使用部分写时复制提升Lakehouse的 ACID Upserts性能
使用部分写时复制提升Lakehouse的 ACID Upserts性能
译自:Fast Copy-On-Write within Apache Parquet for Data Lakehouse ACID Upserts
传统的写时复制会直接读取并处理(解压解码等)整个文件,然后更新相关数据页并保存为新的文件,但大部分场景下,upsert并不会更新所有数据页,这就导致其做了很多无用功。
文章中引入了一种新的写时复制,它会创建指向Apache Parquet文件的数据页的索引,并跳过不相关的数据页(不会对这部分数据进行解压解码等操作),以此来加速数据的处理。
术语
- copy-on-write:写时复制
- merge-on-write:读时合并
概述
随着存储表格式的发展,越来越多的公司正在基于Apache Hudi、Apache Iceberg和Delta Lake等工具来构建lakehouse,以满足多种使用场景,如增量处理。但随着数据卷的增加,upsert的运行速度可能会带来一定的影响。
在各种存储表中,Apache Parquet是其中最主要的文件格式。下面我们将讨论如何通过构建二级索引并对Apache Parquet进行一些创新来提升在Parquet文件中upsert数据的速度。我们还会通过性能测试来展示相较传统的Delta Lake和Hudi写时复制的速度(提升3x~20x倍)。
起因
高效的ACID upsert 对于今天的lakehouse至关重要,一些重要的使用场景,如数据保存和Change Data Capture(CDC)严重依赖ACID upsert。虽然 Apache Hudi, Apache Iceberg 和 Delta Lake中已经大规模采用了upsert,但随着数据卷的增加,其运行速度也在降低(特别是写时复制模式)。有时较慢的upsert会成为消耗时间和资源的点,甚至会阻塞任务的执行。
为了提升upsert的速度,我们在具有行级索引的Apache Parquet文件中引入了部分写时复制,以此来跳过那些不必要的数据页(Apache Parquet中的最小存储单元)。术语"部分"指文件中与upsert相关的数据页。一般场景中只需要更新一小部分文件,而大部分数据页都可以被跳过。通过观察,发现相比Delta Lake和Hudi的传统写时复制,这种方式提升了3~20倍的速度。
Lakehouse中的写时复制
本文中我们使用Apache Hudi作为例子,但同样适用于Delta Lake和Apache Iceberg。Apache Hudi支持两种类型的upserts操作:写时复制和读时合并。通过写时复制,所有具有更新范围内记录的文件都将被重写为新文件,然后创建包含新文件的新snapshot元数据。相比之下,读时合并会创建增量更新文件,并由读取器(reader)进行合并。
下图给出了一个数据表更新单个字段的例子。从逻辑的角度看,对User ID1的email字段进行了更新,其他字段都没变。从物理角度看,表数据存储在磁盘中的单独文件中,大多数情况下,这些文件会基于时间或其他分区机制进行分组(分区)。Apache Hudi使用索引系统在每个分区中定位所需的文件,然后再完整地进行读取,更新内存中的email字段,最后写入磁盘并形成新的文件。下图中红色的部分表示重写产生的新文件。
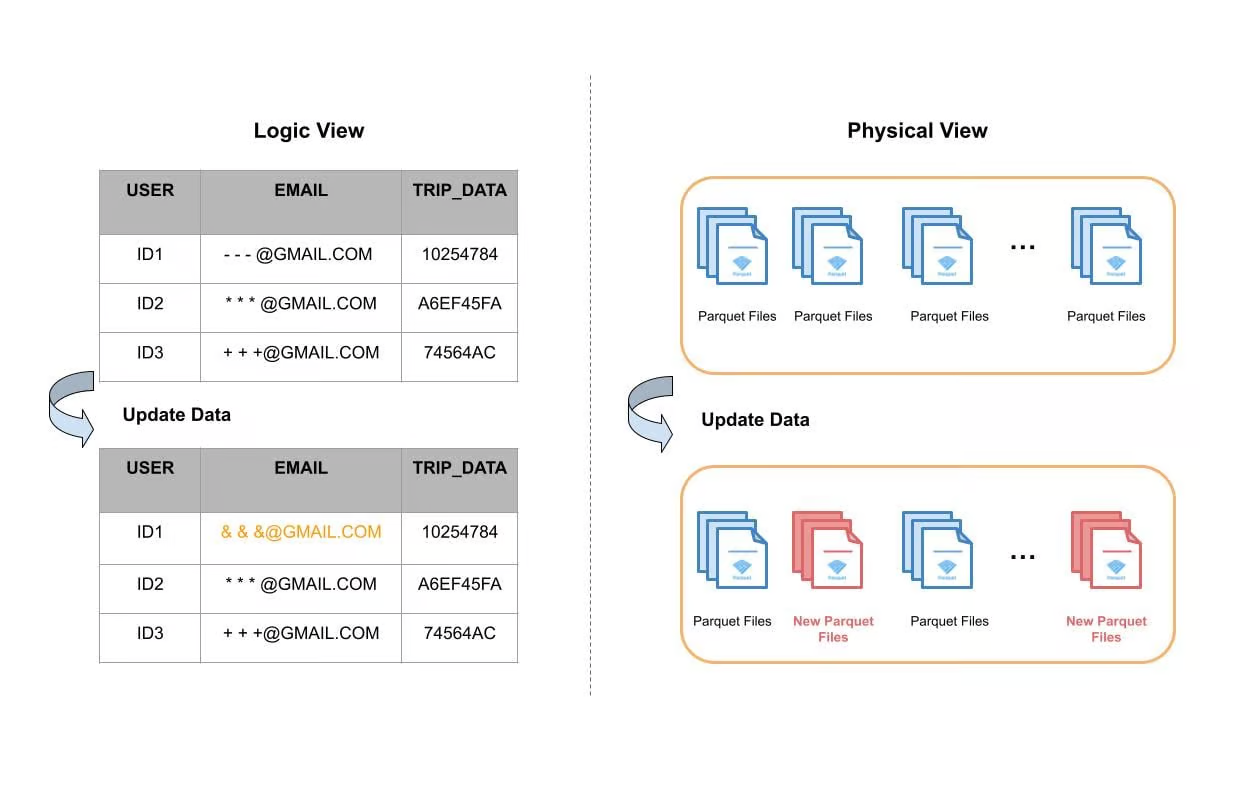
图1:表upsert的逻辑和物理文件视角
使用Apache Hudi构建大型事务数据湖一文中提到,一些表更新可能会涉及到90%的文件,进而导致重写数据湖中的特定大型表中约100TB的数据。因此写时复制对于很多使用场景至关重要。较慢的写时复制不仅会导致任务运行时间变长,还会消耗更多的计算资源。在一些使用场景中可以观察到使用了相当数量的vCore,等同于花费了上百万美元。
引入行级别的二级索引
在讨论如何在Apache 中提升写时复制之前,我们打算引入Parquet 行级别的二级索引,用于帮助在Parquet中定位数据页,进而提升写时复制。
当首次写入一个Parquet文件或通过离线读取Parquet文件时会构建行级别的二级索引,它会将record映射为[file, row-id],而不是[file]。例如,可以使用RECORD_ID作为索引key,FILE和Row_IDs分别指向文件和每个文件的偏移量。
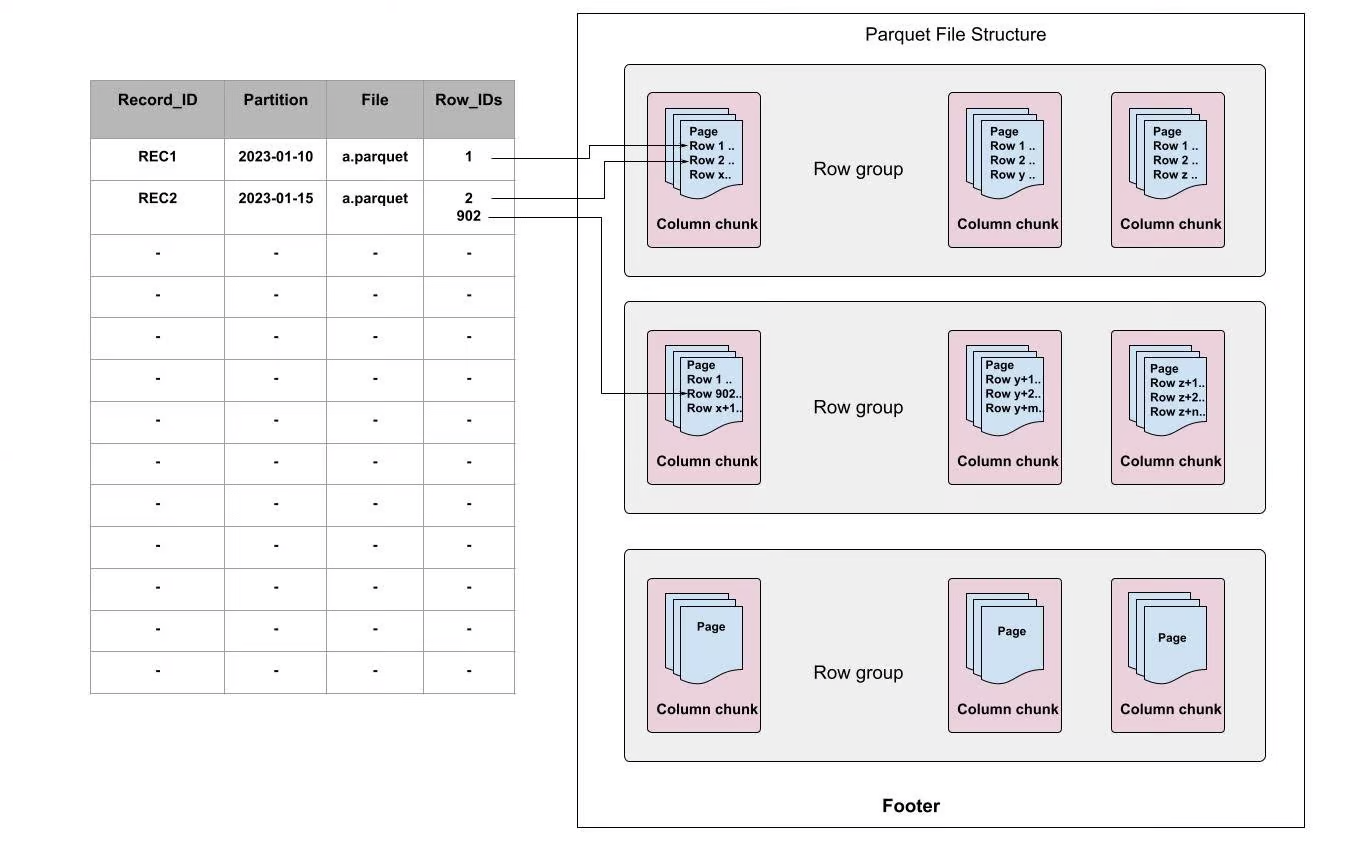
图2:Apache Parquet中行级别的索引
在Apache Parquet内部,数据被分为多个row groups。每个row group由一个或多个column chunks构成(column chunk对应数据集中的一列),然后每个column chunk 会被写成数据页格式。一个block包含多个页,它是访问单个record前必须读取的最小单元。在页内部,除了编码的目录页,每个字段都追加了值、重复级别和定义级别。
如上图所示,每个索引都指向页中record所在的行。使用行级别的索引时,当接收到更新时,我们不仅仅可以快速定位哪个文件,还可以定位需要更新的数据页。使用这种方式可以帮助我们跳过不需要更新的页,并节省大量计算资源,加速写时复制的过程。
Apache Parquet中的写时复制
我们在Apache Parquet中引入了一种新的写时复制方式来加速lakehouse的upserts。我们只对Parquet文件中相关的数据页执行写时复制更新,而对于无关的页,只是将其复制为字节缓存而没有做任何更改。这减少了在更新操作期间需要更新的数据量,并提高了性能。
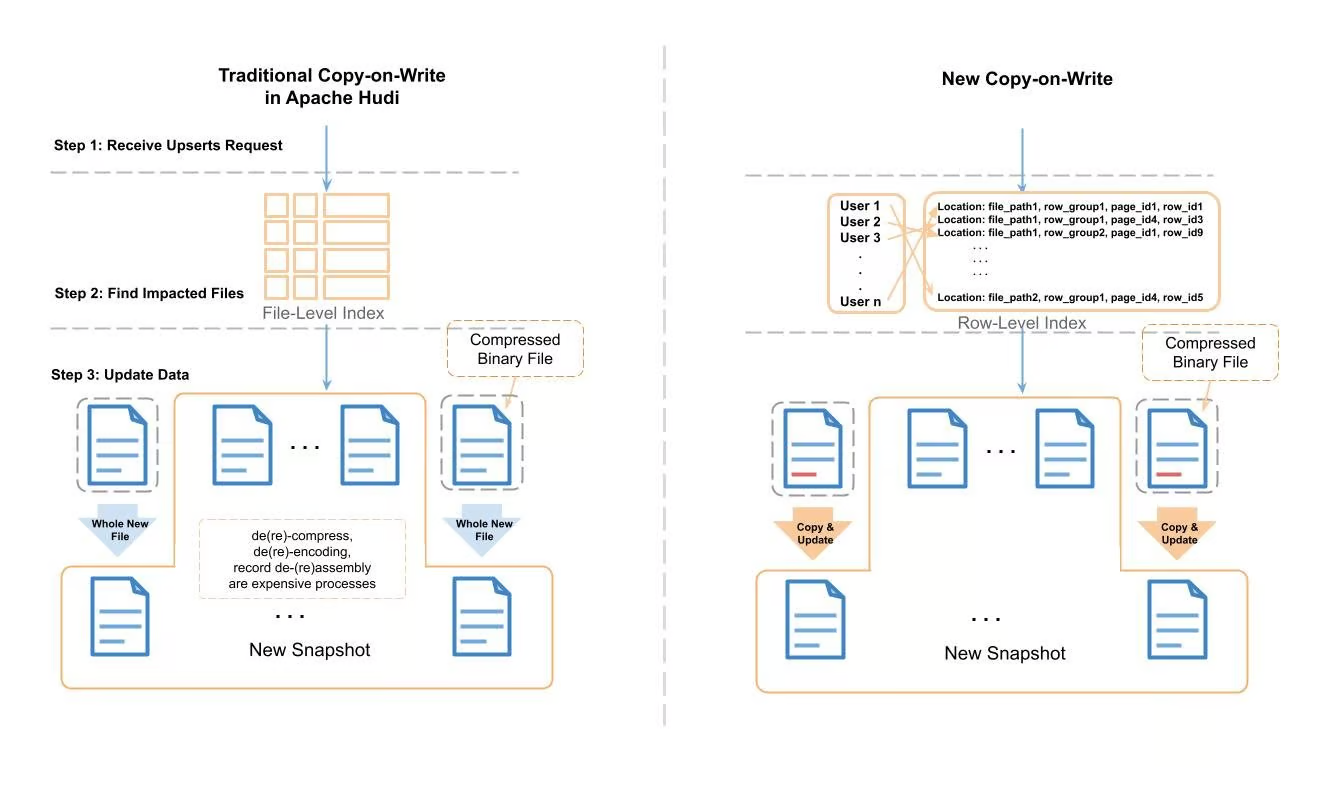
图3:Apache Hudi传统写时复制和新写时复制的比较
上面展示了新的写时复制和传统的写时复制的处理过程。在传统的Apache Hudi upsert中,Hudi会使用record 索引来定位需要修改的文件,然后一个record一个record地将文件读取到内存中,然后查找需要修改的record。在应用变更之后,它会将数据写入一个全新的文件中。在读取-修改-写入的过程中,会产生消耗大量CPU周期和内存的任务(如压缩/解压缩,编码/解码,组装/拆分record等)。
为了处理所需的时间和资源消耗,我们使用行级别的索引和Parquet元数据来定位需要修改的页,对于不在修改范围的页,只需要将其作为字节缓存拷贝到新文件即可,无需压缩/解压缩,编码/解码,组装/拆分record等。我们将该过程称为"拷贝&更新"。下图描述了更多细节:
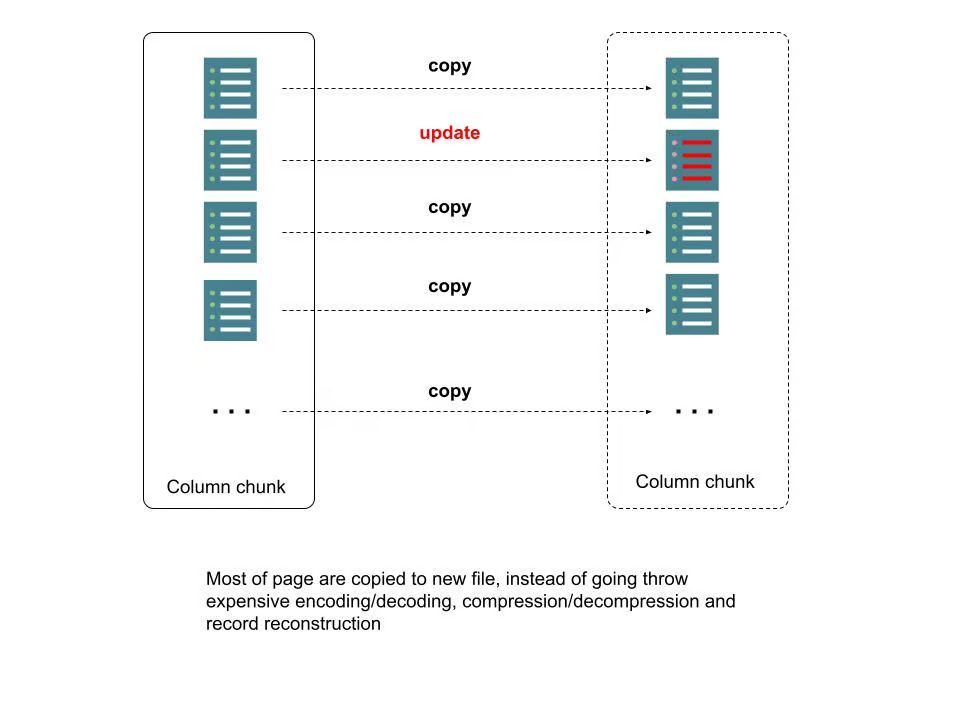
图4:Parquet文件中的新写时复制
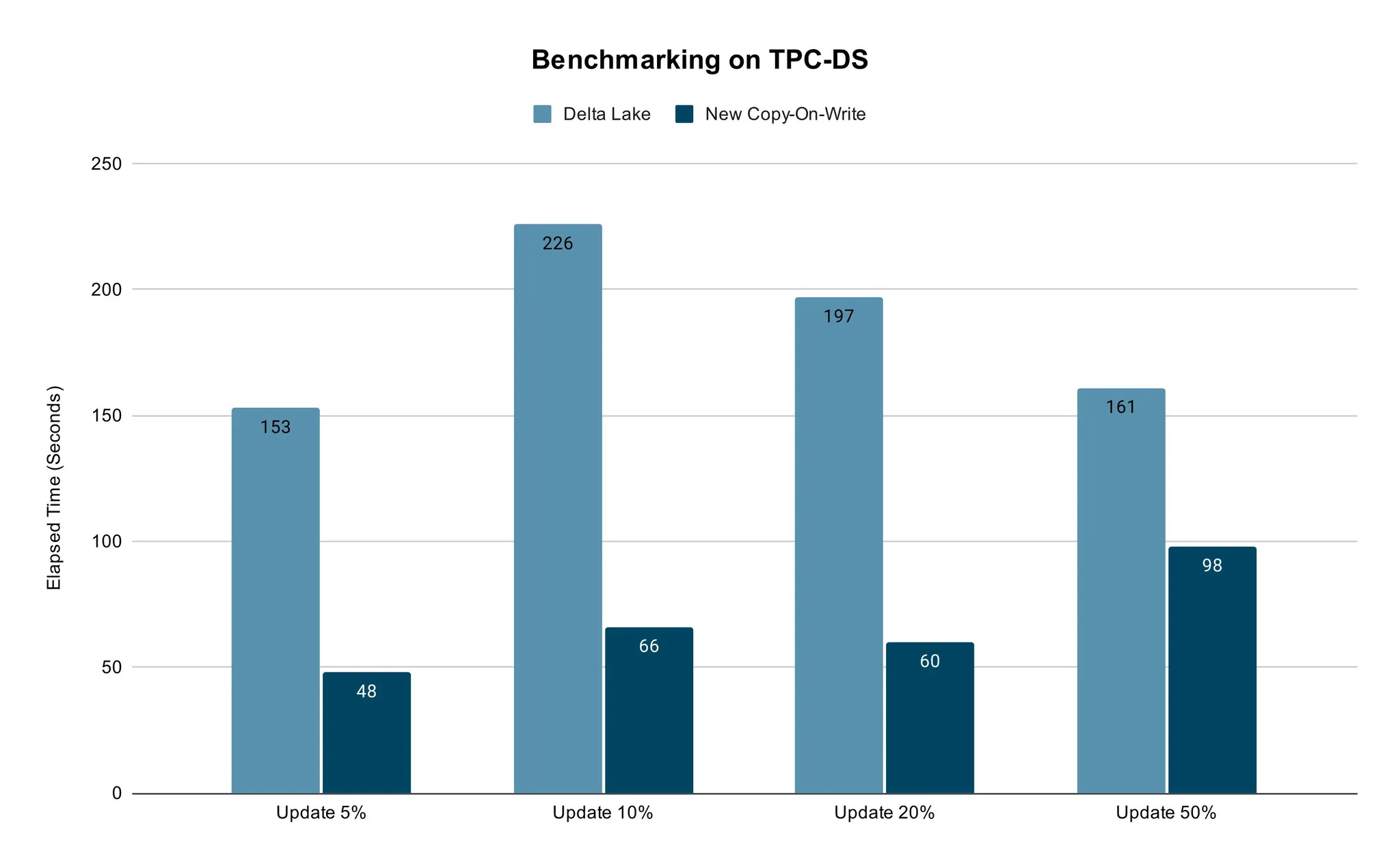
性能测试
我们使用传统的TPC-DS 数据方式测试比较了新的写时复制的性能。
我们采用具有相同vCore数量的TPC-DS销售数据和Spark作业的内存设置,并用开箱即用的配置进行了测试。我们对5%~50%的数据进行了更新,然后比较Delta Lake和新的写时复制所花费的时间。对于真实的使用场景来说,50%的数据更新已经足够了。
测试结果表明,新方法的更新速度更快。不同百分比数据的更新场景下都能保证其性能优势。
总结
总之,高效的ACID upserts对今天的lakehouse至关重要。随着Apache Hudi, Delta Lake 和 Apache Iceberg 的广泛采纳,upserts的慢操作也面临挑战,特别是在数据卷不断扩展的情况下。为了解决这个问题,我们在具有行级索引的Apache Parquet文件中引入了部分写时复制,以此来跳过对不需要的数据页的读写。在性能测试中展现了明显的性能优势。该方法使公司能够高效地执行数据删除和CDC,并适用于其他依赖于lakehouse中高效表更新的场景。
使用部分写时复制提升Lakehouse的 ACID Upserts性能的更多相关文章
- php变量 写时改变 写时复制
写时复制 $var = 1; $var2 = $var; #此时$var2 与 $var 指向同一个zval refcount = 2: $var = 2; # 此时$val 改变 所以 $var 与 ...
- PHP写时复制, 变量复制和对象复制不同!!!
2016年3月18日 15:09:28 星期五 一直以为PHP对象也是写时复制....... 其实: PHP的变量是写时复制, 对象是引用的 写时复制: $a = $b; 如果$b的内容不改变, $a ...
- php 垃圾回收机制----写时复制和引用计数
PHP使用引用计数和写时复制来管理内存.写时复制保证了变量间复制值不浪费内存,引用计数保证了当变量不再需要时,将内存释放给操作系统. 要理解PHP内存管理,首先要理解一个概念----符号表. 符号表的 ...
- JAVA中写时复制(Copy-On-Write)Map实现
1,什么是写时复制(Copy-On-Write)容器? 写时复制是指:在并发访问的情景下,当需要修改JAVA中Containers的元素时,不直接修改该容器,而是先复制一份副本,在副本上进行修改.修改 ...
- fork()和写时复制
写时复制技术最初产生于Unix系统,用于实现一种傻瓜式的进程创建:当发出fork( )系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程.这种行为是非常耗时的,因为它需要: · ...
- Linux的fork()写时复制原则(转)
写时复制技术最初产生于Unix系统,用于实现一种傻瓜式的进程创建:当发出fork( )系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程.这种行为是非常耗时的,因为它需要: · ...
- Linux进程管理——fork()和写时复制
写时复制技术最初产生于Unix系统,用于实现一种傻瓜式的进程创建:当发出fork( )系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程.这种行为是非常耗时的,因为它需要: · ...
- [转]QVector与QByteArray——Qt的写时复制(copy on write)技术
我们在之前的博文QVector的内存分配策略与再谈QVector与std::vector——使用装饰者让std::vector支持连续赋值中简单聊了聊QVector内存分配和赋值方面的一点东西,今天接 ...
- 写时复制和fork,vfork,clone
写时复制 原理: 用了“引用计数”,会有一个变量用于保存引用的数量.当第一个类构造时,string的构造函数会根据传入的参数从堆上分配内存,当有其它类需要这块内存时,这个计数为自动累加,当有类析构时, ...
- c++ string写时复制
string写时复制:将字符串str1赋值给str2后,除非str1的内容已经被改变,否则str2和str1共享内存.当str1被修改之后,stl才为str2开辟内存空间,并初始化. #include ...
随机推荐
- Java 8新特性之 Optional 类
前言 java.util.Optional 是java8中引进的一个新的类,我们通过Optional类的源码可以看到,该方法的作用可以对可能缺失的值进行建模,而不是直接将null赋值给变量. Opti ...
- Three.js 进阶之旅:全景漫游-高阶版在线看房 🏡
声明:本文涉及图文和模型素材仅用于个人学习.研究和欣赏,请勿二次修改.非法传播.转载.出版.商用.及进行其他获利行为. 摘要 专栏上篇文章<Three.js 进阶之旅:全景漫游-初阶移动相机版& ...
- redis 基于 漏斗算法 实现对 api 的限流
漏斗算法 漏桶算法的原理: 漏桶有一定的容量,给漏桶注水,当单位时间内注入水量大于流出水量,漏桶内积累的水就会越来越多,直到溢出. 就好比大批量请求访问nginx相当于注水,nginx根据配置按照固定 ...
- The first week match's mistake
比赛中的补题中的一些错误 P8506 标题计数(https://www.luogu.com.cn/problem/P8506) 第一眼下去,嗯..贪了,只读到一个'#'后边跟一个空格就+1,结果wa几 ...
- .NET敏捷开发框架-RDIFramework.NET V5.1发布(跨平台)
RDIFramework.NET,基于全新.NET Framework与.NET Core的快速信息化系统敏捷开发.整合框架,给用户和开发者最佳的.Net框架部署方案.为企业快速构建跨平台.企业级的应 ...
- 基于海思H3520DV400和QT5.9设计的车载终端DVR控制平台
目录 前言: 说明: 功能介绍: 设计思路: 详细设计: QT界面设计: 代码实现: 注意事项: (一)QT运行慢问题 (二)QT图层隐藏问题 (三)鼠标问题 (四)字体问题 (五)主界面图案 ( ...
- ThreadLocal实现原理和使用场景
ThreadLocal是线程本地变量,每个线程中都存在副本. 实现原理: 每个线程中都有一个ThreadLocalMap,而ThreadLocalMap中的key即是ThreadLocal. 内存泄 ...
- [C++提高编程] 3.4 案例-评委打分
文章目录 3.4 案例-评委打分 3.4.1 案例描述 3.4.2 实现步骤 3.4 案例-评委打分 3.4.1 案例描述 有5名选手:选手ABCDE,10个评委分别对每一名选手打分,去除最高分,去除 ...
- Python-解三元一次方程
需要解的方程组为: x + y + z = 26 x - y = 1 2x - y + z = 18 下面进入代码实现: 1.导入数学计算库 numpy import numpy as np 2.生成 ...
- Gusfield算法学习
算法详解 等价流树正如其名,树上两点间的路径上的边权最小值为图上两点间的最小割. Gusfield算法就是建等价流树的一种算法.设当前正在处理的集合为 \(S(|S|\ge 2)\),从 \(S\) ...