hadoop 环境搭建
Hadoop 2、配置HDFS HA (高可用)

前提条件
先搭建 http://www.cnblogs.com/raphael5200/p/5152004.html 的环境,然后在其基础上进行修改
一、安装Zookeeper
由于环境有限,所以在仅有的4台虚拟机上完成多个操作;
a.在4台虚拟中选3台安装Zookeeper,我选 node5 node6 node7
b.在4台虚拟中选3台作为JournalNode的节点,我选node6 node7 node8
c..在4台虚拟中选2台作为NameNode ,我选node5(Active) node8(Standby)
1.解压并移动
下载并解压zookper压缩包,将zookeeper复制到/usr/local/zookeeper目录下;
2.配置Zookeeper

$ cd /usr/local/zookeeper/
$ vim /conf/zoo.cfg
#写入
tickTime=2000
dataDir=/opt/zookeeper #指定Zookeeper的Data目录
clientPort=2181
initLimit=5
syncLimit=2
# 3台节点
server.1=node5:2888:3888
server.2=node6:2888:3888
server.3=node7:2888:3888
3.配置zookeeper的环境变量
$ vim /root/.bash_profile
#写入
PATH=$PATH:/usr/local/zookeeper-3.4.6/bin
4.覆盖node6 和 node7的zookeeper配置文件和.bash_profile
5.创建myid
分别在node5 node6 node7的dataDir目录中创建一个myid的文件,文件内容分别为1,2,3(即server的id)
Node 5:
$ vim /opt/zookeeper/myid
#写入
1 Node 6:
$ vim /opt/zookeeper/myid
#写入
2 Node 7:
$ vim /opt/zookeeper/myid
#写入
3
6.启动zookeeper
$ cd /usr/local/zookeeper
$ bin/zkServer.sh start
# 显示:Starting zookeeper ... STARTED 表示启动成功
二、免密码登录
node5 node8 两台NameNode相互做免密码登录,在上一文中已经在node5上做了免密码登录,下面只在Node8上做node5的免密码登录:
Node8:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ scp ~/.ssh/id_dsa.pub root@node5:/opt
Node5:
$ cat /opt/id_dsa.pub >> ~/.ssh/authorized_keys
完成以后,测试一下 node8 $: ssh node5
三、配置HDFS 高可用
1.配置HDFS配置文件
$ cd /usr/local/hadoop-2.5.1/etc/hadoop
$ vi hdfs-site.xml
#写入
<configuration>
#配置NameService 名字随便起
<property>
<name>dfs.nameservices</name>
<value>raphael</value>
</property>
# 这里的最后一个名字就是上面的nameService value是两台NameNode的节点
<property>
<name>dfs.ha.namenodes.raphael</name>
<value>node5,node8</value>
</property>
# node5和node8的rpc地址
<property>
<name>dfs.namenode.rpc-address.raphael.node5</name>
<value>node5:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.raphael.node8</name>
<value>node8:8020</value>
</property>
# node5和node8的http地址
<property>
<name>dfs.namenode.http-address.raphael.node5</name>
<value>node5:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.raphael.node8</name>
<value>node8:50070</value>
</property>
# 3台JournalNode地址,后台跟名字,但后面的名字不能与nameService相同
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node6:8485;node7:8485;node8:8485/raphael5200</value>
</property>
#配置客户端调用接口
<property>
<name>dfs.client.failover.proxy.provider.raphael</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
#配置journalnode目录
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journalnode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
$ vi core-site.xml
#这里的value就是NameService的名字
<property>
<name>fs.defaultFS</name>
<value>hdfs://raphael</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
#3台zookeeper节点
<property>
<name>ha.zookeeper.quorum</name>
<value>node5:2181,node6:2181,node7:2181</value>
</property>
a.删除node5 node6 node7 node8 etc/hadoop/masters文件(这里已经不需要standry了)
b.删除node5 node6 node7 node8 上的hadoop.tmp.dir 目录
$ rm -rf /opt/hadoop
c.将node5 配置好的文件,覆盖到node6 node7 node8
$ scp -r etc/hadoop/* root@node6:/usr/local/hadoop/etc/hadoop
$ scp -r etc/hadoop/* root@node7:/usr/local/hadoop/etc/hadoop
$ scp -r etc/hadoop/* root@node8:/usr/local/hadoop/etc/hadoop
2.覆盖并启动
a.启动三台JournalNode node6 node7 node8
# 前提是要先把zookeeper启动起来
$ sbin/hadoop-daemon.sh start journalnode
b.在其中一个NameNode上格式化hadoop.tmp.dir 并初始化
Node5:
$ bin/hdfs namenode -format
c.把格式化后的元数据拷备到另一台NameNode节点上
$ scp -r /opt/hadoop root@node8:/opt/hadoop
d.启动NameNode
Node5:
$ sbin/hadoop-daemon.sh start namenode Node8:
$ bin/hdfs namenode -bootstrapStandby
$ sbin/hadoop-daemon.sh start namenode
e.初始化zkfc
Node5:
$ bin/hdfs zkfc -formatZK
f.全面停止并全面启动
Node5:
$ bin/stop-dfs.sh
$ bin/start-dfs.sh
注:在启动JournalNode和其他项时,没有其他好的方法较验是否启动成功,只能查看日志文件,如果日志文件没有报错,则表示启动成功;
3.访问NameNode
访问两台NameNode node5和node8的50070端口,会显示一个端口是Active 另一个端口是Standby 如下图:
http://node5:50070 http://node8:50070

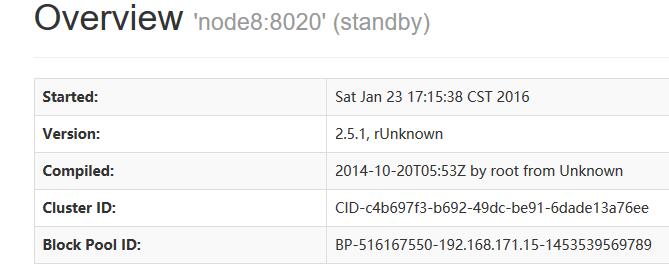
注:如果Node5突然挂掉了,那么node8备用的NameNode会自动的补上,替换为Active,测试方法:Kill node5 的nameNode进程,然后再刷新Node8:
$ jps #ps是显示当前系统进程 ,jps就是显示当前系统的java 进程
$ kill -9 进程ID #杀掉进程
四、使用Yarn来调度HDFS
#先所有的Hadoop相关进程
$ stop-dfs.sh
1.配置yarn-site.xml
$ cd /usr/local/hadoop/
$ vim etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
# 该cluster-id不能与nameService相同
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>raphael521</value>
</property>
#指定2台Resource Manager (即Name Node )节点
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node5</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node8</value>
</property>
#指定zookeeper 节点
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node6:2181,node7:2181,node8:2181</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2.配置etc/hadoop/mapred-site.xml
$ vim etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.将mapred-site.xml yarn-site.xml 覆盖到其他的节点上
4.启动 yarn
#单独启动yarn使用命令:
$ sbin/start-yarn.sh
$ sbin/stop-yarn.sh
#启动所有Hadoop相关进程使用命令
$ start-all.sh
#启动完成以后,另一台NameNode需要手动启动yarn
$ start-yarn.sh
5.访问
访问yarn的端口 http://node5:8088 http://node8:8088 可以看到:
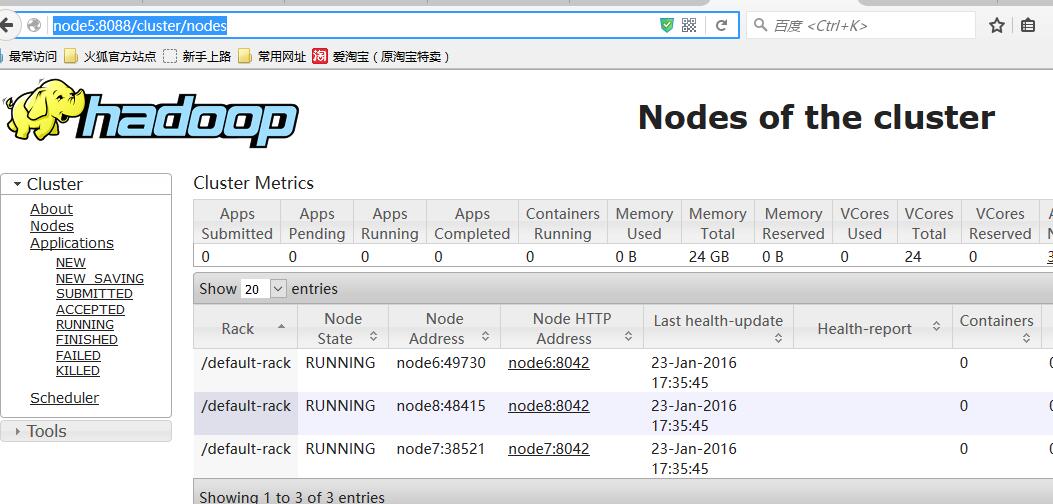

说明:当访问Node5的时候能够正常的显示界面,并且在Nodes下还能加载出集群的所有节点,但是访问node8的时候,则不会显示,而是提示页面将跳到Active的Resource Manager (RM)节点上,然后页面就跳了;
当node5突然挂掉了,zookeeper会立刻将RM切换到node8上,将node8做为Active的RM,然后在Nodes下会在几十秒内加载出所有节点;
hadoop 环境搭建的更多相关文章
- 【转】RHadoop实践系列之一:Hadoop环境搭建
RHadoop实践系列之一:Hadoop环境搭建 RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析.Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- eclipse工具下hadoop环境搭建
eclipse工具下hadoop环境搭建: window10操作系统中搭建eclipse64开发系统,配置hadoop的eclipse插件,让eclipse可以查看Hdfs中的文件内容. ...
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- Hadoop环境搭建、启动和管理界面查看
一.hadoop环境搭建: 1. hadoop 6个核心配置文件的作用:core-site.xml:核心配置文件,主要定义了我们文件访问的格式 hdfs://hadoop-env.sh:主要配置我们的 ...
- Ubuntu中Hadoop环境搭建
Ubuntu中Hadoop环境搭建 JDK安装 方法一:通过命令行直接安装(不建议) 有两种java可以安装oracle-java8-installer以及openjdk (1)安装oracle-ja ...
- Linux集群搭建与Hadoop环境搭建
今天是8月19日,距离开学还有15天,假期作业完成还是遥遥无期,看来开学之前的恶补是躲不过了 今天总结一下在Linux环境下安装Hadoop的过程,首先是对Linux环境的配置,设置主机名称,网络设置 ...
- 转 史上最详细的Hadoop环境搭建
GitChat 作者:鸣宇淳 原文:史上最详细的Hadoop环境搭建 关注公众号:GitChat 技术杂谈,一本正经的讲技术 [不要错过文末活动哦] 前言 Hadoop在大数据技术体系中的地位至关重要 ...
- Hadoop环境搭建(centos)
Hadoop环境搭建(centos) 本平台密码83953588abc 配置Java环境 下载JDK(本实验从/cgsrc 文件中复制到指定目录) mkdir /usr/local/java cp / ...
- 分享一些Hadoop环境搭建所用到的软件
本来想用土的掉渣的语言说说hadoop配置的,因为最近总有人问我,环境搭建老出莫名其妙的问题,可是写到一半,还是决定不写了,网上教程好多好多,而大家遇到问题有很多是软件版本不对应造成的,因此我就把大家 ...
随机推荐
- 深入理解 CSS变形 transform(3d)
坐标轴 在了解透视之前,首先要先了解坐标轴.3D变形与2D变形最大的不同就在于其参考的坐标轴不同.2D变形的坐标轴是平面的,只存在x轴和y轴,而3D变形的坐标轴则是x.y.z三条轴组成的立体空间,x轴 ...
- 刚接触js感觉好吃力啊
我是一个新手,最近刚刚开始学习js这门语言,感觉好难,有一种无从下手的感觉,不知道应该从哪里学习,虽然也看了很多的书,但是对于一个没有计算机基础的人来说,真的是一种煎熬,每一个名词都要去查.万事开头难 ...
- Javascipt 时间格式化(日期)
Date.prototype.format =function(format){ var o = { "M+" : this.getMonth()+1, //month " ...
- wildfly部署solr.war
1.添加solr/home配置,有两种途径: 一个是修改solr.war包的web.xml,路径如下:solr-4.7.2.rar\WEB-INF\web.xml,添加如下内容:
- PHP对表单提交特殊字符的过滤和处理
PHP关于表单提交特殊字符的处理方法做个汇总,主要涉及htmlspecialchars/addslashes/stripslashes/strip_tags/mysql_real_escape_str ...
- java.io.FileNotFoundException: class path resource [META-INF/xfire/services.xml] cannot be opened because it does not exist
解决办法: maven创建项目时: META-INF目录下面新建一个xfire文件夹,把services.xml文件放到这个文件夹里,再将整个META-INF拷贝到WEB-INF中 clean一下工程 ...
- Core Data 学习简单整理01
Core Data是苹果针对Mac和iOS平台开发的一个框架, 通过CoreData可以在本地生成数据库sqlite,提供了ORM的功能,将对象和数据模型相互转换 . 通过Core Data管理和操作 ...
- Xaml 页面布局学习
对于一开始设计xaml界面的初学者,总是习惯性的拖拽控件进行布局,这样也许方便.简单.快捷,但偶尔会出现一些小错误, 当需要将控件进行很细微的挪动时也比较吃力. 这里,我个人建议用一些代码将xaml界 ...
- 手写总结:synchronized 和 lock 区别
1. synchronized 是jvm 层次的(可以会造成死锁), lock 可以写代码控制,一般在异常时在 finally 里可以 unlock 释放锁 2. lock 细度更细,synchro ...
- css与div小结
前些时间学习css与div的课程 什么是css呢 Css 级联样式表或层叠样式表(Cascading Style Sheet) 是能够真正做到 网页表现与内容分离的一种样式设计语言.相对于传统HTML ...