SAS描述统计量
MEANS过程
- MEAN过程默认输出的统计量有:观测总数、均值、标准差、最大值和最小值。如果要计算其他统计量或其中的某一些统计量,则可在PROC语句中指定统计量的关键字。
- BY语句规定了分组变量,要求在BY分组内计算描述性统计量 。
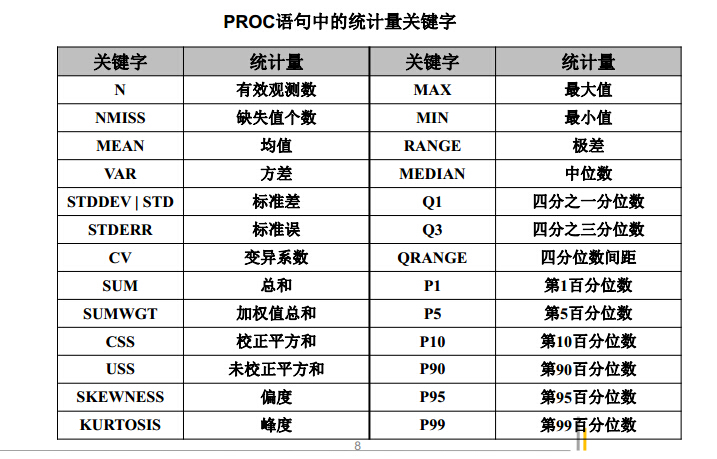
- proc means data=data.bank
- min p1 q1 mean median q3 p99 max ;
- run;
UNIVARIATE过程
- UNIVARIATE过程也可以提供描述统计量的计算,另外还有统计频数、绘制图形和假设检验的功能。
- 使用UNIVARIATE过程计算描述统计量与MEANS过程所用的语句和选项都基本类似,只是UNIVARIATE过程不需要指定统计量关键字,而是默认给出所有的基本统计量和一些关于位置检验的结果。
- proc univariate data=data.bank;
- run;
FREQ过程
- 描述分析,产生频数表和列联表,可以简单的描述数据
- 统计推断产生各种统计量,分析变量之间的关系
- TableS 用来定义频数表或交叉表,可以有多个tables语句。当频数表是命令为tables JOB1, 生成一维表;而命令为: tables JOB1*good_bad;变量之间中间用*隔开,表示生成二维交叉表
- Tables后的选项为norow nocol nopercent:若只需要频数,不需要各行各列的百分比,可在tables后面加上这些参数
- proc freq data=data.bank;
- table poutcome*y/norow nocol nopercent;
- run;
- 对连续数值变量做Freq时,系统会对每个数值进行频数统计,这个结果一般不是我们所需要的。我们一般会将连续变量转换为离散变量,这个可以通过Format过程步来实现。
- proc format;
- value age_cd
- 17-<25='<25'
- 25-<30='25-30'
- 30-<45='30-45'
- 45-<60='45-60'
- 60-high='>=60';
- run;
- proc freq data=data.bank;
- table y*age/norow nocol nopercent;
- format age age_cd.;
- run;
SAS描述统计量的更多相关文章
- 《R语言实战》读书笔记 第七章--基本统计分析
在导入数据并且将数据进行组织和初步可视化以后,需要对数据进行分布探索和两两关系分析等.主要内容有描述性统计分析.频数表和列联表.相关系数和协方差.t检验.非参数统计. 7.1描述性统计分析 7.1.1 ...
- R语言基础
一.扩展包的基本操作语句R安装好之后,默认自带了"stats" "graphics" "grDevices" "utils&qu ...
- 基于SPSS的美国老年夏季运动会运动员数据分析
本文是课程训练的报告,部分图片由于格式原因并没有贴出,有兴趣者阅读完整报告者输入以下链接 http://files.cnblogs.com/files/liugl7/基于SPSS的老 ...
- R语言-混合型数据聚类
利用聚类分析,我们可以很容易地看清数据集中样本的分布情况.以往介绍聚类分析的文章中通常只介绍如何处理连续型变量,这些文字并没有过多地介绍如何处理混合型数据(如同时包含连续型变量.名义型变量和顺序型变量 ...
- SPSS简单使用
当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量.数据录入.统计分析 ...
- (十一)T检验-第二部分
了解什么是有效大小,尝试一个单一样本t检验的完整示例. 效应量 调查研究的一个重要方面是效应量,在实验性研究中或存在处理变量的研究中,效应量是指处理效应的大小,意思很直观: 在非实验性研究中,效应量是 ...
- R语言学习笔记:使用reshape2包实现整合与重构
R语言中提供了许多用来整合和重塑数据的强大方法. 整合 aggregate 重塑 reshape 在整合数据时,往往将多组观测值替换为根据这些观测计算的描述统计量. 在重塑数据时,则会通过修改数据的结 ...
- (数据科学学习手札19)R中基本统计分析技巧总结
在获取数据,并且完成数据的清洗之后,首要的事就是对整个数据集进行探索性的研究,这个过程中会利用到各种描述性统计量和推断性统计量来初探变量间和变量内部的基本关系,本篇笔者便基于R,对一些常用的数据探索方 ...
- 基于R语言的数据分析和挖掘方法总结——中位数检验
3.1 单组样本符号秩检验(Wilcoxon signed-rank test) 3.1.1 方法简介 此处使用的统计分析方法为美国统计学家Frank Wilcoxon所提出的非参数方法,称为Wilc ...
随机推荐
- struts2 ognl表达式访问值栈
1:简单的说,值栈是对应每一个请求对象的轻量级的数据存储中心,在这里统一管理着数据,供Action.Result.Interceptor等Struts2的其他部分使用,这样数据被集中管理起来而不凌乱. ...
- iOS VIPER架构(二)
第一篇文章对VIPER进行了简单的介绍,这篇文章将从VIPER的源头开始,比较现有的几种VIPER实现,对VIPER进行进一步的职责剖析,并对各种细节实现问题进行挖掘和探讨.最后给出两个完整的VIPE ...
- EF6 CodeFirst连接MySql 报nvarchar('max')错误解决办法
1.在DBContext类加标签[DbConfigurationType(typeof(MySql.Data.Entity.MySqlEFConfiguration))] 2.在Nuget控制台输入u ...
- Python+selenium之截图图片并保存截取的图片
本文转载:http://blog.csdn.net/u011541946/article/details/70141488 http://www.cnblogs.com/timsheng/archiv ...
- COGS 2342. [SCOI2007]kshort
★★☆ 输入文件:bzoj_1073.in 输出文件:bzoj_1073.out 简单对比时间限制:2 s 内存限制:512 MB [题目描述] 有n个城市和m条单向道路,城市编号为1 ...
- Uva 127 poj 1214 `Accordian'' Patience 纸牌游戏 模拟
Input Input data to the program specifies the order in which cards are dealt from the pack. The inpu ...
- Python 进程 线程总结
操作系统的底层是 进程 线程 实现的 进程 操作系统完成系统进程的切换,中间有状态的保存.进程有自己独立的空间,进程多,资源消耗大 进程是最小的资源管理单位 可以理解为盛放线程的容器 线程 线程是最小 ...
- openstack nova fail to create vm
2019-05-13 14:43:27.017 47547 ERROR nova.compute.manager [req-3f1af0ed-c342-4cf3-8e76-6963053a5227 8 ...
- C++类和结构体的区别
C++类和结构体的区别? 结构体默认数据访问控制是public; 类默认数据访问控制是private;
- linux ecrypt decrypt
reference ecrypt vickey | openssl enc -aes-256-cbc -a -salt -pass pass:wu decrypt echo U2FsdGVkX1+Hn ...