[深度应用]·Keras实现Self-Attention文本分类(机器如何读懂人心)
[深度应用]·Keras实现Self-Attention文本分类(机器如何读懂人心)
配合阅读:
笔者在[深度概念]·Attention机制概念学习笔记博文中,讲解了Attention机制的概念与技术细节,本篇内容配合讲解,使用Keras实现Self-Attention文本分类,来让大家更加深入理解Attention机制。
作为对比,可以访问[TensorFlow深度学习深入]实战三·分别使用DNN,CNN与RNN(LSTM)做文本情感分析,查看不同网络区别与联系。
一、Self-Attention概念详解
了解了模型大致原理,我们可以详细的看一下究竟Self-Attention结构是怎样的。其基本结构如下
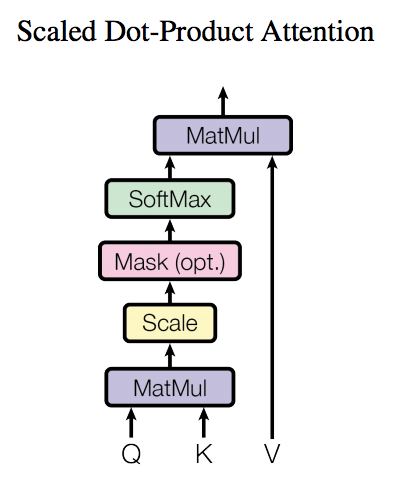

对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度 ,其中 为一个query和key向量的维度。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。该操作可以表示为
这里可能比较抽象,我们来看一个具体的例子(图片来源于https://jalammar.github.io/illustrated-transformer/,该博客讲解的极其清晰,强烈推荐),假如我们要翻译一个词组Thinking Machines,其中Thinking的输入的embedding vector用 表示,Machines的embedding vector用 表示。
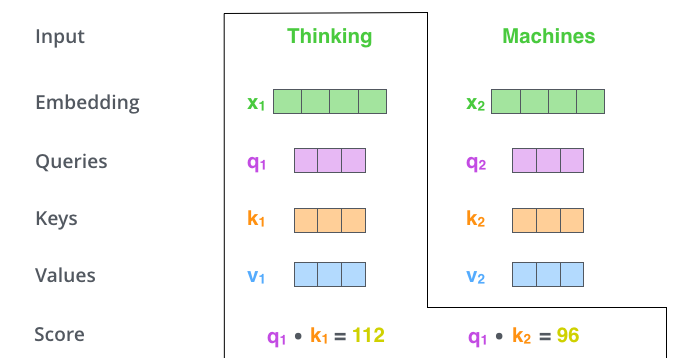
当我们处理Thinking这个词时,我们需要计算句子中所有词与它的Attention Score,这就像将当前词作为搜索的query,去和句子中所有词(包含该词本身)的key去匹配,看看相关度有多高。我们用 代表Thinking对应的query vector, 及 分别代表Thinking以及Machines对应的key vector,则计算Thinking的attention score的时候我们需要计算 与 的点乘,同理,我们计算Machines的attention score的时候需要计算 与 的点乘。如上图中所示我们分别得到了 与 的点乘积,然后我们进行尺度缩放与softmax归一化,如下图所示:
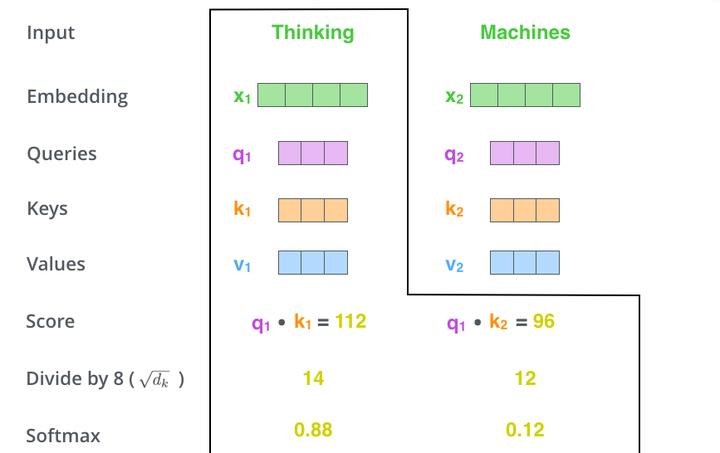
显然,当前单词与其自身的attention score一般最大,其他单词根据与当前单词重要程度有相应的score。然后我们在用这些attention score与value vector相乘,得到加权的向量。
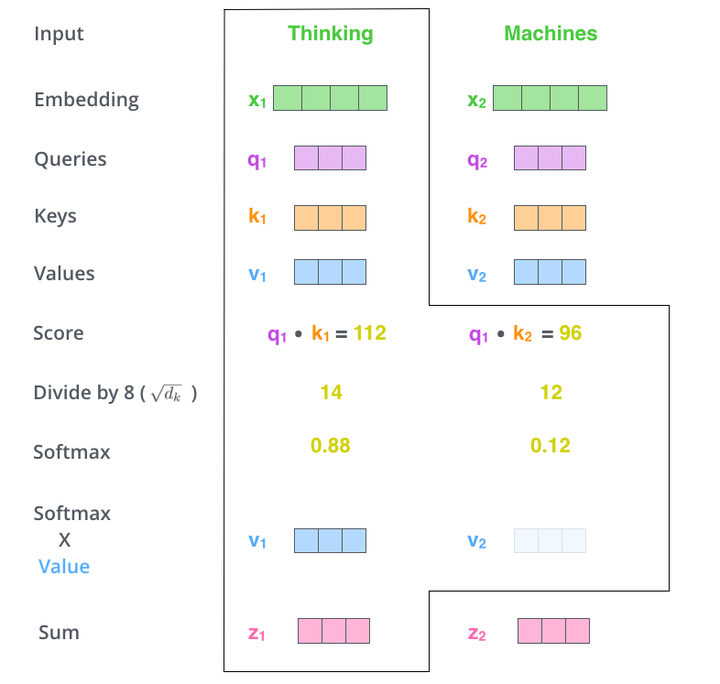
如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示
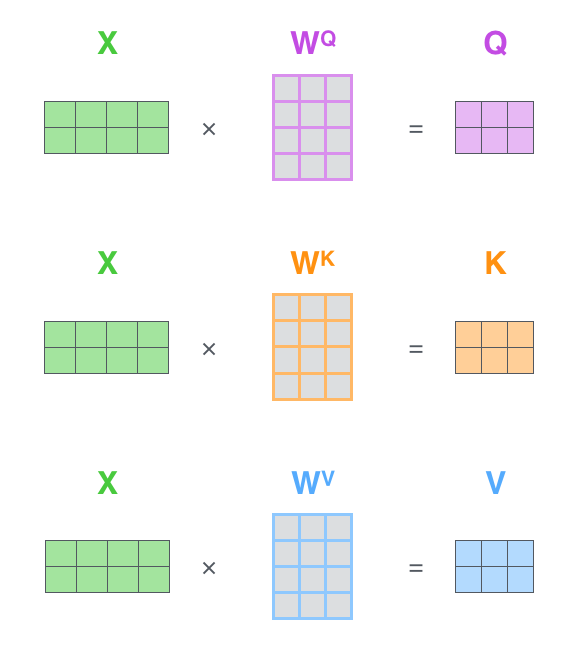
其中 是我们模型训练过程学习到的合适的参数。上述操作即可简化为矩阵形式
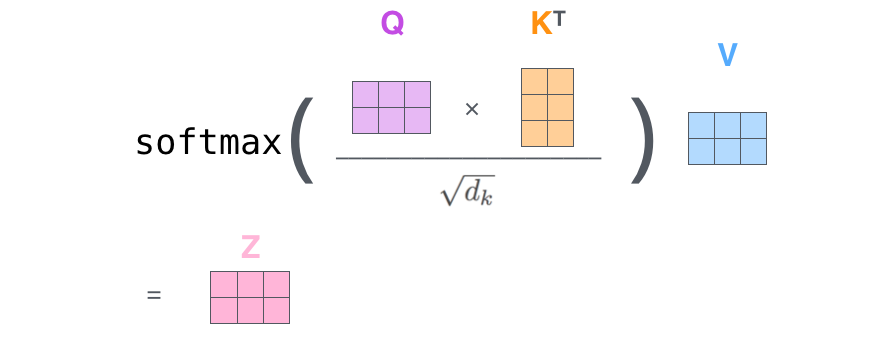
二、Self_Attention模型搭建
笔者使用Keras来实现对于Self_Attention模型的搭建,由于网络中间参数量比较多,这里采用自定义网络层的方法构建Self_Attention,关于如何自定义Keras可以参看这里:编写你自己的 Keras 层
Keras实现自定义网络层。需要实现以下三个方法:(注意input_shape是包含batch_size项的)
build(input_shape): 这是你定义权重的地方。这个方法必须设self.built = True,可以通过调用super([Layer], self).build()完成。call(x): 这里是编写层的功能逻辑的地方。你只需要关注传入call的第一个参数:输入张量,除非你希望你的层支持masking。compute_output_shape(input_shape): 如果你的层更改了输入张量的形状,你应该在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状。
实现代码如下:
from keras.preprocessing import sequence
from keras.datasets import imdb
from matplotlib import pyplot as plt
import pandas as pd from keras import backend as K
from keras.engine.topology import Layer class Self_Attention(Layer): def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(Self_Attention, self).__init__(**kwargs) def build(self, input_shape):
# 为该层创建一个可训练的权重
#inputs.shape = (batch_size, time_steps, seq_len)
self.kernel = self.add_weight(name='kernel',
shape=(3,input_shape[2], self.output_dim),
initializer='uniform',
trainable=True) super(Self_Attention, self).build(input_shape) # 一定要在最后调用它 def call(self, x):
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2]) print("WQ.shape",WQ.shape) print("K.permute_dimensions(WK, [0, 2, 1]).shape",K.permute_dimensions(WK, [0, 2, 1]).shape) QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1])) QK = QK / (64**0.5) QK = K.softmax(QK) print("QK.shape",QK.shape) V = K.batch_dot(QK,WV) return V def compute_output_shape(self, input_shape): return (input_shape[0],input_shape[1],self.output_dim)
这里可以对照一中的概念讲解来理解代码
如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示
上述内容对应
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2])
其中 是我们模型训练过程学习到的合适的参数。上述操作即可简化为矩阵形式
上述内容对应(为什么使用batch_dot呢?这是由于input_shape是包含batch_size项的)
QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1]))
QK = QK / (64**0.5)
QK = K.softmax(QK)
print("QK.shape",QK.shape)
V = K.batch_dot(QK,WV)
这里 QK = QK / (64**0.5) 是除以一个归一化系数,(64**0.5)是笔者自己定义的,其他文章可能会采用不同的方法。
三、训练网络
项目完整代码如下,这里使用的是Keras自带的imdb影评数据集
#%%from keras.preprocessing import sequence
from keras.datasets import imdb
from matplotlib import pyplot as plt
import pandas as pd from keras import backend as K
from keras.engine.topology import Layer class Self_Attention(Layer): def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(Self_Attention, self).__init__(**kwargs) def build(self, input_shape):
# 为该层创建一个可训练的权重
#inputs.shape = (batch_size, time_steps, seq_len)
self.kernel = self.add_weight(name='kernel',
shape=(3,input_shape[2], self.output_dim),
initializer='uniform',
trainable=True) super(Self_Attention, self).build(input_shape) # 一定要在最后调用它 def call(self, x):
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2]) print("WQ.shape",WQ.shape) print("K.permute_dimensions(WK, [0, 2, 1]).shape",K.permute_dimensions(WK, [0, 2, 1]).shape) QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1])) QK = QK / (64**0.5) QK = K.softmax(QK) print("QK.shape",QK.shape) V = K.batch_dot(QK,WV) return V def compute_output_shape(self, input_shape): return (input_shape[0],input_shape[1],self.output_dim) max_features = 20000 print('Loading data...') (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
#标签转换为独热码
y_train, y_test = pd.get_dummies(y_train),pd.get_dummies(y_test)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences') #%%数据归一化处理 maxlen = 64 print('Pad sequences (samples x time)') x_train = sequence.pad_sequences(x_train, maxlen=maxlen) x_test = sequence.pad_sequences(x_test, maxlen=maxlen) print('x_train shape:', x_train.shape) print('x_test shape:', x_test.shape) #%% batch_size = 32
from keras.models import Model
from keras.optimizers import SGD,Adam
from keras.layers import *
from Attention_keras import Attention,Position_Embedding S_inputs = Input(shape=(64,), dtype='int32') embeddings = Embedding(max_features, 128)(S_inputs) O_seq = Self_Attention(128)(embeddings) O_seq = GlobalAveragePooling1D()(O_seq) O_seq = Dropout(0.5)(O_seq) outputs = Dense(2, activation='softmax')(O_seq) model = Model(inputs=S_inputs, outputs=outputs) print(model.summary())
# try using different optimizers and different optimizer configs
opt = Adam(lr=0.0002,decay=0.00001)
loss = 'categorical_crossentropy'
model.compile(loss=loss, optimizer=opt, metrics=['accuracy']) #%%
print('Train...') h = model.fit(x_train, y_train, batch_size=batch_size, epochs=5, validation_data=(x_test, y_test)) plt.plot(h.history["loss"],label="train_loss")
plt.plot(h.history["val_loss"],label="val_loss")
plt.plot(h.history["acc"],label="train_acc")
plt.plot(h.history["val_acc"],label="val_acc")
plt.legend()
plt.show() #model.save("imdb.h5")
四、结果输出

(TF_GPU) D:\Files\DATAs\prjs\python\tf_keras\transfromerdemo>C:/Files/APPs/RuanJian/Miniconda3/envs/TF_GPU/python.exe d:/Files/DATAs/prjs/python/tf_keras/transfromerdemo/train.1.py
Using TensorFlow backend.
Loading data...
25000 train sequences
25000 test sequences
Pad sequences (samples x time)
x_train shape: (25000, 64)
x_test shape: (25000, 64)
WQ.shape (?, 64, 128)
K.permute_dimensions(WK, [0, 2, 1]).shape (?, 128, 64)
QK.shape (?, 64, 64)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 64) 0
_________________________________________________________________
embedding_1 (Embedding) (None, 64, 128) 2560000
_________________________________________________________________
self__attention_1 (Self_Atte (None, 64, 128) 49152
_________________________________________________________________
global_average_pooling1d_1 ( (None, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 2,609,410
Trainable params: 2,609,410
Non-trainable params: 0
_________________________________________________________________
None
Train...
Train on 25000 samples, validate on 25000 samples
Epoch 1/5
25000/25000 [==============================] - 17s 693us/step - loss: 0.5244 - acc: 0.7514 - val_loss: 0.3834 - val_acc: 0.8278
Epoch 2/5
25000/25000 [==============================] - 15s 615us/step - loss: 0.3257 - acc: 0.8593 - val_loss: 0.3689 - val_acc: 0.8368
Epoch 3/5
25000/25000 [==============================] - 15s 614us/step - loss: 0.2602 - acc: 0.8942 - val_loss: 0.3909 - val_acc: 0.8303
Epoch 4/5
25000/25000 [==============================] - 15s 618us/step - loss: 0.2078 - acc: 0.9179 - val_loss: 0.4482 - val_acc: 0.8215
Epoch 5/5
25000/25000 [==============================] - 15s 619us/step - loss: 0.1639 - acc: 0.9368 - val_loss: 0.5313 - val_acc: 0.8106
五、Reference
1.https://zhuanlan.zhihu.com/p/47282410
[深度应用]·Keras实现Self-Attention文本分类(机器如何读懂人心)的更多相关文章
- 基于keras中IMDB的文本分类 demo
本次demo主题是使用keras对IMDB影评进行文本分类: import tensorflow as tf from tensorflow import keras import numpy a ...
- 用keras实现基本的文本分类任务
数据集介绍 包含来自互联网电影数据库的50000条影评文本,对半拆分为训练集和测试集.训练集和测试集之间达成了平衡,意味着它们包含相同数量的正面和负面影评,每个样本都是一个整数数组,表示影评中的字词. ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
- fastText、TextCNN、TextRNN……这里有一套NLP文本分类深度学习方法库供你选择
https://mp.weixin.qq.com/s/_xILvfEMx3URcB-5C8vfTw 这个库的目的是探索用深度学习进行NLP文本分类的方法. 它具有文本分类的各种基准模型,还支持多标签分 ...
- NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码)
NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码) 七月,酷暑难耐,认识的几位同学参加知乎看山杯,均取得不错的排名.当时天池AI医疗大赛初赛结束,官方正在为复赛进行平台调 ...
- 文本分类实战(五)—— Bi-LSTM + Attention模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
随机推荐
- 【Directory】文件操作(初识文件操作二)
上篇我们说了关于文件的创建删除更改可以通过File这个类来完成.对于目录的操作其实File类也可以完成创建删除等相关的操作.用法跟文件的方法大致相同. 那么下面就一起来看一下关于目录相关的用法. 一, ...
- mysql 分组查询前n条数据
今天去面试,碰到一道面试题: 有一个学生成绩表,表中有 表id.学生名.学科.分数.学生id .查询每科学习最好的两名学生的信息: 建表sql: CREATE TABLE `stuscore` ( ` ...
- service-worker实践
service-worker虽然已列入标准,但是支持的浏览器还是有限制,还有比较多的问题. 1. 生命周期 注册成功-------installing--------------> 安装成功(i ...
- 【Word Ladder II】cpp
题目: Given two words (start and end), and a dictionary, find all shortest transformation sequence(s) ...
- 【BZOJ 3620】似乎在梦中见过的样子
题目 (夢の中で逢った.ような--) 「Madoka,不要相信 QB!」伴随着 Homura 的失望地喊叫,Madoka 与 QB 签订了契约. 这是 Modoka 的一个噩梦,也同时是上个轮回中所发 ...
- Linux之ubuntu系统操作学习笔记
1,swp分区:当内存不够时用swp分区顶替内存 2,语言环境检查 locale –a:可以明白系统支持什么语言 3,安装软件: apt-cache search(软件):搜索软件 apt-cach ...
- 【转】Unity3D学习日记(一)使用UGUI制作虚拟摇杆
http://blog.csdn.net/begonia__z/article/details/51170059 如今手机游戏玩法多种多样,尤其使用虚拟摇杆进行格斗类游戏开发或者是MMORPG成为了主 ...
- Emma中文乱码解决方法
vim -/.emma/emmarc db_encoding=latin1 改为 db_encoding=utf8 sudo vim /usr/share/emma/emmalib/mysql_hos ...
- TortoiseGit保存用户名和密码的方法
TortoiseGit在提交或者pull时总会提示你输入用户名密码,非常麻烦,那如何解决呢? 1. 对于TortoiseGit 1.8.1.2及其后的版本,右键选择settings ——> Gi ...
- BZOJ1566 [NOI2009]管道取珠 【dp】
题目 输入格式 第一行包含两个整数n, m,分别表示上下两个管道中球的数目. 第二行为一个AB字符串,长度为n,表示上管道中从左到右球的类型.其中A表示浅色球,B表示深色球. 第三行为一个AB字符串, ...