Python动态属性和特性(一)
在Python中,数据的属性和处理数据的方法统称为属性。其实,方式只是可调用的属性。除了这二者之外,我们还可以创建特性(property),在不改变类接口的前提下,使用存取方法(即读取值和设置值方法)修改属性
Python提供了丰富的API,用于控制属性的访问权限,以及实现动态属性。当我们访问obj的data属性时,类似obj.data,Python解释器会调用特殊方法如__getattr__或__setattr__计算属性。用户自定义的类可以通过__getattr__方法实现虚拟属性,当访问的属性不存在时,即时计算属性的值
我们先从远程下载一个复杂的json文件并保存在本地
from urllib.request import urlopen
import warnings
import os
import json URL = 'http://www.oreilly.com/pub/sc/osconfeed'
JSON = 'data/osconfeed.json' def load():
if not os.path.exists(JSON):
msg = 'downloading {} to {}'.format(URL, JSON)
warnings.warn(msg) # <1>
with urlopen(URL) as remote, open(JSON, 'wb') as local: # <2>
local.write(remote.read()) with open(JSON, encoding="utf-8") as fp:
return json.load(fp) # <3>
这里,我们仅展示一部分的json文件的内容
{
"Schedule": {
"conferences": [{
"serial": 115
}],
"events": [{
"serial": 34505,
"name": "Why Schools Don´t Use Open Source to Teach Programming",
"event_type": "40-minute conference session",
"time_start": "2014-07-23 11:30:00",
"time_stop": "2014-07-23 12:10:00",
"venue_serial": 1462,
"description": "Aside from the fact that high school programming...",
"website_url": "http://oscon.com/oscon2014/public/schedule/detail/34505",
"speakers": [157509],
"categories": ["Education"]
}],
"speakers": [{
"serial": 157509,
"name": "Robert Lefkowitz",
"photo": null,
"url": "http://sharewave.com/",
"position": "CTO",
"affiliation": "Sharewave",
"twitter": "sharewaveteam",
"bio": "Robert ´r0ml´ Lefkowitz is the CTO at Sharewave, a startup..."
}],
"venues": [{
"serial": 1462,
"name": "F151",
"category": "Conference Venues"
}]
}
}
我们可以看到文件的json文件里面的第一个键是Schedule,这个键对应的值也是一个字典,这个字典下还有四个键,分别是"conferences"、 "events"、 "speakers" 和 "venues",这四个键分别对应一个列表,在完整的数据集中, 列表中有成百上千条记录。 不过,"conferences" 键对应的列表中只有一条记录,这 4 个列表中的每个元素都有一个名为 "serial" 的字段,这是元素在各个列表中的唯一标识符。
下面,让我们打印一下"conferences"、 "events"、 "speakers" 和 "venues"对应的列表的长度
feed = load()
print(sorted(feed["Schedule"].keys()))
print(feed["Schedule"]["speakers"][-1]["name"])
print(feed["Schedule"]["speakers"][40]["name"])
for key, value in sorted(feed["Schedule"].items()):
print("{:3} {}".format(len(value), key))
运行结果:
['conferences', 'events', 'speakers', 'venues']
Carina C. Zona
Tim Bray
1 conferences
494 events
357 speakers
53 venues
从上述示例中,我们可以看到如果要访问一个键,必须以feed['Schedule']['events'][40]['name']这种冗长的写法来访问,我们可以尝试实现一个FrozenJSON类,来包装我们原先的json数据,然后以feed.Schedule.events的形式来对字典进行访问
from collections import abc
class FrozenJSON:
def __init__(self, mapping):
self.__data = dict(mapping) # <1>
def __getattr__(self, name): # <2>
if hasattr(self.__data, name):
return getattr(self.__data, name)
else:
return FrozenJSON.build(self.__data[name])
@classmethod
def build(cls, obj): # <3>
if isinstance(obj, abc.Mapping):
return cls(obj)
elif isinstance(obj, abc.MutableSequence):
return [cls.build(item) for item in obj]
else:
return obj
- FrozenJSON类接收一个字典,并复制字典的副本作为自身的属性
- 当我们调用FrozenJSON的实例的某个属性时,如frozenJson.attr,如果attr不是实例本身的属性,则会调用__getattr__方法,该方法中,我们实现了先检查attr是不是字典的某个属性,如果是则返回该属性,如果不是则当成要访问的属性是字典的某个键,将其值取出传入FrozenJSON.build()方法并返回
- FrozenJSON.build()是一个类方法,它接收一个对象,如果该是字典对象,它会调用自身的初始化方法,如果该对象时可迭代对象,则遍历该对象所有的元素,并重新将元素传入自身的build()方法中,最后,如果该对象既不是字典,也不是一个可迭代的对象,则毫无改动的返回原始对象
现在,让我们试一下FrozenJSON类,我们获取原先的json文件,并传入FrozenJSON类中初始化一个FrozenJSON实例,我们通过obj.attr的方式来访问原先字典中的键,还可以调用key()、items()等方法
raw_feed = load()
feed = FrozenJSON(raw_feed)
print(len(feed.Schedule.speakers))
print(sorted(feed.Schedule.keys()))
for key, value in sorted(feed.Schedule.items()):
print('{:3} {}'.format(len(value), key))
print(feed.Schedule.speakers[-1].name)
talk = feed.Schedule.events[40]
print(type(talk))
print(talk.name)
运行结果:
357
['conferences', 'events', 'speakers', 'venues']
1 conferences
494 events
357 speakers
53 venues
Carina C. Zona
<class '__main__.FrozenJSON'>
There *Will* Be Bugs
FrozenJSON 类的关键是 __getattr__ 方法,仅当无法使用常规的方式获取属性(即在实例、 类或超类中找不到指定的属性), 解释器才会调用特殊的 __getattr__ 方法。读取不存在的属性会抛出 KeyError 异常,而不是通常抛出的AttributeError 异常。
FrozenJSON 类只有两个方法(__init__ 和__getattr__)和一个实例属性 __data。因此,尝试获取其他属性会触发解释器调用__getattr__方法。这个方法首先查看self.__data字典有没有指定名称的属性(不是键) , 这样 FrozenJSON 实例便可以处理字典的所有方法,例如把 items 方法委托给self.__data.items() 方法。如果 self.__data 没有指定名称的属
性,那么 __getattr__ 方法以那个名称为键, 从 self.__data 中获取一个元素,传给 FrozenJSON.build 方法。这样就能深入JSON数据的嵌套结构,使用类方法 build 把每一层嵌套转换成一个 FrozenJSON实例。
当我们传入的字典对象包含的键是关键字,例如下面这个示例,如果我们要访问grad.class,势必会报错,这个时候我们只能通过getattr()方法来访问
grad = FrozenJSON({"name": "Jim Bo", "class": 1982})
print(getattr(grad, "class"))
或者,我们可以改造__init__方法,当检查出一个键是关键字的时候,自动加上一个下划线_,这样,当我们要访问grad中的class属性时,直接用grad.class_就行
def __init__(self, mapping):
import keyword
self.__data = {}
for key, value in mapping.items():
if keyword.iskeyword(key):
key += "_"
self.__data[key] = value
但是,如果有时候我们要访问的键并不是有效的标识符,比如2_a同样是传入字典的一个键,但它并不是一个有效的标识符,这个如果调用grad.2_a会抛出SyntaxError: invalid token的错误
grad = FrozenJSON({"name": "Jim Bo", "class": 1982, "2_a": "hello"})
print(getattr(grad, "2_a"))
于是,我们只能通过getattr()方法来获取值,又或者我们像之前那样,通过将键值变为合法,再来访问,我们再次改造FrozenJSON的初始化__init__方法
def __init__(self, mapping):
import keyword
self.__data = {}
for key, value in mapping.items():
if keyword.iskeyword(key):
key += "_"
if not str.isidentifier(key):
key = "_{0}".format(key)
self.__data[key] = value
这个方法会遍历mapping所有的键,当键是关键字的时候,在键的尾部加上下划线,当键并不是关键字的时候,在键的头部加上下划线,然后我们再来访问class和2_a的属性
grad = FrozenJSON({"name": "Jim Bo", "class": 1982, "2_a": "hello"})
print(grad.class_)
print(grad._2_a)
运行结果:
1982
hello
在后面这个键是否能作为标识符的时候,情况会略微复杂,因为键可以包含乘号或加号,如果一旦包含一些特殊符号,那只能通过getattr()来获取了
我们通常说,__init__称为构造方法,其实,用于构建实例的是特殊方法__new__方法,这是个类方法,使用特殊方式处理,因此不用加上@classmethod 装饰器,这个方法会返回一个实例,实例会作为第一个参数(即self)传入__init__方法。因为调用__init__方法时要传入实例,而且禁止返回任何值,所以__init__其实是初始化方法,真正的构造方法时__new__,我们几乎不需要自己编写 __new__ 方法,因为从 object 类继承的实现已经足够了。
class Foo(object):
def __init__(self, bar):
self.bar = bar def object_maker(the_class, some_arg):
new_object = the_class.__new__(the_class)
if isinstance(new_object, the_class):
the_class.__init__(new_object, some_arg)
return new_object demo1 = Foo("bar1")
demo2 = object_maker(Foo, "bar2")
print(demo1)
print(demo1.bar)
print(demo2)
print(demo2.bar)
运行结果:
<__main__.Foo object at 0x0000005184EB1F98>
bar1
<__main__.Foo object at 0x0000005184EB11D0>
bar2
可以看到,我们既可以用Foo类来初始化一个对象,也可以把Foo和所需参数传入object_maker方法,来构造一个我们需要的对象
现在,让我们用__new__方法来代替刚才FrozenJSON类的build()方法
from collections import abc
class FrozenJSON:
def __new__(cls, arg):
if isinstance(arg, abc.Mapping):
return super().__new__(cls)
elif isinstance(arg, abc.MutableSequence):
return [cls(item) for item in arg]
else:
return arg
def __init__(self, mapping):
self.__data = dict(mapping)
def __getattr__(self, name):
if hasattr(self.__data, name):
return getattr(self.__data, name)
else:
return FrozenJSON(self.__data[name])
在__getattr__中,如果访问的键并非__data本身的属性,我们不再调用FrozenJSON.build()方法传入,而是之间把参数传入FrozenJSON的构造方法,这个方法它可能返回一个FrozenJSON实例,也可能不是,我们都知道,当Python要构造一个实例时,首先会调用__new__方法返回一个实例,再用__init__方法对实例进行属性的初始化,在FrozenJSON中,只有arg为Mapping类型时,返回的才是FrozenJSON实例,当arg是一个list或其他类型时,返回的就不是FrozenJSON对象了,这时候Python解释器拿到这个对象,会对比__new__返回的实例和它要创建的实例是不是同一个类型,只有同一个类型,Python解释器才会接着调用__init__进行初始化操作,否则直接将从__new__方法拿到的实例返回
shelve类似一个可持久化的字典,他有一个open()函数,这个函数接收一个参数就是文件名,然后返回一个shelve.Shelf 实例,我们可以用他来存储一些键值对,当存储完毕的时候,就调用close函数来关闭,shelve有以下几个特点:
- shelve.Shelf 是 abc.MutableMapping 的子类,因此提供了处理映射类型的重要方法
- 此外,shelve.Shelf 类还提供了几个管理I/O的方法,如sync和close;它也是一个上下文管理器
- 只要把新值赋予键,就会保存键和值
- 键必须是字符串
- 值必须是 pickle 模块(可序列化对象的模块)能处理的对象
再回到我们之前从网上下载的json文件,之前我们解析过这个文件,文件内部的第一个键是Schedule,而这个键对应的字典还有四个键conferences、events、speakers、venues,而这四个键对应的值,又是包着很多字典对象的list,我们不用去了解这个文件到底在说明什么,现在只需要了解一点,conferences、events、speakers、venues这四个键对应的list中的每一个字典对象,都包含一个叫serial的键,这个键对应的值是一个数字,现在,让我们遍历Schedule下的四个键,并将这四个键与list下每个字典对象中的serial键对应的值相结合相结
class Record:
def __init__(self, **kwargs): # <6>
self.__dict__.update(kwargs)
def load_db(db):
raw_data = load() # <3>
for collection, rec_list in raw_data['Schedule'].items():
record_type = collection[:-1] # <4>
for record in rec_list:
key = '{}.{}'.format(record_type, record['serial']) # <5>
record['serial'] = key
db[key] = Record(**record)
import shelve
DB_NAME = 'data/schedule1_db'
CONFERENCE = 'conference.115'
db = shelve.open(DB_NAME) # <1>
if CONFERENCE not in db: # <2>
load_db(db)
- 先根据DB_NAME请求一个shelve.Shelf 实例
- 得到db(即shelve.Shelf 实例)后,检查conference.115这个键是否在db这个键值对数据库中,如果不在,调用load_db()方法开始加载数据
- 再次用load()方法获取json文件
- 我们遍历json文件下Schedule对应的四个键,分别是conferences、events、speakers、venues,而collection[:-1]代表去除这四个键中最后一个字母,即s,然后存入key
- rec_list代表上述4个键对应的包含字典对象的列表,我们遍历这个列表,取出每个字典对象的serial键,并与key相结合,比如:"conferences":[{"serial":115},{"serial":116}]就会形成两个键,分别是conference.115,conference.116,当然,在我们的json文件中,conferences这个键只有一个{"serial":115}对象,并没有{"serial":116}对象,这里只是举例说明,之后,我们用key替代原先serial的值,并初始化一个Record对象
- 我们将一个字典传入Record的初始化方法,self.__dict__.update(kwargs)这个方法会将kwargs这个字典中所有的键初始化为Record这个对象的属性,也就是说,self.__dict__这个字典,存着是本对象的所有属性
然后,我们尝试一下通过shelve来访问这个json文件
speaker = db['speaker.3471']
print(type(speaker))
print(speaker.name, speaker.twitter)
db.close()
运行结果:
<class 'schedule1.Record'>
Anna Martelli Ravenscroft annaraven
这里可以看到,speakers下,serial为3471所在的字典的name和twitter的值是否和我们打印出来的值一一对应,这里还有一点要记住,就是打开db后,最后要记得关闭db
events下的每个字典里都有两个键,一个是venue_serial,另一个是speakers,让我们扩展之前的Record类,使得我们访问event下的venue或speakers返回的不再是一个冷冰冰的id,而是关联到venues或speakers的实体字典
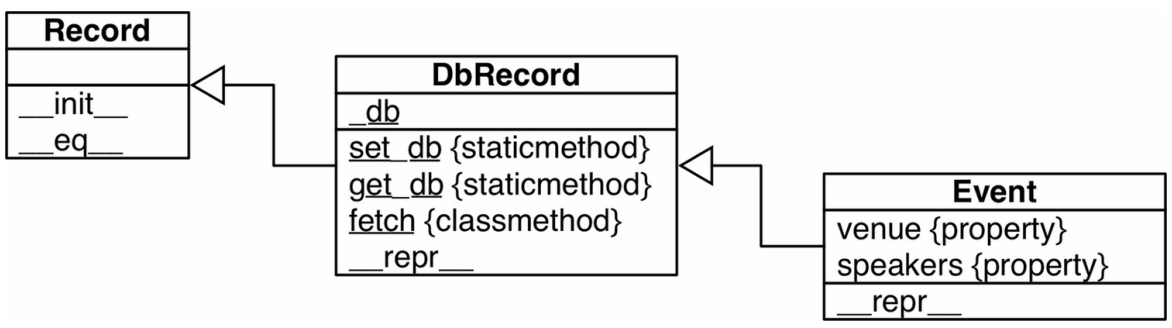
如上图所示,我们在原先的Record类的基础上,又扩展的两个类,分别是DbRecord和Event,DbRecord继承自Record,而Event继承自DbRecord
class Record:
def __init__(self, **kwargs):
self.__dict__.update(kwargs) def __eq__(self, other):
if isinstance(other, Record):
return self.__dict__ == other.__dict__
else:
return NotImplemented
首先是Record类,我们看到,__init__方法没有变化,只是多了一个__eq__方法,比较两个Record中包含的__dict__(即类本身的属性)是否相等,如果不相等,则返回一个NotImplemented,这里多介绍一下NotImplemented这个内建常量
class A:
def __init__(self, num):
self.num = num def __eq__(self, other):
print("call A __eq__")
return NotImplemented class B:
def __init__(self, num):
self.num = num def __eq__(self, other):
print("call B __eq__")
return self.num == other.num a = A(1)
b = B(1)
print(a == b)
运行结果:
call A __eq__
call B __eq__
True
可以看到,类A的__eq__方法不管传入什么,最后都会返回一个NotImplemented,当Python解释器接收到一个NotImplemented常量,就会调用b.__eq__(a)进行比较
class MissingDatabaseError(RuntimeError):
"""Raised when a database is required but was not set.""" class DbRecord(Record):
__db = None @staticmethod
def set_db(db): # <1>
DbRecord.__db = db @staticmethod
def get_db(): # <2>
return DbRecord.__db @classmethod
def fetch(cls, ident): # <3>
db = cls.get_db()
try:
return db[ident]
except TypeError:
if db is None: # <4>
msg = "database not set; call '{}.set_db(my_db)'"
raise MissingDatabaseError(msg.format(cls.__name__))
else:
raise def __repr__(self): # <5>
if hasattr(self, 'serial'):
cls_name = self.__class__.__name__
return '<{} serial={!r}>'.format(cls_name, self.serial)
else:
return super().__repr__()
- 设置数据源,即shelve.Shelf 实例
- 获取数据源
- 传入一个键,从数据源中获取对应的值
- 当数据源为None时抛出MissingDatabaseError错误
- 重定义当前record对象的打印信息
class Event(DbRecord):
@property
def venue(self):
key = 'venue.{}'.format(self.venue_serial)
h = self.__class__.fetch(key)
return self.__class__.fetch(key)
@property
def speakers(self):
if not hasattr(self, '_speaker_objs'):
spkr_serials = self.__dict__['speakers']
fetch = self.__class__.fetch
self._speaker_objs = [fetch('speaker.{}'.format(key))
for key in spkr_serials]
return self._speaker_objs
def __repr__(self):
if hasattr(self, 'name'):
cls_name = self.__class__.__name__
return '<{} {!r}>'.format(cls_name, self.name)
else:
return super().__repr__()
Event类主要是用于遍历events下的字典所用,当我们访问venue这个属性时,他会结合自身venue_serial所对应的值形成venue.{venue_serial},再次返回数据源,同理speakers,当要从event访问speakers,先检查_speaker_objs是否存在,如果不存在,则取出自身的speakers对象,这是一个list,里面包含多个speakers的id,然后遍历这个list从数据源中取出对应的speakers,并缓存为_speaker_objs属性
这里,我们需要改造一下之前的load_db方法
def load_db(db):
raw_data = load()
for collection, rec_list in raw_data['Schedule'].items():
record_type = collection[:-1] # <1>
cls_name = record_type.capitalize() # <2>
cls = globals().get(cls_name, DbRecord) # <3>
if inspect.isclass(cls) and issubclass(cls, DbRecord): # <4>
factory = cls
else:
factory = DbRecord
for record in rec_list: # <5>
key = '{}.{}'.format(record_type, record['serial'])
record['serial'] = key
db[key] = factory(**record) # <6> import shelve db = shelve.open(DB_NAME)
if CONFERENCE not in db:
load_db(db)
DbRecord.set_db(db) # <9>
- collection依旧是Schedule下的四个键,分别是conferences、events、speakers、venues,collection[:-1]可以把这四个键最后的s字符去除
- 将去除尾部s的四个键首字母大写
- 经过上面两个步骤,四个键分别为Conference、Event、Seaker、Venue,检查全局域内是否有和这四个键名称相同的类型,如果有则取出,没有则返回DbRecord,由于我们之前定义了Event类,所以当遍历到events键时,会取出之前定义好的Event类,而其他三个键则会默认返回DbRecord
- 检查从全局域中取出来的类型是否是类型对象,且是DbRecord的子类,并赋值给factory
- 遍历四个键下所有的字典,当遍历到events这个键时,存入数据源的对象时Event类型,而其他三个键则是DbRecord类型
然后,我们尝试获取event下的venue和speakers
event = DbRecord.fetch('event.33950')
print(event)
print(type(event))
print(event.venue)
print(event.venue.name)
print(event.speakers)
for spkr in event.speakers:
print('{0.serial}: {0.name}'.format(spkr))
运行结果:
<Event 'There *Will* Be Bugs'>
<class 'schedule2.Event'>
<DbRecord serial='venue.1449'>
Portland 251
[<DbRecord serial='speaker.3471'>, <DbRecord serial='speaker.5199'>]
speaker.3471: Anna Martelli Ravenscroft
speaker.5199: Alex Martelli
Python动态属性和特性(一)的更多相关文章
- Python动态属性和特性(二)
内置的property经常用作装饰器,但它其实是一个类.在Python中,函数和类通常可以互换,因为二者都是可调用对象,而且没有实例化的new运算符,所以调用构造方法和调用工厂函数没有区别,只要能返回 ...
- python的__future__特性
使用python的__future__特性, __future__是在旧版本的python中提供了新版python的特性. 1) 在python2中相除返回浮点数,在python3中默认返回浮点数 & ...
- Python的高级特性8:你真的了解类,对象,实例,方法吗
Python的高级特性1-7系列是本人从Python2过渡3时写下的一些个人见解(不敢说一定对),接下来的系列主要会以类级为主. 类,对象,实例,方法是几个面向对象的几个基本概念,其实我觉得很多人并不 ...
- Python的高级特性7:闭包和装饰器
本节跟第三节关系密切,最好放在一起来看:python的高级特性3:神奇的__call__与返回函数 一.闭包:闭包不好解释,只能先看下面这个例子: In [23]: def outer(part1): ...
- python的高级特性:切片,迭代,列表生成式,生成器,迭代器
python的高级特性:切片,迭代,列表生成式,生成器,迭代器 #演示切片 k="abcdefghijklmnopqrstuvwxyz" #取前5个元素 k[0:5] k[:5] ...
- Python 3 新特性:类型注解——类似注释吧,反正解释器又不做校验
Python 3 新特性:类型注解 Crossin 上海交通大学 计算机应用技术硕士 95 人赞同了该文章 前几天有同学问到,这个写法是什么意思: def add(x:int, y:int) - ...
- Python动态属性有什么用
Python 动态属性的概念可能会被面试问到,在项目当中也非常实用,但是在一般的编程教程中不会提到,可以进修一下. 先看一个简单的例子.创建一个 Student 类,我希望通过实例来获取每个学生的一些 ...
- 流畅python学习笔记:第十九章:动态属性和特性
首先来看一个json文件的读取.书中给出了一个json样例.该json文件有700多K,数据量充足,适合本章的例子.文件的具体内容可以在http://www.oreilly.com/pub/sc/os ...
- 【Python】【元编程】【一】动态属性和特性
#19.1 使用动态属性转换数据"""#栗子19-2 osconfeed.py:下载 osconfeed.jsonfrom urllib.request import u ...
随机推荐
- paas相关,添加ing
1. docker 构建镜像,docker build -t image_name:version dockerfilePath.使用镜像启动一个docker容器,docker run --name ...
- 介绍我最近做的网站 Asp.Net MVC4 + BootStrap
一.前言 最近一直在做一个多站SEO数据分析的站点(www.easyyh.com),用了一些新技术,如Asp.Net MVC4,BootStrap,EasyUI,这些都是以前没有搞过的,最近搞得差不多 ...
- I/O操做总结(四))
前面已经把java io的主要操作讲完了 这一节我们来说说关于java io的其他内容 Serializable序列化 实例1:对象的序列化 1 2 3 4 5 6 7 8 9 10 11 12 13 ...
- spring data jpa 简单使用
通过解析方法名创建查询 通过前面的例子,读者基本上对解析方法名创建查询的方式有了一个大致的了解,这也是 Spring Data JPA 吸引开发者的一个很重要的因素.该功能其实并非 Spring Da ...
- countUp 动画展示数字变化
html <p id="countUp" style="font-size:25px;height:25px;background-color:#0aa;" ...
- Windows Azure 配置Active Directory 主机(4)
步骤 6:设置在启动时加入域的虚拟机 若要创建其他在首次启动时加入域的虚拟机,请打开 Windows Azure PowerShell ISE,粘贴以下脚本,将占位符替换为您自己的值并运行该脚本. 若 ...
- BZOJ 3992: [SDOI2015]序列统计 NTT+快速幂
3992: [SDOI2015]序列统计 Time Limit: 30 Sec Memory Limit: 128 MBSubmit: 1155 Solved: 532[Submit][Statu ...
- cookie存验证码时间,时间没走完不能再次点击
<script> var balanceSeconds=getcookie('Num'); console.log(balanceSeconds) var timer; var isCli ...
- [dp][uestc]L - 菲波拉契数制升级版
数据很大,以背包的思路数组开不下. 先定序地考虑一个菲波拉契数如fib(i)的表示法,假设i比较大,由菲波拉契数的定义可知道fib(i)=fib(i-1)+fib(i-2);要找到其它表示就继续拆分f ...
- Spark Job具体的物理执行
即使采用pipeline的方式,函数f对依赖的RDD中的数据集合的操作也会有两种方式: 1.f(record),f作用于集合的每一条记录,每次只作用于一条记录 2.f(records),f一次性作用于 ...