TensorFlow深度学习笔记 文本与序列的深度模型
Deep Models for Text and Sequence
转载请注明作者:梦里风林
Github工程地址:https://github.com/ahangchen/GDLnotes
欢迎star,有问题可以到Issue区讨论
官方教程地址
视频/字幕下载
Rare Event
与其他机器学习不同,在文本分析里,陌生的东西(rare event)往往是最重要的,而最常见的东西往往是最不重要的。
语法多义性
- 一个东西可能有多个名字,对这种related文本能够做参数共享是最好的
- 需要识别单词,还要识别其关系,就需要过量label数据
无监督学习
- 不用label进行训练,训练文本是非常多的,关键是要找到训练的内容
- 遵循这样一个思想:相似的词汇出现在相似的场景中
- 不需要知道一个词真实的含义,词的含义由它所处的历史环境决定
Embeddings
- 将单词映射到一个向量(Word2Vec),越相似的单词的向量会越接近
- 新的词可以由语境得到共享参数
Word2Vec
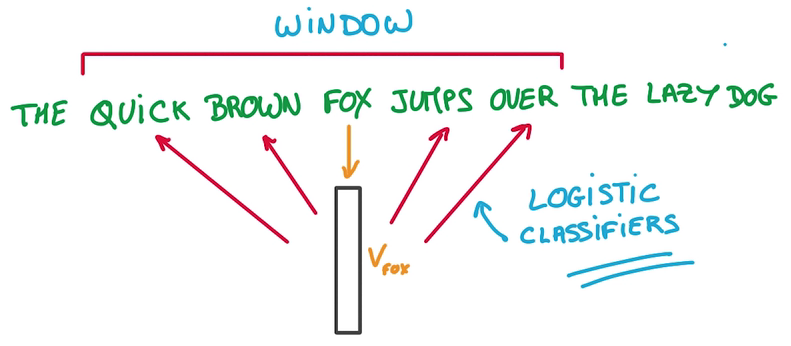
- 将每个词映射到一个Vector列表(就是一个Embeddings)里,一开始随机,用这个Embedding进行预测
- Context即Vector列表里的邻居
- 目标是让Window里相近的词放在相邻的位置,即预测一个词的邻居
用来预测这些相邻位置单词的模型只是一个Logistics Regression, just a simple Linear model
Comparing embeddings
比较两个vector之间的夹角大小来判断接近程度,用cos值而非L2计算,因为vector的长度和分类是不相关的:
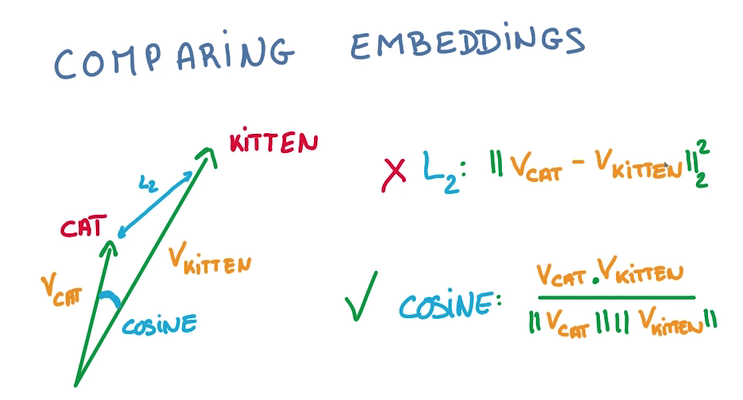
- 最好将要计算的vector都归一化
Predict Words
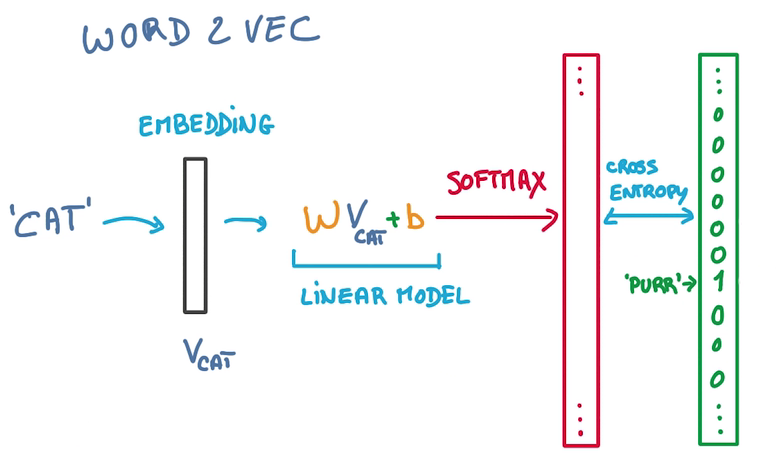
- 单词经过embedding变成一个vector
- 然后输入一个WX+b,做一个线性模型
- 输出的label概率为输入文本中的词汇
- 问题在于WX+b输出时,label太多了,计算这种softmax很低效
- 解决方法是,筛掉不可能是目标的label,只计算某个label在某个局部的概率,sample softmax
t-SNE
- 查看某个词在embedding里的最近邻居可以看到单词间的语义接近关系
- 将vector构成的空间降维,可以更高效地查找最近单词,但降维过程中要保持邻居关系(原来接近的降维后还要接近)
- t-SNE就是这样一种有效的方法
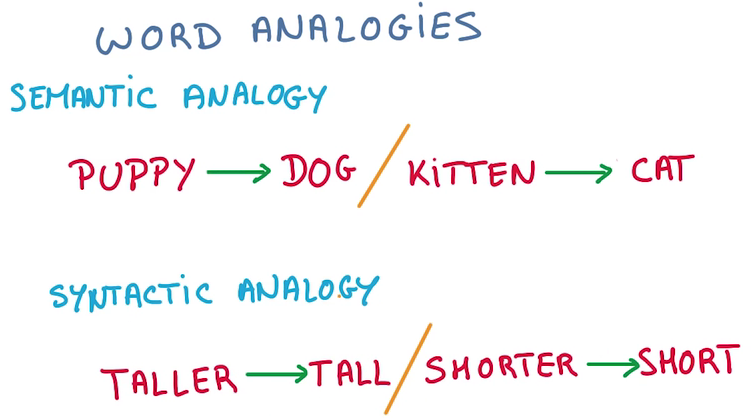
类比
- 实际上我们能得到的不仅是单词的邻接关系,由于将单词向量化,可以对单词进行计算
- 可以通过计算进行语义加减,语法加减

Sequence
文本(Text)是单词(word)的序列,一个关键特点是长度可变,就不能直接变为vector
CNN and RNN
CNN 在空间上共享参数,RNN在时间上(顺序上)共享参数
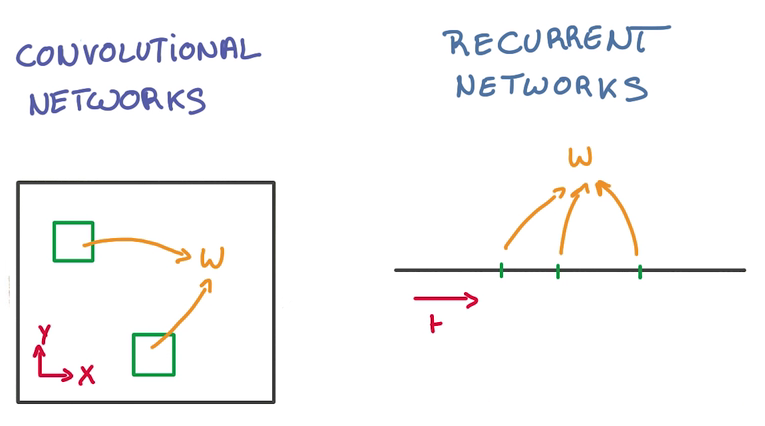
- 在每轮训练中,需要判断至今为之发生了什么,过去输入的所有数据都对当下的分类造成影响
- 一种思路是记忆之前的分类器的状态,在这个基础上训练新的分类器,从而结合历史影响
- 这样需要大量历史分类器
- 重用分类器,只用一个分类器总结状态,其他分类器接受对应时间的训练,然后传递状态
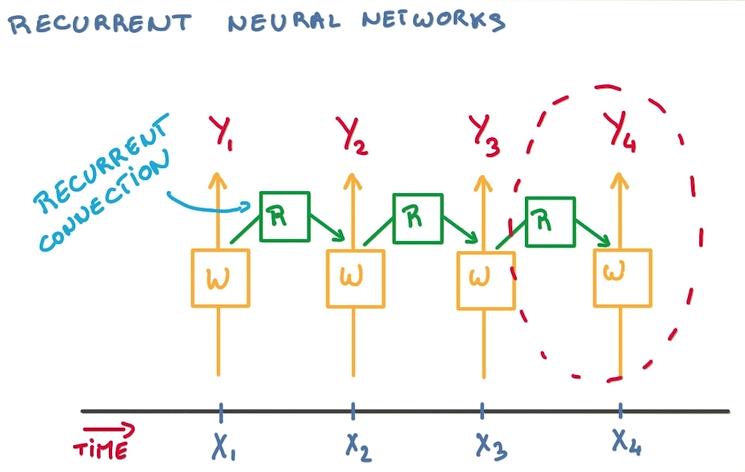
RNN Derivatives
- BackPropagation Through time
- 对同一个weight参数,会有许多求导操作同时更新之
- 对SGD不友好,因为SGD是用许多不相关的求导更新参数,以保证训练的稳定性
- 由于梯度之间的相关性,导致梯度爆炸或者梯度消失
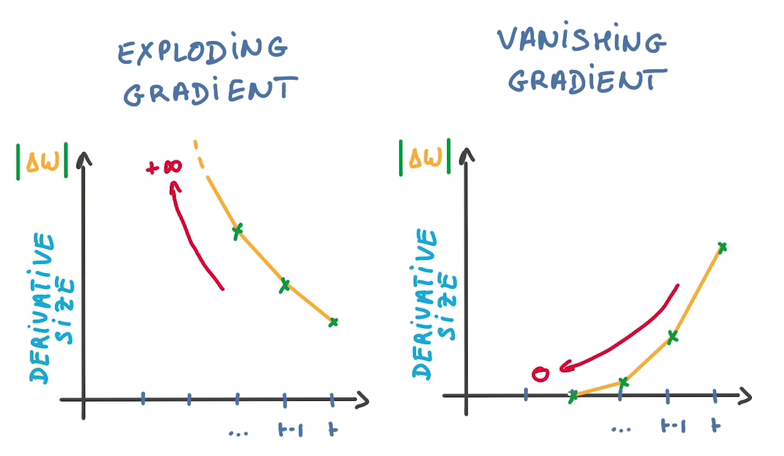
- 使得训练时找不到优化方向,训练失败
Clip Gradient
计算到梯度爆炸的时候,使用一个比值来代替△W(梯度是回流计算的,横坐标从右往左看)
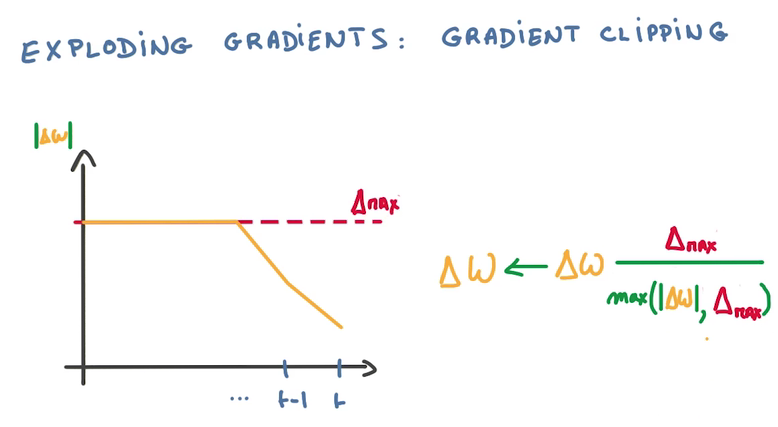
- Hack but cheap and effective
LSTM(Long Short-Term Memory)
梯度消失会导致分类器只对最近的消息的变化有反应,淡化以前训练的参数,也不能用比值的方法来解决
- 一个RNN的model包含两个输入,一个是过去状态,一个是新的数据,两个输出,一个是预测,一个是将来状态
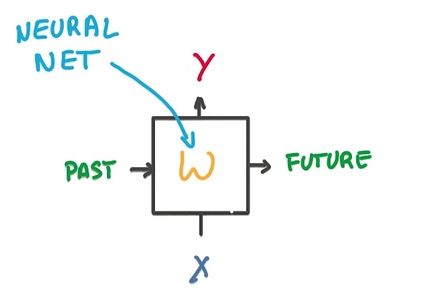
- 中间是一个简单的神经网络
- 将中间的部分换成LSTM-cell就能解决梯度消失问题
- 我们的目的是提高RNN的记忆能力
- Memory Cell

三个门,决定是否写/读/遗忘/写回
- 在每个门上,不单纯做yes/no的判断,而是使用一个权重,决定对输入的接收程度
- 这个权重是一个连续的函数,可以求导,也就可以进行训练,这是LSTM的核心

- 用一个逻辑回归训练这些门,在输出进行归一化
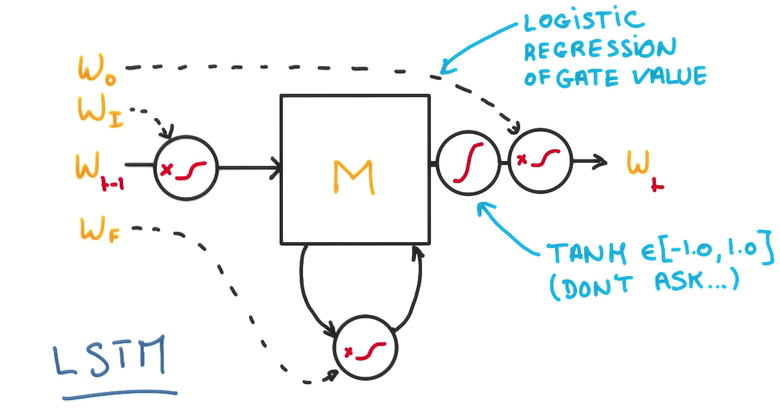
- 这样的模型能让整个cell更好地记忆与遗忘
- 由于整个模型都是线性的,所以可以方便地求导和训练
LSTM Regularization
- L2, works
- Dropout on the input or output of data, works
Beam Search
有了上面的模型之后,我们可以根据上文来推测下文,甚至创造下文,预测,筛选最大概率的词,喂回,继续预测……
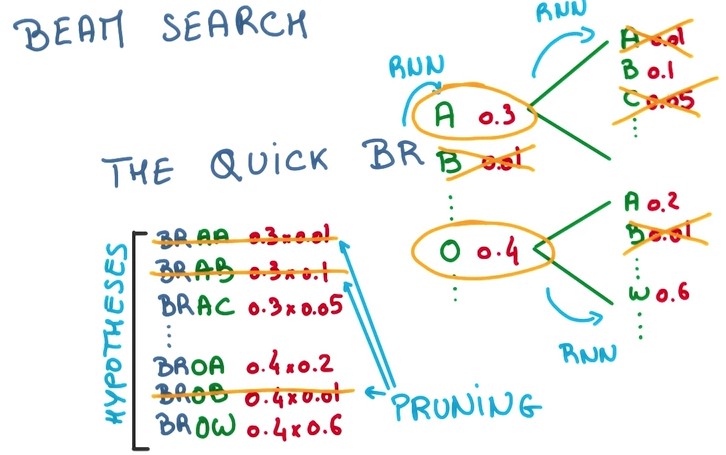
- 我们可以每次只预测一个字母,but this is greedy,每次都挑最好的那个
- 也可以每次多预测几步,然后挑整体概率较高的那个,以减少偶然因素的影响
- 但这样需要生成的sequence会指数增长
- 因此我们在多预测几步的时候,只为概率比较高的几个候选项做预测,that's beam search.
翻译与识图
RNN将variable length sequence问题变成了fixed length vector问题,同时因为实际上我们能利用vector进行预测,我们也可以将vector变成sequence
- 我们可以利用这一点,输入一个序列,到一个RNN里,将输出输入到另一个逆RNN序列,形成另一种序列,比如,语言翻译
如果我们将CNN的输出接到一个RNN,就可以做一种识图系统
循环神经网络实践
觉得我的文章对您有帮助的话,给个star可好?
TensorFlow深度学习笔记 文本与序列的深度模型的更多相关文章
- 2.keras实现-->深度学习用于文本和序列
1.将文本数据预处理为有用的数据表示 将文本分割成单词(token),并将每一个单词转换为一个向量 将文本分割成单字符(token),并将每一个字符转换为一个向量 提取单词或字符的n-gram(tok ...
- TensorFlow 深度学习笔记 从线性分类器到深度神经网络
转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有问题可以到Issue区讨论 官方教程地址 视频/字幕下载 L ...
- TensorFlow文本与序列的深度模型
TensorFlow深度学习笔记 文本与序列的深度模型 Deep Models for Text and Sequence 转载请注明作者:梦里风林Github工程地址:https://github. ...
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- Google TensorFlow深度学习笔记
Google Deep Learning Notes Google 深度学习笔记 由于谷歌机器学习教程更新太慢,所以一边学习Deep Learning教程,经常总结是个好习惯,笔记目录奉上. Gith ...
- 【AI in 美团】深度学习在文本领域的应用
背景 近几年以深度学习技术为核心的人工智能得到广泛的关注,无论是学术界还是工业界,它们都把深度学习作为研究应用的焦点.而深度学习技术突飞猛进的发展离不开海量数据的积累.计算能力的提升和算法模型的改进. ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- AI:深度学习用于文本处理
同本文一起发布的另外一篇文章中,提到了 BlueDot 公司,这个公司致力于利用人工智能保护全球人民免受传染病的侵害,在本次疫情还没有引起强烈关注时,就提前一周发出预警,一周的时间,多么宝贵! 他们的 ...
- python学习笔记(一)元组,序列,字典
python学习笔记(一)元组,序列,字典
随机推荐
- Mysql MERGE 引擎在分表环境下得使用
应用场景:当我们在做分表的时候,通常会把一个大表的数据拆分成若干个分表,这也是数据库优化中的分表概念.随着分表随之而来的问题就是多表查询. 现在有 t1,t2 两张数据表,需要满足不同的查询条件同时从 ...
- postgresql创建用户
(1)内部命令create user 用户名 with superuser password '密码'; 先进入数据库后用命令\h create user 查看帮助 ...
- Delphi线程同步(临界区、互斥、信号量,包括详细代码)
当有多个线程的时候,经常需要去同步这些线程以访问同一个数据或资源. 例如,假设有一个程序,其中一个线程用于把文件读到内存,而另一个线程用于统计文件的字符数.当然,在整个文件调入内存之前,统计它的计数是 ...
- C# ReferenceEquals(), static Equals(), instance Equals(), 和运算行符==之间的关系
C#充许你同时创建值类型和引用类型.两个引用类型的变量在引用同一个对象时,它们是相等的,就像引用到对象的ID一样.两个值类型的变量在它们的类型和内容都是相同时,它们应该是相等的.这就是为什么相等测试要 ...
- cf479C Exams
C. Exams time limit per test 1 second memory limit per test 256 megabytes input standard input outpu ...
- Remove Duplicates from Sorted Array 解答
Question Given a sorted array, remove the duplicates in place such that each element appear only onc ...
- HDU1242 Rescue(BFS+优先队列)
Rescue Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Subm ...
- 【转】C++实现RTMP协议发送H.264编码及AAC编码的音视频
RTMP(Real Time Messaging Protocol)是专门用来传输音视频数据的流媒体协议,最初由Macromedia 公司创建,后来归Adobe公司所有,是一种私有协议,主要用来联系F ...
- 解决 VM虚拟机网卡无法拉起 的问题
复制虚拟机后,第二块网卡始终无法正常运作,表现为无法自动获得dhcp地址,且重启后与第一块网卡使用同样的地址,让人苦笑不得,反复重启了很多次都是这样,后面想到ifcfg-eth1的配置文件可能写得太简 ...
- 【沙茶了+筛选保存最大质因数】【HDU2136】Largest prime factor
Largest prime factor Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Oth ...