Python即时网络爬虫:API说明

API说明——下载gsExtractor内容提取器
1,接口名称
下载内容提取器
2,接口说明
如果您想编写一个网络爬虫程序,您会发现大部分时间耗费在调测网页内容提取规则上,不讲正则表达式的语法如何怪异,即便使用XPath,您也得逐个编写和调试。
如果要从一个网页上提取很多字段,逐个调试XPath将是十分耗时的。通过这个接口,你可以直接获得一个调测好的提取器脚本程序,是标准的XSLT程序,您只需针对目标网页的DOM运行它,就能获得XML格式的结果,所有字段一次性获得。
这个XSLT提取器可以是您用MS谋数台生成的,也可以是其他人共享给您的,只要您有读权限,皆可下载使用。
用于数据分析和数据挖掘的网络爬虫程序中,内容提取器是影响通用性的关键障碍,如果这个提取器是从API获得的,您的网络爬虫程序就能写成通用的框架。请参看GooSeeker的开源Python网络爬虫项目(访问网址: )。
)。
3,接口规范
3.1,接口地址(URL)
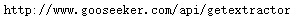
3.2,请求类型(contentType)
不限
3.3,请求方法
HTTP GET
3.4,请求参数
key 必选:Yes;类型:String;说明:申请API时分配的AppKey
theme 必选:Yes;类型:String;说明:提取器名,就是用MS谋数台定义的规则名
middle 必选:No;类型:String;说明:规则编号,如果相同规则名下定义了多个规则,需填写
bname 必选:No;类型:String;说明:整理箱名,如果规则含有多个整理箱,需填写
注释:请参看GooSeeker网络爬虫术语解释:集搜客GooSeeker专有名词解释(访问网址: )
)
3.5,返回类型(contentType)
text/xml; charset=UTF-8
3.6,返回参数
HTTP消息头中的参数,如下:
more-extractor 类型:String;说明:相同规则名下有多少个提取器。通常只在可选参数没有填写的时候需要关注这个参数,用以提示客户端有多个规则和整理箱,客户端自己决定是否要在发送请求时携带明确的参数
3.7,返回错误信息
消息层错误以HTTP 400返回,比如,URL中的参数不符合本规范
应用层错误以HTTP 200 OK返回,具体错误码用XML文件放在消息体中,XML结构如下:
<return>
<code>具体的错误码</code>
</return>
具体的code值如下:
keyError:权限验证失败
paramError:URL中传来的参数有误,比如,参数名称或值不正确
empty:非错误状态,而是请求的提取器是不存在的,比如,某个抓取规则并没有创建整理箱,则返回empty
4,用法范例(python语言)
提取器名获取参考 1分钟快速生成用于网页内容提取的xslt
示例代码:
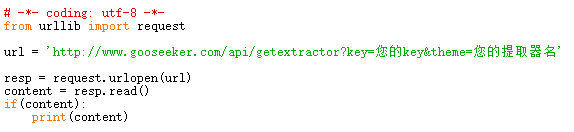
接下来我会对此API进行测试,将案例发布出来。
5,相关文档
6,集搜客GooSeeker开源代码下载源
1, GooSeeker开源Python网络爬虫GitHub源
7,文档修改历史
1,2016-06-23:V1.0
Python即时网络爬虫:API说明的更多相关文章
- Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景 在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端 ...
- Python即时网络爬虫项目: 内容提取器的定义
1. 项目背景 在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作 ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- Python 3网络爬虫开发实战》中文PDF+源代码+书籍软件包
Python 3网络爬虫开发实战>中文PDF+源代码+书籍软件包 下载:正在上传请稍后... 本书书籍软件包为本人原创,在这个时间就是金钱的时代,有些软件下起来是很麻烦的,真的可以为你们节省很多 ...
- Python 3网络爬虫开发实战中文 书籍软件包(原创)
Python 3网络爬虫开发实战中文 书籍软件包(原创) 本书书籍软件包为本人原创,想学爬虫的朋友你们的福利来了.软件包包含了该书籍所需的所有软件. 因为软件导致这个文件比较大,所以百度网盘没有加速的 ...
- Python 3网络爬虫开发实战中文PDF+源代码+书籍软件包(免费赠送)+崔庆才
Python 3网络爬虫开发实战中文PDF+源代码+书籍软件包+崔庆才 下载: 链接:https://pan.baidu.com/s/1H-VrvrT7wE9-CW2Dy2p0qA 提取码:35go ...
- 《Python 3网络爬虫开发实战中文》超清PDF+源代码+书籍软件包
<Python 3网络爬虫开发实战中文>PDF+源代码+书籍软件包 下载: 链接:https://pan.baidu.com/s/18yqCr7i9x_vTazuMPzL23Q 提取码:i ...
随机推荐
- jQuery中$符号冲突问题 (转载)
Jquery的$命名冲突: 在Jquery中,$是JQuery的别名,所有使用$的地方也都可以使用JQuery来替换,如$('#msg')等同于JQuery('#msg') 的写法.然而,当我们引入多 ...
- android R 文件 丢失的处理 如何重新生成
很多时候我们会遇到工程中的R.java文件丢失,必要急,修复很简单. 方法:右击你的工程(项目)——>Android Tools——>Fix Project Properties 即可. ...
- BZOJ 1062 糖果雨
http://www.lydsy.com/JudgeOnline/problem.php?id=1062 思路:找到平行四边形以后,变换坐标:y->y-kx,k为斜率,这样变成了矩形,然后只要二 ...
- C语言的本质(34)——静态库
库是一种软件组件技术,库里面封装了数据和函数. 库的使用可以使程序模块化. Windows系统包括静态链接库(.lib文件)和动态链接库(.dll文件). Linux通常把库文件存放在/usr/lib ...
- 基于spark的plsa实现
PLSA.py # coding:utf8 from pyspark import SparkContext from pyspark import RDD import numpy as np fr ...
- ntp服务器池列表
CentOS: 0.centos.pool.ntp.org 1.centos.pool.ntp.org 2.centos.pool.ntp.org 国内可用的 ntp.fudan.edu.cn 复旦 ...
- Python 自动化脚本学习(三)
函数 例子 def hello(): print("hello" + "world"); 有参数的函数 def hello(name): print(" ...
- IOS 下雪动画
#define SNOW_IMAGENAME @"snow" #define IMAGE_X arc4random()%(int)Main_Screen_Width #define ...
- FP-Growth算法之频繁项集的挖掘(python)
前言: 关于 FP-Growth 算法介绍请见:FP-Growth算法的介绍. 本文主要介绍从 FP-tree 中提取频繁项集的算法.关于伪代码请查看上面的文章. FP-tree 的构造请见:FP-G ...
- AJAX最简单的原理以及应用
Ajax是创建快速动态网页的技术,通过后台与服务器少量的数据交互,是网页实现异步更新.也就是在不整个刷新页面的情况下,可以更新网页中的局部区域. 在原始web应用的模式中: 浏览器 以 h ...