RepPoints:微软巧用变形卷积生成点集进行目标检测,创意满满 | ICCV 2019
RepPoints的设计思想十分巧妙,使用富含语义信息的点集来表示目标,并且巧用可变形卷积来进行实现,整体网络设计十分完备,值得学习
来源:晓飞的算法工程笔记 公众号
论文: RepPoints: Point Set Representation for Object Detection

Introduction
经典的bounding box虽然有利于计算,但没有考虑目标的形状和姿态,而且从矩形区域得到的特征可能会受背景内容或其它的目标的严重影响,低质量的特征会进一步影响目标检测的性能。为了解决bounding box存在的问题,论文提出了RepPoints这种新型目标表示方法,能够进行更细粒度的定位能力以及更好的分类效果。
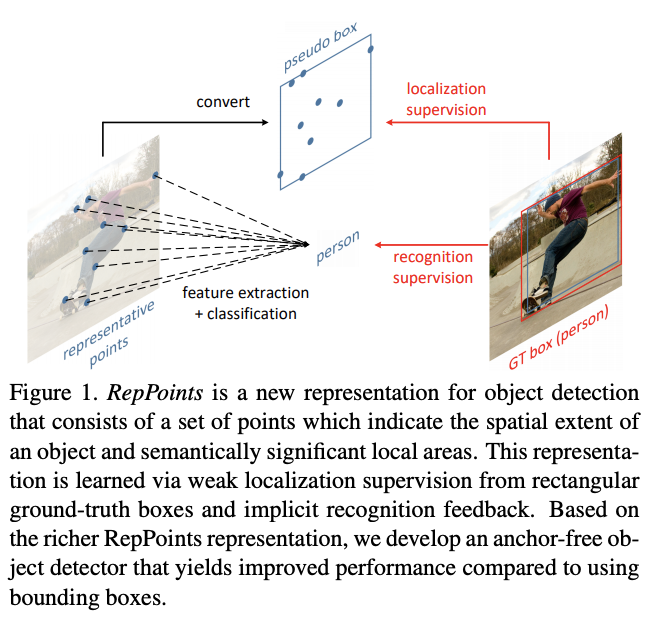
如图1所示,RepPoints是一个点集,能够自适应地包围目标并且包含局部区域的语义特征。RepPoints的训练由目标定位和目标分类共同驱动,能够约束RepPoints紧紧地包围目标以及引导检测器正确地分类目标。这种自适应的表示方法是可微的,能够连续地用在检测器的多个阶段中,并且不需要额外设置的anchor来生成大量的初始框。
The RepPoints Representation
如上面提到的,bounding box只是粗粒度的目标位置表示方法,只考虑了目标的矩形空间,没有考虑形状、姿态以及语义丰富的局部区域,而语义丰富的局部区域能够帮助网络更好的定位以及特征提取。为了解决上述的缺点,RepPoints使用一组自适应的采样点表示目标:
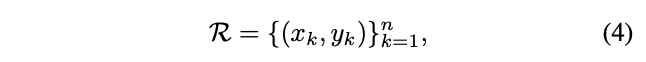
\(n\)为表示目标的采样点总数,论文默认设置为9。
RepPoints refinement
逐步调整bounding box定位和特征提取是multi-stage检测器成功的重要手段,对于RepPoints,调整可简单地表示为:
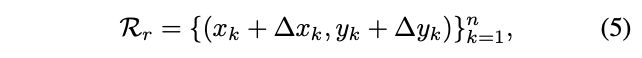
\(\{(\Delta x_k, \Delta y_k)\}^{n}_{k=1}\)为预测的新采样点相对与旧采样点的偏移值,采样点调整的尺寸都是一样的,不会像bouning box那样需要解决中心点坐标和边框长度的尺寸不一致问题。
Converting RepPoints to bounding box
为了利用bounding box的标注信息进行训练以及验证RepPoint-based检测算法的性能,使用预设的转化方法\(\mathcal{T}=\mathcal{R}_P\to \mathcal{B}_P\)将RepPoints转化成伪预测框,共有三种转化方法:
- \(\mathcal{T}=\mathcal{T}_1\): Min-max function,对所有的RepPoints进行min-max操作来获取预测框\(\mathcal{B}_p\)
- \(\mathcal{T}=\mathcal{T}_2\):Partial min-max function,对部分的RepPoints进行min-max操作获取预测框\(\mathcal{B}_p\)
- \(\mathcal{T}=\mathcal{T}_3\):Moment-based function,通过RepPoints的均值和标准差计算中心点位置以及预测框尺寸得到预测框\(\mathcal{B}_p\),尺寸通过全局共享的可学习参数\(\lambda_x\)和\(\lambda_y\)相乘得到
这些函数都是可微的,可加入检测器中进行end-to-end的训练。通过实验验证,这3个转化方法效果都不错。
RPDet: an Anchor Free Detector
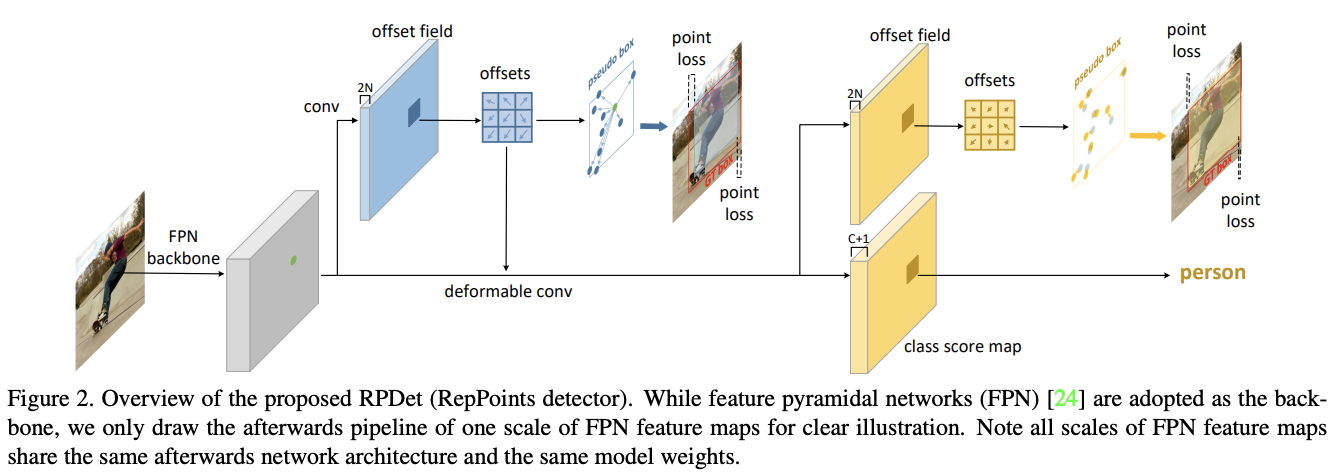
论文基于RepPoints设计了anchor-free目标检测算法RPDet,包含两个识别阶段。因为可变形卷积可采样多个不规则分布的点进行卷积输出,所以可变形卷积十分适合RepPoints场景,能够根据识别结果的反馈进行采样点的引导。
Center point based initial object representation
RPDet将中心点作为初始的目标表示,然后逐步调整出最终的RepPoints,中心点也可认为是特殊的RepPoints。当两个目标存在于特征图同一位置时,这种基于中心点的方法通常会出现识别目标歧义的问题。此前的方法在同一位置设置多个预设的anchor来解决此问题,而RPDet则利用FPN来解决此问题:
- 不同大小的目标由不同level的特征负责识别
- 小物体对应level的特征图一般较大,减少了同一物体存在同一位置的可能性
论文统计发现,当使用上述FPN约束后,COCO数据集中仅1.1.%存在上述的问题。
Utilization of RepPoints
如图2所示,RepPoints是RPDet的基础目标表示方法,从中心点开始,第一组RepPoints通过回归中心点的偏移值获得。第二组RepPoints代表最终的目标位置,由第一组RepPoints优化调整得到。RepPoints的学习主要由两个目标驱动:
- 伪预测框和GT框的左上角点和右上角点的距离损失
- 后续的目标分类损失
第一组RepPoints由距离损失和分类损失引导,第二组RepPoints仅使用距离损失进行引导,主要为了学习到更精准的目标定位。
Backbone and head architectures
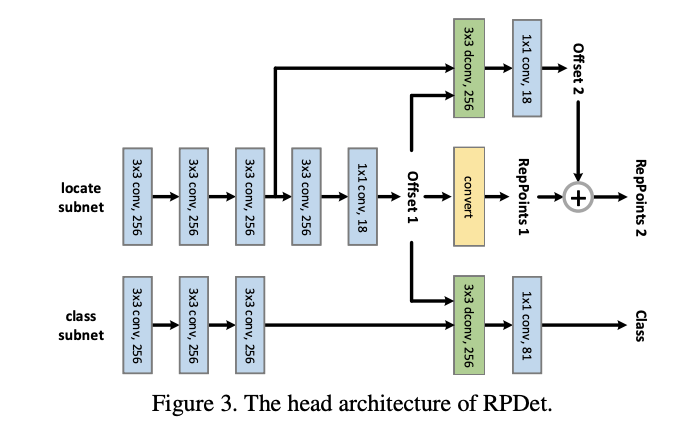
FPN主干网络包含5层特征金字塔level,从stage3(下采样8倍)到stage7(下采样128倍)。Head的结构如图3,Head在不同的level中是共享的,包含两个独立的子网,分别负责定位(RepPoints的生成)和分类:
- 定位子网首先使用3个256-d \(3\times 3\)卷积提取特征,每个卷积都接group normalization层,然后连续接两个小网络计算两组RepPoints的偏移值。
- 分类子网首先使用3个256-d \(3\times 3\)卷积提取特征,每个卷积都接group normalization层,然后将定位子网输出的第一组RepPoints的偏移值输入到256-d \(3\times 3\)可变形卷积中进一步提取特征,最后输出分类结果。
尽管RPDet采用了两阶段定位,但其性能甚至比单阶段的RetinaNet要高,主要是anchor-free的设计使得分类层的计算减少了,覆盖了额外的定位阶段带来的少量消耗。
Localization/class target assignment
定位包含两个阶段,第一阶段从中心点得到第一组RepPoints,第二阶段则从第一组RepPoints调整得到第二组RepPoints,不同的阶段的正样本定义不同:
- 对于第一阶段,特征点被认为是正样本需满足:1) 该特征点所在的特征金字塔level等于\(s(B)=\lfloor log_2 (\sqrt{W_Bh_B}/4)\rfloor\)。2) 目标的中心点在特征图上映射位置对应该特征点。
- 对于第二阶段,只有特征点对应的第一阶段产生的伪预测框与目标的IoU大于0.5才被认为是正样本。与当前的anchor-based方法有点类似,将第一阶段的输出当作anchor。
由于目标的分类只考虑第一组RepPoints,所以,特征点对应的第一组RepPoints产生的伪预测框于目标的IoU大于0.5即认为是正样本,小于0.4则认为是背景类,其它则忽略。
Experiments
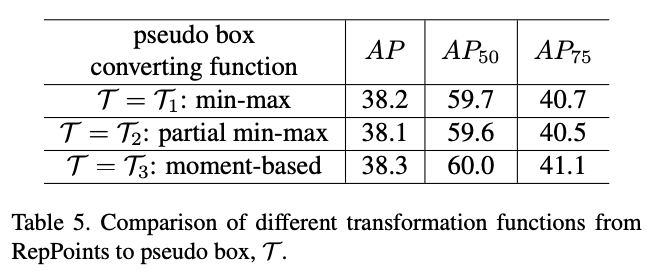
对比不同的伪预测框生成方法的性能。

与其它SOTA检测方法对比性能。
Conclusion
RepPoints的设计思想十分巧妙,使用富含语义信息的点集来表示目标,并且巧用可变形卷积来进行实现,整体网络设计十分完备,值得学习。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

RepPoints:微软巧用变形卷积生成点集进行目标检测,创意满满 | ICCV 2019的更多相关文章
- deeplearning.ai 卷积神经网络 Week 3 目标检测 听课笔记
本周的主题是对象检测(object detection):不但需要检测出物体(image classification),还要能定位出在图片的具体位置(classification with loca ...
- deeplearning.ai 卷积神经网络 Week 3 目标检测
本周的主题是对象检测(object detection):不但需要检测出物体(image classification),还要能定位出在图片的具体位置(classification with loca ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week3 目标检测
一.目标定位 这一小节视频主要介绍了我们在实现目标定位时标签该如何定义. 上图左下角给出了损失函数的计算公式(这里使用的是平方差) 如图示,加入我们需要定位出图像中是否有pedestrian,car, ...
- 卷积生成对抗网络(DCGAN)---生成手写数字
深度卷积生成对抗网络(DCGAN) ---- 生成 MNIST 手写图片 1.基本原理 生成对抗网络(GAN)由2个重要的部分构成: 生成器(Generator):通过机器生成数据(大部分情况下是图像 ...
- GAN实战笔记——第四章深度卷积生成对抗网络(DCGAN)
深度卷积生成对抗网络(DCGAN) 我们在第3章实现了一个GAN,其生成器和判别器是具有单个隐藏层的简单前馈神经网络.尽管很简单,但GAN的生成器充分训练后得到的手写数字图像的真实性有些还是很具说服力 ...
- Guided Anchoring:在线稀疏anchor生成方案,嵌入即提2AP | CVPR 2019
Guided Anchoring通过在线生成anchor的方式解决常规手工预设anchor存在的问题,以及能够根据生成的anchor自适应特征,在嵌入方面提供了两种实施方法,是一个很完整的解决方案 ...
- 使用Caffe完成图像目标检测 和 caffe 全卷积网络
一.[用Python学习Caffe]2. 使用Caffe完成图像目标检测 标签: pythoncaffe深度学习目标检测ssd 2017-06-22 22:08 207人阅读 评论(0) 收藏 举报 ...
- 深度学习原理与框架-卷积网络细节-三代物体检测算法 1.R-CNN 2.Fast R-CNN 3.Faster R-CNN
目标检测的选框操作:第一步:找出一些边缘信息,进行图像合并,获得少量的边框信息 1.R-CNN, 第一步:进行图像的选框,对于选出来的框,使用卷积计算其相似度,选择最相似ROI的选框,即最大值抑制RO ...
- [DeeplearningAI笔记]卷积神经网络3.1-3.5目标定位/特征点检测/目标检测/滑动窗口的卷积神经网络实现/YOLO算法
4.3目标检测 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.1目标定位 对象定位localization和目标检测detection 判断图像中的对象是不是汽车--Image clas ...
- PHP生成中文验证码并检测对错实例
PHP生成中文验证码并检测对错实例,中文验证码的例子还是比较少的,今天给大家分享一下,支持自定义中文.字体.背景色等 生成验证码,注意font字体路径要对,否则显示图片不存在 session_star ...
随机推荐
- ARP(Address Resolution Protocol) Packet
Address Resolution Protocol The Address Resolution Protocol (ARP) is a communication protocol used f ...
- Amlogic电视盒子红外遥控适配笔记
前一阵做了个安卓6的固件, 在R3300L和Q7上跑的, 其他问题没有, 但是有用户反映原来的遥控器用不了了, 于是检查了一下遥控器配置, 顺便学习一下此类设备的红外遥控机制. 为了方便测试还上淘宝买 ...
- 责任链模式与spring容器的搭配应用
背景 有个需求,原先只涉及到一种A情况设备的筛选,每次筛选会经过多个流程,比如先a功能,a功能通过再筛选b功能,然后再筛选c功能,以此类推.现在新增了另外一种B情况的筛选,B情况同样需要A情况的筛选流 ...
- Docker实践之09-高级网络配置
目录 一.Docker网络原理及默认配置 二.Docker网络定制配置参数 三.容器访问控制原理 1.容器访问外部网络 2.容器之间访问 3.访问所有端口 4.访问指定端口 5.映射容器端口到主机端口 ...
- webservice之jax-ws实现方式(服务端)
1.什么是webservice? webservice是一种远程资源调用技术,它的实现方式主要分为两种, 第一种是jaxws方式,它是面向方法的,它的数据类型是xml是基于soap实现传输: 第二种是 ...
- django学习第十四天--Forms和ModelForm
Forms和ModelForm 进行数据校验,先看数据校验的过程 注册页面图解: 前端为了用户体验会做一些校验,不满足校验要求会报错 服务端也会对数据进行一些校验,不满足校验要求会报错 数据库也会对数 ...
- 如何拓展jwt返回的数据
默认的返回值仅有token,我们还需在返回值中增加username和id,方便在客户端页面中显示当前登陆用户 通过修改该视图的返回值可以完成我们的需求. 在user/utils.py中,创建 def ...
- 【Azure 应用服务】可以在app service里建SFTP服务吗?
问题描述 怎样可以在App Service里建SFTP服务? 并不是说通过FTP的方式进行App Service的文件部署. 问题回答 不能通过 App Service 来搭建总计的SFTP服务,因为 ...
- Java //100以内的质数的输出(从2开始,到这个数-1结束为止,都不能被这个数本身整除)+优化
1 //100以内的质数的输出(从2开始,到这个数-1结束为止,都不能被这个数本身整除) 2 boolean isFlag = true; //标识i是否被j除尽,修改其值 3 4 for(int i ...
- Java 临时笔记
1 //srand((unsignedint)time(NULL)); C 2 //获取随机数 10-99 3 4 //int value = (int)(Math.random() * 90+10) ...