Spark Streaming连接TCP Socket
1.Spark Streaming是什么
Spark Streaming是在Spark上建立的可扩展的高吞吐量实时处理流数据的框架,数据可以是来自多种不同的源,例如kafka,Flume,Twitter,ZeroMQ或者TCP Socket等。在这个框架下,支持对流数据的各种运算,比如map,reduce,join等。处理过后的数据可以存储到文件系统或数据库。
利用Spark Streaming,你可以使用与批量加载数据相同的API来创建数据管道,并通过数据管道处理流式数据。此外,Spark Steaming的“micro-batching”方式提供相当好的弹性来应对某些原因造成的任务失败。
2. Spark Streaming的基本原理
Spark Streaming对数据的处理方式主要采用的方法是对Stream数据进行时间切片,分成小的数据片段,通过类似批处理的方式处理数据片段。
Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。
Spark Streaming将流式计算分解成一系列短小的批处理作业。Spark Streaming的输入数据分成一段一段的数据(DStreaming),每一段数据都转换成Spark中的RDD,然后将Spark Streaming中对DStream的操作变为针对Spark中对RDD的操作,将RDD经过操作变成中间结果保存在内存中。
3. DStream
上面提到了DStreaming,那么DStreaming到底是什么呢:
DStreaming相当于在Streaming的框架下对RDD进行封装,表示的是我们处理的一个实时数据流。类似于RDD,DStream提供了转换操作,窗口转换操作和输出操作三种操作方法。
4.Spark Streaming的优势
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
实时性:它能运行在100+的结点上,并达到秒级延迟。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark的任务集的调度过程。其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足除对实时性要求非常高的所有流式准实时计算场景。
高效和容错的特性:对于流式计算来说,容错性至关重要。在spark中每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作,只要输入数据是可容错的,那么任意一个RDD的分区出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。而spark Streaming使用基于内存的Spark作为执行引擎, 其容错性自然很好。
吞吐量:Spark Streaming能集成Spark的批处理和交互查询,其吞吐量比Storm至少高2~5倍。并且它为实现复杂的算法提供了和批处理类似的简单接口。
接下来用Spark Streaming连接TCP Socket来说明如何使用Spark Streaming:
1 创建StreamingContext对象
首先使用StreamingContext模块,这个模块的作用是提供所有的流数据处理的功能:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext sc = SparkContext("local[2]", "streamwordcount")
# 创建本地的SparkContext对象,包含2个执行线程 ssc = StreamingContext(sc, 2)
# 创建本地的StreamingContext对象,处理的时间片间隔时间,设置为2s
2 创建DStream对象
我们需要连接一个打开的 TCP 服务端口,从而获取流数据,这里使用的源是TCP Socket,所以使用socketTextStream()函数:
lines = ssc.socketTextStream("localhost", 8888)
# 创建DStream,指明数据源为socket:来自localhost本机的8888端口
3 对DStream进行操作
我们开始对lines进行处理,首先对当前2秒内获取的数据进行分割并执行标准的MapReduce流程计算。
words = lines.flatMap(lambda line: line.split(" "))
# 使用flatMap和Split对2秒内收到的字符串进行分割
得到的words是一系列的单词,再执行下面的操作:
pairs = words.map(lambda word: (word, 1))
# map操作将独立的单词映射到(word,1)元组 wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# reduceByKey操作对pairs执行reduce操作获得(单词,词频)元组
5 输出数据
将处理后的数据输出到一个文件中:
outputFile = "/home/feige/streaming/ss"
# 输出文件夹的前缀,Spark Streaming会自动使用当前时间戳来生成不同的文件夹名称 wordCounts.saveAsTextFiles(outputFile)
# 将结果输出
6 启动应用
要使程序在Spark Streaming上运行起来,需要执行Spark Streaming启动的流程,调用start()函数启动,awaitTermination()函数等待处理结束的信号。
ssc.start()
# 启动Spark Streaming应用
ssc.awaitTermination()
打开终端执行:
nc -lk 8888
nc的-l参数表示创建一个监听端口,等待新的连接。-k参数表示当前连接结束后仍然保持监听,必须与-l参数同时使用。
执行完上面的命令后不关闭终端,我们将在这个终端中输入一些处理的数据:

打开一个新的终端来执行我们的Spark Streaming应用:

这里是spark streaming执行的过程
现在我们来看看程序执行的效果,程序每隔2秒扫描一次监控窗口输入的内容,我们查看一下:
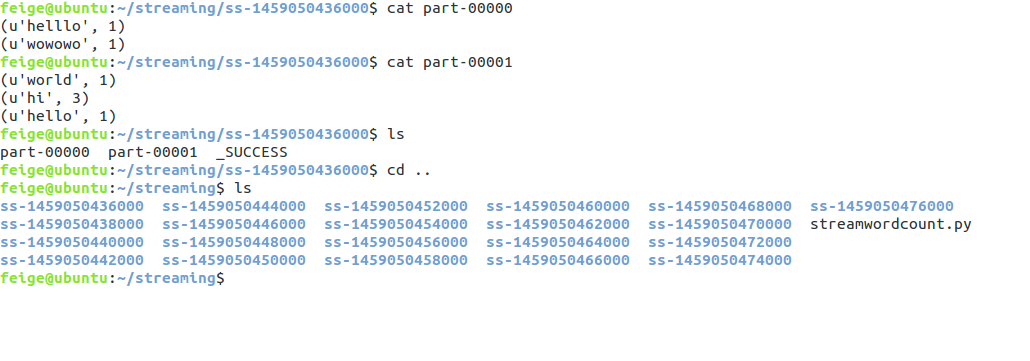
结束语:
最近压力比较大,琐事诸多,相信这段时间过后一切都会好起来的,加油!!!
Spark Streaming连接TCP Socket的更多相关文章
- 2、 Spark Streaming方式从socket中获取数据进行简单单词统计
Spark 1.5.2 Spark Streaming 学习笔记和编程练习 Overview 概述 Spark Streaming is an extension of the core Spark ...
- Spark Streaming连接Kafka的两种方式 direct 跟receiver 方式接收数据的区别
Receiver是使用Kafka的高层次Consumer API来实现的. Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark Streaming 002 统计单词的例子
1.准备 事先在hdfs上创建两个目录: 保存上传数据的目录:hdfs://alamps:9000/library/SparkStreaming/data checkpoint的目录:hdfs://a ...
- .Spark Streaming(上)--实时流计算Spark Streaming原理介
Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍 http://www.cnblogs.com/shishanyuan/p/474 ...
- spark streaming的理解和应用
1.Spark Streaming简介 官方网站解释:http://spark.apache.org/docs/latest/streaming-programming-guide.html 该博客转 ...
- 实时流计算Spark Streaming原理介绍
1.Spark Streaming简介 1.1 概述 Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的.具备容错机制的实时流数据的处理.支持从多种数据源获取数据,包 ...
- Spark Streaming之一:整体介绍
提到Spark Streaming,我们不得不说一下BDAS(Berkeley Data Analytics Stack),这个伯克利大学提出的关于数据分析的软件栈.从它的视角来看,目前的大数据处理可 ...
- Update(Stage4):Spark Streaming原理_运行过程_高级特性
Spark Streaming 导读 介绍 入门 原理 操作 Table of Contents 1. Spark Streaming 介绍 2. Spark Streaming 入门 2. 原理 3 ...
随机推荐
- nginx 1.4.7 发送日志到rsyslog
<pre name="code" class="html">tar -xzf nginx-1.4.7.tar.gz # cd nginx-1.4.7 ...
- cocos2dx 字体
有些时候需要在界面上显示些文字,自然涉及到字体的问题 显示文字使用CCLabelTTF即可,创建方法是 CCLabelTTF(const char* text, const char* font, i ...
- 《windows程序设计》学习_2.2:初识消息,双键的使用
/* 双键的使用 */ #include <windows.h> LRESULT CALLBACK WndProc(HWND,UINT,WPARAM,LPARAM); int WINAPI ...
- NYOJ 14 会场安排问题(也算是经典问题了)
会场安排问题 时间限制:3000 ms | 内存限制:65535 KB 难度:4 描述 学校的小礼堂每天都会有许多活动,有时间这些活动的计划时间会发生冲突,需要选择出一些活动进行举办.小刘的工作就 ...
- BZOJ 2252: [2010Beijing wc]矩阵距离
题目 2252: [2010Beijing wc]矩阵距离 Time Limit: 10 Sec Memory Limit: 256 MB Description 假设我们有矩阵,其元素值非零即1 ...
- java concurrent之前戏synchronized
对于多线程共享资源的情况须要进行同步,以避免一个线程的修改被还有一个线程的修改所覆盖. 最普遍的同步方式就是synchronized. 把代码声明为synchronized.有两个重要后果,一般是指该 ...
- Android学习路线(二十)运用Fragment构建动态UI
要在Android系统上创建一个动态或者多面板的用户界面,你须要将UI组件以及activity行为封装成模块.让它可以在你的activity中灵活地切换显示与隐藏. 你可以使用Fragment类来创建 ...
- docker基础入门之一
一.概述 1.传统虚拟化技术: 纯软件的虚拟化是通过对于硬件层的模拟从而实现允许运行多个操作系统: 硬件辅助虚拟化需要硬件层面对于虚拟化的支持,类似Intel-VT技术等,具有更高的运行效率: 解决方 ...
- Java中Iterator(迭代器)的用法及其背后机制的探究
在Java中遍历List时会用到Java提供的Iterator,Iterator十分好用,原因是: 迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结 ...
- String VS Cstring(字符串)
#include<string> 与 #include<string.h> 这是两个完全不同的头文件,前者用于C++,后者用于C,一般把这两个头文件都包括进去. 越来越觉得需要 ...