领域驱动设计系列(2)浅析VO、DTO、DO、PO的概念、区别和用处
PO:
persistant object持久对象
最形象的理解就是一个PO就是数据库中的一条记录。
好处是可以把一条记录作为一个对象处理,可以方便的转为其它对象。
BO:
business object业务对象
主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。
比如一个简历,有教育经历、工作经历、社会关系等等。
我们可以把教育经历对应一个PO,工作经历对应一个PO,社会关系对应一个PO。
建立一个对应简历的BO对象处理简历,每个BO包含这些PO。
这样处理业务逻辑时,我们就可以针对BO去处理。
VO :
value object值对象
ViewObject表现层对象
主要对应界面显示的数据对象。对于一个WEB页面,或者SWT、SWING的一个界面,用一个VO对象对应整个界面的值。
DTO :
Data Transfer Object数据传输对象
主要用于远程调用等需要大量传输对象的地方。
比如我们一张表有100个字段,那么对应的PO就有100个属性。
但是我们界面上只要显示10个字段,
客户端用WEB service来获取数据,没有必要把整个PO对象传递到客户端,
这时我们就可以用只有这10个属性的DTO来传递结果到客户端,这样也不会暴露服务端表结构.到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为VO
POJO :
plain ordinary java object 简单java对象
个人感觉POJO是最常见最多变的对象,是一个中间对象,也是我们最常打交道的对象。
一个POJO持久化以后就是PO
直接用它传递、传递过程中就是DTO
直接用来对应表示层就是VO
POJO、PO、DTO、VO都是处理流程中的名字,不是PO对应一个POJO,DTO对应一个POJO,VO对应一个POJO
在有些情况下PO、DTO、VO是指同一个POJO
DAO:
data access object数据访问对象
这个大家最熟悉,和上面几个O区别最大,基本没有互相转化的可能性和必要.
主要用来封装对数据库的访问。通过它可以把POJO持久化为PO,用PO组装出来VO、DTO
总结下我认为一个对象究竟是什么O要看具体环境,在不同的层、不同的应用场合,对象的身份也不一样,而且对象身份的转化也是很自然的。就像你对老婆来说就 是老公,对父母来说就是子女。设计这些概念的初衷不是为了唬人而是为了更好的理解和处理各种逻辑,让大家能更好的去用面向对象的方式处理问题.
大家千万不要陷入过度设计,大可不必为了设计而设计一定要在代码中区分各个对象。一句话技术是为应用服务的。
欢迎指正。
画了个图,感觉没有完全表达出自己的意思。。。。。谁帮忙完善下,最好能体现各个O在MVC中的位置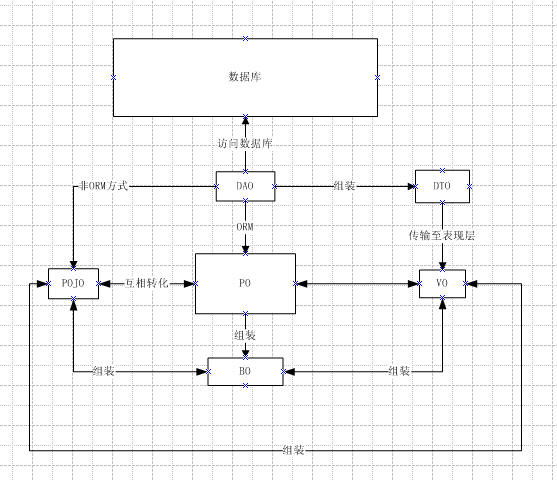
上一篇文章作为一个引子,说明了领域驱动设计的优势,从本篇文章开始,笔者将会结合自己的实际经验,谈及领域驱动设计的应用。本篇文章主要讨论一下我们经常会用到的一些对象:VO、DTO、DO和PO。
由于不同的项目和开发人员有不同的命名习惯,这里我首先对上述的概念进行一个简单描述,名字只是个标识,我们重点关注其概念:
概念:
VO(View Object):视图对象,用于展示层,它的作用是把某个指定页面(或组件)的所有数据封装起来。
DTO(Data Transfer Object):数据传输对象,这个概念来源于J2EE的设计模式,原来的目的是为了EJB的分布式应用提供粗粒度的数据实体,以减少分布式调用的次数,从而提高分布式调用的性能和降低网络负载,但在这里,我泛指用于展示层与服务层之间的数据传输对象。
DO(Domain Object):领域对象,就是从现实世界中抽象出来的有形或无形的业务实体。
PO(Persistent Object):持久化对象,它跟持久层(通常是关系型数据库)的数据结构形成一一对应的映射关系,如果持久层是关系型数据库,那么,数据表中的每个字段(或若干个)就对应PO的一个(或若干个)属性。
模型:
下面以一个时序图建立简单模型来描述上述对象在三层架构应用中的位置:

- 用户发出请求(可能是填写表单),表单的数据在展示层被匹配为VO。
- 展示层把VO转换为服务层对应方法所要求的DTO,传送给服务层。
- 服务层首先根据DTO的数据构造(或重建)一个DO,调用DO的业务方法完成具体业务。
- 服务层把DO转换为持久层对应的PO(可以使用ORM工具,也可以不用),调用持久层的持久化方法,把PO传递给它,完成持久化操作。
- 对于一个逆向操作,如读取数据,也是用类似的方式转换和传递,略。
VO与DTO的区别
大家可能会有个疑问(在笔者参与的项目中,很多程序员也有相同的疑惑):既然DTO是展示层与服务层之间传递数据的对象,为什么还需要一个VO呢?对!对于绝大部分的应用场景来说,DTO和VO的属性值基本是一致的,而且他们通常都是POJO,因此没必要多此一举。但不要忘记这是实现层面的思维,对于设计层面来说,概念上还是应该存在VO和DTO,因为两者有着本质的区别,DTO代表服务层需要接收的数据和返回的数据,而VO代表展示层需要显示的数据。
用一个例子来说明可能会比较容易理解:例如服务层有一个getUser的方法返回一个系统用户,其中有一个属性是gender(性别),对于服务层来说,它只从语义上定义:1-男性,2-女性,0-未指定,而对于展示层来说,它可能需要用“帅哥”代表男性,用“美女”代表女性,用“秘密”代表未指定。说到这里,可能你还会反驳,在服务层直接就返回“帅哥美女”不就行了吗?对于大部分应用来说,这不是问题,但设想一下,如果需求允许客户可以定制风格,而不同风格对于“性别”的表现方式不一样,又或者这个服务同时供多个客户端使用(不同门户),而不同的客户端对于表现层的要求有所不同,那么,问题就来了。再者,回到设计层面上分析,从职责单一原则来看,服务层只负责业务,与具体的表现形式无关,因此,它返回的DTO,不应该出现与表现形式的耦合。
理论归理论,这到底还是分析设计层面的思维,是否在实现层面必须这样做呢?一刀切的做法往往会得不偿失,下面我马上会分析应用中如何做出正确的选择。
VO与DTO的应用
上面只是用了一个简单的例子来说明VO与DTO在概念上的区别,本节将会告诉你如何在应用中做出正确的选择。
在以下才场景中,我们可以考虑把VO与DTO二合为一(注意:是实现层面):
- 当需求非常清晰稳定,而且客户端很明确只有一个的时候,没有必要把VO和DTO区分开来,这时候VO可以退隐,用一个DTO即可,为什么是VO退隐而不是DTO?回到设计层面,服务层的职责依然不应该与展示层耦合,所以,对于前面的例子,你很容易理解,DTO对于“性别”来说,依然不能用“帅哥美女”,这个转换应该依赖于页面的脚本(如JavaScript)或其他机制(JSTL、EL、CSS)。
- 即使客户端可以进行定制,或者存在多个不同的客户端,如果客户端能够用某种技术(脚本或其他机制)实现转换,同样可以让VO退隐。
以下场景需要优先考虑VO、DTO并存:
- 上述场景的反面场景
- 因为某种技术原因,比如某个框架(如Flex)提供自动把POJO转换为UI中某些Field时,可以考虑在实现层面定义出VO,这个权衡完全取决于使用框架的自动转换能力带来的开发和维护效率提升与设计多一个VO所多做的事情带来的开发和维护效率的下降之间的比对。
- 如果页面出现一个“大视图”,而组成这个大视图的所有数据需要调用多个服务,返回多个DTO来组装(当然,这同样可以通过服务层提供一次性返回一个大视图的DTO来取代,但在服务层提供一个这样的方法是否合适,需要在设计层面进行权衡)。
DTO与DO的区别
首先是概念上的区别,DTO是展示层和服务层之间的数据传输对象(可以认为是两者之间的协议),而DO是对现实世界各种业务角色的抽象,这就引出了两者在数据上的区别,例如UserInfo和User(对于DTO和DO的命名规则,请参见笔者前面的一篇博文),对于一个getUser方法来说,本质上它永远不应该返回用户的密码,因此UserInfo至少比User少一个password的数据。而在领域驱动设计中,正如第一篇系列文章所说,DO不是简单的POJO,它具有领域业务逻辑。
DTO与DO的应用
从上一节的例子中,细心的读者可能会发现问题:既然getUser方法返回的UserInfo不应该包含password,那么就不应该存在password这个属性定义,但如果同时有一个createUser的方法,传入的UserInfo需要包含用户的password,怎么办?在设计层面,展示层向服务层传递的DTO与服务层返回给展示层的DTO在概念上是不同的,但在实现层面,我们通常很少会这样做(定义两个UserInfo,甚至更多),因为这样做并不见得很明智,我们完全可以设计一个完全兼容的DTO,在服务层接收数据的时候,不该由展示层设置的属性(如订单的总价应该由其单价、数量、折扣等决定),无论展示层是否设置,服务层都一概忽略,而在服务层返回数据时,不该返回的数据(如用户密码),就不设置对应的属性。
对于DO来说,还有一点需要说明:为什么不在服务层中直接返回DO呢?这样可以省去DTO的编码和转换工作,原因如下:
- 两者在本质上的区别可能导致彼此并不一一对应,一个DTO可能对应多个DO,反之亦然,甚至两者存在多对多的关系。
- DO具有一些不应该让展示层知道的数据
- DO具有业务方法,如果直接把DO传递给展示层,展示层的代码就可以绕过服务层直接调用它不应该访问的操作,对于基于AOP拦截服务层来进行访问控制的机制来说,这问题尤为突出,而在展示层调用DO的业务方法也会因为事务的问题,让事务难以控制。
- 对于某些ORM框架(如Hibernate)来说,通常会使用“延迟加载”技术,如果直接把DO暴露给展示层,对于大部分情况,展示层不在事务范围之内(Open session in view在大部分情况下不是一种值得推崇的设计),如果其尝试在Session关闭的情况下获取一个未加载的关联对象,会出现运行时异常(对于Hibernate来说,就是LazyInitiliaztionException)。
- 从设计层面来说,展示层依赖于服务层,服务层依赖于领域层,如果把DO暴露出去,就会导致展示层直接依赖于领域层,这虽然依然是单向依赖,但这种跨层依赖会导致不必要的耦合。
对于DTO来说,也有一点必须进行说明,就是DTO应该是一个“扁平的二维对象”,举个例子来说明:如果User会关联若干个其他实体(例如Address、Account、Region等),那么getUser()返回的UserInfo,是否就需要把其关联的对象的DTO都一并返回呢?如果这样的话,必然导致数据传输量的大增,对于分布式应用来说,由于涉及数据在网络上的传输、序列化和反序列化,这种设计更不可接受。如果getUser除了要返回User的基本信息外,还需要返回一个AccountId、AccountName、RegionId、RegionName,那么,请把这些属性定义到UserInfo中,把一个“立体”的对象树“压扁”成一个“扁平的二维对象”。笔者目前参与的项目是一个分布式系统,该系统不管三七二十一,把一个对象的所有关联对象都转换为相同结构的DTO对象树并返回,导致性能非常的慢。
DO与PO的区别
DO和PO在绝大部分情况下是一一对应的,PO是只含有get/set方法的POJO,但某些场景还是能反映出两者在概念上存在本质的区别:
- DO在某些场景下不需要进行显式的持久化,例如利用策略模式设计的商品折扣策略,会衍生出折扣策略的接口和不同折扣策略实现类,这些折扣策略实现类可以算是DO,但它们只驻留在静态内存,不需要持久化到持久层,因此,这类DO是不存在对应的PO的。
- 同样的道理,某些场景下,PO也没有对应的DO,例如老师Teacher和学生Student存在多对多的关系,在关系数据库中,这种关系需要表现为一个中间表,也就对应有一个TeacherAndStudentPO的PO,但这个PO在业务领域没有任何现实的意义,它完全不能与任何DO对应上。这里要特别声明,并不是所有多对多关系都没有业务含义,这跟具体业务场景有关,例如:两个PO之间的关系会影响具体业务,并且这种关系存在多种类型,那么这种多对多关系也应该表现为一个DO,又如:“角色”与“资源”之间存在多对多关系,而这种关系很明显会表现为一个DO——“权限”。
- 某些情况下,为了某种持久化策略或者性能的考虑,一个PO可能对应多个DO,反之亦然。例如客户Customer有其联系信息Contacts,这里是两个一对一关系的DO,但可能出于性能的考虑(极端情况,权作举例),为了减少数据库的连接查询操作,把Customer和Contacts两个DO数据合并到一张数据表中。反过来,如果一本图书Book,有一个属性是封面cover,但该属性是一副图片的二进制数据,而某些查询操作不希望把cover一并加载,从而减轻磁盘IO开销,同时假设ORM框架不支持属性级别的延迟加载,那么就需要考虑把cover独立到一张数据表中去,这样就形成一个DO对应多个PO的情况。
- PO的某些属性值对于DO没有任何意义,这些属性值可能是为了解决某些持久化策略而存在的数据,例如为了实现“乐观锁”,PO存在一个version的属性,这个version对于DO来说是没有任何业务意义的,它不应该在DO中存在。同理,DO中也可能存在不需要持久化的属性。
DO与PO的应用
由于ORM框架的功能非常强大而大行其道,而且JavaEE也推出了JPA规范,现在的业务应用开发,基本上不需要区分DO与PO,PO完全可以通过JPA,Hibernate Annotations/hbm隐藏在DO之中。虽然如此,但有些问题我们还必须注意:
- 对于DO中不需要持久化的属性,需要通过ORM显式的声明,如:在JPA中,可以利用@Transient声明。
- 对于PO中为了某种持久化策略而存在的属性,例如version,由于DO、PO合并了,必须在DO中声明,但由于这个属性对DO是没有任何业务意义的,需要让该属性对外隐藏起来,最常见的做法是把该属性的get/set方法私有化,甚至不提供get/set方法。但对于Hibernate来说,这需要特别注意,由于Hibernate从数据库读取数据转换为DO时,是利用反射机制先调用DO的空参数构造函数构造DO实例,然后再利用JavaBean的规范反射出set方法来为每个属性设值,如果不显式声明set方法,或把set方法设置为private,都会导致Hibernate无法初始化DO,从而出现运行时异常,可行的做法是把属性的set方法设置为protected。
- 对于一个DO对应多个PO,或者一个PO对应多个DO的场景,以及属性级别的延迟加载,Hibernate都提供了很好的支持,请参考Hibnate的相关资料。
到目前为止,相信大家都已经比较清晰的了解VO、DTO、DO、PO的概念、区别和实际应用了。通过上面的详细分析,我们还可以总结出一个原则:分析设计层面和实现层面完全是两个独立的层面,即使实现层面通过某种技术手段可以把两个完全独立的概念合二为一,在分析设计层面,我们仍然(至少在头脑中)需要把概念上独立的东西清晰的区分开来,这个原则对于做好分析设计非常重要(工具越先进,往往会让我们越麻木)。第一篇系列博文抛砖引玉,大唱领域驱动设计的优势,但其实领域驱动设计在现实环境中还是有种种的限制,需要选择性的使用,正如我在《田七的智慧》博文中提到,我们不能永远的理想化的去选择所谓“最好的设计”,在必要的情况下,我们还是要敢于放弃,因为最合适的设计才是最好的设计。本来,系列中的第二篇博文应该是讨论领取驱动设计的限制和如何选择性的使用,但请原谅我的疏忽,下一篇系列博文会把这个主题补上,敬请关注。
http://kb.cnblogs.com/page/522348/
领域驱动设计系列(2)浅析VO、DTO、DO、PO的概念、区别和用处的更多相关文章
- 领域驱动设计系列文章——浅析VO、DTO、DO、PO的概念、区别和用处
本篇文章主要讨论一下我们经常会用到的一些对象:VO.DTO.DO和PO. 由于不同的项目和开发人员有不同的命名习惯,这里我首先对上述的概念进行一个简单描述,名字只是个标识,我们重点关注其概念: 概念: ...
- [转]领域驱动设计系列文章(2)——浅析VO、DTO、DO、PO的概念、区别和用处
原文地址:http://www.blogjava.net/johnnylzb/archive/2010/05/27/321968.html 上一篇文章作为一个引子,说明了领域驱动设计的优势,从本篇文章 ...
- 领域驱动设计系列文章(2)——浅析VO、DTO、DO、PO的概念、区别和用处
本篇文章主要讨论一下我们经常会用到的一些对象:VO.DTO.DO和PO. 由于不同的项目和开发人员有不同的命名习惯,这里我首先对上述的概念进行一个简单描述,名字只是个标识,我们重点关注其概念: 概念: ...
- DDD领域驱动设计 ---- 系列文章
C#进阶系列——DDD领域驱动设计初探(七):Web层的搭建 C#进阶系列——DDD领域驱动设计初探(六):领域服务 C#进阶系列——DDD领域驱动设计初探(五):AutoMapper使用 C#进阶系 ...
- .NET领域驱动设计系列(12)
[.NET领域驱动设计实战系列]专题十一:.NET 领域驱动设计实战系列总结 摘要: 一.引用 其实在去年本人已经看过很多关于领域驱动设计的书籍了,包括Microsoft .NET企业级应用框架设计. ...
- SpringBoot中VO,DTO,DO,PO的概念、区别和用处
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/zhuguang10/article/de ...
- 领域驱动设计系列 (六):CQRS
CQRS是Command Query Responsibility Seperation(命令查询职责分离)的缩写. 世上很多事情都比较复杂,但是我们只要进行一些简单的分类后,那么事情就简单了很多,比 ...
- [.NET领域驱动设计实战系列]专题十:DDD扩展内容:全面剖析CQRS模式实现
一.引言 前面介绍的所有专题都是基于经典的领域驱动实现的,然而,领域驱动除了经典的实现外,还可以基于CQRS模式来进行实现.本专题将全面剖析如何基于CQRS模式(Command Query Respo ...
- [.NET领域驱动设计实战系列]专题十一:.NET 领域驱动设计实战系列总结
一.引用 其实在去年本人已经看过很多关于领域驱动设计的书籍了,包括Microsoft .NET企业级应用框架设计.领域驱动设计C# 2008实现.领域驱动设计:软件核心复杂性应对之道.实现领域驱动设计 ...
随机推荐
- LintCode (9)Fizz Buzz
下面是AC代码,C++风格: class Solution { public: vector<string> fizzBuzz(int N) { vector<string> ...
- poj 2771 最大独立集
这道题又无耻的抄袭了别人的代码. 刚开始以为是最大匹配,把条件不相符的人连一起,然后求最大匹配,感觉麻烦,然后看了别人的解题报告,是把相符的人连一起,然后减去,其实就是最大独立集. 最大独立集=|G| ...
- JVM学习之常用概念
方法区 当JVM使用类装载器装载某个类时,它首先要定位对应的class文件,然后读入这个class文件,最后,JVM提取该文件的内容信息,并将这些信息存储到方法区,最后返回一个class实例. ...
- Android Shape画圆,矩形
画圆环代码如下: 画圆环,外边的边界宽度大一点即可: <?xml version="1.0" encoding="utf-8"?> <shap ...
- threadid=1: thread exiting with uncaught exception (group=0x40db8930)
异常信息如下: 07-26 17:23:49.521: W/dalvikvm(29229): threadid=1: thread exiting with uncaught exception (g ...
- nodejs 下载网页及相关资源文件
功能其实很见简单,通过 phantomjs.exe 采集 url 加载的资源,通过子进程的方式,启动nodejs 加载所有的资源,对于css的资源,匹配css内容,下载里面的url资源 当然功能还是很 ...
- 我用的php开发环境是appserv一键安装,通过http://localhost测试成功,但是我有点不清楚的就是为什么访问.php文件要在地址栏上加上localhost(即http://localhost/text.php)才能成功访问?
这类似于一个域名地址. 因为默认localhost 就是指向本机.所以就用这个来访问自己本地的网页.比如你也可以输入 http://127.0.0.1/text.php http://192.168. ...
- win8VPN
上一章已经讲过Windows2008RT搭建VPN服务器搭建过程,接下来说一下win8的VPN登录 这里是win2008的VPN连接过程 先说win8的VPN登录过程.同样也很简单步骤和2008的差不 ...
- SLC和MLC闪存芯片的区别
许多人对闪存的SLC和MLC区分不清.就拿目前热销的MP3随身听来说,是买SLC还是MLC闪存芯片的呢?在这里先告诉大家,如果你对容量要求不高,但是对机器质量.数据的安全性.机器寿命等方面要求较高,那 ...
- Ring3下干净的强行删除文件
在某公司实习完,再次回到寝室.还是在学校好. 实习期间的给我的任务就是为项目添加一个强行删除的模块. 背景是硬盘上存储空间不够时,需要删掉老的文件,如果这时后,老的文件被打开了,没有关掉,就无法删除. ...