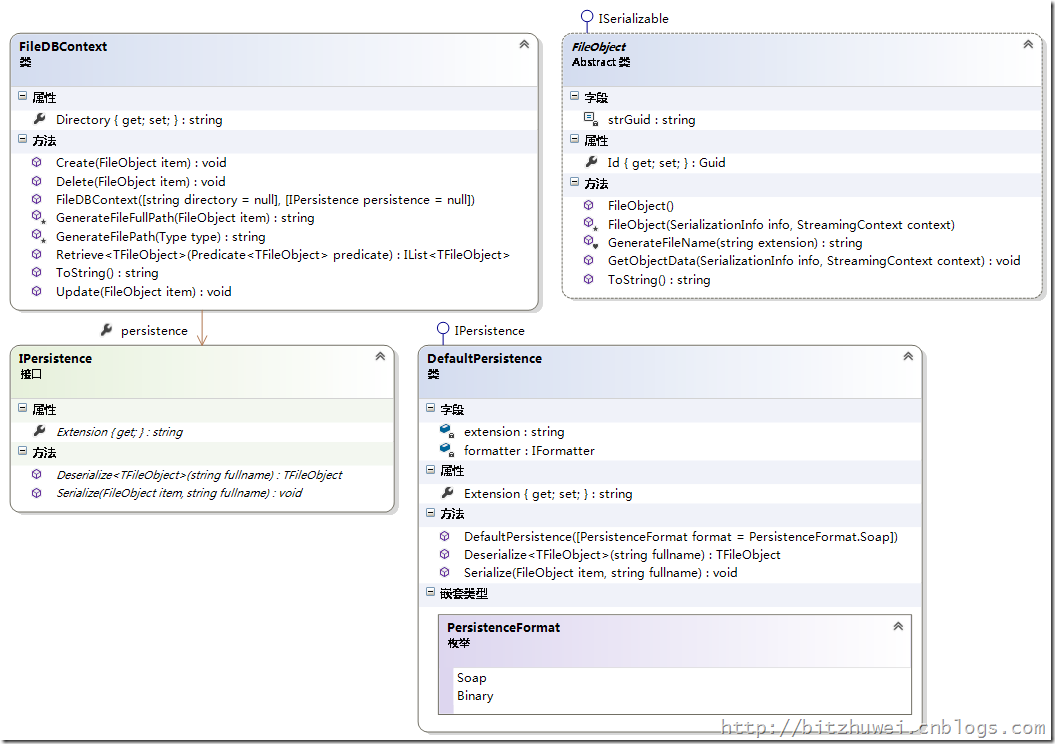
表vs类型(Table vs Type)
为方便叙述,下面我们以Cat为例进行说明。
/// <summary>
/// demo file object
/// </summary>
public class Cat : FileObject
{
public string Name { get; set; }
public int Legs { get; set; } public override string ToString()
{
return string.Format("{0}, Name: {1}, Legs: {2}", base.ToString(), Name, Legs);
}
}
Cat这个类型就等价于关系数据库里的一个Table。
Cat的一个实例,就等价于关系数据库的Table里的一条记录。
以后我们把这样的类型称为表类型。
全局唯一的主键(global unique main key)
类似关系数据库的主键,我们需要用全局唯一的Id来区分每个对象。每个表类型的实例都需要这样一个Id,那么我们就用一个abstract基类做这件事。
/// <summary>
/// 可在文件数据库中使用CRUD操作的所有类型的基类。
/// Base class for all classed that can use CRUD in SharpFileDB.
/// </summary>
[Serializable]
public abstract class FileObject
{
/// <summary>
/// 主键.
/// main key.
/// </summary>
public Guid Id { get; set; } /// <summary>
/// 创建一个文件对象,并自动为其生成一个全局唯一的Id。
/// <para>Create a <see cref="FileObject"/> and generate a global unique id for it.</para>
/// </summary>
public FileObject()
{
this.Id = Guid.NewGuid();
} public override string ToString()
{
return string.Format("Id: {0}", this.Id);
}
}
数据库(FileDBContext)
一个数据库上下文负责各种类型的文件对象的CRUD操作。
/// <summary>
/// 文件数据库。
/// Represents a file database.
/// </summary>
public class FileDBContext
{
#region Fields /// <summary>
/// 文件数据库操作锁
/// <para>database operation lock.</para>
/// </summary>
protected static readonly object operationLock = new object(); /// <summary>
/// 文件数据库
/// <para>Represents a file database.</para>
/// </summary>
/// <param name="directory">数据库文件所在目录<para>Directory for all files of database.</para></param>
public FileDBContext(string directory = null)
{
if (directory == null)
{
this.Directory = Environment.CurrentDirectory;
}
else
{
Directory = directory;
}
} #endregion public override string ToString()
{
return string.Format("@: {0}", Directory);
} #region Properties /// <summary>
/// 数据库文件所在目录
/// <para>Directory of database files.</para>
/// </summary>
public virtual string Directory { get; protected set; } #endregion protected string Serialize(FileObject item)
{
using (StringWriterWithEncoding sw = new StringWriterWithEncoding(Encoding.UTF8))
{
XmlSerializer serializer = new XmlSerializer(item.GetType());
serializer.Serialize(sw, item);
string serializedString = sw.ToString(); return serializedString;
}
} /// <summary>
/// 将字符串反序列化成文档对象
/// </summary>
/// <typeparam name="TDocument">文档类型</typeparam>
/// <param name="serializedFileObject">字符串</param>
/// <returns>
/// 文档对象
/// </returns>
protected TFileObject Deserialize<TFileObject>(string serializedFileObject)
where TFileObject : FileObject
{
if (string.IsNullOrEmpty(serializedFileObject))
throw new ArgumentNullException("data"); using (StringReader sr = new StringReader(serializedFileObject))
{
XmlSerializer serializer = new XmlSerializer(typeof(TFileObject));
object deserializedObj = serializer.Deserialize(sr);
TFileObject fileObject = deserializedObj as TFileObject;
return fileObject;
}
} protected string GenerateFileFullPath(FileObject item)
{
string path = GenerateFilePath(item.GetType());
string name = item.GenerateFileName();
string fullname = Path.Combine(path, name);
return fullname;
} /// <summary>
/// 生成文件路径
/// </summary>
/// <typeparam name="TDocument">文档类型</typeparam>
/// <returns>文件路径</returns>
protected string GenerateFilePath(Type type)
{
string path = Path.Combine(this.Directory, type.Name);
return path;
} #region CRUD /// <summary>
/// 增加一个<see cref="FileObject"/>到数据库。这实际上创建了一个文件。
/// <para>Create a new <see cref="FileObject"/> into database. This operation will create a new file.</para>
/// </summary>
/// <param name="item"></param>
public virtual void Create(FileObject item)
{
string fileName = GenerateFileFullPath(item);
string output = Serialize(item); lock (operationLock)
{
System.IO.FileInfo info = new System.IO.FileInfo(fileName);
System.IO.Directory.CreateDirectory(info.Directory.FullName);
System.IO.File.WriteAllText(fileName, output);
}
} /// <summary>
/// 检索符合给定条件的所有<paramref name="TFileObject"/>。
/// <para>Retrives all <paramref name="TFileObject"/> that satisfies the specified condition.</para>
/// </summary>
/// <typeparam name="TFileObject"></typeparam>
/// <param name="predicate">检索出的对象应满足的条件。<para>THe condition that should be satisfied by retrived object.</para></param>
/// <returns></returns>
public virtual IList<TFileObject> Retrieve<TFileObject>(Predicate<TFileObject> predicate)
where TFileObject : FileObject
{
IList<TFileObject> result = new List<TFileObject>();
if (predicate != null)
{
string path = GenerateFilePath(typeof(TFileObject));
string[] files = System.IO.Directory.GetFiles(path, "*.xml", SearchOption.AllDirectories);
foreach (var item in files)
{
string fileContent = File.ReadAllText(item);
TFileObject deserializedFileObject = Deserialize<TFileObject>(fileContent);
if (predicate(deserializedFileObject))
{
result.Add(deserializedFileObject);
}
}
} return result;
} /// <summary>
/// 更新给定的对象。
/// <para>Update specified <paramref name="FileObject"/>.</para>
/// </summary>
/// <param name="item">要被更新的对象。<para>The object to be updated.</para></param>
public virtual void Update(FileObject item)
{
string fileName = GenerateFileFullPath(item);
string output = Serialize(item); lock (operationLock)
{
System.IO.FileInfo info = new System.IO.FileInfo(fileName);
System.IO.Directory.CreateDirectory(info.Directory.FullName);
System.IO.File.WriteAllText(fileName, output);
}
} /// <summary>
/// 删除指定的对象。
/// <para>Delete specified <paramref name="FileObject"/>.</para>
/// </summary>
/// <param name="item">要被删除的对象。<para>The object to be deleted.</para></param>
public virtual void Delete(FileObject item)
{
if (item == null)
{
throw new ArgumentNullException(item.ToString());
} string filename = GenerateFileFullPath(item);
if (File.Exists(filename))
{
lock (operationLock)
{
File.Delete(filename);
}
}
} #endregion CRUD }
FileDBContext
文件存储方式(Way to store files)
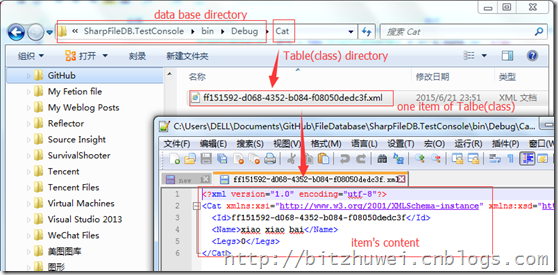
在数据库目录下,SharpFileDB为每个表类型创建一个文件夹,在各自文件夹内存储每个对象。每个对象都占用一个XML文件。暂时用XML格式,因为是.NET内置的格式,省的再找外部序列化工具。XML文件名与其对应的对象Id相同。
下载(Download)
我已将源码放到(https://github.com/bitzhuwei/SharpFileDB/),欢迎试用、提建议或Fork此项目。
更新(Update)
2015-06-22
增加了序列化接口(IPersistence),使得FileDBContext可以选择序列化器。
增加了二进制序列化类型(BinaryPersistence)。
使用Convert.ToBase64String()和Convert.FromBase64String()实现Byte数组与string之间的转换。
//Image-->Byte[]-->String
Byte[] bytes = File.ReadAllBytes(@"d:\a.gif");
MemoryStream ms = new MemoryStream(bty);
String imgStr = Convert.ToBase64String(ms.ToArray()); //String-->Byte[]-->Image
byte[] imgBytes = Convert.FromBase64String(imgStr);
Response.BinaryWrite(imgBytes.ToArray()); // 将一个二制字符串写入HTTP输出流
修改了接口IPersistence,让它直接进行内存数据与文件之间的转化。这样,即使序列化的结果是byte[]或其它类型,也可以直接保存到文件,不再需要先转化为string后再保存。
/// <summary>
/// 文件数据库使用此接口进行持久化相关的操作。
/// <para>File database executes persistence operations via this interface.</para>
/// </summary>
public interface IPersistence
{
/// <summary>
/// <see cref="FileObject"/>文件的扩展名。
/// Extension name of <see cref="FileObject"/>'s file.
/// </summary>
string Extension { get; } /// <summary>
/// 将文件对象序列化为文件。
/// <para>Serialize the specified <paramref name="item"/> into <paramref name="fullname"/>.</para>
/// </summary>
/// <param name="item">要进行序列化的文件对象。<para>file object to be serialized.</para></param>
/// <param name="fullname">要保存到的文件的绝对路径。<para>file's fullname.</para></param>
/// <returns></returns>
void Serialize([Required] FileObject item, [Required] string fullname); /// <summary>
/// 将文件反序列化成文件对象。
/// <para>Deserialize the specified file to an instance of <paramref name="TFileObject"/>.</para>
/// </summary>
/// <typeparam name="TFileObject"></typeparam>
/// <param name="serializedFileObject"></param>
/// <returns></returns>
TFileObject Deserialize<TFileObject>([Required] string fullname) where TFileObject : FileObject;
}
使用接口ISerializable,让每个FileObject都自行处理自己的字段、属性的序列化和反序列化动作(保存、忽略等)。
/// <summary>
/// 可在文件数据库中使用CRUD操作的所有类型的基类。类似于关系数据库中的Table。
/// Base class for all classed that can use CRUD in SharpFileDB. It's similar to the concept 'table' in relational database.
/// </summary>
[Serializable]
public abstract class FileObject : ISerializable
{
/// <summary>
/// 用以区分每个Table的每条记录。
/// This Id is used for diffrentiate instances of 'table's.
/// </summary>
public Guid Id { get; internal set; } /// <summary>
/// 创建一个文件对象,在用<code>FileDBContext.Create();</code>将此对象保存到数据库之前,此对象的Id为<code>Guid.Empty</code>。
/// <para>Create a <see cref="FileObject"/> whose Id is <code>Guid.Empty</code> until it's saved to database by <code>FileDBContext.Create();</code>.</para>
/// </summary>
public FileObject()
{
} /// <summary>
/// 生成文件名,此文件将用于存储此<see cref="FileObject"/>的内容。
/// Generate file name that will contain this instance's data of <see cref="FileObject"/>.
/// </summary>
/// <param name="extension">文件扩展名。<para>File's extension name.</para></param>
/// <returns></returns>
internal string GenerateFileName([Required] string extension)
{
string id = this.Id.ToString(); string name = string.Format(CultureInfo.InvariantCulture, "{0}.{1}", id, extension); return name;
} public override string ToString()
{
return string.Format("Id: {0}", this.Id);
} const string strGuid = "Guid"; #region ISerializable 成员 /// <summary>
/// This method will be invoked automatically when IFormatter.Serialize() is called.
/// <para>You must use <code>base(info, context);</code> in the derived class to feed <see cref="FileObject"/>'s fields and properties.</para>
/// <para>当使用IFormatter.Serialize()时会自动调用此方法。</para>
/// <para>继承此类型时,必须在子类型中用<code>base(info, context);</code>来填充<see cref="FileObject"/>自身的数据。</para>
/// </summary>
/// <param name="info"></param>
/// <param name="context"></param>
public virtual void GetObjectData([Required] SerializationInfo info, StreamingContext context)
{
info.AddValue(strGuid, this.Id.ToString());
} #endregion /// <summary>
/// This method will be invoked automatically when IFormatter.Serialize() is called.
/// <para>You must use <code>: base(info, context)</code> in the derived class to feed <see cref="FileObject"/>'s fields and properties.</para>
/// <para>当使用IFormatter.Serialize()时会自动调用此方法。</para>
/// <para>继承此类型时,必须在子类型中用<code>: base(info, context)</code>来填充<see cref="FileObject"/>自身的数据。</para>
/// </summary>
/// <param name="info"></param>
/// <param name="context"></param>
protected FileObject([Required] SerializationInfo info, StreamingContext context)
{
string str = (string)info.GetValue(strGuid, typeof(string));
this.Id = Guid.Parse(str);
}
}
FileObject相当于关系数据库中的Table
另外,FileObject在使用new FileObject();创建时不为其指定Guid,而在FileDBContext.Create(FileObject)时才进行指定。这样,在反序列化时就不必浪费时间去白白指定一个即将被替换的Guid了。这也更合乎情理:只有那些已经存储到数据库或立刻就要存储到数据库的FileObject才有必要拥有一个Guid。
用一个DefaultPersistence类型代替了BinaryPersistence和XmlPersistence。由于SoapFormatter和BinaryFormatter是近亲,而XmlSerializer跟他们是远亲;同时SoapFormatter和BinaryFormatter分别实现了文本文件序列化和二进制序列化,XmlSerializer就更不用出场了。因此现在不再使用XmlSerializer。
/// <summary>
/// 用<see cref="IFormatter"/>实现<see cref="IPersistence"/>。
/// <para>Implement <see cref="IPersistence"/> using <see cref="IFormatter"/>.</para>
/// </summary>
public class DefaultPersistence : IPersistence
{
private System.Runtime.Serialization.IFormatter formatter; public DefaultPersistence(PersistenceFormat format = PersistenceFormat.Soap)
{
switch (format)
{
case PersistenceFormat.Soap:
this.formatter = new System.Runtime.Serialization.Formatters.Soap.SoapFormatter();
this.Extension = "soap";
break;
case PersistenceFormat.Binary:
this.formatter = new System.Runtime.Serialization.Formatters.Binary.BinaryFormatter();
this.Extension = "bin";
break;
default:
throw new NotImplementedException();
}
} public enum PersistenceFormat
{
Soap,
Binary,
} #region IPersistence 成员 private string extension;
public string Extension
{
get { return this.extension; }
private set { this.extension = value; }
} public void Serialize(FileObject item, string fullname)
{
if (item == null)
{
throw new ArgumentNullException("item");
} if (string.IsNullOrEmpty(fullname))
{
throw new ArgumentNullException("fullname");
} using (FileStream s = new FileStream(fullname, FileMode.Create, FileAccess.Write))
{
formatter.Serialize(s, item);
}
} public TFileObject Deserialize<TFileObject>(string fullname) where TFileObject : FileObject
{
if(string.IsNullOrEmpty(fullname))
{
throw new ArgumentNullException("fullname");
} TFileObject fileObject = null; using (FileStream s = new FileStream(fullname, FileMode.Open, FileAccess.Read))
{
object obj = formatter.Deserialize(s);
fileObject = obj as TFileObject;
} return fileObject;
} #endregion }
支持Soap和binary的持久化工具。
2015-06-23
把FileObject重命名为Document。追随LiteDB的命名。
新增Demo项目MyNote,演示如何使用SharpFileDB。
2015-06-24
经不完全测试,当写入同一文件夹内的文件数目超过百万时,下述序列化方式所需时间加倍。
using (FileStream s = new FileStream(fullname, FileMode.Create, FileAccess.Write))
{
formatter.Serialize(s, string.Empty);
}
继续测试中。
2015-06-25
根据上述试验和对事务、索引等的综合考虑,决定不再采用“一个数据库记录(Document)放到一个单独的文件里”这种方案。因此到目前为止的SharpFileDB作为初次尝试的版本,不再更新,今后将重新设计一套单文件数据库。
我把这个版本的项目源码放到这里。它超级简单,只有3个类,你不需懂SQL,只要会用C#就能使用。还附有一个Demo:便条(MyNote),你可以参考。
如果你的应用程序所需保存的数据库记录在几万条的规模,用这个是没问题的。
点此下载源码SharpFileDB.Version0.1.MultiFiles
Document这个类代表一条数据库记录。
[Serializable]
public abstract class Document : ISerializable
{
public Guid Id { get; internal set; } public Document()
{
} internal string GenerateFileName(string extension)
{
string id = this.Id.ToString(); string name = string.Format(CultureInfo.InvariantCulture, "{0}.{1}", id, extension); return name;
} public override string ToString()
{
return string.Format("Id: {0}", this.Id);
} /// <summary>
/// 使用的字符越少,序列化时占用的字节就越少。一个字符都不用最好。
/// <para>Using less chars means less bytes after serialization. And "" is allowed.</para>
/// </summary>
const string strGuid = ""; #region ISerializable 成员 public virtual void GetObjectData(SerializationInfo info, StreamingContext context)
{
string id = this.Id.ToString();
info.AddValue(strGuid, id);
} #endregion protected Document(SerializationInfo info, StreamingContext context)
{
string str = info.GetString(strGuid);
this.Id = Guid.Parse(str);
}
}
这个类就是被设计了用做基类供使用者继承的;另外也需要对其进行序列化,所以我希望 const string strGuid = ""; 有两个特点:
1最短(减少序列化后的字节数)很明显,单个字符最短了。一个字符都不用那是不行的。
2最不易被别人重复使用(比如我要是用 const string strGuid = "a"; 什么的,别人在子类型中也出现的概率就比"~"大)
经测试发现,BinaryFormatter可以接受 const string strGuid = ""; 所以改用这个设定。
2015-07-06
根据现有代码和从LiteDB得到的启发,决定重新设计编写一个单文件数据库。目前的代码全部作废,不过保留起来备用,因为其中一些最基础的功能还是会用到的。
待完成的工作
必须支持事务ACID。
必须使用索引。参考LiteDB的skip list方式。
必须分页,每页4096bytes。这是读写磁盘文件的最小单位。充分利用之,可以提升I/O效率。(https://github.com/mbdavid/LiteDB/wiki/How-LiteDB-Works)
PS:我国大多数县的人口为几万到几十万。目前,县里各种政府部门急需实现信息化网络化办公办事,但他们一般用不起那种月薪上万的开发者和高端软件公司。我注意到,一个县级政府部门日常应对的人群数量就是万人左右,甚至常常是千人左右。所以他们不需要太高端复杂的系统设计,用支持万人级别的数据库就可以了。另一方面,初级开发者也不能充分利用那些看似高端复杂的数据库的优势。做个小型系统而已,还是简单一点好。
所以我就想做这样一个小型文件数据库,我相信这会帮助很多人。能以己所学惠及大众,才是我们的价值所在。
小型文件数据库 (a file database for small apps) SharpFileDB的更多相关文章
- SharpFileDB - a file database for small apps
SharpFileDB - a file database for small apps 本文中文版在此处. I'm not an expert of database. Please feel fr ...
- 文件 "c:\Program Files\Microsoft SQL Server\MSSQL10.SQLEXPRESS\MSSQL\DATA\ttt.mdf" 已压缩,但未驻留在只读数据库或文件组中。必须将此文件解压缩。 CREATE DATABASE 失败。无法创建列出的某些文件名。请查看相关错误。 (.Net SqlClient Data Provider)
问题: 文件 "c:\Program Files\Microsoft SQL Server\MSSQL10.SQLEXPRESS\MSSQL\DATA\ttt.mdf" 已压缩,但 ...
- 数据库中File权限的危害
The FILE privilege gives you permission to read and write files on the server host using the LOAD DA ...
- Oracle 联机重做日志文件(ONLINE LOG FILE)
--========================================= -- Oracle 联机重做日志文件(ONLINE LOG FILE) --================== ...
- sqlite内存数据库和文件数据库的同步[转]
由于sqlite对多进程操作支持效果不太理想,在项目中,为了避免频繁读写 文件数据库带来的性能损耗,我们可以采用操作sqlite内存数据库,并将内存数据库定时同步到文件数据库中的方法. 实现思路如下: ...
- .NET平台开源项目速览(3)小巧轻量级NoSQL文件数据库LiteDB
今天给大家介绍一个不错的小巧轻量级的NoSQL文件数据库LiteDB.本博客在2013年也介绍过2款.NET平台的开源数据库: 1.[原创]开源.NET下的XML数据库介绍及入门 2.[原创]C#开源 ...
- Oracle数据库如何创建DATABASE LINK?
Oracle数据库如何创建DATABASE LINK? 2011-08-09 14:54 taowei20061122 CSDN博客 http://blog.csdn.net/taowei20061 ...
- 迁移应用数据库到MySQL Database on Azure
by Rong Yu 有用户问怎么把他们应用的数据库迁移到MySQL Database on Azure上,有哪些方式,有没有需要注意的地方.今天我们来概括介绍一下迁移应用数据库到MySQL Data ...
- C#实现文件数据库
本文转载:http://www.cnblogs.com/gaochundong/archive/2013/04/24/csharp_file_database.html#commentform 本文为 ...
随机推荐
- linux中redis安装
一.登录redis官网下载redis-3.0.7.tar.gz 二.通过ftp工具上传至自己的服务器中 三.tar -zxvf redis-3.0.7.tar.gz解压 四.cd redis-3.0. ...
- sencha touch的开源插件和例子
写了好久的sencha touch,没想到换工作竟然一年多没有搞了.因为项目的缘故收集了好多的组件,由于懒惰,没有整理,现在想想有点后悔了,再加上如果就这样丢弃,感觉有些遗憾,今天整理了一下放在git ...
- 动态SQL 学习
<select id="findUser" parameterType="Map" resultType="User"> ...
- JDBC入门之一--连接Mysql实验
工具:mysql-connector-java-5.1.40.eclipse 1)首先要将mysql-connector-java包整合到eclipse中,右击项目,然后选择build path,出现 ...
- 《DSP using MATLAB》示例Example6.1
今天是2016年最后一天了,看到其他博友都写年终总结,做了这个,做了那个,收获满满,再看看自己, 恍恍惚惚一年,不知道干了些什么,惭愧.刚才接到老妈远方的电话,弟弟就在一小时前做爸爸了,我在 这里祝福 ...
- 通过 listboxitem 查找属于listbox第几条数据
public override System.Windows.Style SelectStyle(object item, System.Windows.DependencyObject contai ...
- PHP CI框架 result()详解
该方法执行成功返回一个对象数组,失败则返回一个空数组. 一般情况下,我们使用下面的方法遍历结果,代码就像这样: $query = $this->db->query("要执行的 S ...
- MVC Html.BeginForm 与 Ajax.BeginForm 使用总结
最近采用一边工作一边学习的方式使用MVC5+EF6做一个Demo项目, 期间遇到不少问题, 一直处于研究状态, 没能来得及记录. 今天项目进度告一段落, 得以有空记录学习中遇到的一些问题. 由于MVC ...
- [VijosP1764]Dual Matrices 题解
题目大意: 一个N行M列的二维矩阵,矩阵的每个位置上是一个绝对值不超过1000的整数.你需要找到两个不相交的A*B的连续子矩形,使得这两个矩形包含的元素之和尽量大. 思路: 预处理,n2时间算出每个点 ...
- Access restriction: The type 'FileURLConnection' is not API
遇到这种报错,解决方案如下: 报错原因是访问限制报错 工具栏中Project>preferences>java-Compiler>Errors/Warnings>把右侧的[De ...