sklearn 学习之分类树
概要
基于 sklearn 包自带的 iris 数据集,了解一下分类树的各种参数设置以及代表的意义。
iris 数据集介绍
iris 数据集包含 150 个样本,对应数据集的每行数据,每行数据包含每个样本的四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和样本的类别信息,所以 iris 数据集是一个 150 行 5 列的二维表。
iris 数据集总共有三类:Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),以及 Iris Virginica(维吉尼亚鸢尾),每类 50 个数据。其中的一个种类与另外两个种类是线性可分离的,后两个种类是非线性可分离的,具体地看后续实验分析。
下边这张图片是在网上找的数据集示例,单位是 cm.
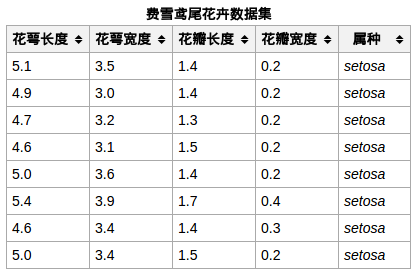
对其有了大概的认识,下边就进行深入探究吧。
sklearn.tree.DecisionTreeClassifier
函数参数
该函数包含很多参数,具体如下:
DecisionTreeClassifier(criterion=’gini’,splitter=’best’,max_depth=None,min_samples_split=2,min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features=None,random_state=None,max_leaf_nodes=None,min_impurity_decrease=0.0,min_impurity_split=None,class_weight=None, presort=False)
下面一一解释。
criterion
参数 criterion 表示选择特征的准则,默认是 'gini',也就是基尼系数了,sklearn 库是使用的改良后的 CART 算法。当然你也可以设置成 'entropy',即信息增益,具体使用哪个,那就实验看看模型效果呗。
下面我们使用默认的 'gini' 准则来生成决策树:
# -*- coding: utf-8 -*-"""Created on Wed Apr 18 11:33:09 2018@author: zhoukui"""from sklearn.datasets import load_irisfrom sklearn import treefrom sklearn.externals.six import StringIOimport pydotplus'''StringIO 经常被用来作字符串的缓存,它的部分接口跟文件一样,可以认为是作为"内存文件对象",简而言之,就是为了方便'''dot_data = StringIO()iris = load_iris()clf = tree.DecisionTreeClassifier() # 如果改用信息增益准则,就在括号中添加: criterion='entropy'clf = clf.fit(iris.data, iris.target)# print(clf.max_features_) # 输出拟合树的属性dot_data = tree.export_graphviz(clf, out_file=None,feature_names=iris.feature_names,class_names=iris.target_names,filled=True,rounded=True,impurity=False)graph = pydotplus.graph_from_dot_data(dot_data)graph.write_pdf("iris.pdf")
可视化如下:
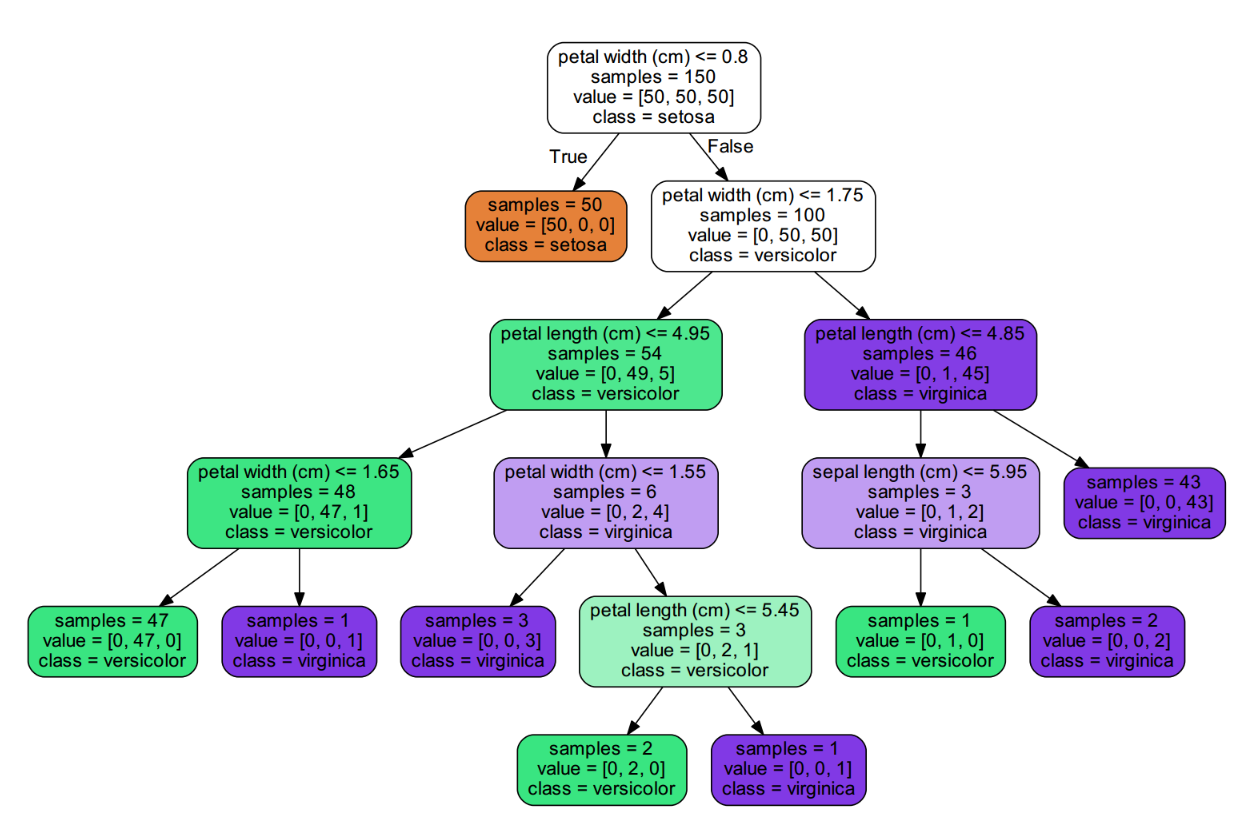
图 1:采用 'gini' 标准生成的决策树
由图可知,第一个选择的特征是花瓣宽度(petal width),只要其值小于 0.8,就把所有的 setosa 类共 50 个全都找出来了,其它的分类可以自己继续分析。
如果你选择 'entropy' 准则,就会得到下面这样的树:
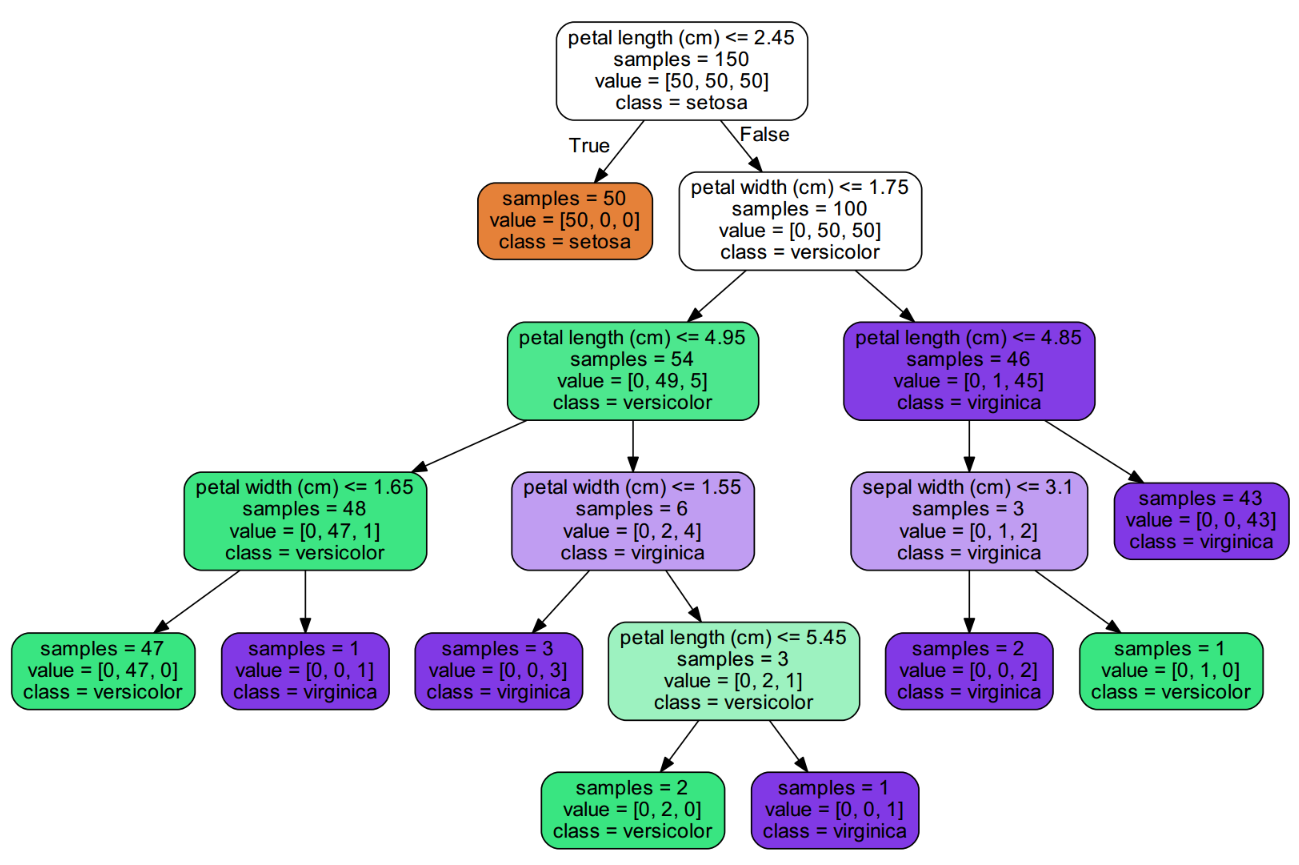
图 2:采用 'entropy' 标准生成的决策树
由图可知,此时第一个选择的特征改为了花瓣长度(petal length),其值小于 2.45,也能够把 50 个 setosa 类全部分出来。仔细对比一下,这两种准则生成的树几乎一样,看来对于这个 iris 数据集对于准则的选择并不敏感。
splitter
该参数是设置划分点的选择标准,比方说图 1 中第一个节点的 0.8 的选择,默认是 'best',表示在所有特征中找最好的切分点。也可以选择 'random',表示随机地在部分特征中选择最好的切分点(数据量大的时候),所以默认的 'best' 适合样本量不大的时候,而如果样本数据量非常大,可尝试使用 'random' . 在本例中,如果选择后者,会产生一个更加复杂的树,显然没有 'best' 好。
max_depth
我们知道决策树的一个大缺点就是过拟合,max_depth 参数就是设置决策树的最大层数的,默认值是 None. 如果树形比较简单的话一般选择默认就行了,如果树形太过于复杂,可以设置一下最大层数。比方说对于 iris 数据,我们设置 max_depth = 3,就会得到一个深度为 3 的树,看下图它的层数没有算上根节点。anyway,知道什么意思就行了。实践中如果模型样本量、特征非常多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布,常用的可以取值10-100之间。
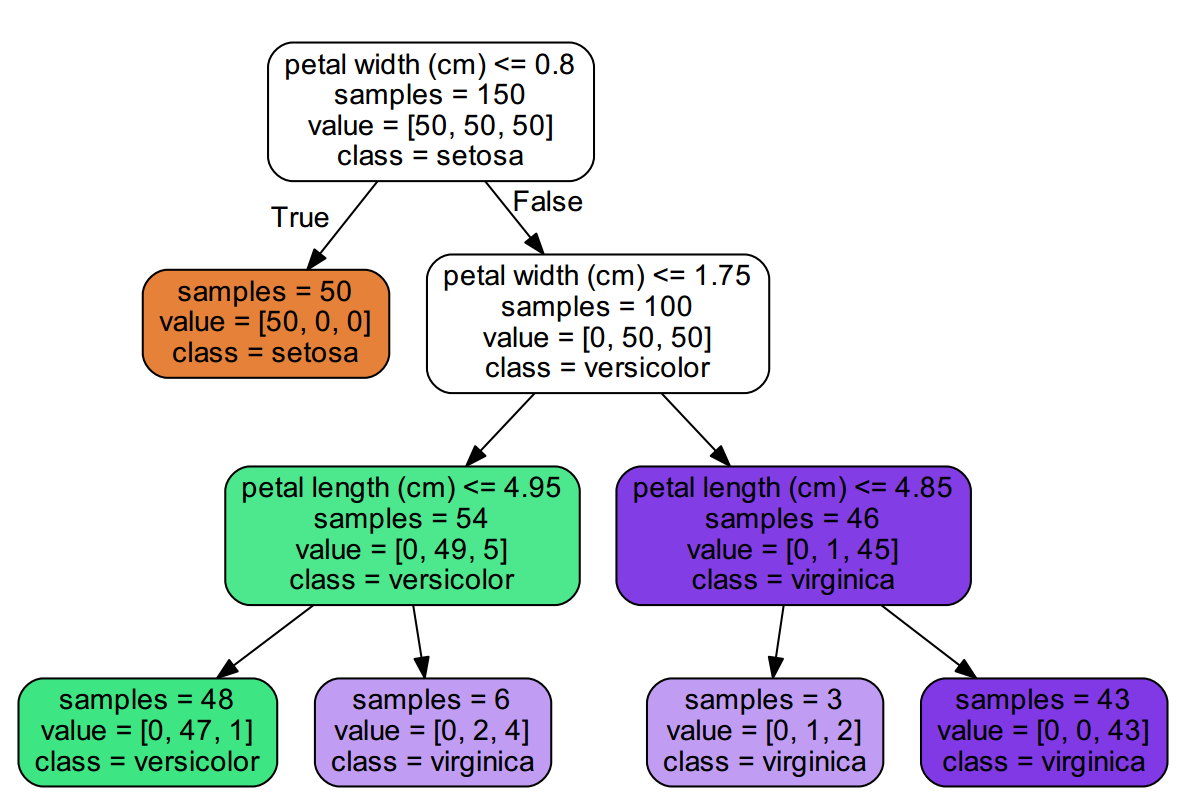
图 3:限制 `max_depth = 3` 生成的决策树
### min_samples_split
该参数表示分裂所要求的最少样本,默认值为 2,如果数量少于该值就不再分叉了,观察图 1 末尾的几节点,可以发现存在样本量为 3 时还在继续分裂,这时候生成的模型也容易过拟合,如果我们设置 min_samples_split = 30,就会生成下面的决策树:
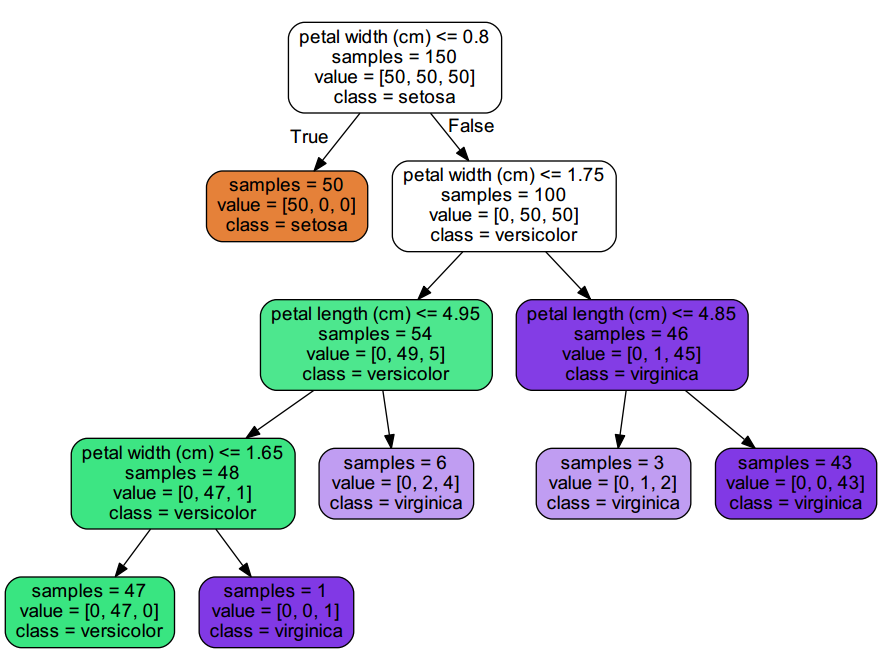
图 4:限制 `min_samples_split = 30` 生成的决策树
可以发现决策树是简洁了一点点。
另外该参数也支持浮点型,表示所占总样本量的百分比,如果样本量除以总样本量低于这个值,便不再分裂。比方说我们令 min_samples_split = 0.2(\(150*0.2=30\)),会生成和图 4 一样的树。
min_samples_leaf=1
该参数表示每个决策树的叶子节点上面的样本数量,少于设置值就会被剪掉(当然包括兄弟结点)。该参数同样也支持浮点型,意义同参数 min_samples_split,注意与 min_samples_split 的区别,如果设置了 min_samples_leaf 值,表示生成树中没有样本量低于该值的叶子节点,而 min_samples_split 值表示低于该值便不再分裂。
min_weight_fraction_leaf
该值限制了叶子节点样本量占所有样本百分比(权重)的最小值,如果小于这个值,则会和兄弟节点一起剪掉,其和 min_samples_leaf 的百分比形式等价。 默认值是 0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
max_features
该值确定参与分裂的特征数,默认值是 None,即全部特征都参与。其详细取值如下:
- 如果是整型
int,就作为所选取的特征数目:max_features - 如果是
float类型,选取特征数目由所有特征乘以这个小数决定:n_features*max_features - 如果是 'auto',则特征数目为:sqrt(n_features)
- 如果是 'sqrt', 则特征数目也为:sqrt(n_features)
- 如果是 'log2',则特征数目为:\(log_2\)(n_features)
- 如果是 'None', 则特征数目为:n_features
random_state
这个也很好理解,如果是 int,那么 random_state 是随机数字发生器的种子。如果是 RandomState,那么 random_state 就是随机数字发生器。如果是默认的 None,则表示随机数字发生器是 np.random 使用的 RandomState instance.
max_leaf_nodes
该值限制了生成树的叶子结点树,默认是 None,表示没有限制。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征多的话,可以加以限制,具体的值可以通过交叉验证得到。比如我们限制其值为 2,那么就会生成如下的决策树:

图 5:限制 `max_leaf_nodes = 2` 生成的决策树
再强调一句,决策树没有奇数的叶子节点,如果你设置 max_leaf_nodes = 3 ,那么就会生成具有 4 个叶子节点的决策树。
min_impurity_decrease
最小不纯度值减少的量,默认是 0.,一个节点只有在分裂后其不纯度值减少的量大于该值时才会被分裂。
min_impurity_split
最小不纯度值,默认是 None. 一个节点只有其不纯度值大于该值时才会被分裂。
class_weight
指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。默认值是 None,这里可以自己指定各个样本的权重如果使用 'balanced',则算法会自己计算权重,样本量少的类别所对应的样本权重会高。 也可以自己定义权重,使用字典类型,详细看官网。 ,
presort
该值表示对样本是否进行预排序,默认是 False,即不排序。一般来说,如果样本量少或者限制了一个深度很小的决策树,设置为 True 可以让划分点选择更加快,决策树建立的更加快。如果样本量太大的话,反而没有什么好处。
属性
拟合数据后得到的模型有一些属性,可以查看相关信息。
classes_
形状为 [n_classes,] 的数组或者列表,表示预测的类。对 iris 数据集,因为共有三类,所以输出 [0, 1, 2].
feature_importances_
形状为 [n_classes,] 的数组或者列表,表示特征的重要度。值越大表示越重要,由于其生成树过程中有一定的随机性,所以每次运行该值并不唯一,如果固定了 random_state,那就确定了,其它参数默认,运行会发现,最后一个特征,即花瓣宽度最重要。
max_features_
参与生成树的特征数目(个人还不太确定),对 iris 数据集,其输出是 4. 如果创建树时设置 max_features = 3,其属性 max_features_ 值就是 3,所以我应该没有猜错。
n_classes_
类的数目。对 iris 数据集,其输出是 3.
n_features_
fit 函数产生的特征数目,对 iris 数据集,其输出是 4.
n_outputs_
fit 函数输出结果数目,对 iris 数据集(单值输出),其输出是 1.
tree_
生成的树对象。
方法
拟合数据后得到的决策树同样有一些方法,可以用来查看一些信息,当然最重要的是预测。下面列出几个比较重要的方法。
apply(X, check_input=True)
返回每个样本的叶节点的预测序号。
decision_path(X, check_input=True)
返回决策树的决策路径 [n_samples, n_nodes].
fit(X, y, sample_weight=None, check_input=True, X_idx_sorted=None)
从训练数据建立决策树,返回一个对象。
predict(X, check_input=True)
预测X的分类或者回归,返回 [n_samples].
predict_log_proba(X)
预测输入样本的对数概率,返回[n_samples, n_classes].
predict_proba(X, check_input=True)
预测输入样本的属于各个类的概率[n_samples, n_classes].
score(X, y, sample_weight=None)
返回对于测试数据的平均准确率。
总结
- 从决策树的各种参数设置可以发现,大多都和控制生成树的规模有关,所以也反映出决策树模型是一种很容易过拟合的模型
- 一般来说,样本量过小时,容易过拟合,如果同时特征很多,此时应考虑降维
- 使用决策树模型时,可以利用决策树可视化的优点,探测性尝试树的深度
sklearn 学习之分类树的更多相关文章
- sklearn学习7-----决策树(tree)
1.使用示例 2.树模型参数:[很多参数都是用来限制树过于庞大,即担心其过拟合] # 1.criterion gini or entropy:用什么作为衡量标准 ( 熵值或者Gini系数 ). ...
- sklearn 学习 第一篇:分类
分类属于监督学习算法,是指根据已有的数据和标签(分类)进行学习,预测未知数据的标签.分类问题的目标是预测数据的类别标签(class label),可以把分类问题划分为二分类和多分类问题.二分类是指在两 ...
- Sklearn分类树在合成数集上的表现
小伙伴们大家好~o( ̄▽ ̄)ブ,今天我们开始来看一下Sklearn分类树的表现,我的开发环境是Jupyter lab,所用的库和版本大家参考: Python 3.7.1(你的版本至少要3.4以上) S ...
- C#无限极分类树-创建-排序-读取 用Asp.Net Core+EF实现之方法二:加入缓存机制
在上一篇文章中我用递归方法实现了管理菜单,在上一节我也提到要考虑用缓存,也算是学习一下.Net Core的缓存机制. 关于.Net Core的缓存,官方有三种实现: 1.In Memory Cachi ...
- C#无限极分类树-创建-排序-读取 用Asp.Net Core+EF实现
今天做一个管理后台菜单,想着要用无限极分类,记得园子里还是什么地方见过这种写法,可今天找了半天也没找到,没办法静下心来自己写了: 首先创建节点类(我给它取名:AdminUserTree): /// & ...
- 决策树算法原理(CART分类树)
决策树算法原理(ID3,C4.5) CART回归树 决策树的剪枝 在决策树算法原理(ID3,C4.5)中,提到C4.5的不足,比如模型是用较为复杂的熵来度量,使用了相对较为复杂的多叉树,只能处理分类不 ...
- sklearn学习总结(超全面)
https://blog.csdn.net/fuqiuai/article/details/79495865 前言sklearn想必不用我多介绍了,一句话,她是机器学习领域中最知名的python模块之 ...
- 机器学习实战---决策树CART简介及分类树实现
https://blog.csdn.net/weixin_43383558/article/details/84303339?utm_medium=distribute.pc_relevant_t0. ...
- php大力力 [025节] 来不及学习和分类的,大力力认为有价值的一些技术文章合集(大力力二叔公)(2015-08-27)
php大力力 [025节] 来不及学习和分类的,大力力认为有价值的一些技术文章合集(大力力二叔公)(2015-08-27) 比较好的模版 免费模板网,提供大量DIV+CSS布局网页模板下载及后台管理 ...
随机推荐
- (转)深度学习(Deep Learning, DL)的相关资料总结
from:http://blog.sciencenet.cn/blog-830496-679604.html 深度学习(Deep Learning,DL)的相关资料总结 有人认为DL是人工智能的一场革 ...
- 从RAID看垂直伸缩到水平伸缩的演化
磁盘的读写过程,最消耗时间的地方就是在磁盘中磁道寻址的过程,而一旦寻址完成,写入数据的速度很快. 连续写入:写入只寻址一次 存储位置与逻辑位置相邻 不用多次寻址 随机写入:每写一次 便寻址一次 增加了 ...
- poj3164(最小树形图&朱刘算法模板)
题目链接:http://poj.org/problem?id=3164 题意:第一行为n, m,接下来n行为n个点的二维坐标, 再接下来m行每行输入两个数u, v,表点u到点v是单向可达的,求这个有向 ...
- tarjan求强连通分量的思考
我是按照这里的思路来的.这个博文只是感性理解. 递归树 关于递归树,这篇博文讲的很好,我只是给自己总结一下. 定义vis数组,在dfs连通图时赋予它们不同的含义: vis=0,表示这个点没有被访问. ...
- [Xcode 实际操作]六、媒体与动画-(1)使用图形上下文按一定比例缩放图片
目录:[Swift]Xcode实际操作 本文将演示如何通过图形上下文,来实现图片缩放的功能. 在项目导航区,打开视图控制器的代码文件[ViewController.swift] import UIKi ...
- Linux命令 查看Linux版本和是否联网
1.查看Linux内核版本 1.1 $ cat /proc/version [heima01@heima01 ~]$ cat /proc/version Linux version 2.6.32-57 ...
- 2016 CCPC-Final
A.The Third Cup is Free #include <bits/stdc++.h> using namespace std; typedef long long ll; in ...
- IBM WebSphere MQ
相关链接: http://kakajw.iteye.com/category/269774 http://www.ibm.com/support/knowledgecenter/zh/SSFKSJ_7 ...
- Codeforces Round #564 (Div. 2) A. Nauuo and Votes
链接:https://codeforces.com/contest/1173/problem/A 题意: Nauuo is a girl who loves writing comments. One ...
- HDU-2063-过山车(最大匹配)
链接:https://vjudge.net/problem/HDU-2063 题意: RPG girls今天和大家一起去游乐场玩,终于可以坐上梦寐以求的过山车了.可是,过山车的每一排只有两个座位,而且 ...